Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Integración con AWS Glue Schema Registry
En estas secciones se describen las integraciones con AWS Glue Schema Registry. Los ejemplos de esta sección muestran un esquema con formato de datos AVRO. Para obtener más ejemplos, incluidos esquemas con formato de datos JSON, consulte las pruebas de integración y la información de ReadMe (Léame) en el Repositorio de código abierto de AWS Glue Schema Registry
Temas
- Caso de uso: Conexión de Schema Registry a Amazon MSK o Apache Kafka
- Caso de uso: Integración de Amazon Kinesis Data Streams con AWS Glue Schema Registry
- Caso de uso: Amazon Managed Service para Apache Flink
- Caso de uso: integración con AWS Lambda
- Caso de uso: AWS Glue Data Catalog
- Caso de uso: Streaming de AWS Glue
- Caso de uso: Apache Kafka Streams
Caso de uso: Conexión de Schema Registry a Amazon MSK o Apache Kafka
Supongamos que está escribiendo datos en un tema de Apache Kafka. Puede seguir estos pasos para comenzar.
Cree un clúster de Amazon Managed Streaming for Apache Kafka (Amazon MSK) o Apache Kafka con al menos un tema. Si crea un clúster de Amazon MSK, puede utilizar la AWS Management Console. Siga las siguientes isntrucciones: Introducción al uso de Amazon MSK en la Guía para desarrolladores de Amazon Managed Streaming for Apache Kafka.
Siga el paso Instalación de bibliotecas SerDe anterior.
Para crear registros de esquema, esquemas o versiones de esquema, siga las instrucciones de la sección Introducción a Schema Registry de este documento.
Inicie a sus productores y consumidores en el uso de Schema Registry para escribir y leer registros a/desde el tema de Amazon MSK o Apache Kafka. Puede encontrar un ejemplo de código de productor y consumidor en el archivo ReadMe (Léame)
de las bibliotecas Serde. La biblioteca de Schema Registry del productor serializará automáticamente el registro y agregará un ID de versión de esquema al registro. Si se ha introducido el esquema de este registro, o si el registro automático está activado, el esquema se habrá registrado en Schema Registry.
El consumidor que lee el tema de Amazon MSK o Apache Kafka, con la biblioteca de AWS Glue Schema Registry, buscará automáticamente el esquema desde Schema Registry.
Caso de uso: Integración de Amazon Kinesis Data Streams con AWS Glue Schema Registry
Esta integración requiere que tenga un flujo de datos de Amazon Kinesis. Para obtener más información, consulte Introducción a Amazon Kinesis Data Streams en la Guía para desarrolladores de Amazon Kinesis Data Streams.
Existen dos formas de interactuar con los datos en un flujo de datos de Kinesis.
A través de las bibliotecas Kinesis Producer Library (KPL) y Kinesis Client Library (KCL) en Java. No se proporciona soporte multilingüe.
A través de las API
PutRecords,PutRecordyGetRecordsde Kinesis Data Streams disponibles en AWS SDK for Java.
Si utiliza actualmente las bibliotecas KPL/KCL, le recomendamos seguir utilizando ese método. Hay versiones actualizadas de KCL y KPL con Schema Registry integrado, como se muestra en los ejemplos. De lo contrario, puede utilizar el código de muestra para aprovechar el AWS Glue Schema Registry si utiliza las API de KDS directamente.
La integración de Schema Registry sólo está disponible con KPL v0.14.2 o posterior y con KCL v2.3 o posterior. La integración de Schema Registry con datos JSON sólo está disponible con KPL v0.14.8 o posterior y con KCL v2.3.6 o posterior.
Interacción con datos mediante SDK de Kinesis V2
En esta sección se describe la interacción con Kinesis mediante SDK de Kinesis V2
// Example JSON Record, you can construct a AVRO record also private static final JsonDataWithSchema record = JsonDataWithSchema.builder(schemaString, payloadString); private static final DataFormat dataFormat = DataFormat.JSON; //Configurations for Schema Registry GlueSchemaRegistryConfiguration gsrConfig = new GlueSchemaRegistryConfiguration("us-east-1"); GlueSchemaRegistrySerializer glueSchemaRegistrySerializer = new GlueSchemaRegistrySerializerImpl(awsCredentialsProvider, gsrConfig); GlueSchemaRegistryDataFormatSerializer dataFormatSerializer = new GlueSchemaRegistrySerializerFactory().getInstance(dataFormat, gsrConfig); Schema gsrSchema = new Schema(dataFormatSerializer.getSchemaDefinition(record), dataFormat.name(), "MySchema"); byte[] serializedBytes = dataFormatSerializer.serialize(record); byte[] gsrEncodedBytes = glueSchemaRegistrySerializer.encode(streamName, gsrSchema, serializedBytes); PutRecordRequest putRecordRequest = PutRecordRequest.builder() .streamName(streamName) .partitionKey("partitionKey") .data(SdkBytes.fromByteArray(gsrEncodedBytes)) .build(); shardId = kinesisClient.putRecord(putRecordRequest) .get() .shardId(); GlueSchemaRegistryDeserializer glueSchemaRegistryDeserializer = new GlueSchemaRegistryDeserializerImpl(awsCredentialsProvider, gsrConfig); GlueSchemaRegistryDataFormatDeserializer gsrDataFormatDeserializer = glueSchemaRegistryDeserializerFactory.getInstance(dataFormat, gsrConfig); GetShardIteratorRequest getShardIteratorRequest = GetShardIteratorRequest.builder() .streamName(streamName) .shardId(shardId) .shardIteratorType(ShardIteratorType.TRIM_HORIZON) .build(); String shardIterator = kinesisClient.getShardIterator(getShardIteratorRequest) .get() .shardIterator(); GetRecordsRequest getRecordRequest = GetRecordsRequest.builder() .shardIterator(shardIterator) .build(); GetRecordsResponse recordsResponse = kinesisClient.getRecords(getRecordRequest) .get(); List<Object> consumerRecords = new ArrayList<>(); List<Record> recordsFromKinesis = recordsResponse.records(); for (int i = 0; i < recordsFromKinesis.size(); i++) { byte[] consumedBytes = recordsFromKinesis.get(i) .data() .asByteArray(); Schema gsrSchema = glueSchemaRegistryDeserializer.getSchema(consumedBytes); Object decodedRecord = gsrDataFormatDeserializer.deserialize(ByteBuffer.wrap(consumedBytes), gsrSchema.getSchemaDefinition()); consumerRecords.add(decodedRecord); }
Interacción con los datos mediante las bibliotecas KPL/KCL
En esta sección se describe la integración de Kinesis Data Streams con Schema Registry mediante las bibliotecas KPL/KCL. Para obtener más información sobre el uso de KPL/KCL, consulte Desarrollar productores con Amazon Kinesis Producer Library en la Guía para desarrolladores de Amazon Kinesis Data Streams.
