Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Configuración de Flink en Amazon EMR
Configuración de Flink con el metaalmacén de Hive y el Catálogo de Glue
EMRLas versiones 6.9.0 y posteriores de Amazon son compatibles con Hive Metastore y AWS Glue Catalog con el conector Apache Flink a Hive. En esta sección se describen los pasos necesarios para configurar el Catálogo de AWS Glue y el metaalmacén de Hive con Flink.
Uso del metaalmacén de Hive
-
Cree un EMR clúster con la versión 6.9.0 o superior y al menos dos aplicaciones: Hive y Flink.
-
Utilice el ejecutor de scripts para ejecutar el siguiente script como una función escalonada:
hive-metastore-setup.shsudo cp /usr/lib/hive/lib/antlr-runtime-3.5.2.jar /usr/lib/flink/lib sudo cp /usr/lib/hive/lib/hive-exec-3.1.3*.jar /lib/flink/lib sudo cp /usr/lib/hive/lib/libfb303-0.9.3.jar /lib/flink/lib sudo cp /usr/lib/flink/opt/flink-connector-hive_2.12-1.15.2.jar /lib/flink/lib sudo chmod 755 /usr/lib/flink/lib/antlr-runtime-3.5.2.jar sudo chmod 755 /usr/lib/flink/lib/hive-exec-3.1.3*.jar sudo chmod 755 /usr/lib/flink/lib/libfb303-0.9.3.jar sudo chmod 755 /usr/lib/flink/lib/flink-connector-hive_2.12-1.15.2.jar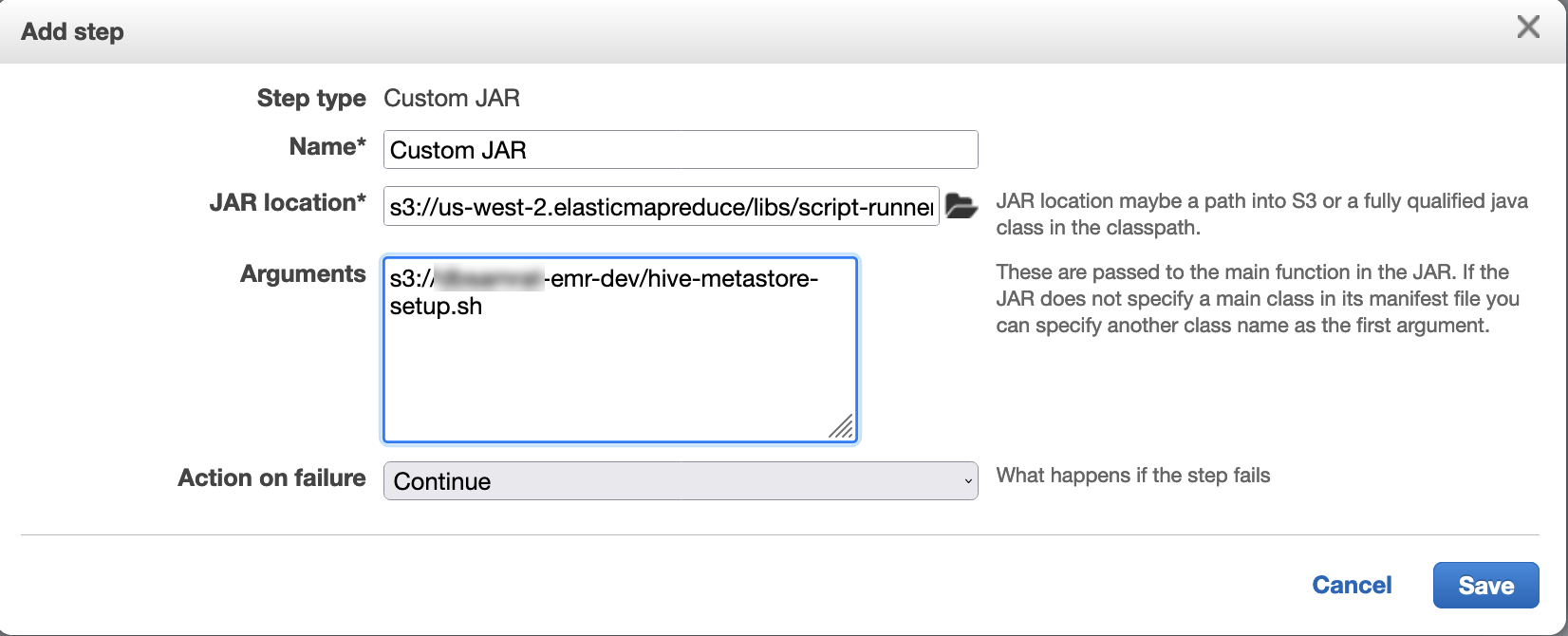
Utilice el catálogo de datos de AWS Glue
-
Cree un EMR clúster con la versión 6.9.0 o superior y al menos dos aplicaciones: Hive y Flink.
