Tutorial: Cómo escribir un script ETL en AWS Glue para Ray
importante
AWS Glue para Ray ya no está abierto a nuevos clientes. Los clientes existentes pueden seguir utilizando el servicio con normalidad. Para obtener más información, consulte Finalización del soporte de AWS Glue para Ray.
Ray permite escribir y escalar tareas distribuidas de forma nativa en Python. AWS Glue para Ray ofrece entornos de Ray sin servidor a los que puede acceder tanto desde ambos trabajos y sesiones interactivas (las sesiones interactivas de Ray están en versión preliminar). El sistema de trabajo de AWS Glue proporciona una forma coherente de administrar y ejecutar las tareas de forma programada, mediante un disparador o desde la consola de AWS Glue.
La combinación de estas herramientas de AWS Glue crea una poderosa cadena de herramientas que puede usar para la extracción, transformación y carga (ETL) de cargas de trabajo, un caso de uso popular para AWS Glue. En este tutorial, aprenderá los conceptos básicos de la creación de esta solución.
También admitimos el uso de AWS Glue para Spark para sus cargas de trabajo de ETL. Para obtener acceso a un tutorial acerca de la escritura de un script de AWS Glue para Spark, consulte Tutorial: Escritura de un script de Glue for Spark AWS. Para obtener más información sobre los motores disponibles, consulte AWS Glue para Spark y AWS Glue para Ray. Ray es capaz de abordar muchos tipos diferentes de tareas en los ámbitos de la analítica, machine learning y el desarrollo de aplicaciones.
En este tutorial, extraerá, transformará y cargará un conjunto de datos de CSV alojado en Amazon Simple Storage Service (Amazon S3). Empezará con el conjunto de datos de registros de viajes de la Comisión de Taxis y Limusinas de Nueva York (TLC), que se almacena en un bucket público de Amazon S3. Para obtener más información sobre este conjunto de datos, consulte el Registro de datos abiertos
Transformará sus datos con transformaciones predefinidas disponibles en la biblioteca Ray Data. Ray Data es una biblioteca de preparación de conjuntos de datos diseñada por Ray e incluida de forma predeterminada en los entornos de AWS Glue para Ray. Para obtener más información sobre las bibliotecas incluidad de forma predeterminada, consulte Módulos incluidos con los trabajos de Ray. A continuación, escribirá los datos transformados en un bucket de Amazon S3 que usted controle.
Requisitos previos: para este tutorial, necesita una cuenta de AWS con acceso a AWS Glue y a Amazon S3.
Paso 1: crear un bucket en Amazon S3 para almacenar los datos de salida
Necesitará un bucket de Amazon S3 que pueda controlar para que sirva de depósito de los datos creados en este tutorial. Puede crear este bucket mediante el siguiente procedimiento.
nota
Si quiere escribir sus datos en un bucket existente que usted controla, puede omitir este paso. Tome nota de yourBucketName, el nombre del bucket existente, para usarlo en pasos posteriores.
Para crear un bucket para la salida del trabajo de Ray
-
Para crear un bucket, siga los pasos que se indican en Crear un bucket en la Guía del usuario de Amazon S3.
-
Cuando elija el nombre de un bucket, tome nota de
yourBucketName, que consultará en pasos posteriores. -
Para otras configuraciones, la configuración sugerida que se proporciona en la consola de Amazon S3 debería funcionar correctamente en este tutorial.
Por ejemplo, el cuadro de diálogo de creación del bucket podría tener este aspecto en la consola de Amazon S3.
-
Paso 2: crear una política y rol de IAM para su trabajo de Ray
Su trabajo necesitará un rol de AWS Identity and Access Management (IAM) con lo siguiente:
-
Permisos otorgados por la política administrada de
AWSGlueServiceRole. Estos son los permisos básicos necesarios para ejecutar un trabajo de AWS Glue. -
Readlos permisos de nivel de acceso para el recurso de Amazon S3nyc-tlc/*. -
Writelos permisos de nivel de acceso para el recurso de Amazon S3yourBucketName/* -
Una relación de confianza que permite a la entidad principal
glue.amazonaws.com.rproxy.goskope.comasumir el rol.
Puede crear este rol mediante el siguiente procedimiento.
Crear un rol de IAM para su trabajo de AWS Glue para Ray
nota
Puede seguir muchos procedimientos diferentes para crear un rol de IAM. Para obtener más información u opciones sobre cómo aprovisionar los recursos de IAM, consulte la documentación de AWS Identity and Access Management.
-
Cree una política que defina los permisos de Amazon S3 descritos anteriormente mediante los pasos que aparecen en Creación de políticas de IAM (consola) con el editor visual en la Guía del usuario de IAM.
-
Cuando seleccione un servicio, elija Amazon S3.
