Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Rendimiento de Amazon FSx para Lustre
En este capítulo, se proporcionan temas sobre el rendimiento de Amazon FSx para Lustre, incluidos algunos consejos y recomendaciones importantes para maximizar el rendimiento de su sistema de archivos.
Temas
Descripción general de
Amazon FSx para Lustre, basado en Lustre, el popular sistema de archivos de alto rendimiento, proporciona un rendimiento de escalado horizontal que aumenta linealmente con el tamaño del sistema de archivos. Los sistemas de archivos de Lustre escalan horizontalmente en múltiples servidores y discos de archivos. Este escalado proporciona a cada cliente acceso directo a los datos almacenados en cada disco para eliminar muchos de los cuellos de botella presentes en los sistemas de archivos tradicionales. Amazon FSx para Lustre se basa en la arquitectura escalable de Lustre para admitir altos niveles de rendimiento en un gran número de clientes.
Cómo funcionan los sistemas de archivos de FSx para Lustre
Cada sistema de archivos de FSx para Lustre consta de los servidores de archivos con los que se comunican los clientes y un conjunto de discos conectados a cada servidor de archivos que almacenan sus datos. Cada servidor de archivos emplea un caché en memoria rápido para mejorar el rendimiento de los datos a los que se accede con más frecuencia. Según la clase de almacenamiento, el servidor de archivos se puede aprovisionar con una caché de lectura de la SSD opcional. Cuando un cliente accede a los datos almacenados en la caché en memoria o SSD, el servidor de archivos no necesita leerlos del disco, lo que reduce la latencia y aumenta el rendimiento total que se puede obtener. El siguiente diagrama ilustra las rutas de una operación de escritura, una operación de lectura servida desde el disco y una operación de lectura servida desde la caché en memoria o SSD.
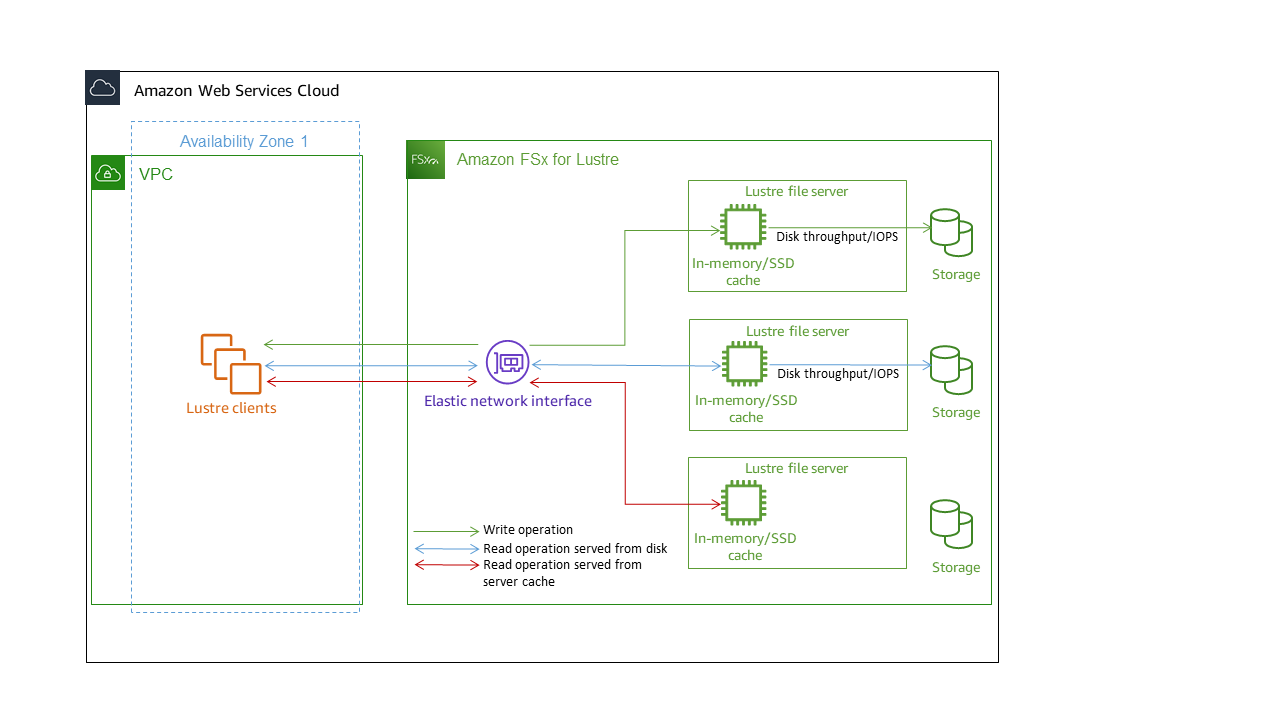
Cuando se leen datos almacenados en la caché en memoria o SSD del servidor de archivos, el rendimiento del sistema de archivos viene determinado por el rendimiento de la red. Cuando se escriben datos en el sistema de archivos, o cuando se leen datos que no están almacenados en la caché en memoria, el rendimiento del sistema de archivos viene determinado por el menor entre el rendimiento de la red y el rendimiento del disco.