-
Seleccione Usar para metadatos de la tabla de Hive en la configuración del Catálogo de datos de AWS Glue para habilitar el Catálogo de datos en el clúster.
-
Usa el ejecutor de scripts para ejecutar el siguiente script como una función escalonada: Ejecuta comandos y scripts en un EMR clúster de Amazon:
glue-catalog-setup.sh
sudo cp /usr/lib/hive/auxlib/aws-glue-datacatalog-hive3-client.jar /usr/lib/flink/lib sudo cp /usr/lib/hive/lib/antlr-runtime-3.5.2.jar /usr/lib/flink/lib sudo cp /usr/lib/hive/lib/hive-exec-3.1.3*.jar /lib/flink/lib sudo cp /usr/lib/hive/lib/libfb303-0.9.3.jar /lib/flink/lib sudo cp /usr/lib/flink/opt/flink-connector-hive_2.12-1.15.2.jar /lib/flink/lib sudo chmod 755 /usr/lib/flink/lib/aws-glue-datacatalog-hive3-client.jar sudo chmod 755 /usr/lib/flink/lib/antlr-runtime-3.5.2.jar sudo chmod 755 /usr/lib/flink/lib/hive-exec-3.1.3*.jar sudo chmod 755 /usr/lib/flink/lib/libfb303-0.9.3.jar sudo chmod 755 /usr/lib/flink/lib/flink-connector-hive_2.12-1.15.2.jar
Configuración de Flink con un archivo de configuración
Puedes usar la EMR configuración de Amazon API para configurar Flink con un archivo de configuración. Los archivos que se pueden configurar en el API son:
-
flink-conf.yaml -
log4j.properties -
flink-log4j-session -
log4j-cli.properties
El archivo de configuración principal para Flink es flink-conf.yaml.
Para configurar el número de ranuras de tareas que se usan para Flink de la AWS CLI
-
Cree un archivo,
configurations.json, con el siguiente contenido:[ { "Classification": "flink-conf", "Properties": { "taskmanager.numberOfTaskSlots":"2" } } ] -
A continuación, cree un clúster con la siguiente configuración:
aws emr create-cluster --release-labelemr-7.3.0\ --applications Name=Flink \ --configurations file://./configurations.json \ --regionus-east-1\ --log-uri s3://myLogUri\ --instance-type m5.xlarge \ --instance-count2\ --service-role EMR_DefaultRole_V2 \ --ec2-attributes KeyName=YourKeyName,InstanceProfile=EMR_EC2_DefaultRole
nota
También puede cambiar algunas configuraciones con el FlinkAPI. Para obtener más información, consulte Conceptos
Con Amazon 5.21.0 y EMR versiones posteriores, puedes anular las configuraciones de los clústeres y especificar clasificaciones de configuración adicionales para cada grupo de instancias de un clúster en ejecución. Para ello, utilice la EMR consola de Amazon, el AWS Command Line Interface (AWS CLI) o el AWS SDK. Para obtener más información, consulte Suministrar una configuración para un grupo de instancias en un clúster en ejecución.
