Habilitar la suplantación de usuario para supervisar la actividad del usuario y del trabajo de Spark
Cuadernos de EMR le permite configurar la suplantación de usuarios en un clúster de Spark. Esta característica le ayuda a realizar un seguimiento de la actividad de los trabajos iniciados desde el propio editor de blocs de notas. Además, Cuadernos de EMR dispone de un widget de cuaderno de Jupyter para ver los detalles de los trabajos de Spark junto con la salida de las consultas en el editor de cuadernos. El widget está disponible de forma predeterminada y no requiere ninguna configuración especial. Sin embargo, para ver los servidores del historial, el cliente debe configurarse para ver las interfaces web de Amazon EMR que se alojan en el nodo principal.
nota
Cuadernos de EMR está disponible como Espacios de trabajo de EMR Studio en la nueva consola. El botón Crear espacio de trabajo de la consola le permite crear nuevos cuadernos. Para crear espacios de trabajo o acceder a ellos, los usuarios de Cuadernos de EMR necesitan permisos de rol de IAM adicionales. Para obtener más información, consulte Cuadernos de Amazon EMR es Espacios de trabajo de Amazon EMR Studio en la consola y Consola Amazon EMR.
Configuración de la suplantación de usuarios de Spark
De forma predeterminada, los trabajos de Spark que los usuarios envían mediante el editor de blocs de notas parecen proceder de una identidad de usuario de livy indefinida. Es posible configurar la suplantación de usuarios para dicho clúster para que estos trabajos se asocien a la identidad del usuario que ejecutó el código. Se crean directorios de usuario de HDFS en el nodo principal para cada identidad de usuario que ejecuta código en el cuaderno. Por ejemplo, si el usuario NbUser1 ejecuta código desde el editor de cuadernos, puede conectarse con el nodo principal y comprobar que hadoop fs -ls /user muestra el directorio /user/user_NbUser1.
Para habilitar esta característica, establezca las propiedades de las clasificaciones de configuración core-site y livy-conf. Esta característica no está disponible de forma predeterminada si se indica a Amazon EMR que cree un clúster junto con un cuaderno. Para obtener más información sobre cómo usar clasificaciones de configuración para personalizar aplicaciones, consulte Configuración de aplicaciones en la Guía de publicación de Amazon EMR.
Utilice los siguientes valores y clasificaciones de configuración para habilitar la suplantación de usuarios en Cuadernos de EMR:
[ { "Classification": "core-site", "Properties": { "hadoop.proxyuser.livy.groups": "*", "hadoop.proxyuser.livy.hosts": "*" } }, { "Classification": "livy-conf", "Properties": { "livy.impersonation.enabled": "true" } } ]
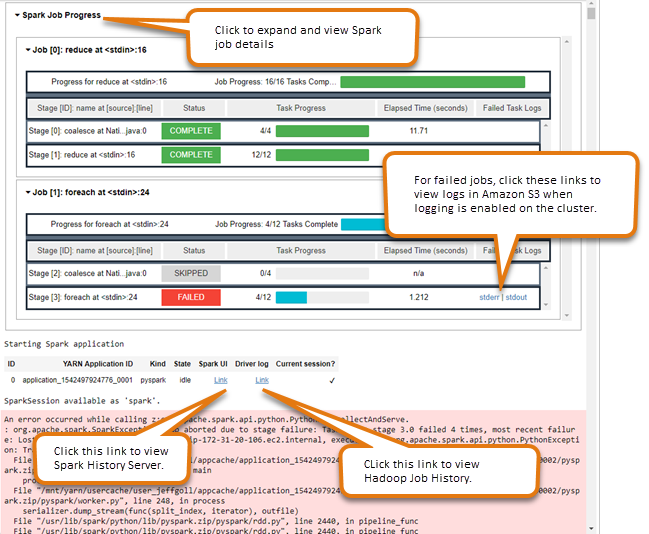
Uso del widget de supervisión de trabajos de Spark
Cuando se ejecuta código en el editor de blocs de notas que ejecuta a su vez trabajos de Spark en el clúster de EMR, la salida incluye un widget de Jupyter Notebook para la monitorización de trabajos de Spark. El widget proporciona detalles del trabajo y enlaces útiles a la página del servidor de historial de Spark y a la página del historial de trabajos de Hadoop, junto con los enlaces correspondientes a registros de trabajos en Amazon S3 para los trabajos con errores.
Para ver las páginas del servidor de historial en el nodo principal del clúster, debe configurar un cliente SSH y un proxy de forma adecuada. Para obtener más información, consulte Ver las interfaces web alojadas en clústeres de Amazon EMR. Para ver los registros en Amazon S3, el registro de clúster debe estar habilitado, que es la opción predeterminada para los clústeres nuevos. Para obtener más información, consulte Ver los archivos de registro archivados en Amazon S3.
A continuación, se muestra un ejemplo de supervisión de trabajos de Spark.