Para obtener más información sobre el rendimiento de la red, el rendimiento del disco y las características de IOPS de las clases de almacenamiento SSD y HDD, consulte Características de rendimiento de las clases de almacenamiento en SSD y HDD y Características de rendimiento de la clase Intelligent-Tiering de almacenamiento.
Rendimiento de los metadatos del sistema de archivos
Las operaciones de E/S por segundo (IOPS) de los metadatos del sistema de archivos determinan la cantidad de archivos y directorios que puede crear, enumerar, leer y eliminar por segundo.
Los sistemas de archivos Persistent 2 le permiten aprovisionar las IOPS de metadatos independientemente de la capacidad de almacenamiento y proporcionan una mayor visibilidad de la cantidad y el tipo de IOPS de metadatos que incorporan las instancias de cliente al sistema de archivos. Con los sistemas de archivos SSD, las IOPS de metadatos se aprovisionan automáticamente en función de la capacidad de almacenamiento que aprovisione. Los sistemas de Intelligent-Tiering archivos no admiten el modo automático.
Con los sistemas de archivos Persistent 2 de FSx para Lustre, la cantidad de IOPS de metadatos que aprovisione y el tipo de operación de metadatos determinan la tasa de operaciones de metadatos que el sistema de archivos puede admitir. El nivel de IOPS de metadatos que aprovisione determina la cantidad de IOPS aprovisionadas para los discos de metadatos del sistema de archivos.
| Tipo de operación | Operaciones que puede realizar por segundo para cada IOPS de metadatos aprovisionadas |
|---|---|
|
Crear, abrir y cerrar archivos |
2 |
|
Eliminar archivos |
1 |
|
Crear y renombrar directorios |
0.1 |
|
Eliminar directorios |
0.2 |
En el caso de los sistemas de archivos SSD, puede elegir aprovisionar las IOPS de metadatos mediante el modo automático. En el modo automático, Amazon FSx aprovisiona IOPS de metadatos en función de la capacidad de almacenamiento del sistema de archivos de acuerdo con la siguiente tabla:
| Capacidad de almacenamiento del sistema de archivos | IOPS de metadatos incluidas en el modo automático |
|---|---|
|
1200 GiB |
1500 |
|
2400 GiB |
3 000 |
|
De 4800 a 9600 GiB |
6000 |
|
De 12 000 a 45 600 GiB |
12000 |
|
≥48 000 GiB |
12 000 IOPS por 24 000 GiB |
En el User-provisioned modo, si lo desea, puede optar por especificar el número de IOPS de metadatos que desea aprovisionar. Los valores válidos son los siguientes:
Para los sistemas de archivos SSD, los valores válidos son
1500,3000,6000,12000y múltiplos de12000, hasta un máximo de192000.Para los sistemas de Intelligent-Tiering archivos, los valores válidos son
6000y12000.
Para obtener información acerca de cómo configurar la IOPS de los metadatos, consulte Administración del rendimiento de los metadatos. Tenga en cuenta que usted paga por las IOPS de metadatos aprovisionadas por encima de la cantidad predeterminada de IOPS de metadatos en el sistema de archivos.
Rendimiento de las instancias de clientes individuales
Si va a crear un sistema de archivos con una capacidad de rendimiento superior a 10 GBps, le recomendamos que habilite Elastic Fabric Adapter (EFA) para optimizar el rendimiento por instancia de cliente. Para optimizar aún más el rendimiento por instancia de cliente, los sistemas de EFA-enabled archivos también admiten GPUDirect Storage para las instancias de GPU-based cliente de EFA-enabled NVIDIA y ENA Express para las instancias de cliente de ENA Express-enabled.
