Migrar programas de Apache Spark a AWS Glue
Apache Spark es una plataforma de código abierto para cargas de trabajo de computación distribuidas que se realizan en conjuntos de datos de gran tamaño. AWS Glue aprovecha las capacidades de Spark para ofrecer una experiencia de ETL optimizada. Puede migrar programas de Spark a AWS Glue para aprovechar nuestras características. AWS Glue proporciona las mismas mejoras de rendimiento que cabría esperar de Apache Spark en Amazon EMR.
Ejecutar código Spark
El código nativo Spark se puede ejecutar en un entorno de AWS Glue directamente. Los scripts a menudo se desarrollan al cambiar iterativamente un fragmento de código, un flujo de trabajo adecuado para una sesión interactiva. No obstante, el código existente es más adecuado para su ejecución en un trabajo de AWS Glue, que permite programar y obtener sistemáticamente registros y métricas para cada ejecución de script. Puede cargar y editar un script existente mediante la consola.
-
Adquiera el origen de su script. Para este ejemplo, utilizará un script de muestra del repositorio de Apache Spark. Ejemplo de binarizer
-
En la consola de AWS Glue, expanda el panel de navegación izquierdo y seleccione ETL > Jobs (Trabajos)
En el panel Create job (Crear trabajo), seleccioneSpark script editor (Editor de scripts de Spark). Aparecerá la sección Options (Opciones). En Options (Opciones), elija Upload and edit an existing script (Cargar y editar un script existente).
Aparecerá la sección File upload (Cargar archivo). En File upload (Cargar archivo), haga clic en Choose file (Elegir archivo). Aparecerá el selector de archivos del sistema. Vaya hasta la ubicación donde guardó
binarizer_example.py, selecciónelo y confirme la opción elegida.Aparecerá el botón Create (Crear) en el encabezado del panel Create job (Crear trabajo). Haga clic allí.
-
El navegador irá hasta el editor de scripts. En el encabezado, haga clic en la pestaña Job details (Detalles del trabajo). Defina el nombre y el Rol de IAM. Para obtener información sobre los roles de IAM de AWS Glue, consulte Configuración de permisos de IAM para AWS Glue.
