Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Escalador automático de Flink
Descripción general
Las versiones 6.15.0 y posteriores de Amazon EMR admiten el escalador automático de Flink. La funcionalidad del escalador automático de trabajos recopila métricas de la ejecución de los trabajos de transmisión de Flink y escala automáticamente los vértices individuales de los trabajos. Esto reduce la contrapresión y cumple el objetivo de utilización establecido.
Para obtener más información, consulte la sección sobre el escalador automático
Consideraciones
-
Las versiones 6.15.0 y posteriores de Amazon EMR admiten el escalador automático de Flink.
-
El escalador automático de Flink solo es compatible con trabajos de transmisión.
-
Solo se admite el programador adaptativo. El programador predeterminado no es compatible.
-
Se recomienda habilitar el escalado de clústeres para permitir el aprovisionamiento dinámico de recursos. Se prefiere el escalado administrado de Amazon EMR porque la evaluación de las métricas se realiza cada 5 a 10 segundos. En este intervalo, el clúster puede adaptarse más fácilmente al cambio en los recursos del clúster necesarios.
Habilitación del escalador automático
Siga los siguientes pasos para activar el escalador automático de Flink cuando cree un Amazon EMR en un clúster. EC2
-
En la consola de Amazon EMR, cree un nuevo clúster de EMR:
-
Elija la versión
emr-6.15.0de Amazon EMR o una posterior. Elija el paquete de aplicaciones de Flink y seleccione cualquier otra aplicación que desee incluir en su clúster.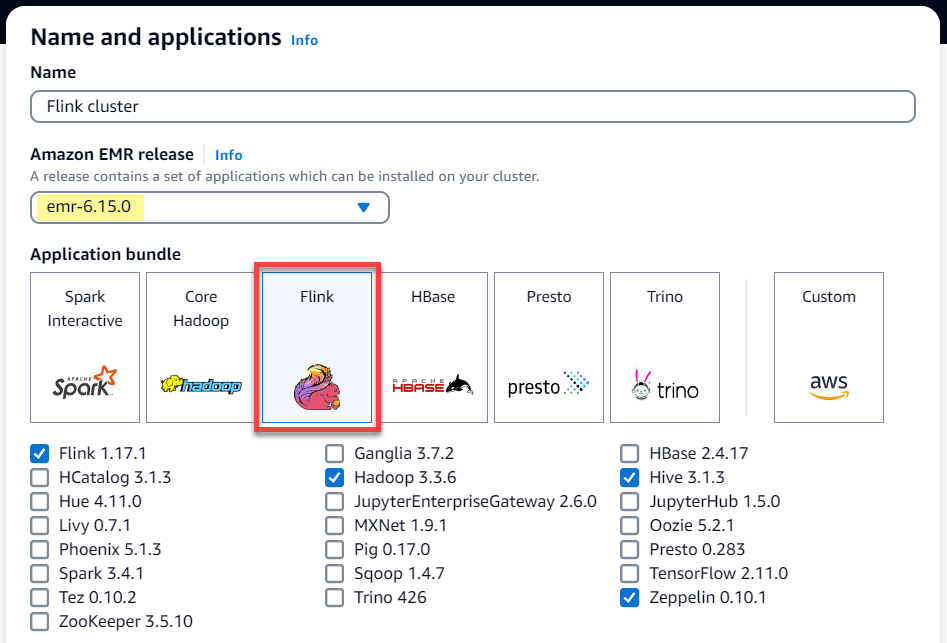
-
En la opción Escalado y aprovisionamiento del clúster, seleccione Usar escalado administrado de EMR.

-
-
En la sección Configuración de software, introduzca la siguiente configuración para habilitar el escalador automático de Flink. Para los escenarios de prueba, defina el intervalo de decisión, el intervalo de la ventana de métricas y el intervalo de estabilización en un valor inferior para que el trabajo tome inmediatamente una decisión de escalado a fin de facilitar la verificación.