Configuración de Schema Registry en KPL
Establezca la definición de esquema para los datos, el formato de datos y el nombre del esquema creados en AWS Glue Schema Registry.
Opcionalmente, configure el objeto
GlueSchemaRegistryConfiguration.Transfiera el objeto de esquema a
addUserRecord API.private static final String SCHEMA_DEFINITION = "{"namespace": "example.avro",\n" + " "type": "record",\n" + " "name": "User",\n" + " "fields": [\n" + " {"name": "name", "type": "string"},\n" + " {"name": "favorite_number", "type": ["int", "null"]},\n" + " {"name": "favorite_color", "type": ["string", "null"]}\n" + " ]\n" + "}"; KinesisProducerConfiguration config = new KinesisProducerConfiguration(); config.setRegion("us-west-1") //[Optional] configuration for Schema Registry. GlueSchemaRegistryConfiguration schemaRegistryConfig = new GlueSchemaRegistryConfiguration("us-west-1"); schemaRegistryConfig.setCompression(true); config.setGlueSchemaRegistryConfiguration(schemaRegistryConfig); ///Optional configuration ends. final KinesisProducer producer = new KinesisProducer(config); final ByteBuffer data = getDataToSend(); com.amazonaws.services.schemaregistry.common.Schema gsrSchema = new Schema(SCHEMA_DEFINITION, DataFormat.AVRO.toString(), "demoSchema"); ListenableFuture<UserRecordResult> f = producer.addUserRecord( config.getStreamName(), TIMESTAMP, Utils.randomExplicitHashKey(), data, gsrSchema); private static ByteBuffer getDataToSend() { org.apache.avro.Schema avroSchema = new org.apache.avro.Schema.Parser().parse(SCHEMA_DEFINITION); GenericRecord user = new GenericData.Record(avroSchema); user.put("name", "Emily"); user.put("favorite_number", 32); user.put("favorite_color", "green"); ByteArrayOutputStream outBytes = new ByteArrayOutputStream(); Encoder encoder = EncoderFactory.get().directBinaryEncoder(outBytes, null); new GenericDatumWriter<>(avroSchema).write(user, encoder); encoder.flush(); return ByteBuffer.wrap(outBytes.toByteArray()); }
Configuración de Kinesis Client Library
Desarrolle un consumidor de Kinesis Client Library en Java. Para obtener más información, consulte Desarrollo de un consumidor de Kinesis Client Library en Java en la Guía para desarrolladores de Amazon Kinesis Data Streams.
Cree una instancia de
GlueSchemaRegistryDeserializeral transferir un objetoGlueSchemaRegistryConfiguration.Transfiera el
GlueSchemaRegistryDeserializeraretrievalConfig.glueSchemaRegistryDeserializer.Acceda al esquema de los mensajes entrantes al llamar a
kinesisClientRecord.getSchema().GlueSchemaRegistryConfiguration schemaRegistryConfig = new GlueSchemaRegistryConfiguration(this.region.toString()); GlueSchemaRegistryDeserializer glueSchemaRegistryDeserializer = new GlueSchemaRegistryDeserializerImpl(DefaultCredentialsProvider.builder().build(), schemaRegistryConfig); RetrievalConfig retrievalConfig = configsBuilder.retrievalConfig().retrievalSpecificConfig(new PollingConfig(streamName, kinesisClient)); retrievalConfig.glueSchemaRegistryDeserializer(glueSchemaRegistryDeserializer); Scheduler scheduler = new Scheduler( configsBuilder.checkpointConfig(), configsBuilder.coordinatorConfig(), configsBuilder.leaseManagementConfig(), configsBuilder.lifecycleConfig(), configsBuilder.metricsConfig(), configsBuilder.processorConfig(), retrievalConfig ); public void processRecords(ProcessRecordsInput processRecordsInput) { MDC.put(SHARD_ID_MDC_KEY, shardId); try { log.info("Processing {} record(s)", processRecordsInput.records().size()); processRecordsInput.records() .forEach( r -> log.info("Processed record pk: {} -- Seq: {} : data {} with schema: {}", r.partitionKey(), r.sequenceNumber(), recordToAvroObj(r).toString(), r.getSchema())); } catch (Throwable t) { log.error("Caught throwable while processing records. Aborting."); Runtime.getRuntime().halt(1); } finally { MDC.remove(SHARD_ID_MDC_KEY); } } private GenericRecord recordToAvroObj(KinesisClientRecord r) { byte[] data = new byte[r.data().remaining()]; r.data().get(data, 0, data.length); org.apache.avro.Schema schema = new org.apache.avro.Schema.Parser().parse(r.schema().getSchemaDefinition()); DatumReader datumReader = new GenericDatumReader<>(schema); BinaryDecoder binaryDecoder = DecoderFactory.get().binaryDecoder(data, 0, data.length, null); return (GenericRecord) datumReader.read(null, binaryDecoder); }
Interacción con datos mediante las API de Kinesis Data Streams
En esta sección se describe la integración de Kinesis Data Streams con Schema Registry mediante las API de Kinesis Data Streams.
Actualice estas dependencias de Maven:
<dependencyManagement> <dependencies> <dependency> <groupId>com.amazonaws</groupId> <artifactId>aws-java-sdk-bom</artifactId> <version>1.11.884</version> <type>pom</type> <scope>import</scope> </dependency> </dependencies> </dependencyManagement> <dependencies> <dependency> <groupId>com.amazonaws</groupId> <artifactId>aws-java-sdk-kinesis</artifactId> </dependency> <dependency> <groupId>software.amazon.glue</groupId> <artifactId>schema-registry-serde</artifactId> <version>1.1.5</version> </dependency> <dependency> <groupId>com.fasterxml.jackson.dataformat</groupId> <artifactId>jackson-dataformat-cbor</artifactId> <version>2.11.3</version> </dependency> </dependencies>En el productor, agregue información de encabezado de esquema con la API
PutRecordsoPutRecorden Kinesis Data Streams.//The following lines add a Schema Header to the record com.amazonaws.services.schemaregistry.common.Schema awsSchema = new com.amazonaws.services.schemaregistry.common.Schema(schemaDefinition, DataFormat.AVRO.name(), schemaName); GlueSchemaRegistrySerializerImpl glueSchemaRegistrySerializer = new GlueSchemaRegistrySerializerImpl(DefaultCredentialsProvider.builder().build(), new GlueSchemaRegistryConfiguration(getConfigs())); byte[] recordWithSchemaHeader = glueSchemaRegistrySerializer.encode(streamName, awsSchema, recordAsBytes);En el productor, use la API
PutRecordsoPutRecordpara poner el registro en el flujo de datos.En el consumidor, elimine el registro de esquema del encabezado y serialice un registro de esquemas de Avro.
