Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Complemento Apache Spark para la integración de Ranger con Amazon EMR
Amazon EMR se ha integrado EMR RecordServer para proporcionar un control de acceso detallado a Spark. SQL EMR RecordServer es un proceso privilegiado que se ejecuta en todos los nodos de un clúster compatible con Apache Ranger. Cuando un controlador o ejecutor de Spark ejecuta una SQL sentencia de Spark, todas las solicitudes de metadatos y datos pasan por. RecordServer Para obtener más información EMR RecordServer, consulta la EMRComponentes de Amazon para usar con Apache Ranger página.
Temas
Características admitidas
| SQLDeclaración/acción de los guardabosques | STATUS | Versión compatible EMR |
|---|---|---|
|
SELECT |
Compatible |
A partir de la 5.32 |
|
SHOW DATABASES |
Compatible |
A partir de la 5.32 |
|
SHOW COLUMNS |
Compatible |
A partir de la 5.32 |
|
SHOW TABLES |
Compatible |
A partir de la 5.32 |
|
SHOW TABLE PROPERTIES |
Compatible |
A partir de la 5.32 |
|
DESCRIBE TABLE |
Compatible |
A partir de la 5.32 |
|
INSERT OVERWRITE |
Compatible |
A partir de las 5.34 y 6.4 |
| INSERT INTO | Compatible | A partir de las 5.34 y 6.4 |
|
ALTER TABLE |
Compatible |
A partir de la 6.4 |
|
CREATE TABLE |
Compatible |
A partir de las 5.35 y 6.7 |
|
CREATE DATABASE |
Compatible |
A partir de las 5.35 y 6.7 |
|
DROP TABLE |
Compatible |
A partir de las 5.35 y 6.7 |
|
DROP DATABASE |
Compatible |
A partir de las 5.35 y 6.7 |
|
DROP VIEW |
Compatible |
A partir de las 5.35 y 6.7 |
|
CREATE VIEW |
No es compatible |
Cuando se utiliza Spark, se admiten las siguientes funcionesSQL:
-
Control de acceso detallado a las tablas del metaalmacén de Hive, y las políticas se pueden crear para bases de datos, tablas y columnas.
-
Las políticas de Apache Ranger pueden incluir políticas de concesión y de denegación a usuarios y grupos.
-
Los eventos de auditoría se envían a CloudWatch los registros.
Vuelva a implementar la definición de servicio que va a utilizar o INSERT las ALTER declaraciones DDL
nota
A partir de Amazon EMR 6.4, puedes usar Spark SQL con las instrucciones: INSERTINTO, INSERTOVERWRITE, o ALTERTABLE. A partir de Amazon EMR 6.7, puedes usar Spark SQL para crear o eliminar bases de datos y tablas. Si ya tiene una instalación en el servidor de Apache Ranger con las definiciones de servicio de Apache Spark implementadas, utilice el siguiente código para volver a implementar las definiciones de servicio.
# Get existing Spark service definition id calling Ranger REST API and JSON processor curl --silent -f -u<admin_user_login>:<password_for_ranger_admin_user>\ -H "Accept: application/json" \ -H "Content-Type: application/json" \ -k 'https://*<RANGER SERVER ADDRESS>*:6182/service/public/v2/api/servicedef/name/amazon-emr-spark' | jq .id # Download the latest Service definition wget https://s3.amazonaws.com/elasticmapreduce/ranger/service-definitions/version-2.0/ranger-servicedef-amazon-emr-spark.json # Update the service definition using the Ranger REST API curl -u<admin_user_login>:<password_for_ranger_admin_user>-X PUT -d @ranger-servicedef-amazon-emr-spark.json \ -H "Accept: application/json" \ -H "Content-Type: application/json" \ -k 'https://*<RANGER SERVER ADDRESS>*:6182/service/public/v2/api/servicedef/<Spark service definition id from step 1>'
Instalación de la definición de servicio
La instalación de EMR la definición de servicio Apache Spark requiere la configuración del servidor Ranger Admin. Consulte Configura un servidor Ranger Admin para integrarlo con Amazon EMR.