El rendimiento que puede transferir a una única instancia de cliente depende del tipo de sistema de archivos que elija y de la interfaz de red de la instancia de cliente.
| Tipo de sistema de archivos | Interfaz de red de la instancia de cliente | Rendimiento máximo por cliente, GBps |
|---|---|---|
|
No EFA-enabled |
Cualquiera |
100 GBps* |
|
EFA-enabled |
ENA |
100 GBps* |
|
EFA-enabled |
ENA Express |
100 Gbps |
|
EFA-enabled |
EFA |
700 Gbps |
|
EFA-enabled |
EFA con GDS |
1200 Gbps |
nota
* El tráfico entre una instancia de cliente individual y un servidor de almacenamiento de objetos FSx para Lustre individuales está limitado a 5 GBps. Consulte Direcciones IP para sistemas de archivos por el número de servidores de almacenamiento de objetos en los que se basa el sistema de archivos de FSx para Lustre.
Disposición de almacenamiento del sistema de archivos
Todos los datos de archivos de Lustre se almacenan en volúmenes de almacenamiento denominados destinos de almacenamiento de objetos (OST). Todos los metadatos de archivos (incluidos nombres de archivos, marcas de tiempo, permisos, etc.) se almacenan en volúmenes de almacenamiento llamados destinos de metadatos (MDT). Los sistemas de archivos de Amazon FSx para Lustre se componen de uno o más MDT y varios OST. Amazon FSx para Lustre distribuye sus datos de archivos entre los OST que componen su sistema de archivos para equilibrar la capacidad de almacenamiento con el rendimiento y la carga de IOPS.
Para ver el uso de almacenamiento de los MDT y OST que componen su sistema de archivos, ejecute el siguiente comando desde un cliente que tenga montado el sistema de archivos.
lfs df -hmount/path
El resultado de este comando tendrá un aspecto similar al siguiente.
ejemplo
UUID bytes Used Available Use% Mounted onmountname-MDT0000_UUID 68.7G 5.4M 68.7G 0% /fsx[MDT:0]mountname-OST0000_UUID 1.1T 4.5M 1.1T 0% /fsx[OST:0]mountname-OST0001_UUID 1.1T 4.5M 1.1T 0% /fsx[OST:1] filesystem_summary: 2.2T 9.0M 2.2T 0% /fsx
Fragmentación de datos en su sistema de archivos
Puede optimizar el rendimiento de su sistema de archivos con la fragmentación de archivos. Amazon FSx para Lustre distribuye automáticamente los archivos entre los OST para garantizar que los datos se sirven desde todos los servidores de almacenamiento. Puede aplicar el mismo concepto a nivel de archivo configurando cómo se distribuyen los archivos a través de múltiples OST.
Fragmentación significa que los archivos pueden ser divididos en múltiples trozos que son almacenados en diferentes OST. Cuando un archivo se divide en varios OST, las peticiones de lectura o escritura en el archivo se reparten entre esos OST, aumentando el rendimiento agregado o IOPS que sus aplicaciones pueden manejar a través de él.
Los siguientes son los diseños predeterminados de los sistemas de archivos de Amazon FSx para Lustre.
Para los sistemas de archivos creados antes del 18 de diciembre de 2020, el diseño predeterminado especifica el número de franjas de 1. Esto significa que, a menos que se especifique un diseño diferente, cada archivo creado en Amazon FSx para Lustre con las herramientas estándar de Linux se almacena en un único disco.
Para los sistemas de archivos creados después del 18 de diciembre de 2020, el diseño predeterminado es un diseño de archivos progresivo en el que los archivos de menos de 1 GB de tamaño se almacenan en una franja, y a los archivos de mayor tamaño se les asigna un número de fragmento de 5.
Para los sistemas de archivos creados después del 25 de agosto de 2023, la disposición por defecto es una disposición de archivos progresiva de 4 componentes que se explica en Disposición progresiva de archivos.
Para todos los sistemas de archivos, independientemente de su fecha de creación, los archivos importados de Amazon S3 no utilizan el diseño predeterminado, sino que utilizan el diseño del
ImportedFileChunkSizeparámetro del sistema de archivos. S3-imported los archivos con un tamaño superior al 1 seImportedFileChunkSizealmacenarán en varios OST con un recuento de franjas de(FileSize / ImportedFileChunksize) + 1. El valor predeterminado deImportedFileChunkSizees 1 GiB.