//The following lines remove Schema Header from record GlueSchemaRegistryDeserializerImpl glueSchemaRegistryDeserializer = new GlueSchemaRegistryDeserializerImpl(DefaultCredentialsProvider.builder().build(), getConfigs()); byte[] recordWithSchemaHeaderBytes = new byte[recordWithSchemaHeader.remaining()]; recordWithSchemaHeader.get(recordWithSchemaHeaderBytes, 0, recordWithSchemaHeaderBytes.length); com.amazonaws.services.schemaregistry.common.Schema awsSchema = glueSchemaRegistryDeserializer.getSchema(recordWithSchemaHeaderBytes); byte[] record = glueSchemaRegistryDeserializer.getData(recordWithSchemaHeaderBytes); //The following lines serialize an AVRO schema record if (DataFormat.AVRO.name().equals(awsSchema.getDataFormat())) { Schema avroSchema = new org.apache.avro.Schema.Parser().parse(awsSchema.getSchemaDefinition()); Object genericRecord = convertBytesToRecord(avroSchema, record); System.out.println(genericRecord); }
Interacción con datos mediante las API de Kinesis Data Streams
El siguiente es el código de ejemplo para usar las API PutRecords y GetRecords.
//Full sample code import com.amazonaws.services.schemaregistry.deserializers.GlueSchemaRegistryDeserializerImpl; import com.amazonaws.services.schemaregistry.serializers.GlueSchemaRegistrySerializerImpl; import com.amazonaws.services.schemaregistry.utils.AVROUtils; import com.amazonaws.services.schemaregistry.utils.AWSSchemaRegistryConstants; import org.apache.avro.Schema; import org.apache.avro.generic.GenericData; import org.apache.avro.generic.GenericDatumReader; import org.apache.avro.generic.GenericDatumWriter; import org.apache.avro.generic.GenericRecord; import org.apache.avro.io.Decoder; import org.apache.avro.io.DecoderFactory; import org.apache.avro.io.Encoder; import org.apache.avro.io.EncoderFactory; import software.amazon.awssdk.auth.credentials.DefaultCredentialsProvider; import software.amazon.awssdk.services.glue.model.DataFormat; import java.io.ByteArrayOutputStream; import java.io.File; import java.io.IOException; import java.nio.ByteBuffer; import java.util.Collections; import java.util.HashMap; import java.util.Map; public class PutAndGetExampleWithEncodedData { static final String regionName = "us-east-2"; static final String streamName = "testStream1"; static final String schemaName = "User-Topic"; static final String AVRO_USER_SCHEMA_FILE = "src/main/resources/user.avsc"; KinesisApi kinesisApi = new KinesisApi(); void runSampleForPutRecord() throws IOException { Object testRecord = getTestRecord(); byte[] recordAsBytes = convertRecordToBytes(testRecord); String schemaDefinition = AVROUtils.getInstance().getSchemaDefinition(testRecord); //The following lines add a Schema Header to a record com.amazonaws.services.schemaregistry.common.Schema awsSchema = new com.amazonaws.services.schemaregistry.common.Schema(schemaDefinition, DataFormat.AVRO.name(), schemaName); GlueSchemaRegistrySerializerImpl glueSchemaRegistrySerializer = new GlueSchemaRegistrySerializerImpl(DefaultCredentialsProvider.builder().build(), new GlueSchemaRegistryConfiguration(regionName)); byte[] recordWithSchemaHeader = glueSchemaRegistrySerializer.encode(streamName, awsSchema, recordAsBytes); //Use PutRecords api to pass a list of records kinesisApi.putRecords(Collections.singletonList(recordWithSchemaHeader), streamName, regionName); //OR //Use PutRecord api to pass single record //kinesisApi.putRecord(recordWithSchemaHeader, streamName, regionName); } byte[] runSampleForGetRecord() throws IOException { ByteBuffer recordWithSchemaHeader = kinesisApi.getRecords(streamName, regionName); //The following lines remove the schema registry header GlueSchemaRegistryDeserializerImpl glueSchemaRegistryDeserializer = new GlueSchemaRegistryDeserializerImpl(DefaultCredentialsProvider.builder().build(), new GlueSchemaRegistryConfiguration(regionName)); byte[] recordWithSchemaHeaderBytes = new byte[recordWithSchemaHeader.remaining()]; recordWithSchemaHeader.get(recordWithSchemaHeaderBytes, 0, recordWithSchemaHeaderBytes.length); com.amazonaws.services.schemaregistry.common.Schema awsSchema = glueSchemaRegistryDeserializer.getSchema(recordWithSchemaHeaderBytes); byte[] record = glueSchemaRegistryDeserializer.getData(recordWithSchemaHeaderBytes); //The following lines serialize an AVRO schema record if (DataFormat.AVRO.name().equals(awsSchema.getDataFormat())) { Schema avroSchema = new org.apache.avro.Schema.Parser().parse(awsSchema.getSchemaDefinition()); Object genericRecord = convertBytesToRecord(avroSchema, record); System.out.println(genericRecord); } return record; } private byte[] convertRecordToBytes(final Object record) throws IOException { ByteArrayOutputStream recordAsBytes = new ByteArrayOutputStream(); Encoder encoder = EncoderFactory.get().directBinaryEncoder(recordAsBytes, null); GenericDatumWriter datumWriter = new GenericDatumWriter<>(AVROUtils.getInstance().getSchema(record)); datumWriter.write(record, encoder); encoder.flush(); return recordAsBytes.toByteArray(); } private GenericRecord convertBytesToRecord(Schema avroSchema, byte[] record) throws IOException { final GenericDatumReader<GenericRecord> datumReader = new GenericDatumReader<>(avroSchema); Decoder decoder = DecoderFactory.get().binaryDecoder(record, null); GenericRecord genericRecord = datumReader.read(null, decoder); return genericRecord; } private Map<String, String> getMetadata() { Map<String, String> metadata = new HashMap<>(); metadata.put("event-source-1", "topic1"); metadata.put("event-source-2", "topic2"); metadata.put("event-source-3", "topic3"); metadata.put("event-source-4", "topic4"); metadata.put("event-source-5", "topic5"); return metadata; } private GlueSchemaRegistryConfiguration getConfigs() { GlueSchemaRegistryConfiguration configs = new GlueSchemaRegistryConfiguration(regionName); configs.setSchemaName(schemaName); configs.setAutoRegistration(true); configs.setMetadata(getMetadata()); return configs; } private Object getTestRecord() throws IOException { GenericRecord genericRecord; Schema.Parser parser = new Schema.Parser(); Schema avroSchema = parser.parse(new File(AVRO_USER_SCHEMA_FILE)); genericRecord = new GenericData.Record(avroSchema); genericRecord.put("name", "testName"); genericRecord.put("favorite_number", 99); genericRecord.put("favorite_color", "red"); return genericRecord; } }
Caso de uso: Amazon Managed Service para Apache Flink
Apache Flink es un marco de código abierto y motor de procesamiento distribuido popular para informática con estado sobre flujos de datos ilimitados y delimitados. Amazon Managed Service para Apache Flink es un servicio de AWS completamente administrado que permite crear y administrar aplicaciones de Apache Flink para procesar datos de streaming.