Siga estos pasos para instalar la definición de servicio de Apache Spark:
Paso 1: SSH en el servidor de administración de Apache Ranger
Por ejemplo:
ssh ec2-user@ip-xxx-xxx-xxx-xxx.ec2.internal
Paso 2: descargue la definición de servicio y el complemento del servidor de Apache Ranger Admin
En un directorio temporal, descargue la definición de servicio. Esta definición de servicio es compatible con las versiones 2.x de Ranger.
mkdir /tmp/emr-spark-plugin/ cd /tmp/emr-spark-plugin/ wget https://s3.amazonaws.com/elasticmapreduce/ranger/service-definitions/version-2.0/ranger-spark-plugin-2.x.jar wget https://s3.amazonaws.com/elasticmapreduce/ranger/service-definitions/version-2.0/ranger-servicedef-amazon-emr-spark.json
Paso 3: Instalar el complemento Apache Spark para Amazon EMR
export RANGER_HOME=.. # Replace this Ranger Admin's home directory eg /usr/lib/ranger/ranger-2.0.0-admin mkdir $RANGER_HOME/ews/webapp/WEB-INF/classes/ranger-plugins/amazon-emr-spark mv ranger-spark-plugin-2.x.jar $RANGER_HOME/ews/webapp/WEB-INF/classes/ranger-plugins/amazon-emr-spark
