Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
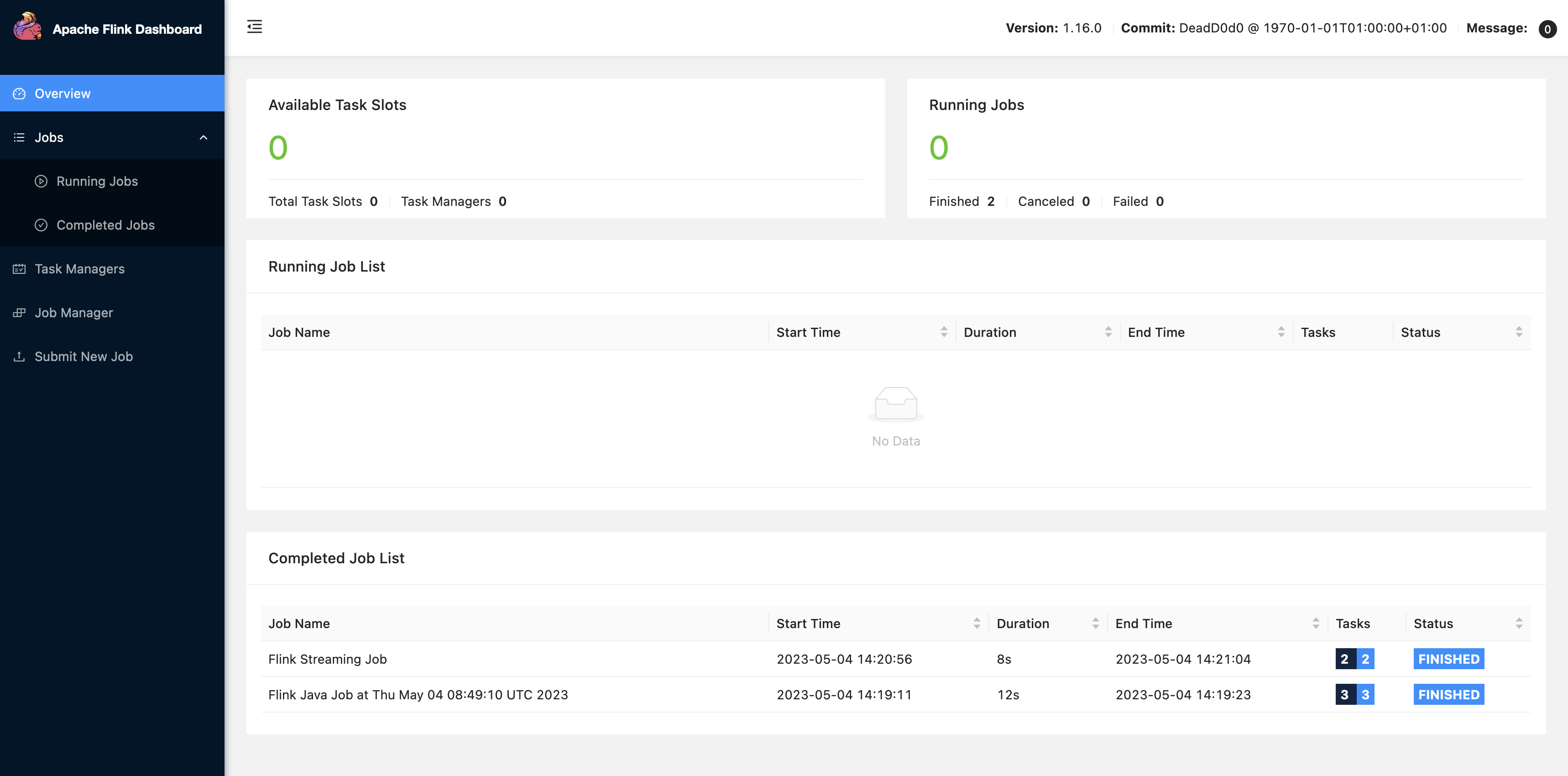
Trabajar con trabajos de Flink de Zeppelin en Amazon EMR
Introducción
Las versiones 6.10.0 y posteriores de Amazon EMR admiten la integración de Apache Zeppelin con Apache Flink. Puede enviar trabajos de Flink de forma interactiva a través de los cuadernos de Zeppelin. Con el intérprete de Flink, puede ejecutar consultas de Flink, definir los trabajos de streaming y lotes de Flink y visualizar el resultado en los cuadernos de Zeppelin. El intérprete de Flink se basa en la API de REST de Flink. Esto le permite acceder a los trabajos de Flink y manipularlos desde el entorno de Zeppelin para procesar y analizar los datos en tiempo real.