El código abierto Apache Flink proporciona una serie de orígenes y receptores. Por ejemplo, los orígenes de datos predefinidos incluyen la lectura de archivos, directorios y sockets, y la ingesta de datos de recopilaciones e iteradores. Los conectores Apache Flink DataStream proporcionan código para que Apache Flink interactúe con varios sistemas de terceros, como Apache Kafka o Kinesis como orígenes o receptores.
Para obtener más información, consulte la Guía para desarrolladores de Amazon Kinesis Data Analytics.
Conector Kafka de Apache Flink
Apache Flink proporciona un conector de flujo de datos Apache Kafka para leer y escribir datos en temas de Kafka con garantías de una sola vez. El consumidor Kafka de Flink, FlinkKafkaConsumer, proporciona acceso a la lectura de uno o más temas de Kafka. El productor Kafka de Apache Flink, FlinkKafkaProducer, permite escribir una secuencia de registros en uno o más temas de Kafka. Para obtener más información, consulte Conector de Apache Kafka
Conector de flujos de Kinesis de Apache Flink
El conector de flujo de datos de Kinesis proporciona acceso a Amazon Kinesis Data Streams. El FlinkKinesisConsumer es un origen de datos de streaming en paralelo de exactamente una única vez que se suscribe a múltiples flujos de Kinesis dentro de la misma región de servicio de AWS, y puede manejar de forma transparente la redistribución de flujos mientras el trabajo se está ejecutando. Cada subtarea del consumidor es responsable de obtener registros de datos de múltiples fragmentos de Kinesis. El número de fragmentos obtenidos por cada subtarea cambiará a medida que Kinesis cierre y cree fragmentos. El FlinkKinesisProducer utiliza Kinesis Producer Library (KPL) para poner los datos de un flujo de Apache Flink en un flujo de Kinesis. Para obtener más información, consulte Conector de Amazon Kinesis Streams
Para obtener más información, consulte el repositorio GitHub de esquemas de AWS Glue
Integración con Apache Flink
La biblioteca SerDes proporcionada con Schema Registry se integra con Apache Flink. Para trabajar con Apache Flink, debe implementar las interfaces de SerializationSchemaDeserializationSchemaGlueSchemaRegistryAvroSerializationSchema y GlueSchemaRegistryAvroDeserializationSchema, que puede conectar a los conectores Apache Flink.
Adición de una dependencia de AWS Glue Schema Registry en la aplicación Apache Flink
Para configurar las dependencias de integración a AWS Glue Schema Registry en la aplicación Apache Flink:
Agregue la dependencia al archivo
pom.xml.<dependency> <groupId>software.amazon.glue</groupId> <artifactId>schema-registry-flink-serde</artifactId> <version>1.0.0</version> </dependency>
Integración de Kafka o Amazon MSK con Apache Flink
Puede usar Managed Service para Apache Flink con Kafka como origen o receptor.
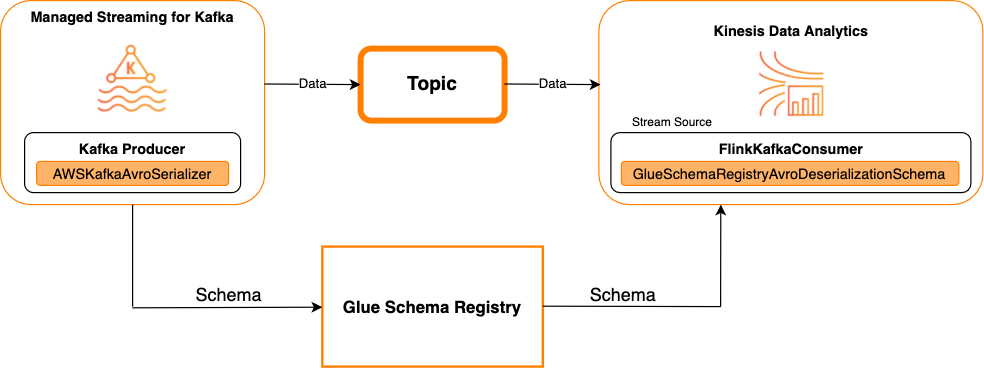
Kafka como origen
En el siguiente diagrama, se muestra la integración de Kinesis Data Streams con Managed Service para Apache Flink, con Kafka como origen.
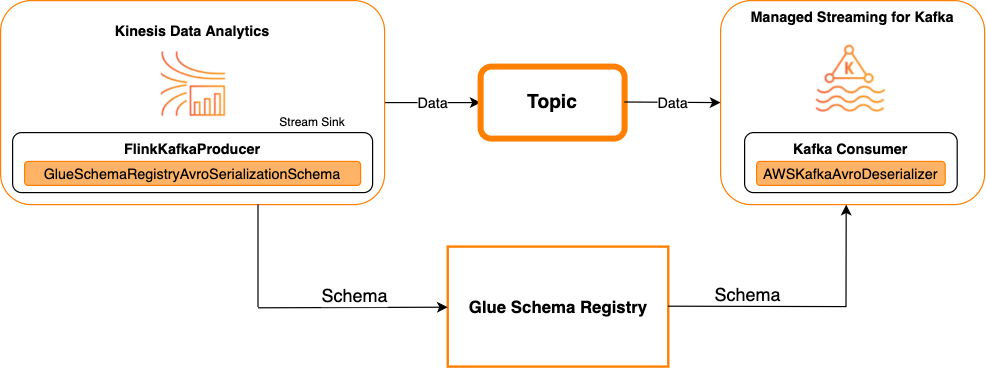
Kafka como receptor
En el siguiente diagrama, se muestra la integración de Kinesis Data Streams con Managed Service para Apache Flink, con Kafka como receptor.