Paso 4: Registrar la definición del servicio Apache Spark para Amazon EMR
curl -u *<admin users login>*:*_<_**_password_ **_for_** _ranger admin user_**_>_* -X POST -d @ranger-servicedef-amazon-emr-spark.json \ -H "Accept: application/json" \ -H "Content-Type: application/json" \ -k 'https://*<RANGER SERVER ADDRESS>*:6182/service/public/v2/api/servicedef'
Si este comando se ejecuta correctamente, verás un nuevo servicio en la interfaz de usuario de tu Ranger llamado "AMAZON- EMR - SPARK «, como se muestra en la siguiente imagen (se muestra la versión 2.0 de Ranger).
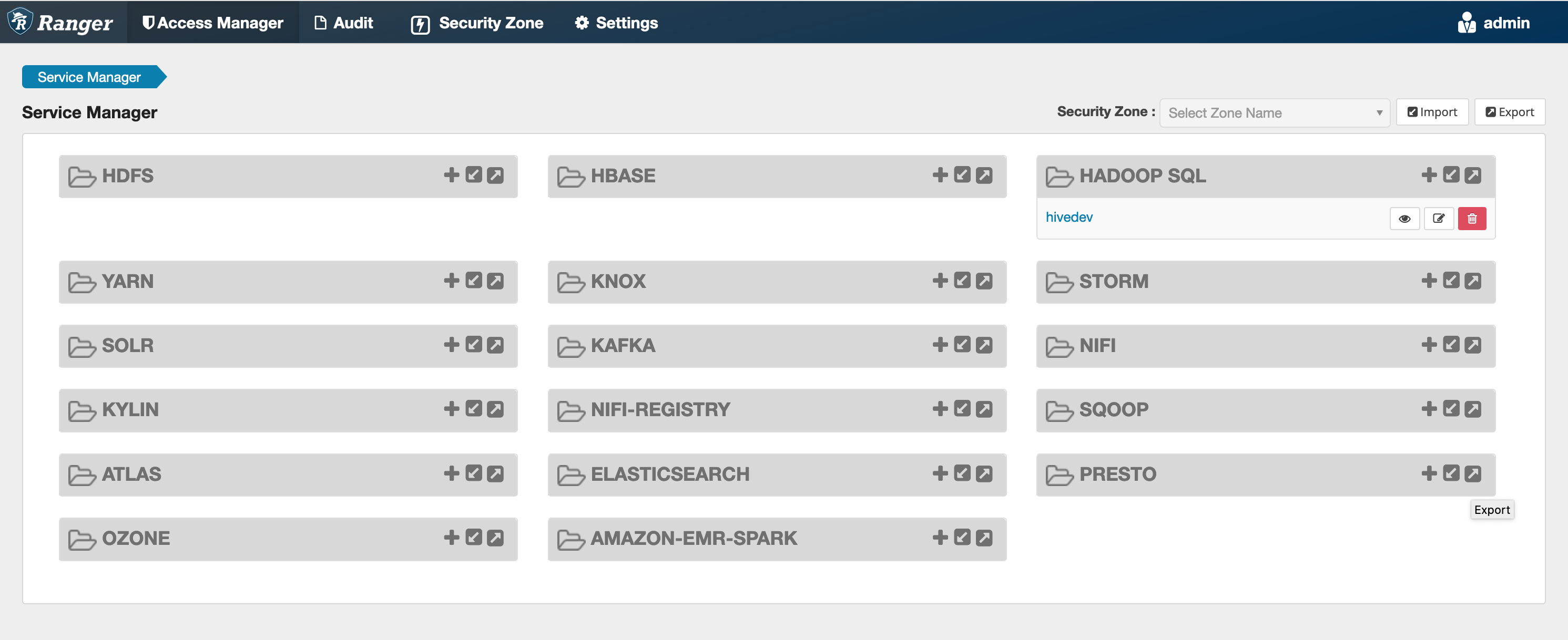
Paso 5: Crea una instancia de la aplicación AMAZON-EMR-SPARK
Nombre del servicio (si se muestra): el nombre del servicio que se utilizará. El valor sugerido es amazonemrspark. Anote el nombre de este servicio, ya que será necesario al crear una configuración EMR de seguridad.
Nombre público: el nombre que se mostrará para esta instancia. El valor sugerido es amazonemrspark.