Hay cuatro subintérpretes en el intérprete de Flink. Tienen diferentes propósitos, pero todos están en la JVM y comparten los mismos puntos de entrada a Flink preconfigurados (ExecutionEnviroment, StreamExecutionEnvironment, BatchTableEnvironment, StreamTableEnvironment). Los intérpretes son los siguientes:
-
%flink: creaExecutionEnvironment,StreamExecutionEnvironment,BatchTableEnvironment,StreamTableEnvironmenty proporciona un entorno de Scala. -
%flink.pyflink: proporciona un entorno de Python. -
%flink.ssql: proporciona un entorno de SQL de streaming. -
%flink.bsql: proporciona un entorno de SQL de lotes.
Requisitos previos
-
La integración de Zeppelin con Flink es compatible con los clústeres creados con la versión 6.10.0 y posteriores de Amazon EMR.
-
Para ver las interfaces web que están alojadas en los clústeres de EMR como se requiere en estos pasos, debe configurar un túnel de SSH para permitir el acceso entrante. Para obtener más información, consulte Configurar ajustes de proxy para ver sitios web alojados en el nodo principal.
Configuración de Zeppelin-Flink en un clúster de EMR
Siga los siguientes pasos para configurar Apache Flink en Apache Zeppelin para que se ejecute en un clúster de EMR:
-
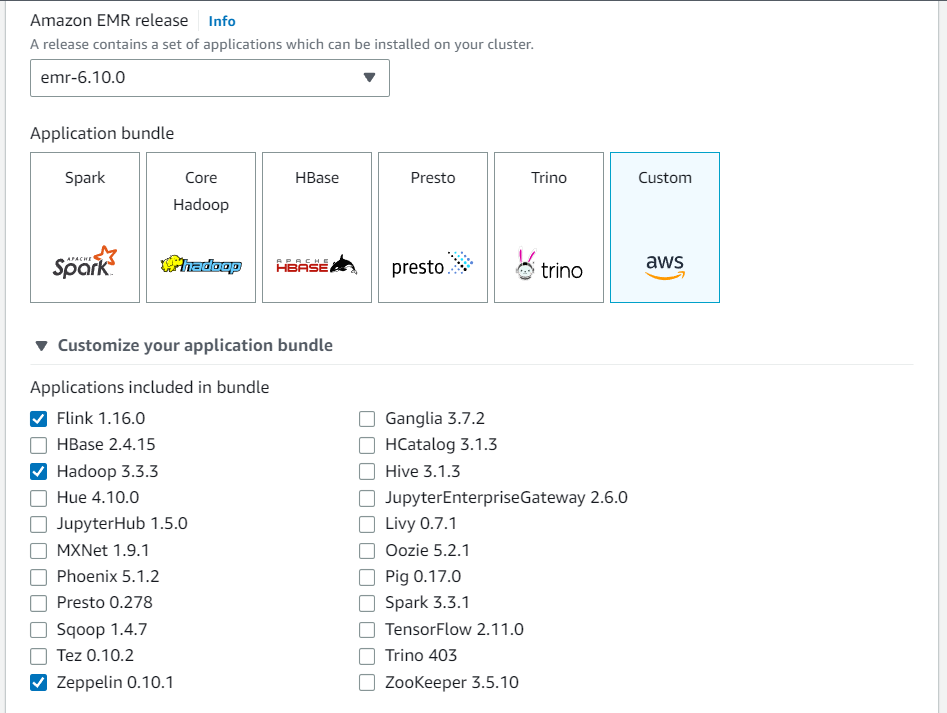
Cree un clúster nuevo desde la consola de Amazon EMR. Seleccione emr-6.10.0 o una versión posterior para la versión de Amazon EMR. A continuación, elija personalizar el paquete de aplicaciones con la opción Personalizado. Incluya al menos Flink, Hadoop y Zeppelin en su paquete.