Para integrar Kafka (o Amazon MSK) con Managed Service para Apache Flink, con Kafka como origen o receptor, realice los siguientes cambios de código. Agregue los bloques de código en negrita a su código respectivo en las secciones análogas.
Si Kafka es el origen, entonces use el código deserializador (bloque 2). Si Kafka es el receptor, use el código serializador (bloque 3).
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); String topic = "topic"; Properties properties = new Properties(); properties.setProperty("bootstrap.servers", "localhost:9092"); properties.setProperty("group.id", "test"); // block 1 Map<String, Object> configs = new HashMap<>(); configs.put(AWSSchemaRegistryConstants.AWS_REGION, "aws-region"); configs.put(AWSSchemaRegistryConstants.SCHEMA_AUTO_REGISTRATION_SETTING, true); configs.put(AWSSchemaRegistryConstants.AVRO_RECORD_TYPE, AvroRecordType.GENERIC_RECORD.getName()); FlinkKafkaConsumer<GenericRecord> consumer = new FlinkKafkaConsumer<>( topic, // block 2 GlueSchemaRegistryAvroDeserializationSchema.forGeneric(schema, configs), properties); FlinkKafkaProducer<GenericRecord> producer = new FlinkKafkaProducer<>( topic, // block 3 GlueSchemaRegistryAvroSerializationSchema.forGeneric(schema, topic, configs), properties); DataStream<GenericRecord> stream = env.addSource(consumer); stream.addSink(producer); env.execute();
Integración de Kinesis Data Streams con Apache Flink
Puede usar Managed Service para Apache Flink, con Kinesis Data Streams como origen o como receptor.
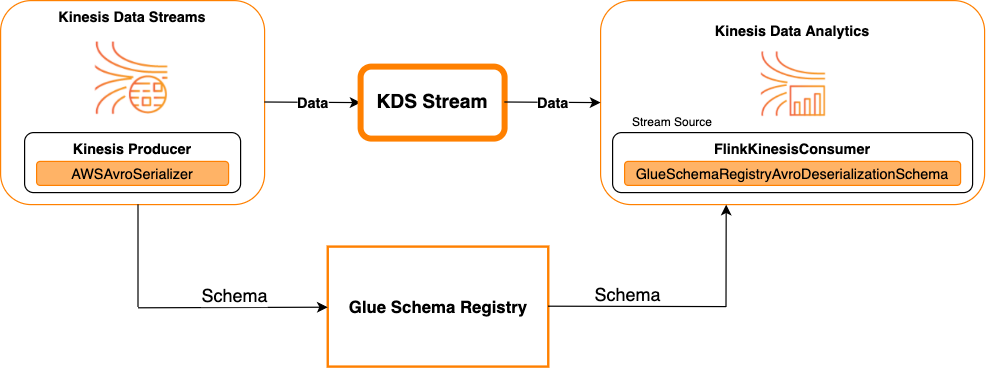
Kinesis Data Streams como origen
En el siguiente diagrama, se muestra la integración de Kinesis Data Streams con Managed Service para Apache Flink, con Kinesis Data Streams como origen.
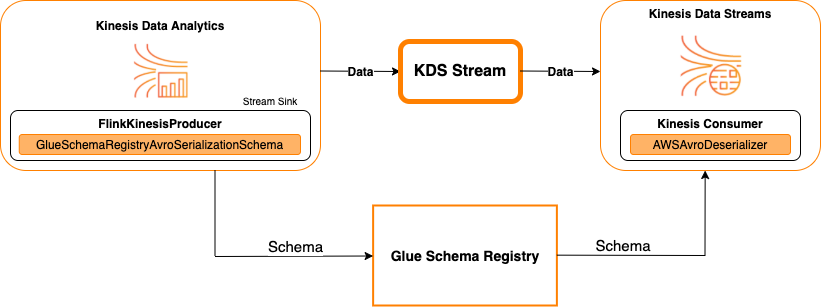
Kinesis Data Streams como receptor
En el siguiente diagrama, se muestra la integración de Kinesis Data Streams con Managed Service para Apache Flink, con Kinesis Data Streams como receptor.
Para integrar Kinesis Data Streams con Managed Service para Apache Flink, con Kinesis Data Streams como origen o receptor, realice los cambios de código que se indican a continuación. Agregue los bloques de código en negrita a su código respectivo en las secciones análogas.
Si Kinesis Data Streams es el origen, utilice el código deserializador (bloque 2). Si Kinesis Data Streams es el receptor, use el código serializador (bloque 3).
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); String streamName = "stream"; Properties consumerConfig = new Properties(); consumerConfig.put(AWSConfigConstants.AWS_REGION, "aws-region"); consumerConfig.put(AWSConfigConstants.AWS_ACCESS_KEY_ID, "aws_access_key_id"); consumerConfig.put(AWSConfigConstants.AWS_SECRET_ACCESS_KEY, "aws_secret_access_key"); consumerConfig.put(ConsumerConfigConstants.STREAM_INITIAL_POSITION, "LATEST"); // block 1 Map<String, Object> configs = new HashMap<>(); configs.put(AWSSchemaRegistryConstants.AWS_REGION, "aws-region"); configs.put(AWSSchemaRegistryConstants.SCHEMA_AUTO_REGISTRATION_SETTING, true); configs.put(AWSSchemaRegistryConstants.AVRO_RECORD_TYPE, AvroRecordType.GENERIC_RECORD.getName()); FlinkKinesisConsumer<GenericRecord> consumer = new FlinkKinesisConsumer<>( streamName, // block 2 GlueSchemaRegistryAvroDeserializationSchema.forGeneric(schema, configs), properties); FlinkKinesisProducer<GenericRecord> producer = new FlinkKinesisProducer<>( // block 3 GlueSchemaRegistryAvroSerializationSchema.forGeneric(schema, topic, configs), properties); producer.setDefaultStream(streamName); producer.setDefaultPartition("0"); DataStream<GenericRecord> stream = env.addSource(consumer); stream.addSink(producer); env.execute();
Caso de uso: integración con AWS Lambda
Para utilizar una función AWS Lambda como consumidor Apache Kafka/Amazon MSK y deserializar mensajes codificados por AVRO-con AWS Glue Schema Registry, visite la página de MSK Labs
Caso de uso: AWS Glue Data Catalog
Las tablas de AWS Glue soportan esquemas que se pueden especificar en forma manual o por referencia a AWS Glue Schema Registry. Schema Registry se integra con el Catálogo de datos para permitirle utilizar opcionalmente esquemas almacenados en Schema Registry al crear o actualizar tablas o particiones de AWS Glue en el Catálogo de datos. Para identificar una definición de esquema en Schema Registry, es necesario conocer, al menos, el ARN del esquema del que forma parte. Una versión de esquema, que contiene una definición de esquema, puede ser referenciada por su UUID o número de versión. Siempre hay una versión de esquema, la “última” versión, que se puede buscar sin saber su número de versión o UUID.