Nombre común del certificado: el campo CN (Nombre común) del certificado que se utiliza para conectarse al servidor de administración desde un complemento cliente. Este valor debe coincidir con el campo CN del TLS certificado que se creó para el complemento.
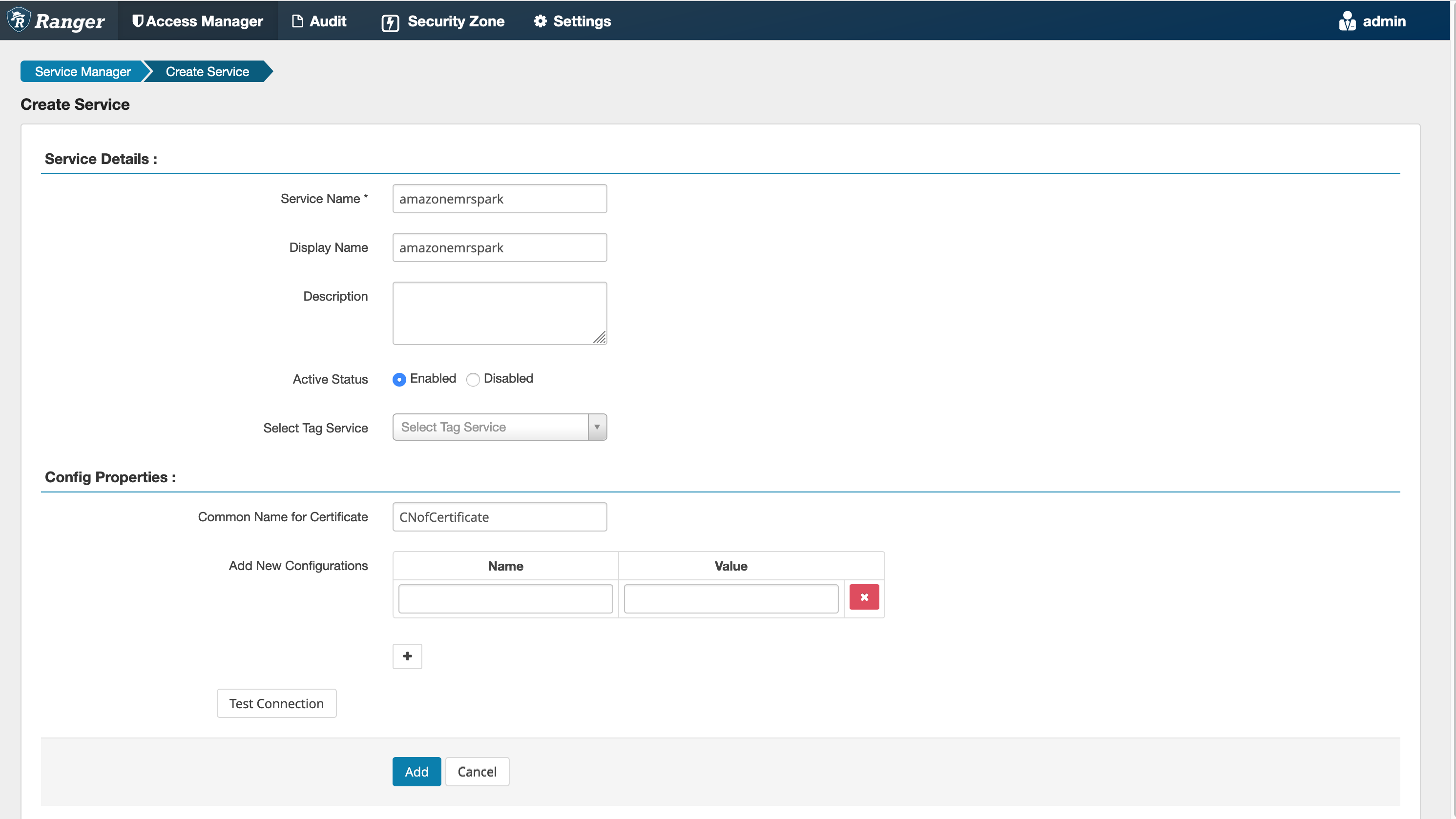
nota
El TLS certificado de este complemento debería haberse registrado en el almacén de confianza del servidor Ranger Admin. Consulte TLScertificados para la integración de Apache Ranger con Amazon EMR para obtener más detalles.
Crear políticas de Spark SQL
Al crear una nueva política, los campos que hay que rellenar son:
Nombre de la política: el nombre de la política.
Etiqueta de la política: una etiqueta que puede poner en esta política.
Base de datos: la base de datos a la que se aplica esta política. El comodín “*” representa todas las bases de datos.
Tabla: las tablas a las que se aplica esta política. El comodín “*” representa todas las tablas.
EMRColumna Spark: las columnas a las que se aplica esta política. El comodín “*” representa todas las columnas.
Descripción: una descripción de esta política.
