Actualizaciones de IA generativa para Apache Spark en AWS Glue
La función Actualizaciones de Spark en AWS Glue permite que los ingenieros de datos y desarrolladores actualicen y migren sus trabajos actuales de Spark de AWS Glue a las versiones más recientes de Spark mediante la IA generativa. Los ingenieros de datos pueden utilizarla para escanear sus trabajos de Spark de AWS Glue, generar planes de actualización, ejecutar planes y validar los resultados. Reduce el tiempo y el costo de las actualizaciones de Spark al automatizar el trabajo indiferenciado de identificar y actualizar los scripts, las configuraciones, las dependencias, los métodos y las características de Spark.
Funcionamiento
Cuando utiliza el análisis de actualizaciones, AWS Glue identifica las diferencias entre las versiones y las configuraciones en el código del trabajo para generar un plan de actualización. El plan de actualización detalla todos los cambios de código y los pasos de migración necesarios. A continuación, AWS Glue crea y ejecuta la aplicación actualizada en un entorno para validar los cambios y genera una lista de cambios de código para que pueda migrar el trabajo. Puede ver el script actualizado junto con el resumen que detalla los cambios propuestos. Tras ejecutar pruebas propias, acepte los cambios y el trabajo de AWS Glue se actualizará automáticamente a la última versión con el nuevo script.
El proceso de análisis de la actualización puede tardar un tiempo en completarse, en función de la complejidad del trabajo y la carga de trabajo. Los resultados del análisis de la actualización se almacenarán en la ruta de Amazon S3 especificada, que se puede revisar para comprender la actualización y cualquier posible problema de compatibilidad. Tras revisar los resultados del análisis de la actualización, puede decidir si desea continuar con la actualización propiamente dicha o hacer los cambios necesarios en el trabajo antes de la actualización.
Requisitos previos
Estos son los requisitos previos necesarios para utilizar la IA generativa para actualizar trabajos en AWS Glue:
-
Trabajos de PySpark de AWS Glue 2: solo los trabajos de AWS Glue 2 se pueden actualizar a AWS Glue 5.
-
Se necesitan permisos de IAM para iniciar el análisis, revisar los resultados y actualizar el trabajo. Para obtener más información, consulte los ejemplos de la sección Permisos a continuación.
-
Si se utiliza AWS KMS para cifrar artefactos de análisis, se necesitan permisos adicionales de AWS AWS KMS. Para obtener más información, consulte los ejemplos de la sección AWS KMSPolítica de a continuación.
Permisos
-
Actualice la política de IAM del intermediario con el siguiente permiso:
-
Actualice el rol de ejecución del trabajo que vaya a actualizar para incluir la siguiente política en línea:
{ "Effect": "Allow", "Action": ["s3:GetObject"], "Resource": [ "ARN of the Amazon S3 path provided on API", "ARN of the Amazon S3 path provided on API/*" ] }Por ejemplo, si utiliza la ruta de Amazon S3
s3://amzn-s3-demo-bucket/upgraded-result, la política será:{ "Effect": "Allow", "Action": ["s3:GetObject"], "Resource": [ "arn:aws:s3:::amzn-s3-demo-bucket/upgraded-result/", "arn:aws:s3:::amzn-s3-demo-bucket/upgraded-result/*" ] }
AWS KMSPolítica de
Para transferir su propia clave personalizada de AWS KMS al iniciar un análisis, consulte la siguiente sección para configurar los permisos adecuados para las claves de AWS KMS.
Esta política garantiza que tiene los permisos de cifrado y descifrado de la clave de AWS KMS.
{ "Effect": "Allow", "Principal":{ "AWS": "<IAM Customer caller ARN>" }, "Action": [ "kms:Decrypt", "kms:GenerateDataKey", ], "Resource": "<key-arn-passed-on-start-api>" }
Ejecución de un análisis de actualización y aplicación del script de actualización
Puede ejecutar un análisis de actualización, que generará un plan de actualización para un trabajo que seleccione en la vista Trabajos.
-
En Trabajos, seleccione un trabajo de AWS Glue 2.0 y, a continuación, elija Ejecutar análisis de actualización en el menú Acciones.