Al llamar a las operaciones CreateTable o UpdateTable, transferirá una estructura TableInput que contiene un StorageDescriptor, que podría tener una SchemaReference a un esquema existente en Schema Registry. Del mismo modo, cuando se llama a las API GetTable o GetPartition, la respuesta puede contener el esquema y la SchemaReference. Cuando se crea una tabla o partición mediante referencias de esquema, el Catálogo de datos intentará buscar el esquema para esta referencia de esquema. En caso de que no pueda encontrar el esquema, Schema Registry devuelve un esquema vacío en la respuesta GetTable; de lo contrario, la respuesta tendrá el esquema y la referencia del esquema.
Puede realizar las siguientes acciones desde la consola de AWS Glue.
Para realizar estas operaciones y crear, actualizar o ver la información del esquema, debe brindar al usuario que realiza la llamada un rol de IAM que proporcione permisos para la API GetSchemaVersion.
Agregar una tabla o actualizar el esquema de una tabla
Agregar una nueva tabla a partir de un esquema existente enlaza la tabla a una versión de esquema específica. Una vez que se registren las nuevas versiones de esquema, puede actualizar esta definición de tabla desde la página View tables (Ver tabla) en la consola de AWS Glue o con la API Acción UpdateTable (Python: update_table).
Agregar una tabla a partir de un esquema existente
Puede crear una tabla de AWS Glue a partir de una versión de esquema en el registro mediante la consola AWS Glue o la API CreateTable.
API de AWS Glue
Al llamar a la API CreateTable, transferirá una TableInput que contiene un StorageDescriptor con una SchemaReference a un esquema existente en Schema Registry.
Consola de AWS Glue
Para crear una tabla desde la consola de AWS Glue:
-
Inicie sesión en AWS Management Console y abra la consola de AWS Glue en https://console.aws.amazon.com/glue/
. En el panel de navegación, en Data catalog (Catálogo de datos), elija Tables (Tablas).
En el menú Add tables (Agregar tablas), elija Add table from existing schema (Agregar tabla a partir del esquema existente).
Configure las propiedades de la tabla y el almacén de datos según la Guía para desarrolladores de AWS Glue.
En la página Choose a Glue schema (Elegir un esquema de Glue), seleccione el Record (Registro) donde reside el esquema.
Elija el Schema name (Nombre del esquema) y seleccione la Version (Versión) del esquema que se va a aplicar.
Revise la previsualización del esquema y elija Next (Siguiente).
Revise y cree la tabla.
El esquema y la versión aplicados a la tabla aparecen en la columna Glue schema (Esquema de Glue) en la lista de tablas. Puede ver la tabla para ver más detalles.
Actualización del esquema de una tabla
Cuando esté disponible una nueva versión de esquema, es posible que desee actualizar el esquema de una tabla mediante la API Acción UpdateTable (Python: update_table) o la consola de AWS Glue.
importante
Al actualizar el esquema de una tabla existente que tiene un esquema de AWS Glue especificado manualmente, el nuevo esquema al que se hace referencia en el Schema Registry puede ser incompatible. Esto puede dar lugar a que sus trabajos presenten errores.
API de AWS Glue
Al llamar a la API UpdateTable, transferirá una TableInput que contiene un StorageDescriptor con una SchemaReference a un esquema existente en Schema Registry.
Consola de AWS Glue
Para actualizar el esquema de una tabla desde la consola de AWS Glue:
-
Inicie sesión en AWS Management Console y abra la consola de AWS Glue en https://console.aws.amazon.com/glue/
. En el panel de navegación, en Data catalog (Catálogo de datos), elija Tables (Tablas).
Vea la tabla de la lista de tablas.
Haga clic en Update schema (Actualizar esquema) en el cuadro que le informa sobre una nueva versión.
Revise las diferencias entre el esquema actual y el nuevo.
Seleccione Show all schema differences (Mostrar todas las diferencias de esquemas) para ver más detalles.
Seleccione Save table (Guardar tabla) para aceptar la nueva versión.
Caso de uso: Streaming de AWS Glue
El streaming de AWS Glue consume datos de orígenes de streaming y realiza operaciones ETL antes de escribir en un receptor de salida. El origen del streaming de entrada se puede especificar mediante una tabla de datos o directamente especificando la configuración de origen.
El streaming de AWS Glue admite una tabla del Catálogo de datos para el origen de transmisión creado con el esquema presente en AWS Glue Schema Registry. Puede crear un esquema en AWS Glue Schema Registry y, mediante el uso de este, crear una tabla de AWS Glue con un origen de streaming. Esta tabla de AWS Glue se puede utilizar como entrada para un trabajo de streaming de AWS Glue de manera de deserializar los datos en el flujo de entrada.
Un punto que se debe tener en cuenta aquí es que, cuando cambia el esquema de AWS Glue Schema Registry, debe reiniciar el trabajo de streaming de AWS Glue para que el cambio se vea reflejado.
Caso de uso: Apache Kafka Streams
La API Apache Kafka Streams es una biblioteca cliente para procesar y analizar datos almacenados en Apache Kafka. Esta sección describe la integración de Apache Kafka Streams con AWS Glue Schema Registry, que le permite administrar y aplicar esquemas en sus aplicaciones de streaming de datos. Para obtener más información sobre Apache Kafka Streams, consulte Apache Kafka Streams
Integración con las bibliotecas SerDes
Existe una clase de GlueSchemaRegistryKafkaStreamsSerde con la que puede configurar una aplicación de Streams.