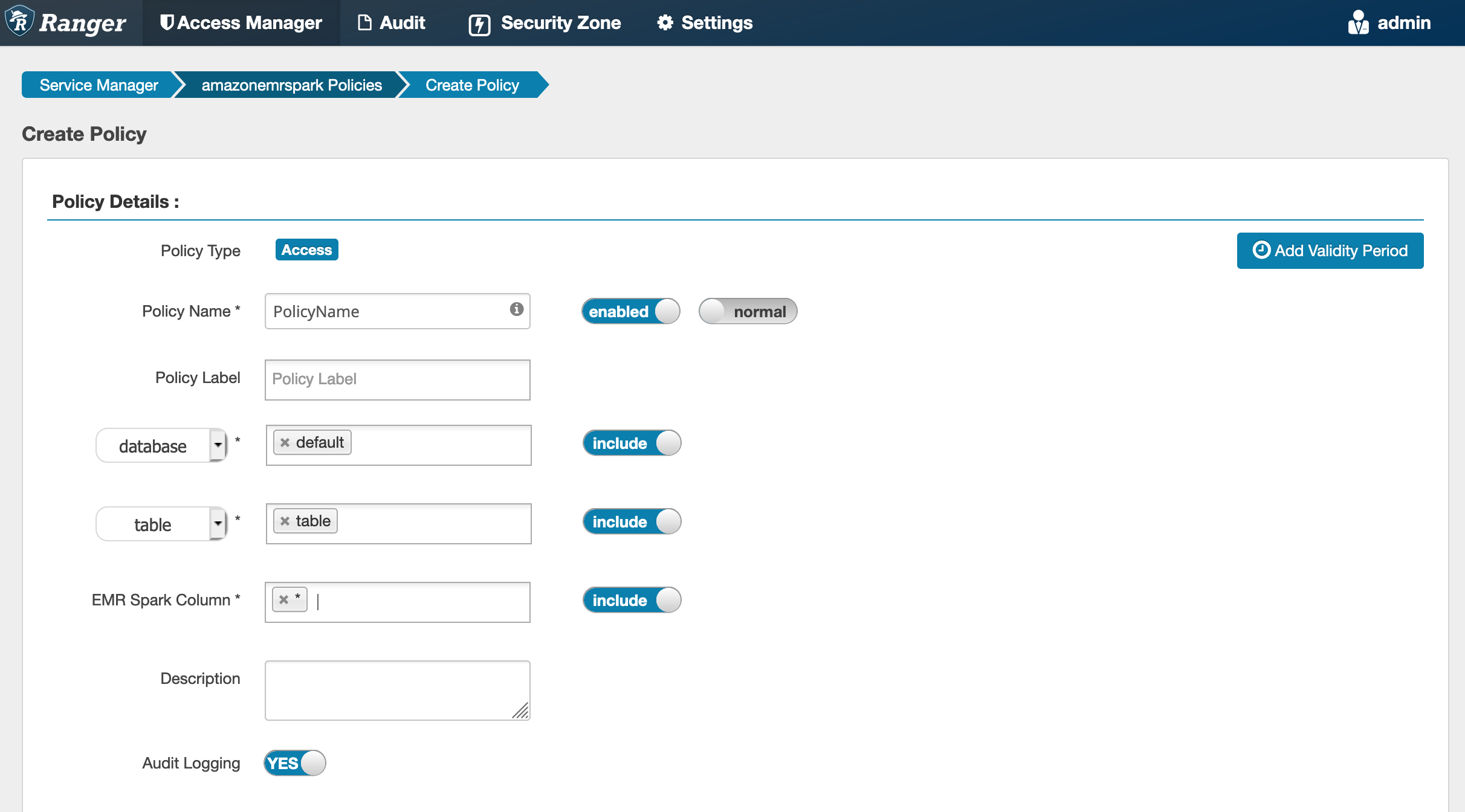
Para especificar los usuarios y grupos, ingrese los usuarios y grupos que aparecen a continuación para conceder los permisos. También puede especificar exclusiones para las condiciones de autorización y denegación.