Opciones de paralelismo
Como propietario de la aplicación, conoce bien los recursos que asignar a las tareas en Flink. Para los ejemplos de esta documentación, utilice el mismo número de tareas que el de las tareas de instancias que utilice para la aplicación. En general, recomendamos este nivel inicial de paralelismo, pero también puede aumentar el grado de detalle del paralelismo con ranuras de tareas, que generalmente no deben superar el número de núcleos virtuales
Configurar Flink en un EMR clúster con varios nodos principales
Flink permanece disponible durante el proceso JobManager de conmutación por error del nodo principal en un EMR clúster de Amazon con varios nodos principales. A partir de Amazon EMR 5.28.0, la JobManager alta disponibilidad también se habilita automáticamente. No se necesita ninguna configuración manual.
Con EMR las versiones 5.27.0 o anteriores de Amazon, JobManager existe un único punto de fallo. Cuando se JobManager produce un error, pierde todos los estados de las tareas y no reanudará las tareas en ejecución. Puede habilitar la JobManager alta disponibilidad configurando el recuento de intentos de aplicación, los puntos de control y habilitándola ZooKeeper como almacenamiento de estado para Flink, como se muestra en el siguiente ejemplo:
[ { "Classification": "yarn-site", "Properties": { "yarn.resourcemanager.am.max-attempts": "10" } }, { "Classification": "flink-conf", "Properties": { "yarn.application-attempts": "10", "high-availability": "zookeeper", "high-availability.zookeeper.quorum": "%{hiera('hadoop::zk')}", "high-availability.storageDir": "hdfs:///user/flink/recovery", "high-availability.zookeeper.path.root": "/flink" } } ]
Debe configurar tanto el número máximo de intentos de servidor maestro de aplicaciones como el número máximo de YARN intentos de aplicación de Flink. Para obtener más información, consulte Configuración de la alta disponibilidad del YARN clúster
Configuración del tamaño del proceso de memoria
Para EMR las versiones de Amazon que utilizan Flink 1.11.x, debes configurar el tamaño total del proceso de memoria tanto para () como para JobManager (jobmanager.memory.process.size) in TaskManager. taskmanager.memory.process.size flink-conf.yaml Puede establecer estos valores configurando el clúster con la configuración API o eliminando manualmente los comentarios de estos campos mediante. SSH Flink proporciona los siguientes valores predeterminados.
-
jobmanager.memory.process.size: 1600 m -
taskmanager.memory.process.size: 1728 m
Para excluir el JVM metaespacio y la sobrecarga, utilice el tamaño total de la memoria de Flink () en lugar de. taskmanager.memory.flink.size taskmanager.memory.process.size El valor predeterminado de taskmanager.memory.process.size es 1280 m. No se recomienda establecer taskmanager.memory.process.size y taskmanager.memory.process.size.
Todas EMR las versiones de Amazon que usan Flink 1.12.0 y versiones posteriores tienen los valores predeterminados listados en el conjunto de código abierto para Flink como valores predeterminados en AmazonEMR, por lo que no necesitas configurarlos tú mismo.
Configuración del tamaño del archivo de salida del registro
Los contenedores de aplicaciones de Flink crean tres tipos de archivos de registro (archivos .out, archivos .log y archivos .err) y también escriben en ellos. Solo los archivos .err se comprimen y se eliminan del sistema de archivos, mientras que los archivos de registro .log y .out permanecen en el sistema de archivos. Para garantizar que estos archivos de salida se puedan administrar y que el clúster permanezca estable, puede configurar la rotación de registros en log4j.properties para establecer un número máximo de archivos y limitar sus tamaños.
Amazon, EMR versiones 5.30.0 y posteriores
A partir de Amazon EMR 5.30.0, Flink usa el marco de registro log4j2 con el nombre de clasificación de configuración. El siguiente ejemplo de configuración muestra flink-log4j. el formato log4j2.
[ { "Classification": "flink-log4j", "Properties": { "appender.main.name": "MainAppender", "appender.main.type": "RollingFile", "appender.main.append" : "false", "appender.main.fileName" : "${sys:log.file}", "appender.main.filePattern" : "${sys:log.file}.%i", "appender.main.layout.type" : "PatternLayout", "appender.main.layout.pattern" : "%d{yyyy-MM-dd HH:mm:ss,SSS} %-5p %-60c %x - %m%n", "appender.main.policies.type" : "Policies", "appender.main.policies.size.type" : "SizeBasedTriggeringPolicy", "appender.main.policies.size.size" : "100MB", "appender.main.strategy.type" : "DefaultRolloverStrategy", "appender.main.strategy.max" : "10" }, } ]
Amazon, EMR versiones 5.29.0 y anteriores
Con EMR las versiones 5.29.0 y anteriores de Amazon, Flink usa el marco de registro log4j. El siguiente ejemplo ilustra la siguiente configuración de un dominio de log4j.
