Tutorial: uso de un cuaderno de IA de SageMaker con su punto de conexión de desarrollo
En AWS Glue, puede crear un punto de conexión de desarrollo y, a continuación, crear un cuaderno de IA de SageMaker para desarrollar sus scripts de machine learning y ETL. Un cuaderno de IA de SageMaker es una instancia de computación de machine learning completamente administrada que ejecuta la aplicación Cuaderno de Jupyter.
-
En la consola de AWS Glue, seleccione Puntos de enlace de desarrollo para ir a la lista de puntos de enlace de desarrollo.
-
Seleccione la casilla situada junto al nombre de un punto de enlace de desarrollo que desee utilizar y, en el menú Action (Acción), elija Create SageMaker notebook (Crear bloc de notas de SageMaker).
-
Rellene la página Create and configure a notebook (Crear y configurar un bloc de notas) como se indica a continuación:
-
Escriba un nombre para el bloc de notas.
-
En Attach to development endpoint (Asociar a un punto de enlace de desarrollo), verifique el punto de enlace de desarrollo.
-
Elija crear un rol AWS Identity and Access Management (IAM).
Se recomienda crear un rol. Si utiliza un rol existente, asegúrese de que tiene los permisos necesarios. Para obtener más información, consulte Paso 6: Crear una política de IAM para cuadernos de IA de SageMaker.
-
(Opcional) Elija una VPC, una subred y uno o varios grupos de seguridad.
-
(Opcional) Elija una clave de cifrado de AWS Key Management Service.
-
(Opcional) Añada etiquetas para la instancia de bloc de notas.
-
-
Elija Crear cuaderno. En la página Notebooks (Blocs de notas), elija el icono de actualización que aparece en la parte superior derecha y continúe hasta que el Status (Estado) aparezca como
Ready. -
Seleccione la casilla situada junto al nombre del bloc de notas nuevo y, a continuación, elija Open notebook (Abrir bloc de notas).
-
Cree un bloc de notas nuevo: en la página de jupyter, elija New (Nuevo) y, a continuación, seleccione Sparkmagic (PySpark).
La pantalla que aparece debe ser similar a la siguiente:
-
(Opcional) En la parte superior de la página, elija Untitled (Sin título) y asigne un nombre al bloc de notas.
-
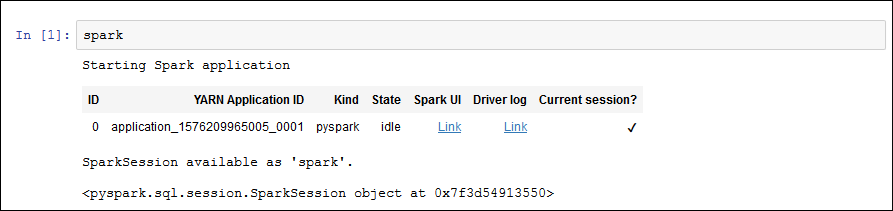
Para iniciar una aplicación de Spark, escriba el comando siguiente en el bloc de notas y, a continuación, elija Run (Ejecutar) en la barra de herramientas.
sparkDespués de un breve intervalo, debería ver la respuesta siguiente:
-
Cree un marco dinámico y ejecute una consulta en él: copie, pegue y ejecute el código siguiente, que genera el recuento y el esquema de la tabla
persons_json.import sys from pyspark.context import SparkContext from awsglue.context import GlueContext from awsglue.transforms import * glueContext = GlueContext(SparkContext.getOrCreate()) persons_DyF = glueContext.create_dynamic_frame.from_catalog(database="legislators", table_name="persons_json") print ("Count: ", persons_DyF.count()) persons_DyF.printSchema()
