Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Depurar aplicaciones y trabajos con EMR Studio
Con Amazon EMR Studio, puede lanzar interfaces de aplicaciones de datos para analizar las aplicaciones y las ejecuciones de trabajos en el navegador.
También puede lanzar las interfaces de usuario persistentes y fuera del clúster para Amazon EMR que se ejecutan en clústeres de EC2 desde la consola de Amazon EMR. Para obtener más información, consulte Visualización de interfaces de usuario de aplicaciones persistentes en Amazon EMR.
En función de la configuración del navegador, es posible que necesite habilitar las ventanas emergentes para que se abra la interfaz de usuario de una aplicación.
Para obtener información sobre la configuración y el uso de las interfaces de la aplicación, consulte The YARN Timeline Server, Monitoring and Instrumentation o Tez UI Overview.
Depurar Amazon EMR que se ejecuta en trabajos de Amazon EC2
- Workspace UI
-
Iniciar una interfaz de usuario en el clúster a partir de un archivo de cuaderno
Si utiliza las versiones 5.33.0 y posteriores de Amazon EMR, puede iniciar la interfaz de usuario web de Spark (la interfaz de usuario de Spark o el servidor de historial de Spark) desde un cuaderno en el espacio de trabajo.
On-cluster Las UI funcionan con los PySpark núcleos Spark o SparkR. El tamaño máximo de archivo visible para los registros de eventos o contenedores de Spark es de 10 MB. Si sus archivos de registro superan los 10 MB, le recomendamos que utilice el servidor de historial de Spark persistente en lugar de la interfaz de usuario de Spark integrada en el clúster para depurar los trabajos.
Para que EMR Studio pueda lanzar interfaces de usuario de aplicaciones en un clúster desde un espacio de trabajo, un clúster debe poder comunicarse con Amazon API Gateway. Debe configurar el clúster de EMR para permitir el tráfico de red saliente a Amazon API Gateway y asegurarse de que se pueda acceder a Amazon API Gateway desde el clúster.
La interfaz de usuario de Spark accede a los registros del contenedor resolviendo los nombres de host. Si utiliza un nombre de dominio personalizado, debe asegurarse de que Amazon DNS o el servidor DNS que especifique puedan resolver los nombres de host de los nodos de su clúster. Para ello, defina las opciones del protocolo de configuración dinámica de host (DHCP) para la Amazon Virtual Private Cloud (VPC) asociada al clúster. Para obtener más información sobre las opciones de DHCP, consulte los conjuntos de opciones de DHCP en la Guía del usuario de Amazon Virtual Private Cloud.
-
En su EMR Studio, abra el espacio de trabajo que desee usar y asegúrese de que esté conectado a un clúster de Amazon EMR que se ejecute en EC2. Para obtener instrucciones, consulte Asociar computación a un espacio de trabajo de EMR Studio.
-
Abre un archivo de bloc de notas y usa el PySpark núcleo Spark o SparkR. Para seleccionar un kernel, seleccione su nombre en la parte superior derecha de la barra de herramientas del cuaderno para abrir el cuadro de diálogo Seleccionar kernel. El nombre aparece como No hay ningún kernel si no se ha seleccionado ningún kernel.
-
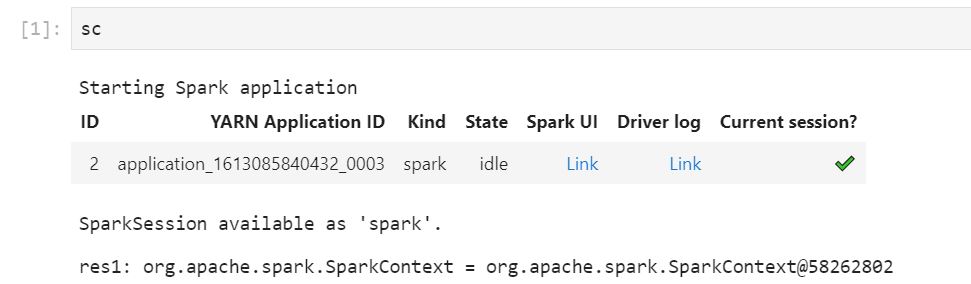
Ejecute el código de su cuaderno. El fragmento siguiente aparece como salida en el cuaderno al iniciar el contexto de Spark. Puede que tarde unos segundos en aparecer. Si ha iniciado el contexto de Spark, puede ejecutar el comando %%info para acceder a un enlace que le llevará a la interfaz de usuario de Spark en cualquier momento.
Si los enlaces de la interfaz de usuario de Spark no funcionan o no aparecen después de unos segundos, cree una nueva celda de cuaderno y ejecute el comando %%info para regenerar los enlaces.
-
Para iniciar la interfaz de usuario de Spark, seleccione Vincular en la interfaz de usuario de Spark. Si la aplicación de Spark se está ejecutando, la interfaz de usuario de Spark se abrirá en una pestaña nueva. Si la aplicación se ha completado, en su lugar se abrirá el servidor de historial de Spark.