Opcionalmente: configure Requested number of workers (Cantidad solicitada de trabajadores) en
2y Number of retries (Cantidad de reintentos) en1. Estas opciones son valiosas a la hora de ejecutar trabajos de producción, pero rechazarlas agilizará la experiencia mientras prueba una función.En la barra de navegación, haga clic en Save (Guardar), luego en Run (Ejecutar)
-
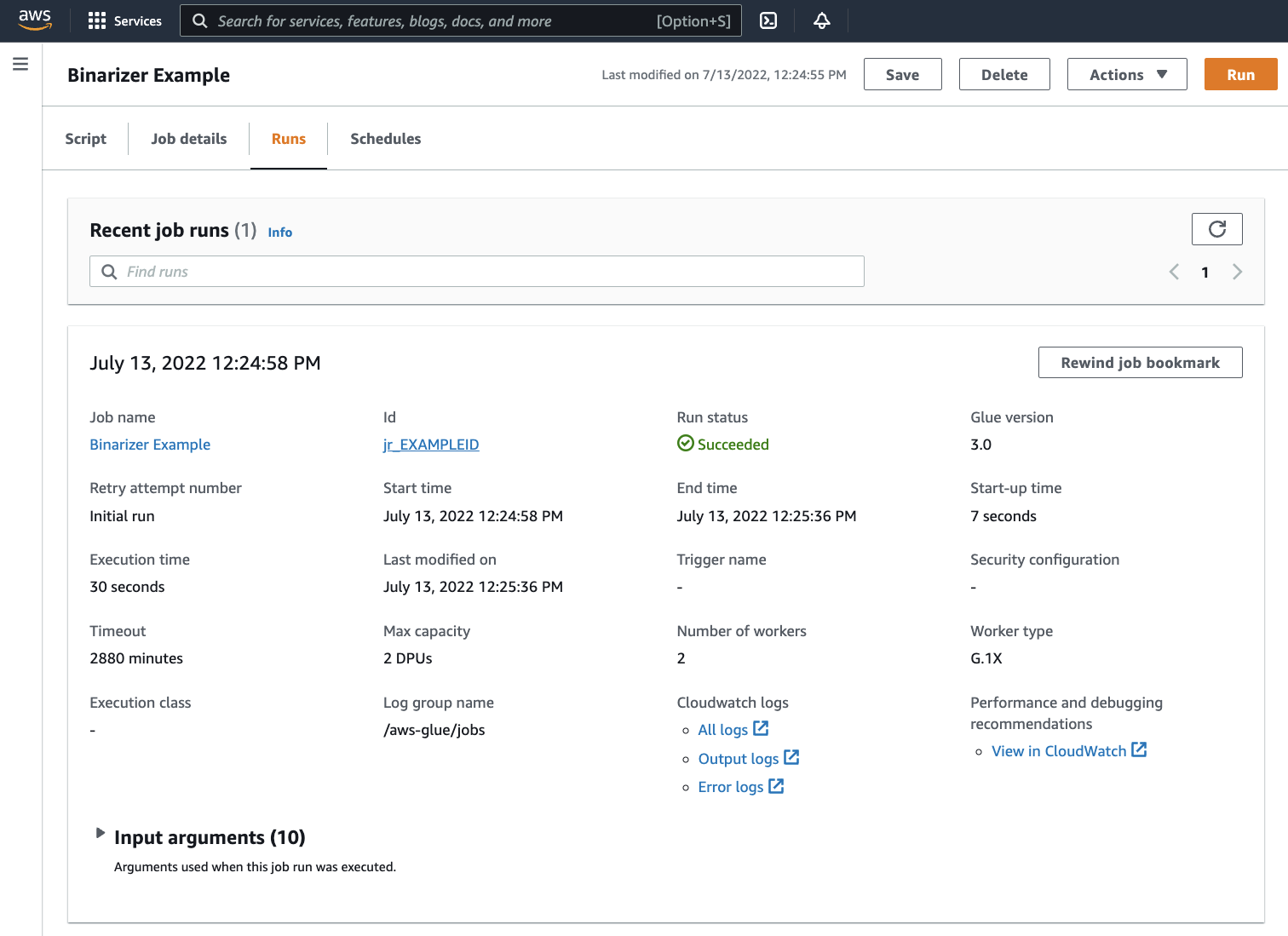
Vaya a la pestaña Runs (Ejecuciones). Verá un panel correspondiente a la ejecución de su trabajo. Espere unos minutos y la página deberá actualizarse automáticamente para mostrar Succeeded (Exitoso) en Run status (Estado de la ejecución).
-
Deberá examinar la salida para confirmar que el script de Spark se ejecutó según lo previsto. Este script de ejemplo de Apache Spark debe escribir una cadena en la secuencia de salida. Puede encontrarlo yendo a Output logs (Registros de salida) en Registros de Cloudwatch (Cloudwatch logs) en el panel para la ejecución correcta del trabajo. Tenga en cuenta el id de ejecución de trabajo, un id generado en la etiqueta Id (Identificador) que comienza con
jr_.Esto abrirá la consola de CloudWatch, configurada para visualizar el contenido del AWS Gluegrupo de registro
/aws-glue/jobs/outputpredeterminado, filtrado al contenido de los flujos de registro para el identificador de ejecución del trabajo. Cada trabajador habrá generado un flujo de registro, que se muestra como filas en Log streams (Flujos de registro). Un trabajador debería haber ejecutado el código solicitado. Deberá abrir todos los flujos de registro para identificar al trabajador correcto. Una vez que encuentre el trabajador correcto, se debería ver la salida del script, como se ve en la siguiente imagen: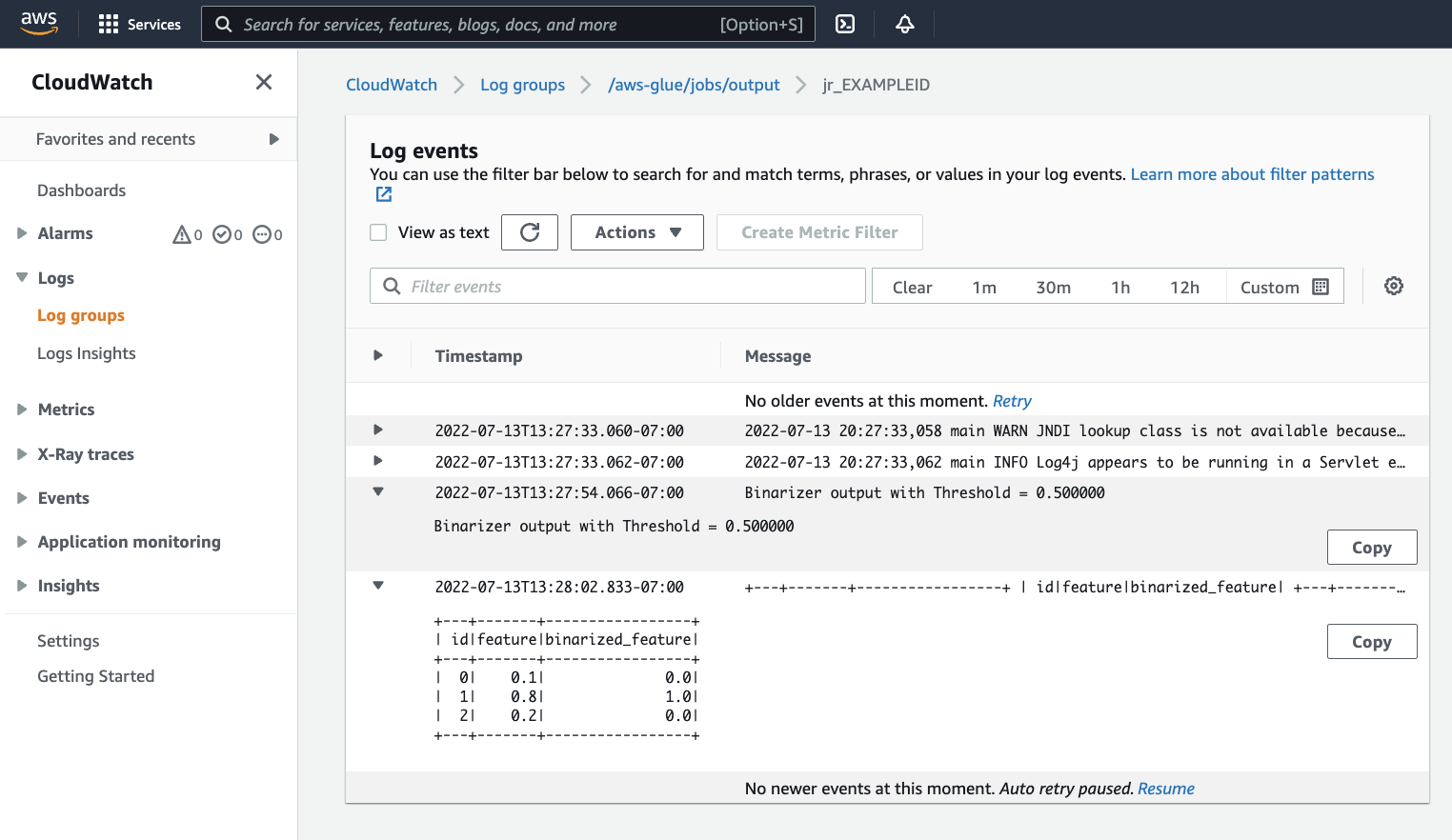
Procedimientos comunes necesarios para migrar programas Spark
Evaluar el soporte de la versión de Spark
Las versiones de AWS Glue determinan la versión de Apache Spark y Python disponible para el trabajo de AWS Glue. Puede encontrar nuestras versiones de AWS Glue y lo que admiten en Versiones de AWS Glue. Es posible que tenga que actualizar el programa de Spark para que sea compatible con una versión más reciente de Spark con el fin de acceder a determinadas características de AWS Glue.