Código de ejemplo de aplicación de Kafka Streams
Para utilizar el AWS Glue Schema Registry dentro de una aplicación Apache Kafka Streams:
Configure la aplicación Kafka Streams.
final Properties props = new Properties(); props.put(StreamsConfig.APPLICATION_ID_CONFIG, "avro-streams"); props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092"); props.put(StreamsConfig.CACHE_MAX_BYTES_BUFFERING_CONFIG, 0); props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass().getName()); props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, AWSKafkaAvroSerDe.class.getName()); props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest"); props.put(AWSSchemaRegistryConstants.AWS_REGION, "aws-region"); props.put(AWSSchemaRegistryConstants.SCHEMA_AUTO_REGISTRATION_SETTING, true); props.put(AWSSchemaRegistryConstants.AVRO_RECORD_TYPE, AvroRecordType.GENERIC_RECORD.getName()); props.put(AWSSchemaRegistryConstants.DATA_FORMAT, DataFormat.AVRO.name());Cree un flujo a partir del tema avro-input.
StreamsBuilder builder = new StreamsBuilder(); final KStream<String, GenericRecord> source = builder.stream("avro-input");Procese los registros de datos (el ejemplo filtra aquellos registros cuyo valor de color_favorito es rosa o cuyo valor de cantidad es 15).
final KStream<String, GenericRecord> result = source .filter((key, value) -> !"pink".equals(String.valueOf(value.get("favorite_color")))); .filter((key, value) -> !"15.0".equals(String.valueOf(value.get("amount"))));Escriba los resultados en el tema avro-output.
result.to("avro-output");Inicie la aplicación Apache Kafka Streams.
KafkaStreams streams = new KafkaStreams(builder.build(), props); streams.start();
Resultados de implementación
Estos resultados muestran el proceso de filtrado de registros que se filtraron en el paso 3 como color_favorito “rosa” o valor “15,0”.
Registros antes del filtrado:
{"name": "Sansa", "favorite_number": 99, "favorite_color": "white"} {"name": "Harry", "favorite_number": 10, "favorite_color": "black"} {"name": "Hermione", "favorite_number": 1, "favorite_color": "red"} {"name": "Ron", "favorite_number": 0, "favorite_color": "pink"} {"name": "Jay", "favorite_number": 0, "favorite_color": "pink"} {"id": "commute_1","amount": 3.5} {"id": "grocery_1","amount": 25.5} {"id": "entertainment_1","amount": 19.2} {"id": "entertainment_2","amount": 105} {"id": "commute_1","amount": 15}
Registros después del filtrado:
{"name": "Sansa", "favorite_number": 99, "favorite_color": "white"} {"name": "Harry", "favorite_number": 10, "favorite_color": "black"} {"name": "Hermione", "favorite_number": 1, "favorite_color": "red"} {"name": "Ron", "favorite_number": 0, "favorite_color": "pink"} {"id": "commute_1","amount": 3.5} {"id": "grocery_1","amount": 25.5} {"id": "entertainment_1","amount": 19.2} {"id": "entertainment_2","amount": 105}
Caso de uso: Apache Kafka Connect
La integración de Apache Kafka Connect con el AWS Glue Schema Registry permite obtener información de esquemas a partir de los conectores. Los convertidores Apache Kafka especifican el formato de datos dentro de Apache Kafka y cómo traducirlos a datos Apache Kafka Connect. Cada usuario de Apache Kafka Connect tendrá que configurar estos convertidores en función del formato en el que desea que sus datos estén cargados o almacenados en Apache Kafka. De esta manera, puede definir sus propios convertidores para traducir los datos de Apache Kafka Connect al tipo utilizado en AWS Glue Schema Registry (por ejemplo: Avro) y utilizar nuestro serializador para registrar su esquema y serializar. Los convertidores también pueden usar nuestro deserializador para deserializar los datos recibidos de Apache Kafka y volver a convertirlos en datos Apache Kafka Connect. A continuación se muestra un diagrama de flujo de trabajo de ejemplo.
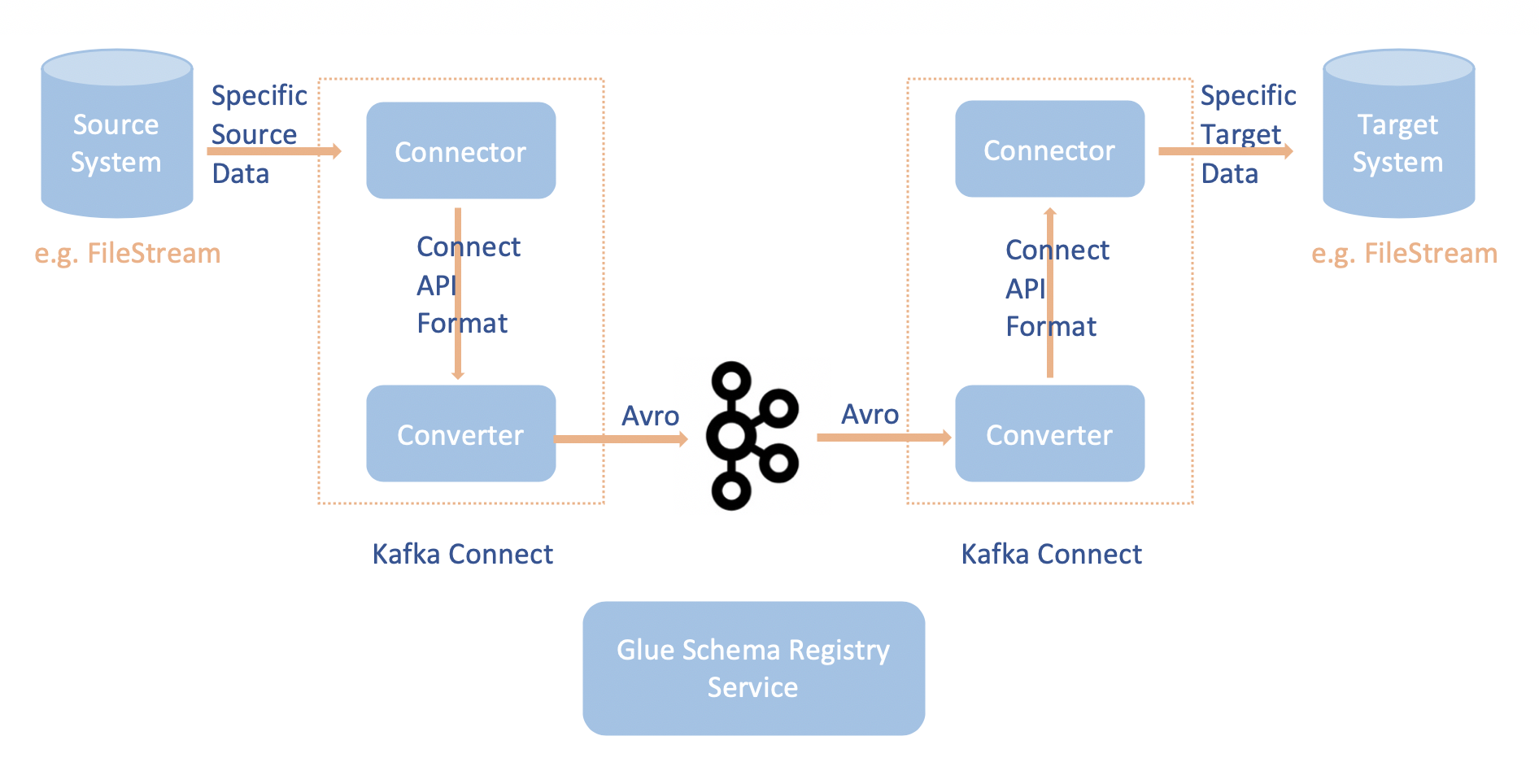
Instale el proyecto