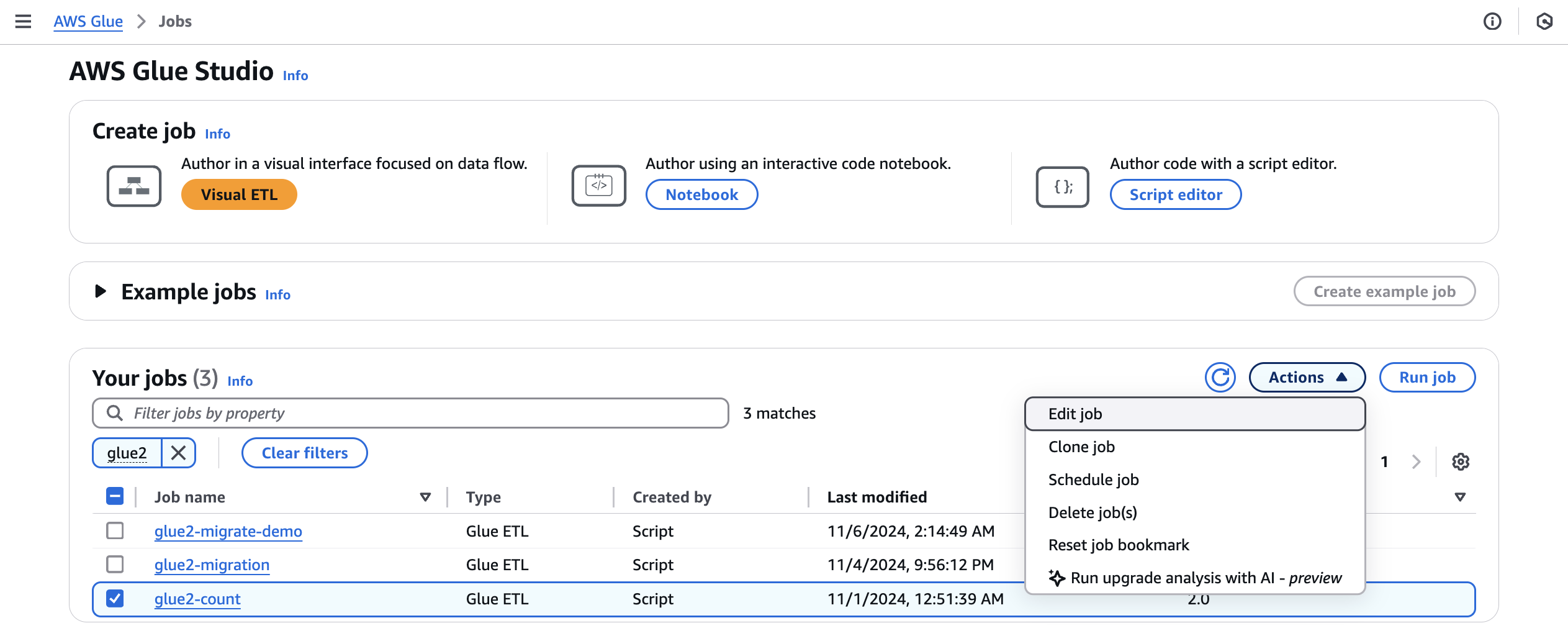
-
En el modal, seleccione una ruta para almacenar el plan de mejoras generado en Ruta de resultados. Debe ser un bucket de Amazon S3 al que pueda acceder y en el que pueda escribir.
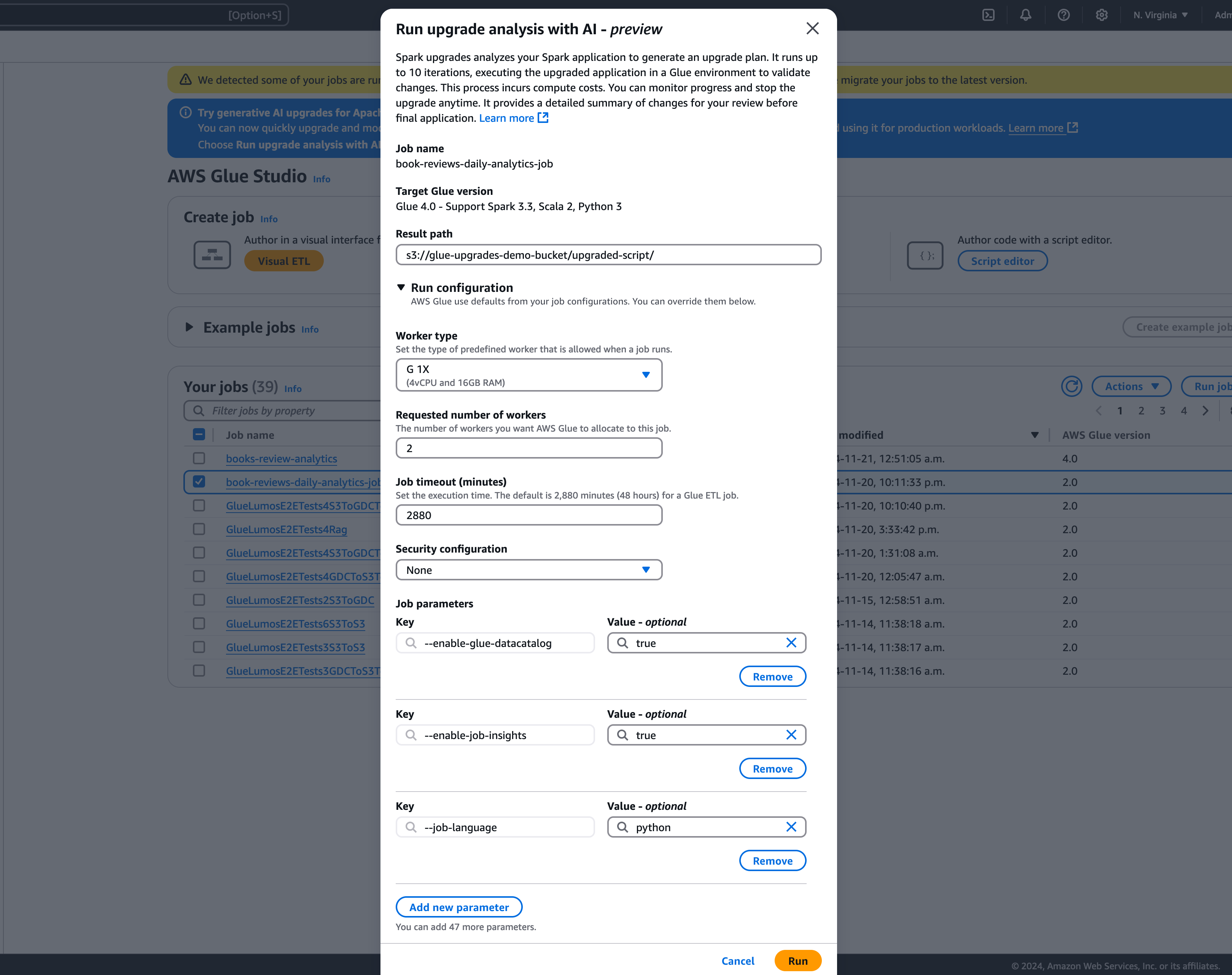
-
Configure las opciones adicionales si es necesario:
-
Configuración de ejecución: (opcional): la configuración de ejecución es una configuración opcional que permite personalizar varios aspectos de las ejecuciones de validación hechas durante el análisis de la actualización. Esta configuración se utiliza para ejecutar el script actualizado y permite seleccionar las propiedades del entorno de computación (tipo de proceso de trabajo, número de procesos de trabajo, etc.). Tenga en cuenta que debe utilizar sus cuentas de desarrollador ajenas a la producción para hacer las validaciones de los conjuntos de datos de muestra antes de revisar, aceptar los cambios y aplicarlos a los entornos de producción. La configuración de ejecución incluye los siguientes parámetros personalizables:
-
Tipo de trabajador: puede especificar el tipo de trabajador que se utilizará en las ejecuciones de validación, lo que le permitirá elegir los recursos de computación adecuados en función de sus requisitos.
-
Número de trabajadores: puede definir el número de procesos de trabajo que se van a aprovisionar para las ejecuciones de validación, lo que le permite escalar los recursos en función de sus necesidades de carga de trabajo.
-
Tiempo de espera del trabajo (en minutos): este parámetro le permite establecer un límite de tiempo para las ejecuciones de validación, lo que garantiza que los trabajos finalicen después de un periodo específico para evitar un consumo excesivo de recursos.
-
Configuración de seguridad: puede configurar los parámetros de seguridad, como el cifrado y el control de acceso, para garantizar la protección de los datos y los recursos durante las ejecuciones de validación.
-
Parámetros de trabajo adicionales: si es necesario, puede agregar nuevos parámetros de trabajo para personalizar aún más el entorno de ejecución de las ejecuciones de validación.
Al aprovechar la configuración de las ejecuciones, puede personalizar las ejecuciones de validación para que se adapten a sus requisitos específicos. Por ejemplo, puede configurar las ejecuciones de validación para usar un conjunto de datos más pequeño, lo que permite que el análisis se complete más rápidamente y optimiza los costos. Este enfoque garantiza que el análisis de actualización se haga de manera eficiente y, al mismo tiempo, minimiza la utilización de los recursos y los costos asociados durante la fase de validación.
