Descripción de las métricas de escalado administrado en Amazon EMR
Amazon EMR publica métricas de alta resolución con datos en una granularidad de un minuto cuando se habilita el escalado administrado para un clúster. Puede ver los eventos de cada inicio y terminación de cambio de tamaño controlado por el escalado administrado con la consola de Amazon EMR o la consola de Amazon CloudWatch. Las métricas de CloudWatch son fundamentales para que Escalado administrado de Amazon EMR funcione. Le recomendamos que monitorice de cerca las métricas de CloudWatch para asegurarse de que no falten datos. Para obtener más información sobre cómo configurar las alarmas de CloudWatch para detectar las métricas que faltan, consulte Uso de las alarmas de Amazon CloudWatch. Para obtener más información acerca de los eventos de CloudWatch con Amazon EMR, consulte Supervisar eventos de CloudWatch.
Las siguientes métricas indican la capacidad actual o prevista de un clúster. Estas métricas solo están disponibles cuando el escalado administrado está habilitado. Para los clústeres compuestos por flotas de instancias, las métricas de capacidad del clúster se miden en Units. Para los clústeres compuestos por grupos de instancias, las métricas de capacidad del clúster se miden en Nodes o en vCPU en función del tipo de unidad utilizado en la política de escalado administrado.
| Métrica | Descripción |
|---|---|
|
El número total previsto de unidades, nodos o vCPU en un clúster según lo determine el escalado administrado. Unidades: recuento |
|
El número total actual de unidades, nodos o vCPU disponibles en un clúster en ejecución. Cuando se solicita un cambio de tamaño del clúster, esta métrica se actualizará después de agregar o quitar las nuevas instancias del clúster. Unidades: recuento |
|
El número previsto de unidades, nodos o vCPU CORE en un clúster según lo determine el escalado administrado. Unidades: recuento |
|
El número actual de unidades, nodos o vCPU CORE que se ejecutan en un clúster. Unidades: recuento |
|
El número previsto de unidades, nodos o vCPU TASK en un clúster según lo determine el escalado administrado. Unidades: recuento |
|
El número actual de unidades, nodos o vCPU TASK que se ejecutan en un clúster. Unidades: recuento |
Las siguientes métricas indican el estado de uso del clúster y las aplicaciones. Estas métricas están disponibles para todas las características de Amazon EMR, pero se publican con una resolución más alta con datos y una granularidad de un minuto cuando se habilita el escalado administrado para un clúster. Puede comparar las siguientes métricas con las métricas de capacidad del clúster de la tabla anterior para conocer las decisiones de escalado administrado.
| Métrica | Descripción |
|---|---|
|
|
El número de aplicaciones enviadas a YARN que se han completado. Caso de uso: monitorizar el progreso del clúster Unidades: recuento |
|
|
El número de aplicaciones enviadas a YARN que están en estado pendiente. Caso de uso: monitorizar el progreso del clúster Unidades: recuento |
|
|
El número de aplicaciones enviadas a YARN que se están ejecutando. Caso de uso: monitorizar el progreso del clúster Unidades: recuento |
ContainerAllocated |
El número de contenedores de recursos asignados por ResourceManager. Caso de uso: monitorizar el progreso del clúster Unidades: recuento |
|
|
El número de contenedores en la cola que aún no se han asignado. Caso de uso: monitorizar el progreso del clúster Unidades: recuento |
ContainerPendingRatio |
La proporción entre contenedores pendientes y contenedores asignados (ContainerPendingRatio = ContainerPending / ContainerAllocated). Si ContainerAllocated = 0, entonces ContainerPendingRatio = ContainerPending. El valor de ContainerPendingRatio representa un número, no un porcentaje. Este valor es útil para escalar recursos del clúster en función del comportamiento de asignación de contenedores. Unidades: recuento |
|
|
El porcentaje de almacenamiento HDFS usado actualmente. Caso de uso: analizar el rendimiento del clúster Unidades: porcentaje |
|
|
Indica que un clúster ya no está funcionando, pero sigue activo y acumulando cargos. Se establece en 1 si no se ejecuta ninguna tarea ni ningún trabajo; en caso contrario, se establece en 0. Este valor se comprueba a intervalos de cinco minutos, y un valor de 1 indica que el clúster estaba inactivo cuando se comprobó, no que estuvo inactivo durante los cinco minutos. Para evitar falsos positivos, debe activar una alarma cuando este valor sea 1 durante más de una comprobación consecutiva de cinco minutos. Por ejemplo, puede activar una alarma cuando este valor sea 1 durante treinta minutos o más. Caso de uso: monitorizar el rendimiento del clúster Unidades: booleano |
|
|
La cantidad de memoria disponible para asignar. Caso de uso: monitorizar el progreso del clúster Unidades: recuento |
|
|
El número de nodos que se están ejecutando actualmente en tareas o trabajos de MapReduce. Equivalente a la métrica YARN Caso de uso: monitorizar el progreso del clúster Unidades: recuento |
|
|
El porcentaje de memoria restante disponible para YARN (YARNMemoryAvailablePercentage = MemoryAvailableMB / MemoryTotalMB). Este valor es útil para escalar recursos del clúster en función del uso de memoria de YARN. Unidades: porcentaje |
Diagramación de métricas de escalado administrado
Puede diagramar las métricas para ver los patrones de carga de trabajo del clúster y las decisiones de escalado correspondientes tomadas por Escalado administrado de Amazon EMR, como se muestra en los pasos siguientes.