Incluir bibliotecas de terceros
Muchos programas de Spark existentes tendrán dependencias, tanto en artefactos privados como públicos. AWS Glue admite dependencias de estilo JAR para trabajos de Scala, así como dependencias Wheel y de origen puro de Python para trabajos de Python.
Python: para obtener información sobre las dependencias de Python, consulte Uso de bibliotecas de Python con AWS Glue
Las dependencias habituales de Python se proporcionan en el entorno de AWS Glue, incluida la biblioteca Pandas--additional-python-modules. Para obtener información sobre argumentos de trabajo, consulte Uso de los parámetros de trabajo en los trabajos de AWS Glue.
Puede proporcionar dependencias de Python adicionales con el argumento de trabajo --extra-py-files. Si va a migrar un trabajo desde un programa de Spark, este parámetro es una buena opción porque equivale funcionalmente al indicador --py-files de PySpark y está sujeto a las mismas limitaciones. Para obtener más información sobre el parámetro --extra-py-files, consulte Inclusión de archivos de Python con características nativas de PySpark
Para los nuevos trabajos, puede administrar las dependencias de Python con el argumento de trabajo --additional-python-modules. El uso de este argumento permite una experiencia de administración de dependencias más completa. Este parámetro admite dependencias de estilo Wheel, incluidas aquellas con enlaces de código nativo compatibles con Amazon Linux 2.
Scala
Puede proporcionar dependencias de Scala adicionales con el argumento de trabajo --extra-jars. Las dependencias deben estar alojadas en Amazon S3 y el valor del argumento debe ser una lista delimitada por comas de rutas de Amazon S3 sin espacios. Puede que le resulte más fácil administrar la configuración si reagrupa las dependencias antes de alojarlas y configurarlas. AWS Glue Las dependencias JAR contienen código de bytes de Java, que se puede generar desde cualquier lenguaje JVM. Puede usar otros lenguajes de JVM, como Java, para escribir dependencias personalizadas.
Administrar credenciales de origen de datos.