-
Cree el resto del clúster con la configuración que prefiera.
-
Una vez que el clúster esté en ejecución, selecciónelo en la consola para ver sus detalles y abrir la pestaña Aplicaciones. Seleccione Zeppelin en la sección Interfaces de usuario de aplicaciones para abrir la interfaz web de Zeppelin. Asegúrese de haber configurado el acceso a la interfaz web de Zeppelin con un túnel de SSH al nodo principal y una conexión de proxy, tal y como se describe en Requisitos previos.
-
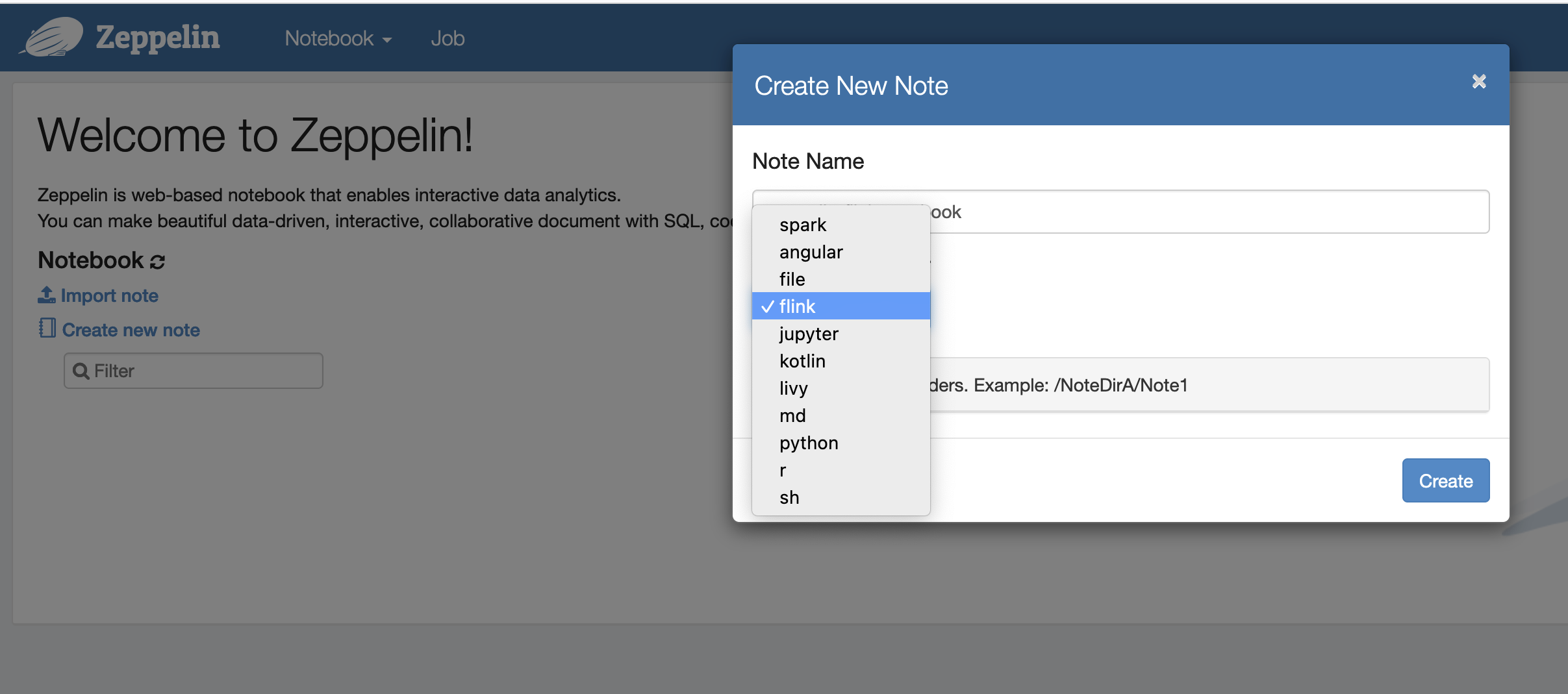
Ahora puede crear una nota nueva en un cuaderno de Zeppelin con Flink como intérprete predeterminado.
-
Consulte los siguientes ejemplos de código que muestran cómo ejecutar trabajos de Flink desde un cuaderno de Zeppelin.