Para diagramar métricas de escalado administrado en la consola de CloudWatch
-
Abra la consola de CloudWatch
. -
En el panel de navegación, seleccione Amazon EMR. Puede buscar el identificador del clúster que desea monitorizar.
-
Desplácese hacia abajo hasta la métrica que desea representar gráficamente. Abra una métrica para mostrar el gráfico.
-
Para representar gráficamente una o varias métricas, seleccione la casilla de verificación junto a cada métrica.
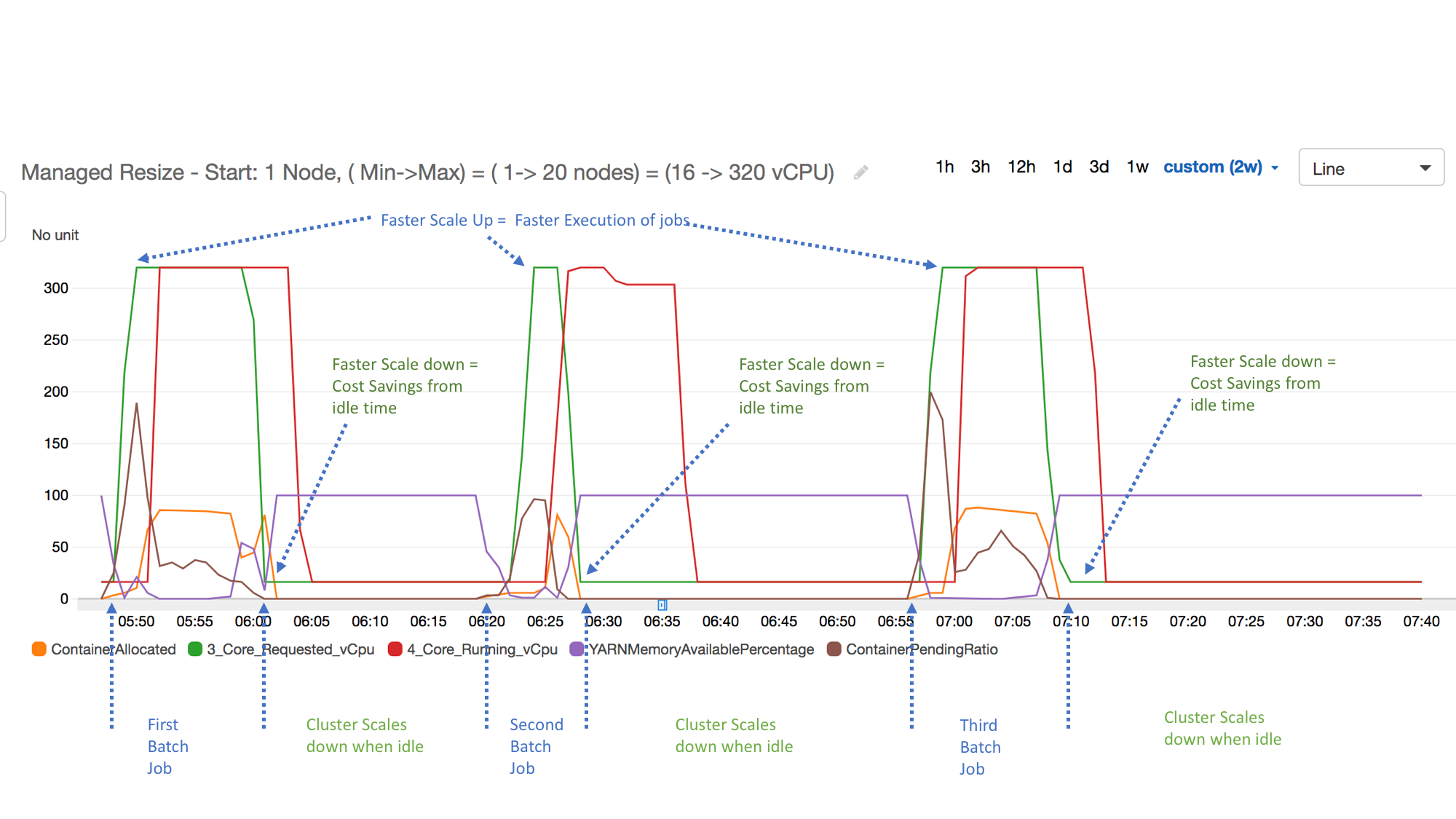
En el siguiente ejemplo, se ilustra la actividad de Escalado administrado de Amazon EMR de un clúster. El gráfico muestra tres periodos de reducción de capacidad automática, que ahorran costos cuando hay una carga de trabajo menos activa.