Los programas Spark existentes pueden incluir una configuración compleja o personalizada para extraer datos de sus fuentes de datos. Los flujos de autenticación de orígenes de datos habituales son compatibles con conexiones de AWS Glue. Para obtener más información acerca de las conexiones de AWS Glue, consulte Conexión a datos.
Las conexiones de AWS Glue facilitan la conexión de un trabajo a diversos tipos de almacenes de datos principalmente de dos formas: mediante llamadas de métodos a nuestras bibliotecas y configurando Additional network connection (Conexión de red adicional) en la consola de AWS. También puede llamar al AWS SDK desde su trabajo para recuperar información de una conexión.
Llamada de métodos: las conexiones de AWS Glue están estrechamente integradas con el Catálogo de datos de AWS Glue, un servicio que permite seleccionar información sobre los conjuntos de datos, y los métodos disponibles para interactuar con las conexiones de AWS Glue así lo reflejan. Si tiene una configuración de autenticación existente que le gustaría reutilizar, para conexiones JDBC, puede acceder a la configuración de conexión de AWS Glue mediante el método extract_jdbc_conf en GlueContext. Para obtener más información, consulte extract_jdbc_conf.
Configuración de la consola: los trabajos de AWS Glue utilizan las conexiones de AWS Glue asociadas para configurar conexiones a subredes de Amazon VPC. Si administra directamente sus materiales de seguridad, es posible que tenga que proporcionar una Additional network connection (Conexión de red adicional) de tipo NETWORK en la consola de AWS para configurar el enrutamiento. Para obtener más información sobre la API de conexión de AWS Glue, consulte API de conexión.
Si sus programas Spark tienen un flujo de autenticación personalizado o poco común, es posible que tenga que gestionar los materiales de seguridad de forma manual. Si las conexiones de AWS Glue no resultan adecuadas, se puede alojar de manera segura los materiales de seguridad en Secrets Manager y acceder a ellos a través de boto3 o el AWS SDK, que se proporcionan en el trabajo.
Configurar Apache Spark
Las migraciones complejas a menudo alteran la configuración de Spark para adaptarse a sus cargas de trabajo. Las versiones modernas de Apache Spark permiten configurar el tiempo de ejecución con SparkSession. AWS Glue Se proporciona un SparkSession a los trabajos 3.0+, que se puede modificar para establecer la configuración del tiempo de ejecución. Configuración Apache Spark
Establecer configuración personalizada
Los programas de Spark migrados se pueden diseñar para que adopten una configuración personalizada. AWS Glue permite establecer la configuración en el nivel del trabajo y la ejecución del trabajo, mediante los argumentos del trabajo. Para obtener información sobre argumentos de trabajo, consulte Uso de los parámetros de trabajo en los trabajos de AWS Glue. Puede acceder a los argumentos del trabajo dentro del contexto de un trabajo a través de nuestras bibliotecas. AWS Glue proporciona una función de utilidad para ofrecer una vista coherente de los argumentos establecidos en el trabajo y aquellos establecidos en la ejecución del trabajo. Consulte Acceso a los parámetros mediante getResolvedOptions en Python y API GlueArgParser Scala de AWS Glue en Scala.
Migración de código Java
Como se explica en Incluir bibliotecas de terceros, sus dependencias pueden contener clases generadas por lenguajes JVM, como Java o Scala. Sus dependencias pueden incluir un método de main. Puede usar un método de main en una dependencia como punto de entrada para un trabajo de Scala de AWS Glue. Esto permite escribir su método de main en Java, o reutilizar un método de main empaquetado según los estándares de su propia biblioteca.
Para usar un método de main de una dependencia, realice lo siguiente: borre el contenido del panel de edición proporcionando el objeto predeterminado GlueApp. Proporcione el nombre completo de una clase en una dependencia como argumento de trabajo con la clave de --class. Luego, podrá activar una ejecución de trabajo.
No se puede configurar el orden ni la estructura de los argumentos que AWS Glue pasa al método main. Si el código existente necesita leer la configuración establecida en AWS Glue, es probable que esto provoque incompatibilidad con el código anterior. Si usa getResolvedOptions, tampoco tendrá un buen lugar para llamar a este método. Considere la posibilidad de invocar la dependencia directamente desde un método main generado por AWS Glue. El siguiente script de ETL de AWS Glue muestra un ejemplo de esto.
import com.amazonaws.services.glue.util.GlueArgParser object GlueApp { def main(sysArgs: Array[String]) { val args = GlueArgParser.getResolvedOptions(sysArgs, Seq("JOB_NAME").toArray) // Invoke static method from JAR. Pass some sample arguments as a String[], one defined inline and one taken from the job arguments, using getResolvedOptions com.mycompany.myproject.MyClass.myStaticPublicMethod(Array("string parameter1", args("JOB_NAME"))) // Alternatively, invoke a non-static public method. (new com.mycompany.myproject.MyClass).someMethod() } }