-
-
Configuración de cifrado (opcional):
-
Habilitar el cifrado de los artefactos de actualización: habilite el cifrado en reposo al escribir los datos en la ruta de resultados. Si no quiere cifrar los artefactos de actualización, deje esta opción sin marcar.
-
-
-
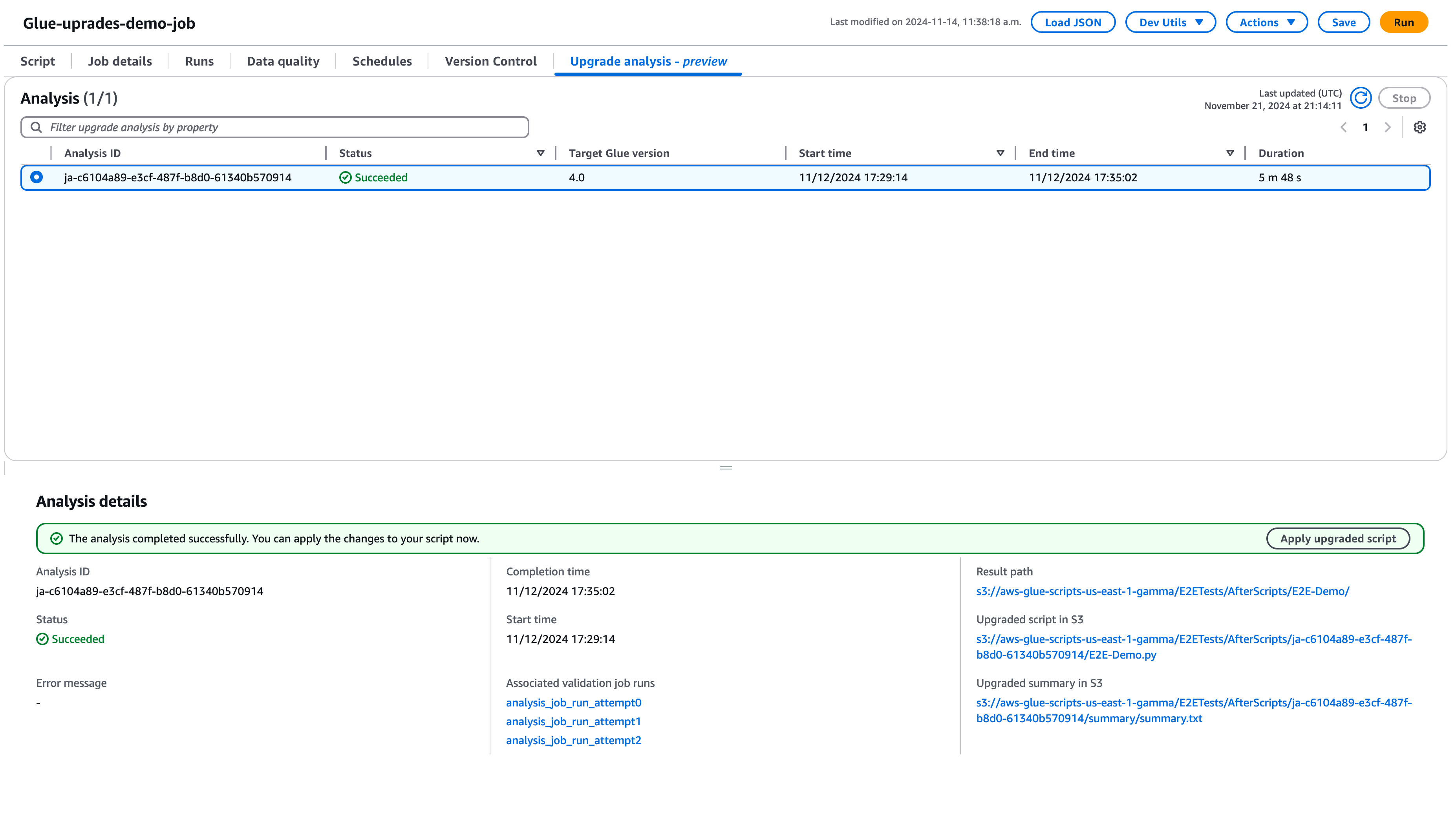
Seleccione Ejecutar para iniciar el análisis de la actualización. Mientras se ejecuta el análisis, puede ver los resultados en la pestaña Análisis de actualización. La ventana de detalles del análisis le mostrará información sobre el análisis, así como enlaces a los artefactos de la actualización.
-
Ruta de resultados: aquí es donde se almacenan el resumen de los resultados y el script de actualización.