Tras iniciar la interfaz de usuario de Spark, puedes modificar la URL en el navegador para abrir el YARN ResourceManager o el servidor de cronología de Yarn. Agregue una de las siguientes rutas después de amazonaws.com.
| Interfaz de usuario web |
Ruta |
Ejemplo de URL modificada |
| YARN ResourceManager |
/rm |
j-examplebby5ijhttps://.emrappui-prod. eu-west-1.amazonaws.com /rm |
| Yarn Timeline Server |
/yts |
https://.emrappui-prod. j-examplebby5ij eu-west-1.amazonaws.com /yts |
| Servidor de historial de Spark |
/shs |
https://.emrappui-prod. j-examplebby5ij eu-west-1.amazonaws.com /shs
|
- Studio UI
-
Iniciar el servidor YARN Timeline, el servidor de historial de Spark o la interfaz de usuario de Tez persistentes desde la interfaz de usuario de EMR Studio
-
En su EMR Studio, seleccione Amazon EMR en EC2 en la parte izquierda de la página para abrir la lista de clústeres de Amazon EMR en EC2.
-
Filtre la lista de clústeres por nombre, estado o identificador introduciendo valores en el cuadro de búsqueda. También puede buscar por intervalo de tiempo de creación.
-
Seleccione un clúster y, a continuación, seleccione Iniciar las interfaces de usuario de la aplicación para seleccionar una interfaz de usuario de la aplicación. La interfaz de usuario de la aplicación se abre en una nueva pestaña del navegador y puede que tarde en cargarse.
Depurar un EMR Studio en ejecución en EMR sin servidor
Al igual que Amazon EMR que se ejecuta en Amazon EC2, puede utilizar la interfaz de usuario del espacio de trabajo para analizar sus aplicaciones de EMR sin servidor. En la interfaz de usuario del espacio de trabajo, si utiliza las versiones 6.14.0 y posteriores de Amazon EMR, puede iniciar la interfaz de usuario web de Spark (la interfaz de usuario de Spark o el servidor de historial de Spark) desde un cuaderno en el espacio de trabajo. Para su comodidad, también ofrecemos un enlace para acceder rápidamente a los registros de controladores de Spark.
Depurar Amazon EMR en ejecuciones de trabajos de EKS con el servidor de historial de Spark
Cuando envía una ejecución de trabajo a un clúster de Amazon EMR en EKS, puede acceder a los registros de esa ejecución de trabajos mediante el servidor de historial de Spark. El servidor de historial de Spark proporciona herramientas para monitorear las aplicaciones de Spark, como una lista de las etapas y tareas del programador, un resumen del tamaño de los RDD y el uso de memoria, e información sobre el entorno. Puede iniciar el servidor de historial de Spark para las ejecuciones de trabajos de Amazon EMR en EKS de las siguientes maneras:
-
Cuando envíe una ejecución de trabajo con EMR Studio con un punto de conexión administrado de Amazon EMR en EKS, puede lanzar el servidor de historial de Spark desde un archivo de cuaderno de su espacio de trabajo.
-
Cuando envíes una ejecución de trabajo con el AWS SDK AWS CLI o Amazon EMR en EKS, puedes lanzar el Spark History Server desde la interfaz de usuario de EMR Studio.
Para obtener información sobre cómo utilizar el servidor de historial de Spark, consulte Supervisión e instrumentación en la documentación de Apache Spark. Para obtener más información sobre las ejecuciones de trabajos, consulte Conceptos y componentes en la Guía de desarrollo de Amazon EMR en EKS.
Para iniciar el servidor de historial de Spark desde un archivo de cuaderno en su espacio de trabajo de EMR Studio
-
Abra un espacio de trabajo que esté conectado a un clúster de Amazon EMR en EKS.
-
Seleccione y abra el archivo de su cuaderno en el espacio de trabajo.
-
Elija la interfaz de usuario de Spark en la parte superior del archivo del cuaderno para abrir el servidor de historial de Spark persistente en una pestaña nueva.
Para iniciar el servidor de historial de Spark desde la interfaz de usuario de EMR Studio
La lista de trabajos de la interfaz de usuario de EMR Studio muestra solo las ejecuciones de trabajos que envíe mediante el uso de Amazon EMR AWS CLI o el AWS SDK para Amazon EMR en EKS.
-
En su EMR Studio, seleccione Amazon EMR en EKS en la parte izquierda de la página.
-
Busque el clúster virtual de Amazon EMR en EKS que utilizó para enviar la ejecución de su trabajo. Puede filtrar la lista de clústeres por estado o identificador introduciendo valores en el cuadro de búsqueda.
-
Seleccione el clúster para abrir su página de detalles. En la página de detalles se muestra información sobre el clúster, como el identificador, el espacio de nombres y el estado. En la página también se muestra una lista de todas las ejecuciones de trabajos enviadas a ese clúster.
-
En la página de detalles del clúster, seleccione una ejecución de trabajos para depurarla.
-
En la parte superior derecha de la lista Trabajos, seleccione Iniciar servidor de historial de Spark para abrir la interfaz de la aplicación en una nueva pestaña del navegador.