aws-glue-schema-registryal clonar el repositorio de Github para AWS Glue Schema Registry. git clone git@github.com:awslabs/aws-glue-schema-registry.git cd aws-glue-schema-registry mvn clean install mvn dependency:copy-dependenciesSi planea usar Apache Kafka Connect en modo independiente, actualice connect-standalone.properties según las instrucciones que se incluyen a continuación. Si planea usar Apache Kafka Connect en modo distribuido, actualice connect-avro-distributed.properties según las mismas instrucciones.
Agregue estas propiedades también al archivo de propiedades de conexión Apache Kafka:
key.converter.region=aws-regionvalue.converter.region=aws-regionkey.converter.schemaAutoRegistrationEnabled=true value.converter.schemaAutoRegistrationEnabled=true key.converter.avroRecordType=GENERIC_RECORD value.converter.avroRecordType=GENERIC_RECORDAgregue el siguiente comando a la sección Launch mode (Modo de lanzamiento) en kafka-run-class.sh:
-cp $CLASSPATH:"<your AWS GlueSchema Registry base directory>/target/dependency/*"
Agregue el siguiente comando a la sección Launch mode (Modo de lanzamiento) en kafka-run-class.sh
-cp $CLASSPATH:"<your AWS GlueSchema Registry base directory>/target/dependency/*"Debería tener un aspecto similar al siguiente:
# Launch mode if [ "x$DAEMON_MODE" = "xtrue" ]; then nohup "$JAVA" $KAFKA_HEAP_OPTS $KAFKA_JVM_PERFORMANCE_OPTS $KAFKA_GC_LOG_OPTS $KAFKA_JMX_OPTS $KAFKA_LOG4J_OPTS -cp $CLASSPATH:"/Users/johndoe/aws-glue-schema-registry/target/dependency/*" $KAFKA_OPTS "$@" > "$CONSOLE_OUTPUT_FILE" 2>&1 < /dev/null & else exec "$JAVA" $KAFKA_HEAP_OPTS $KAFKA_JVM_PERFORMANCE_OPTS $KAFKA_GC_LOG_OPTS $KAFKA_JMX_OPTS $KAFKA_LOG4J_OPTS -cp $CLASSPATH:"/Users/johndoe/aws-glue-schema-registry/target/dependency/*" $KAFKA_OPTS "$@" fiSi usa bash, ejecute los siguientes comandos para configurar su CLASSPATH en su bash_profile. Para cualquier otro shell, actualice el entorno en consecuencia.
echo 'export GSR_LIB_BASE_DIR=<>' >>~/.bash_profile echo 'export GSR_LIB_VERSION=1.0.0' >>~/.bash_profile echo 'export KAFKA_HOME=<your Apache Kafka installation directory>' >>~/.bash_profile echo 'export CLASSPATH=$CLASSPATH:$GSR_LIB_BASE_DIR/avro-kafkaconnect-converter/target/schema-registry-kafkaconnect-converter-$GSR_LIB_VERSION.jar:$GSR_LIB_BASE_DIR/common/target/schema-registry-common-$GSR_LIB_VERSION.jar:$GSR_LIB_BASE_DIR/avro-serializer-deserializer/target/schema-registry-serde-$GSR_LIB_VERSION.jar' >>~/.bash_profile source ~/.bash_profile(Opcional) si desea realizar una prueba con un origen de archivo simple, clone el conector de origen del archivo.
git clone https://github.com/mmolimar/kafka-connect-fs.git cd kafka-connect-fs/En la configuración del conector de origen, edite el formato de datos a Avro, el lector de archivos a
AvroFileReadery actualice un objeto Avro de ejemplo desde la ruta del archivo de la que está leyendo. Por ejemplo:vim config/kafka-connect-fs.propertiesfs.uris=<path to a sample avro object> policy.regexp=^.*\.avro$ file_reader.class=com.github.mmolimar.kafka.connect.fs.file.reader.AvroFileReaderInstale el conector de origen.
mvn clean package echo "export CLASSPATH=\$CLASSPATH:\"\$(find target/ -type f -name '*.jar'| grep '\-package' | tr '\n' ':')\"" >>~/.bash_profile source ~/.bash_profileActualice las propiedades del receptor en
<your Apache Kafka installation directory>/config/connect-file-sink.propertiesfile=<output file full path> topics=<my topic>
Inicie el conector de origen (en este ejemplo es un conector de origen de archivo).
$KAFKA_HOME/bin/connect-standalone.sh $KAFKA_HOME/config/connect-standalone.properties config/kafka-connect-fs.propertiesEjecute el conector del receptor (en este ejemplo es un conector receptor de archivo).
$KAFKA_HOME/bin/connect-standalone.sh $KAFKA_HOME/config/connect-standalone.properties $KAFKA_HOME/config/connect-file-sink.propertiesPara ver un ejemplo de uso de Kafka Connect, mire el script run-local-tests.sh en la carpeta integration-tests (pruebas de integración) en el repositorio de Github para AWS Glue Schema Registry
.