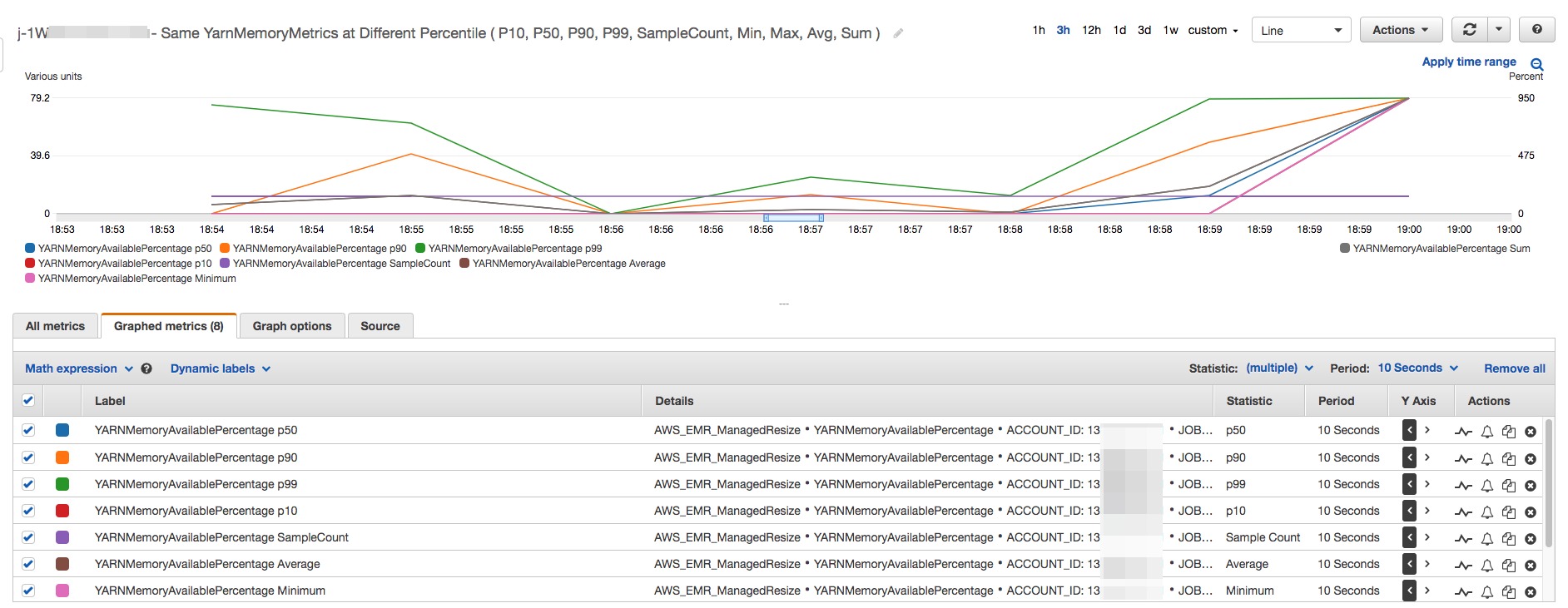
Todas las métricas de capacidad y uso del clúster se publican a intervalos de un minuto. La información estadística adicional también se asocia a cada dato de un minuto, lo que le permite diagramar varias funciones como Percentiles, Min, Max, Sum, Average, SampleCount.
Por ejemplo, el siguiente gráfico muestra la misma métrica YARNMemoryAvailablePercentage en percentiles diferentes, P10, P50, P90, P99, junto con Sum, Average, Min, SampleCount.