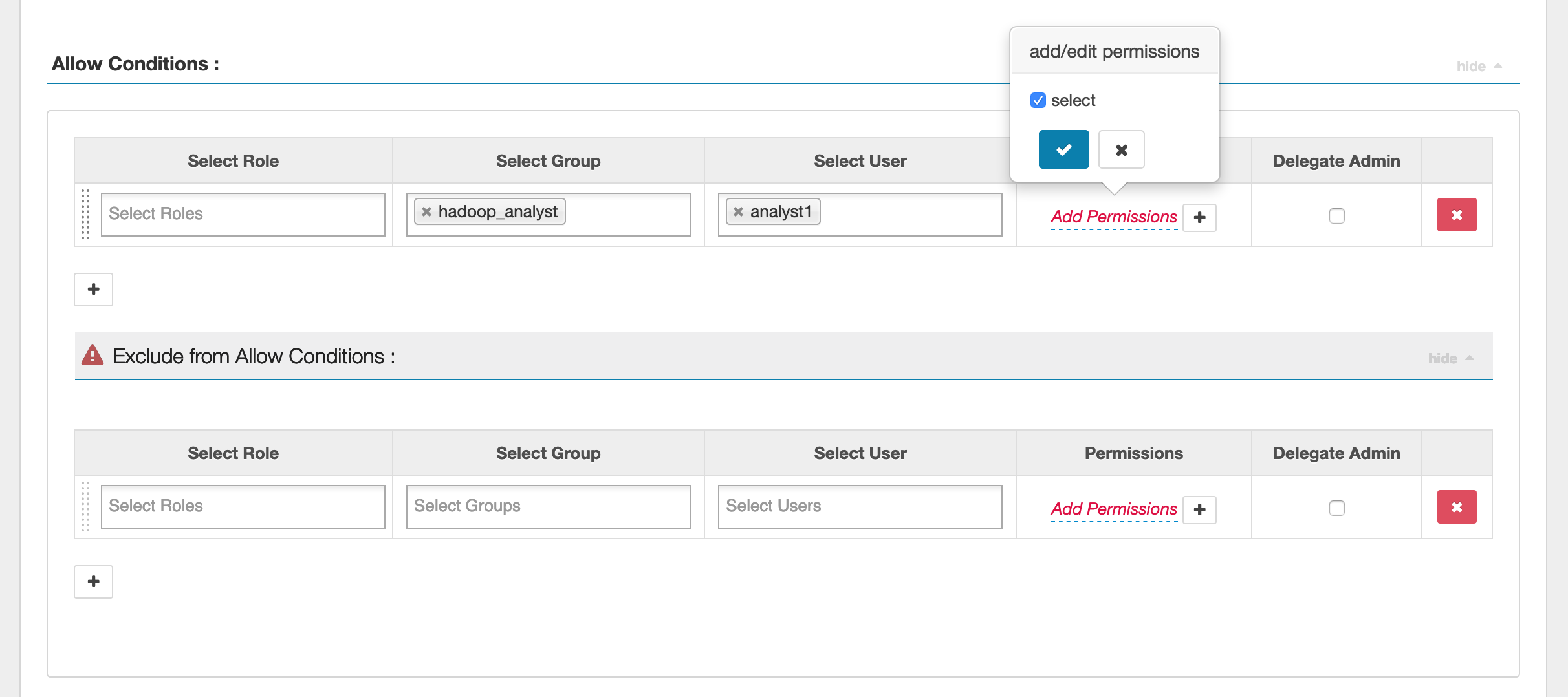
Tras especificar las condiciones de autorización y denegación, haga clic en Guardar.
Consideraciones
Cada nodo del EMR clúster debe poder conectarse al nodo principal en el puerto 9083.
Limitaciones
Las siguientes son las limitaciones actuales del complemento Apache Spark:
-
Record Server siempre se conectará a un EMR clúster de Amazon en HMS ejecución. HMSConfigúrelo para conectarse al modo remoto, si es necesario. No debe incluir valores de configuración en el archivo de configuración Hive-site.xml de Apache Spark.
-
Las tablas creadas con fuentes de datos de Spark CSV o Avro no se pueden leer con ellas. EMR RecordServer Use Hive para crear y escribir datos, y lea con Record.
-
No se admiten las tablas de Delta Lake y Hudi.
-
Los usuarios tienen que tener acceso a la base de datos predeterminada. Este es un requisito para el uso de Apache Spark.
-
El servidor de Ranger Admin no admite la característica de autocompletar.
-
El SQL complemento Spark para Amazon EMR no admite filtros de filas ni enmascaramiento de datos.
-
Cuando se usa ALTER TABLE con SparkSQL, una ubicación de partición debe ser el directorio secundario de una ubicación de tabla. No se admite la inserción de datos en una partición cuya ubicación sea diferente de la ubicación de la tabla.