-
Cuando seleccione los permisos para su política, adjunte los siguientes conjuntos de acciones para los siguientes recursos (mencionados anteriormente):
-
Lea los permisos de nivel de acceso para el recurso de Amazon S3
nyc-tlc/*. -
Escriba los permisos de nivel de acceso para el recurso de Amazon S3
yourBucketName/*
-
-
Cuando seleccione el nombre de la política, tome nota de
YourPolicyName, que consultará en un paso posterior.
-
-
Cree un rol para su trabajo de AWS Glue para Ray; para ello, siga los pasos que se indican en Crear un rol para un servicio de AWS (consola) en la Guía del usuario de IAM.
-
Cuando seleccione una entidad de servicio AWS de confianza, elija
Glue. Esto completará automáticamente la relación de confianza necesaria para su trabajo. -
Cuando seleccione políticas para la política de permisos, adjunte las siguientes políticas:
-
AWSGlueServiceRole -
YourPolicyName
-
-
Cuando seleccione el nombre del rol, tome nota de
YourRoleName, que consultará en pasos posteriores.
-
Paso 3: crear y ejecutar un trabajo de AWS Glue para Ray
En este paso, usted crea un trabajo de AWS Glue mediante la Consola de administración de AWS, proporciona un script de ejemplo y ejecuta el trabajo. Cuando crea un trabajo, se crea un lugar en la consola para que usted almacene, configure y edite el script de Ray. Para obtener más información acerca de la creación de trabajos, consulte Administración de trabajos de AWS Glue en la consola de AWS.
En este tutorial, abordamos el siguiente escenario de ETL: lea los registros de enero de 2022 del conjunto de datos de Registros de viajes de TLC de New York City, agregue una nueva columna (tip_rate) al conjunto de datos mediante la combinación de datos en las columnas existentes; luego, elimine la cantidad de columnas que no sean relevantes para el análisis actual y, a continuación, escriba los resultados en yourBucketName. El siguiente script de Ray lleva a cabo estos pasos:
import ray import pandas from ray import data ray.init('auto') ds = ray.data.read_csv("s3://nyc-tlc/opendata_repo/opendata_webconvert/yellow/yellow_tripdata_2022-01.csv") # Add the given new column to the dataset and show the sample record after adding a new column ds = ds.add_column( "tip_rate", lambda df: df["tip_amount"] / df["total_amount"]) # Dropping few columns from the underlying Dataset ds = ds.drop_columns(["payment_type", "fare_amount", "extra", "tolls_amount", "improvement_surcharge"]) ds.write_parquet("s3://yourBucketName/ray/tutorial/output/")
Para crear y ejecutar un trabajo de AWS Glue para Ray
-
En la Consola de administración de AWS, vaya a la página de inicio de AWS Glue.
-
En el panel de navegación lateral, seleccione Trabajos de ETL.
-
En Crear trabajo, elija Editor de script de Ray y, a continuación, elija Crear, como se muestra en la siguiente ilustración.
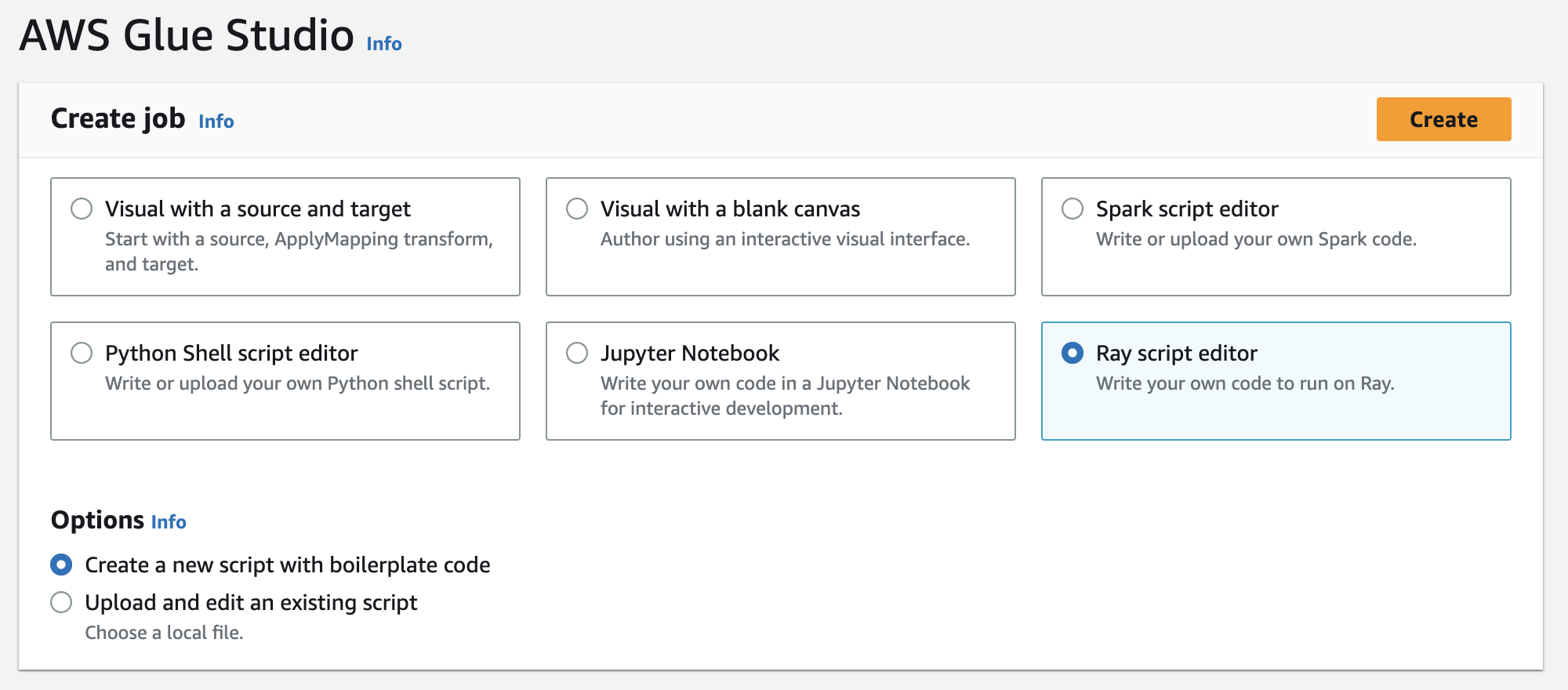
-
Pegue el texto completo del script en el panel Script y sustituya el texto existente.
-
Vaya a Detalles del trabajo y configure la propiedad de rol de IAM en
YourRoleName. -
Elija Guardar y, a continuación, elija Ejecutar.
Paso 4: inspeccionar la salida