[ { "Classification": "flink-log4j", "Properties": { "log4j.appender.file": "org.apache.log4j.RollingFileAppender", "log4j.appender.file.append":"true", # keep up to 4 files and each file size is limited to 100MB "log4j.appender.file.MaxFileSize":"100MB", "log4j.appender.file.MaxBackupIndex":4, "log4j.appender.file.layout":"org.apache.log4j.PatternLayout", "log4j.appender.file.layout.ConversionPattern":"%d{yyyy-MM-dd HH:mm:ss,SSS} %-5p %-60c %x - %m%n" }, } ]
Configuración de Flink para que se ejecute con Java 11
EMRLas versiones 6.12.0 y posteriores de Amazon proporcionan compatibilidad con el entorno de ejecución de Java 11 para Flink. En las siguientes secciones, se describe cómo configurar el clúster para proporcionar compatibilidad con el tiempo de ejecución de Java 11 a Flink.
Temas
Configuración de Flink para Java 11 al crear un clúster
Siga los siguientes pasos para crear un EMR clúster con Flink y Java 11 en tiempo de ejecución. El archivo de configuración en el que se agrega la compatibilidad con el tiempo de ejecución de Java 11 es flink-conf.yaml.
Configuración de Flink para Java 11 en un clúster en ejecución
Siga los siguientes pasos para actualizar un EMR clúster en ejecución con Flink y Java 11 Runtime. El archivo de configuración en el que se agrega la compatibilidad con el tiempo de ejecución de Java 11 es flink-conf.yaml.
Confirmación del tiempo de ejecución de Java para Flink en un clúster en ejecución
Para determinar el tiempo de ejecución de Java para un clúster en ejecución, inicie sesión en el nodo principal tal y SSH como se describe en Conectarse al nodo principal con SSH. A continuación, ejecute el siguiente comando:
ps -ef | grep flink
El comando ps con la opción -ef muestra una lista de todos los procesos en ejecución en el sistema. Puede filtrar esa salida con grep para encontrar menciones de la cadena flink. Revise el resultado para ver el valor del entorno de ejecución de Java (JRE),jre-XX. En la siguiente salida, jre-11 indica que se elige Java 11 en tiempo de ejecución para Flink.
flink 19130 1 0 09:17 ? 00:00:15 /usr/lib/jvm/jre-11/bin/java -Djava.io.tmpdir=/mnt/tmp -Dlog.file=/usr/lib/flink/log/flink-flink-historyserver-0-ip-172-31-32-127.log -Dlog4j.configuration=file:/usr/lib/flink/conf/log4j.properties -Dlog4j.configurationFile=file:/usr/lib/flink/conf/log4j.properties -Dlogback.configurationFile=file:/usr/lib/flink/conf/logback.xml -classpath /usr/lib/flink/lib/flink-cep-1.17.0.jar:/usr/lib/flink/lib/flink-connector-files-1.17.0.jar:/usr/lib/flink/lib/flink-csv-1.17.0.jar:/usr/lib/flink/lib/flink-json-1.17.0.jar:/usr/lib/flink/lib/flink-scala_2.12-1.17.0.jar:/usr/lib/flink/lib/flink-table-api-java-uber-1.17.0.jar:/usr/lib/flink/lib/flink-table-api-scala-bridge_2.12-1.17.0.
Como alternativa, inicie sesión en el nodo principal con un comando SSH flink-yarn-session -d e inicie una YARN sesión de Flink con él. El resultado muestra la máquina virtual Java (JVM) de Flink, java-11-amazon-corretto en el siguiente ejemplo:
2023-05-29 10:38:14,129 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: containerized.master.env.JAVA_HOME, /usr/lib/jvm/java-11-amazon-corretto.x86_64