Ejecución de trabajos de Flink con Zeppelin-Flink en un clúster de EMR
-
Ejemplo 1: Flink Scala
a) WordCount Ejemplo de lote (SCALA)
%flink val data = benv.fromElements("hello world", "hello flink", "hello hadoop") data.flatMap(line => line.split("\\s")) .map(w => (w, 1)) .groupBy(0) .sum(1) .print()b) WordCount Ejemplo de transmisión (SCALA)
%flink val data = senv.fromElements("hello world", "hello flink", "hello hadoop") data.flatMap(line => line.split("\\s")) .map(w => (w, 1)) .keyBy(0) .sum(1) .print senv.execute()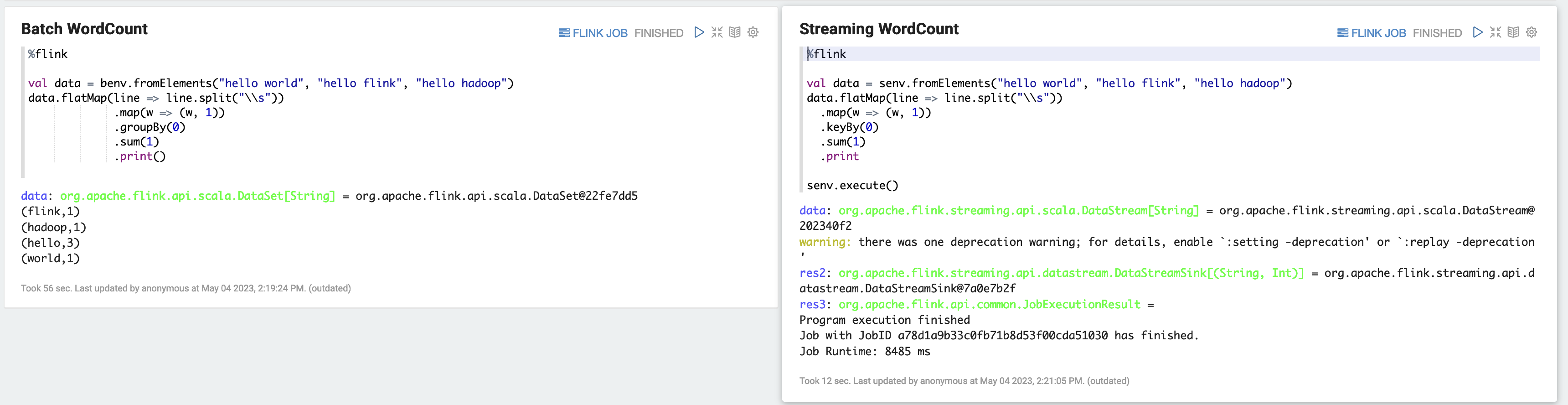
-
Ejemplo 2: SQL en streaming de Flink
%flink.ssql SET 'sql-client.execution.result-mode' = 'tableau'; SET 'table.dml-sync' = 'true'; SET 'execution.runtime-mode' = 'streaming'; create table dummy_table ( id int, data string ) with ( 'connector' = 'filesystem', 'path' = 's3://s3-bucket/dummy_table', 'format' = 'csv' ); INSERT INTO dummy_table SELECT * FROM (VALUES (1, 'Hello World'), (2, 'Hi'), (2, 'Hi'), (3, 'Hello'), (3, 'World'), (4, 'ADD'), (5, 'LINE')); SELECT * FROM dummy_table;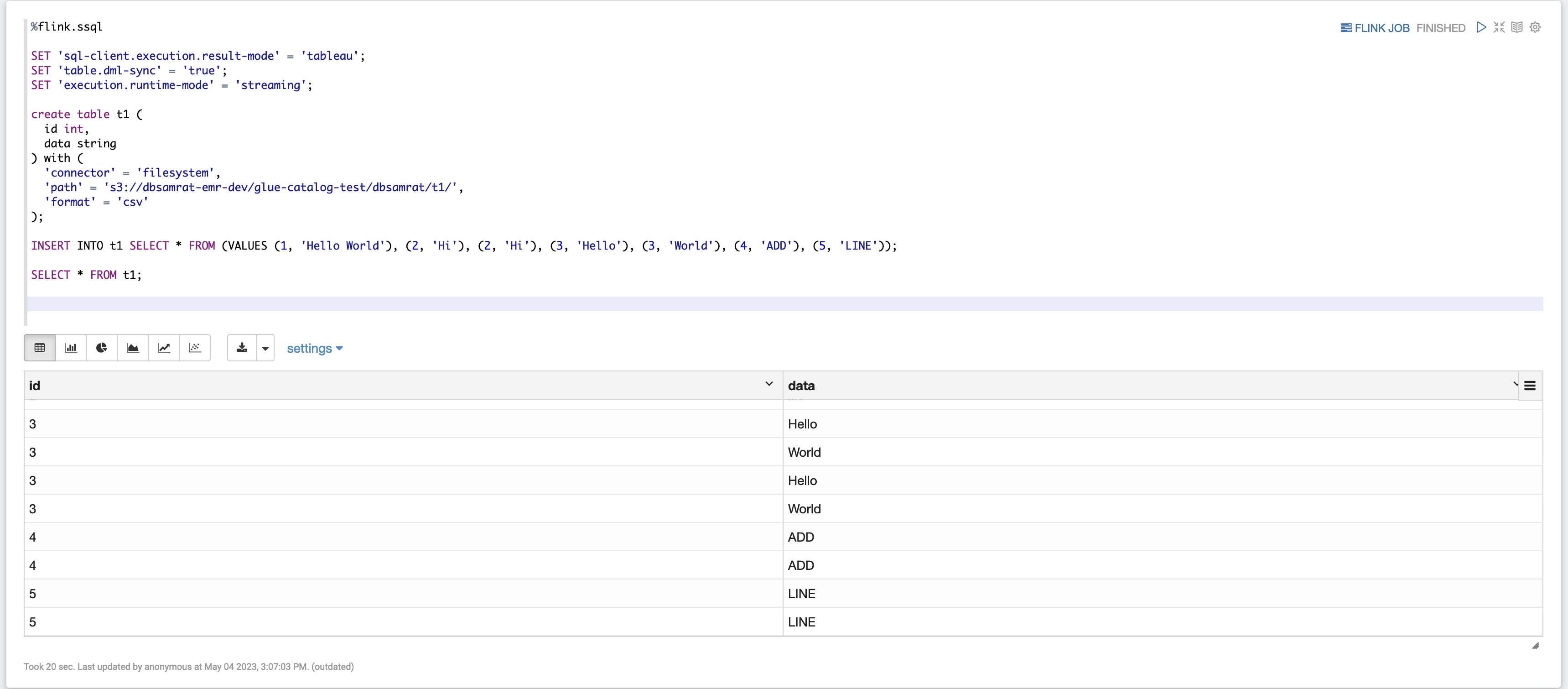
-
Ejemplo 3: Pyflink. Tenga en cuenta que debe cargar su propio archivo de texto de muestra