[ { "Classification": "flink-conf", "Properties": { "job.autoscaler.enabled": "true", "jobmanager.scheduler": "adaptive", "job.autoscaler.stabilization.interval": "60s", "job.autoscaler.metrics.window": "60s", "job.autoscaler.decision.interval": "10s", "job.autoscaler.debug.logs.interval": "60s" } } ] -
Seleccione o configure cualquier otro ajuste como prefiera y cree el clúster con escalador automático de Flink.
Configuraciones del escalador automático
En esta sección, se describe la mayoría de las configuraciones que puede cambiar en función de sus necesidades específicas.
nota
En el caso de configuraciones que se basan en el tiempo como time, interval y window, la unidad predeterminada es milisegundos cuando no se especifica ninguna. Por lo tanto, un valor de 30 sin sufijo equivale a 30 milisegundos. Para otras unidades de tiempo, incluya el sufijo correspondiente: s para segundos, m para minutos y h para horas.
Temas
Configuraciones de bucles del escalador automático
El escalador automático busca las métricas a nivel de vértice de trabajo para cada intervalo de tiempo configurable, las convierte en variables procesables a escala, estima el nuevo paralelismo entre los vértices de trabajo y lo recomienda al programador de trabajos. Las métricas se recopilan solo después del tiempo de reinicio del trabajo y del intervalo de estabilización del clúster.
| Clave de configuración | Valor predeterminado | Descripción | Valores de ejemplo |
|---|---|---|---|
job.autoscaler.enabled |
false |
Habilite el escalado automático en su clúster de Flink. | true, false |
job.autoscaler.decision.interval |
60s |
Intervalo de decisión del escalador automático. | 30 (la unidad predeterminada es milisegundos), 5m, 1h |
job.autoscaler.restart.time |
3m |
Se utilizará el tiempo de reinicio previsto hasta que el operador pueda determinarlo de forma fiable a partir del historial. | 30 (la unidad predeterminada es milisegundos), 5m, 1h |
job.autoscaler.stabilization.interval |
300s |
El periodo de estabilización en el que no se ejecutará ningún nuevo escalado. | 30 (la unidad predeterminada es milisegundos), 5m, 1h |
job.autoscaler.debug.logs.interval |
300s |
El intervalo de registros de depuración del escalador automático. | 30 (la unidad predeterminada es milisegundos), 5m, 1h |
Configuraciones de la agregación de métricas y el historial
El escalador automático busca las métricas, las agrega en una ventana deslizante basada en tiempo y las evalúa para tomar decisiones de escalado. El historial de decisiones de escalado de cada vértice de trabajo se utiliza para estimar el nuevo paralelismo. Estos valores tienen una fecha de vencimiento basada en la antigüedad y el tamaño del historial (al menos 1).
| Clave de configuración | Valor predeterminado | Descripción | Valores de ejemplo |
|---|---|---|---|
job.autoscaler.metrics.window |
600s |
Scaling metrics aggregation window size. |
30 (la unidad predeterminada es milisegundos), 5m, 1h |
job.autoscaler.history.max.count |
3 |
Número máximo de decisiones de escalado anteriores que se deben conservar por vértice. | De 1 a Integer.MAX_VALUE |
job.autoscaler.history.max.age |
24h |
Número mínimo de decisiones de escalado anteriores que se deben conservar por vértice. | 30 (la unidad predeterminada es milisegundos), 5m, 1h |
Configuraciones a nivel de vértice de trabajo
El paralelismo de cada vértice de trabajo se modifica en función del objetivo de utilización y está limitado por los límites de paralelismo mínimo-máximo. No se recomienda fijar el objetivo de utilización cerca del 100 % (es decir, un valor de 1), y el límite de utilización funciona como amortiguador para gestionar las fluctuaciones de carga intermedias.