Puede ver la configuración de diseño de un archivo o directorio mediante el comando lfs getstripe.
lfs getstripepath/to/filename
Este comando indica el número de franjas, el tamaño y el desfase de fragmentos de un archivo. El número de franjas indica el número de OST en las que se divide el archivo. El tamaño de franja es la cantidad de datos continuos que se almacenan en un OST. El desplazamiento de franja es el índice del primer OST sobre el que se divide el archivo.
Modificar la configuración de franjas
Los parámetros de diseño de un archivo se establecen cuando se crea el archivo por primera vez. Utilice el comando lfs setstripe para crear un nuevo archivo vacío con una disposición específica.
lfs setstripefilename--stripe-countnumber_of_OSTs
El comando lfs setstripe afecta a la disposición de un nuevo archivo. Úselo para especificar la disposición de un archivo antes de crearlo. También puede definir una disposición para un directorio. Una vez establecida en un directorio, esa disposición se aplica a cada nuevo archivo añadido a ese directorio, pero no a los archivos existentes. Cualquier nuevo subdirectorio que cree también hereda la nueva disposición, que se aplica a los nuevos archivos o directorios que se creen dentro de ese subdirectorio.
Para modificar la disposición de un archivo existente, utilice el comando lfs migrate. Este comando copia el archivo según sea necesario para distribuir su contenido de acuerdo con la disposición que especifique en el comando. Por ejemplo, los archivos anexados o cuyo tamaño ha aumentado no cambian el número de franjas, por lo que hay que migrarlos para cambiar el diseño del archivo. Alternativamente, puede crear un nuevo archivo utilizando el comando lfs setstripe para especificar su distribución, copiar el contenido original en el nuevo archivo y cambiar el nombre del nuevo archivo para reemplazar el archivo original.
Puede haber casos en los que la configuración de la presentación por defecto no sea óptima para su carga de trabajo. Por ejemplo, un sistema de archivos con decenas de OST y una gran cantidad de archivos de varios gigabytes puede obtener un rendimiento superior al dividir los archivos en secciones superiores al valor de recuento de franjas predeterminado de cinco OST. La creación de archivos de gran tamaño con un número reducido de franjas puede provocar cuellos de botella en el I/O rendimiento y también provocar que los OST se llenen. En este caso, puede crear un directorio con un mayor número de franjas para estos archivos.
Es importante configurar un diseño de franjas para archivos grandes (especialmente para archivos de más de un gigabyte de tamaño) por las siguientes razones:
Mejora el rendimiento al permitir que varios OST y sus servidores asociados contribuyan con IOPS, ancho de banda de la red y recursos de CPU al leer y escribir archivos de gran tamaño.
Reduce la probabilidad de que un pequeño subconjunto de OST se convierta en puntos calientes que limiten el rendimiento general de la carga de trabajo.
Evita que un solo archivo grande llene un OST, lo que podría provocar errores de llenado del disco.
No existe una única configuración de distribución óptima para todos los casos de uso. Para obtener instrucciones detalladas sobre los diseños de los archivos, consulte Gestión del diseño de los archivos (división en bandas) y del espacio libre
El diseño de franjas es más importante para los archivos de gran tamaño, especialmente para los casos de uso en los que los archivos suelen tener un tamaño de cientos de megabytes o más. Por este motivo, el diseño predeterminado de un nuevo sistema de archivos asigna un recuento de franjas de cinco a los archivos de más de 1 GiB de tamaño.
El recuento de franjas es el parámetro de diseño que se debe ajustar para los sistemas que admiten archivos de gran tamaño. El recuento de franjas especifica el número de volúmenes OST que pueden contener fragmentos de un archivo segmentado. Por ejemplo, con un número de fragmentos de 2 y un tamaño de fragmento de 1 MiB, Lustre escribe porciones alternativas de 1 MiB de un archivo en cada una de las dos OST.
El número efectivo de franjas es el menor entre el número real de volúmenes OST y el valor del recuento de franjas que especifique. Puede utilizar el valor especial del recuento de franjas de
-1para indicar que las franjas deben colocarse en todos los volúmenes OST.Establecer un gran número de fragmentos para archivos pequeños no es óptimo, ya que, para algunas operaciones, Lustre requiere un recorrido de ida y vuelta en red a todos los OST del diseño, incluso si el archivo es demasiado pequeño para ocupar espacio en todos los volúmenes de OST.