word.txtcon un nombre en su bucket de S3.%flink.pyflink import argparse import logging import sys from pyflink.common import Row from pyflink.table import (EnvironmentSettings, TableEnvironment, TableDescriptor, Schema, DataTypes, FormatDescriptor) from pyflink.table.expressions import lit, col from pyflink.table.udf import udtf def word_count(input_path, output_path): t_env = TableEnvironment.create(EnvironmentSettings.in_streaming_mode()) # write all the data to one file t_env.get_config().set("parallelism.default", "1") # define the source if input_path is not None: t_env.create_temporary_table( 'source', TableDescriptor.for_connector('filesystem') .schema(Schema.new_builder() .column('word', DataTypes.STRING()) .build()) .option('path', input_path) .format('csv') .build()) tab = t_env.from_path('source') else: print("Executing word_count example with default input data set.") print("Use --input to specify file input.") tab = t_env.from_elements(map(lambda i: (i,), word_count_data), DataTypes.ROW([DataTypes.FIELD('line', DataTypes.STRING())])) # define the sink if output_path is not None: t_env.create_temporary_table( 'sink', TableDescriptor.for_connector('filesystem') .schema(Schema.new_builder() .column('word', DataTypes.STRING()) .column('count', DataTypes.BIGINT()) .build()) .option('path', output_path) .format(FormatDescriptor.for_format('canal-json') .build()) .build()) else: print("Printing result to stdout. Use --output to specify output path.") t_env.create_temporary_table( 'sink', TableDescriptor.for_connector('print') .schema(Schema.new_builder() .column('word', DataTypes.STRING()) .column('count', DataTypes.BIGINT()) .build()) .build()) @udtf(result_types=[DataTypes.STRING()]) def split(line: Row): for s in line[0].split(): yield Row(s) # compute word count tab.flat_map(split).alias('word') \ .group_by(col('word')) \ .select(col('word'), lit(1).count) \ .execute_insert('sink') \ .wait() logging.basicConfig(stream=sys.stdout, level=logging.INFO, format="%(message)s") word_count("s3://s3_bucket/word.txt", "s3://s3_bucket/demo_output.txt")
-
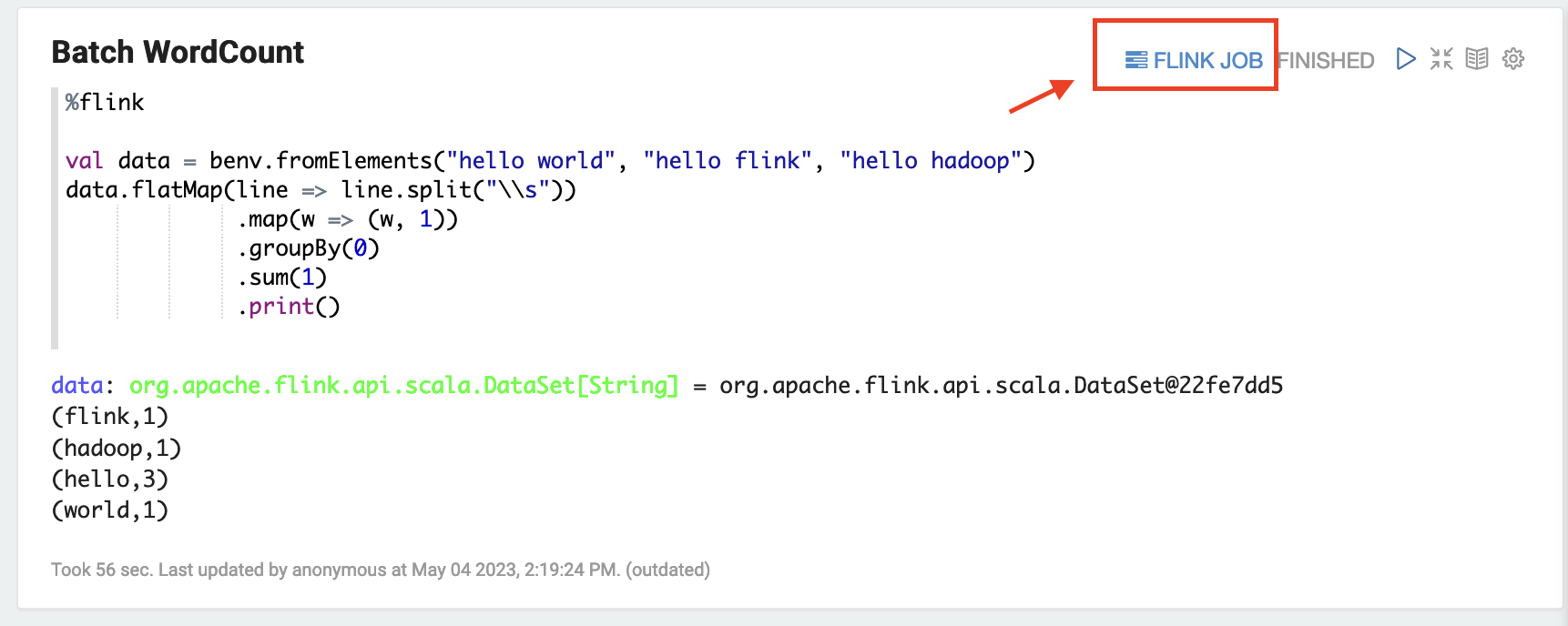
Elija FLINK JOB en la interfaz de usuario de Zeppelin para acceder a la interfaz de usuario web de Flink y verla.
-
Al elegir FLINK JOB, se accede a la consola web de Flink en otra pestaña del navegador.