| Clave de configuración | Valor predeterminado | Descripción | Valores de ejemplo |
|---|---|---|---|
job.autoscaler.target.utilization |
0.7 |
Objetivo de utilización del vértice. | 0 - 1 |
job.autoscaler.target.utilization.boundary |
0.4 |
Límite del objetivo de utilización del vértice. El escalado no se realizará si la velocidad de procesamiento actual está dentro de [target_rate /
(target_utilization - boundary) y (target_rate /
(target_utilization + boundary)]. |
0 - 1 |
job.autoscaler.vertex.min-parallelism |
1 |
El paralelismo mínimo que puede utilizar el escalador automático. | 0 - 200 |
job.autoscaler.vertex.max-parallelism |
200 |
El paralelismo máximo que puede utilizar el escalador automático. Tenga en cuenta que se ignorará este límite si es superior al paralelismo máximo establecido en la configuración de Flink o directamente en cada operador. | 0 - 200 |
Configuraciones de eventos de procesamiento pendientes
El vértice de trabajo necesita recursos adicionales para gestionar los eventos pendientes, o atrasados, que se acumulan durante el periodo de operación de escalado. Esto también se conoce como duración de catch-up. Si el tiempo de procesamiento del atraso supera el valor del lag -threshold configurado, el objetivo de utilización del vértice de trabajo aumenta hasta el nivel máximo. Esto ayuda a evitar operaciones de escalado innecesarias mientras se procesa la acumulación de eventos pendientes.
| Clave de configuración | Valor predeterminado | Descripción | Valores de ejemplo |
|---|---|---|---|
job.autoscaler.backlog-processing.lag-threshold |
5m |
Umbral de retraso que evitará escalados innecesarios y eliminará los mensajes pendientes responsables del retraso. | 30 (la unidad predeterminada es milisegundos), 5m, 1h |
job.autoscaler.catch-up.duration |
15m |
El tiempo objetivo para procesar por completo cualquier acumulación después de una operación de escalado. Configúrelo en 0 para deshabilitar el escalado que se basa en la acumulación de eventos. | 30 (la unidad predeterminada es milisegundos), 5m, 1h |
Configuraciones de operaciones de escala
El escalador automático no realiza la operación de reducción vertical inmediatamente después de una operación de escalado vertical dentro del periodo de gracia. Esto evita un ciclo innecesario de up-down-up-down operaciones de escalado provocado por fluctuaciones temporales de carga.
Podemos utilizar la relación de operaciones de reducción vertical para reducir gradualmente el paralelismo y liberar recursos a fin de hacer frente a los picos de carga temporales. Esto también ayuda a evitar una operación de escalado vertical menor innecesaria tras una operación de reducción vertical mayor.
Se puede detectar una operación de escalado vertical ineficaz según el historial de decisiones de escalado de vértices de trabajo anteriores para evitar nuevos cambios en el paralelismo.
| Clave de configuración | Valor predeterminado | Descripción | Valores de ejemplo |
|---|---|---|---|
job.autoscaler.scale-up.grace-period |
1h |
Duración durante la cual no se permite reducir verticalmente el tamaño de un vértice después de haberlo escalado verticalmente. | 30 (la unidad predeterminada es milisegundos), 5m, 1h |
job.autoscaler.scale-down.max-factor |
0.6 |
Factor máximo de reducción vertical. Un valor de 1 significa que no hay límite en la reducción vertical; 0.6 significa que el trabajo solo se puede reducir verticalmente con el 60 % del paralelismo original. |
0 - 1 |
job.autoscaler.scale-up.max-factor |
100000. |
Relación máxima de escalado vertical. Un valor de 2.0 significa que el trabajo solo se puede escalar verticalmente con el 200 % del paralelismo actual. |
0 - Integer.MAX_VALUE |
job.autoscaler.scaling.effectiveness.detection.enabled |
false |
Si se debe permitir la detección de operaciones de escalado ineficaces y permitir que el escalador automático bloquee nuevos escalados verticales. | true, false |