Después de ejecutar su trabajo de AWS Glue, debe validar que el resultado cumpla con las expectativas de este escenario. Puede hacerlo mediante el siguiente procedimiento.
Para validar si su trabajo de Ray se ejecutó correctamente
-
En la página de detalles del trabajo, vaya a Ejecuciones.
-
Después de unos minutos, debería ver una ejecución con el Estado de ejecución como Correcto.
-
Vaya a la consola de Amazon S3 en https://console.aws.amazon.com/s3/
e inspeccione yourBucketName. Debería ver los archivos escritos en su bucket de salida. -
Lea los archivos de Parquet y verifique su contenido. Puede hacerlo con las herramientas existentes. Si no dispone de un proceso para validar los archivos de Parquet, puede hacerlo en la consola de AWS Glue mediante una sesión interactiva de AWS Glue, con Spark o Ray (versión preliminar).
En una sesión interactiva, tiene acceso a las bibliotecas Ray Data, Spark o pandas, que se proporcionan de forma predeterminada (según el motor que elija). Para verificar el contenido del archivo, puede usar los métodos de inspección habituales disponibles en esas bibliotecas, como
count,schemayshow. Para obtener más información sobre las sesiones interactivas en la consola, consulte Uso de cuaderno con AWS Glue Studio y AWS Glue.Como ha confirmado que los archivos se han escrito en el bucket, puede decir con relativa certeza que si el resultado tiene problemas, no están relacionados con la configuración de IAM. Configure su sesión con
YourRoleNamepara tener acceso a los archivos pertinentes.
Si no ve los resultados esperados, examine el contenido de resolución de problemas que aparecen en esta guía para identificar y corregir el origen del error. Encontrará el contenido sobre la resolución de problemas en el capítulo Resolución de problemas de AWS Glue. Para ver errores específicos relacionados con los trabajos de Ray, consulte Solución de problemas AWS Glue de errores de Ray en los registros en el capítulo sobre resolución de problemas.
Siguientes pasos
Ya ha visto y realizado un proceso de ETL mediante AWS Glue para Ray de principio a fin. Puede utilizar los siguientes recursos a fin de comprender qué herramientas proporciona AWS Glue para Ray para transformar e interpretar sus datos a escala.
-
Para obtener más información sobre este tema, consulte Uso de Ray Core y Ray Data en AWS Glue para Ray. Para obtener más experiencia en el uso de las tareas de Ray, siga los ejemplos que aparecen en la documentación de Ray Core. Consulte Ray Core: Ray Tutorials and Examples (2.4.0)
en la documentación de Ray. -
Para obtener información sobre las bibliotecas de administración de datos disponibles en AWS Glue para Ray, consulte Conexión a los datos de los trabajos de Ray. Para obtener más experiencia en el uso de Ray Data para transformar y escribir conjuntos de datos, siga los ejemplos que aparecen en la documentación de Ray Data. Consulte Ray Data: Examples (2.4.0
). -
Para obtener más información sobre la configuración de trabajos de AWS Glue para Ray, consulte Trabajar con tareas de Ray en AWS Glue.
-
Para obtener más información sobre cómo escribir scripts de AWS Glue para Ray, continúe leyendo la documentación de esta sección.