Puede configurar una disposición progresiva de archivos (PFL) que permita que la disposición de un archivo cambie con el tamaño. Una configuración PFL puede simplificar la gestión de un sistema de archivos que tenga una combinación de archivos grandes y pequeños sin tener que establecer explícitamente una configuración para cada archivo. Para obtener más información, consulte Disposición progresiva de archivos.
El tamaño predeterminado de la banda es de 1 MiB. Definir un desfase de franjas puede resultar útil en circunstancias especiales, pero en general es mejor dejarlo sin especificar y utilizar el valor predeterminado.
Disposición progresiva de archivos
Puede especificar una configuración de diseño de archivos progresivo (PFL) para un directorio con el fin de especificar diferentes configuraciones de franjas para archivos pequeños y grandes antes de rellenarlo. Por ejemplo, puede establecer una PFL en el directorio de nivel superior antes de que se escriba cualquier dato en un nuevo sistema de archivos.
Para especificar una configuración de PFL, utilice el comando lfs setstripe con las opciones -E para especificar los componentes de disposición para archivos de diferentes tamaños, como el siguiente comando:
lfs setstripe -E 100M -c 1 -E 10G -c 8 -E 100G -c 16 -E -1 -c 32/mountname/directory
Este comando establece cuatro componentes de disposición:
El primer componente (
-E 100M -c 1) indica un valor de recuento de franjas de 1 para archivos de un tamaño máximo de 100 MiB.El segundo componente (
-E 10G -c 8) indica un recuento de franjas de 8 para archivos de hasta 10 GiB de tamaño.El tercer componente (
-E 100G -c 16) indica un recuento de franjas de 16 para archivos de hasta 100 GiB de tamaño.El cuarto componente (
-E -1 -c 32) indica un recuento de franjas de 32 para archivos de más de 100 GiB.
importante
Si se agregan datos a un archivo creado con una configuración PFL, se rellenarán todos sus componentes de diseño. Por ejemplo, con el comando de 4 componentes mostrado arriba, si crea un archivo de 1 MiB y luego agrega datos al final del archivo, el diseño del archivo se expandirá para tener un conteo de franjas de -1, es decir, todos los OST en el sistema. Esto no significa que se escribirán datos en cada OST, pero una operación como la lectura de la longitud del fichero enviará una petición en paralelo a cada OST, añadiendo una carga de red significativa al sistema de archivos.
Por lo tanto, tenga cuidado de limitar el número de franjas para cualquier archivo de longitud pequeña o mediana al que posteriormente se le puedan agregar datos. Dado que los archivos de registro suelen crecer al añadirse nuevos registros, Amazon FSx para Lustre asigna un recuento de franjas predeterminado de 1 a cualquier archivo creado en modo de adición, independientemente de la configuración de franjas predeterminada especificada por su directorio principal.
La configuración de PFL predeterminada para los sistemas de archivos en Amazon FSx para Lustre creados después del 25 de agosto de 2023 se establece con este comando:
lfs setstripe -E 100M -c 1 -E 10G -c 8 -E 100G -c 16 -E -1 -c 32/mountname
Los clientes con cargas de trabajo que tienen un acceso altamente concurrente en archivos medianos y grandes probablemente se beneficien de una disposición con más franjas en tamaños más pequeños y franjas en todos los OST para los archivos más grandes, como se muestra en la disposición de ejemplo de cuatro componentes.
Supervisión del rendimiento y uso
Cada minuto, Amazon FSx for Lustre envía métricas de uso de cada disco (MDT y OST) a Amazon. CloudWatch
Para ver los detalles de uso agregados del sistema de archivos, puede consultar la estadística Suma de cada métrica. Por ejemplo, la suma de la estadística DataReadBytes indica el rendimiento total de lectura observado por todos los OST de un sistema de archivos. Del mismo modo, la suma de la estadística FreeDataStorageCapacity indica la capacidad total de almacenamiento disponible para los datos de los archivos en el sistema de archivos.
Para obtener más información sobre la supervisión del rendimiento del sistema de archivos, consulte Supervisión de sistemas de archivos de Amazon FSx para Lustre.