-
Script actualizado en Amazon S3: ubicación del script de actualización en Amazon S3. Puede ver el script antes de aplicar la actualización.
-
Resumen de la actualización en Amazon S3: la ubicación del resumen de la actualización en Amazon S3. Puede ver el resumen de la actualización antes de aplicarla.
-
-
Cuando el análisis de actualización se haya completado correctamente, puede aplicar el script de actualización para actualizar automáticamente el trabajo mediante la selección de la opción Aplicar el script actualizado.
Una vez aplicada, la versión de AWS Glue se actualizará a la versión 4.0. Puede ver el nuevo script en la pestaña Script.
Descripción del resumen de la actualización
En este ejemplo, se muestra el proceso de actualización de un trabajo de AWS Glue de la versión 2.0 a la versión 4.0. El trabajo de muestra lee los datos del producto de un bucket de Amazon S3, aplica varias transformaciones a los datos mediante Spark SQL y, a continuación, guarda los resultados transformados en un bucket de Amazon S3.
from awsglue.transforms import * from pyspark.context import SparkContext from awsglue.context import GlueContext from pyspark.sql.types import * from pyspark.sql.functions import * from awsglue.job import Job import json from pyspark.sql.types import StructType sc = SparkContext.getOrCreate() glueContext = GlueContext(sc) spark = glueContext.spark_session job = Job(glueContext) gdc_database = "s3://aws-glue-scripts-us-east-1-gamma/demo-database/" schema_location = ( "s3://aws-glue-scripts-us-east-1-gamma/DataFiles/" ) products_schema_string = spark.read.text( f"{schema_location}schemas/products_schema" ).first()[0] product_schema = StructType.fromJson(json.loads(products_schema_string)) products_source_df = ( spark.read.option("header", "true") .schema(product_schema) .option( "path", f"{gdc_database}products/", ) .csv(f"{gdc_database}products/") ) products_source_df.show() products_temp_view_name = "spark_upgrade_demo_product_view" products_source_df.createOrReplaceTempView(products_temp_view_name) query = f"select {products_temp_view_name}.*, format_string('%0$s-%0$s', category, subcategory) as unique_category from {products_temp_view_name}" products_with_combination_df = spark.sql(query) products_with_combination_df.show() products_with_combination_df.createOrReplaceTempView(products_temp_view_name) product_df_attribution = spark.sql( f""" SELECT *, unbase64(split(product_name, ' ')[0]) as product_name_decoded, unbase64(split(unique_category, '-')[1]) as subcategory_decoded FROM {products_temp_view_name} """ ) product_df_attribution.show() product_df_attribution.write.mode("overwrite").option("header", "true").option( "path", f"{gdc_database}spark_upgrade_demo_product_agg/" ).saveAsTable("spark_upgrade_demo_product_agg", external=True) spark_upgrade_demo_product_agg_table_df = spark.sql( f"SHOW TABLE EXTENDED in default like 'spark_upgrade_demo_product_agg'" ) spark_upgrade_demo_product_agg_table_df.show() job.commit()
from awsglue.transforms import * from pyspark.context import SparkContext from awsglue.context import GlueContext from pyspark.sql.types import * from pyspark.sql.functions import * from awsglue.job import Job import json from pyspark.sql.types import StructType sc = SparkContext.getOrCreate() glueContext = GlueContext(sc) spark = glueContext.spark_session # change 1 spark.conf.set("spark.sql.adaptive.enabled", "false") # change 2 spark.conf.set("spark.sql.legacy.pathOptionBehavior.enabled", "true") job = Job(glueContext) gdc_database = "s3://aws-glue-scripts-us-east-1-gamma/demo-database/" schema_location = ( "s3://aws-glue-scripts-us-east-1-gamma/DataFiles/" ) products_schema_string = spark.read.text( f"{schema_location}schemas/products_schema" ).first()[0] product_schema = StructType.fromJson(json.loads(products_schema_string)) products_source_df = ( spark.read.option("header", "true") .schema(product_schema) .option( "path", f"{gdc_database}products/", ) .csv(f"{gdc_database}products/") ) products_source_df.show() products_temp_view_name = "spark_upgrade_demo_product_view" products_source_df.createOrReplaceTempView(products_temp_view_name) # change 3 query = f"select {products_temp_view_name}.*, format_string('%1$s-%1$s', category, subcategory) as unique_category from {products_temp_view_name}" products_with_combination_df = spark.sql(query) products_with_combination_df.show() products_with_combination_df.createOrReplaceTempView(products_temp_view_name) # change 4 product_df_attribution = spark.sql( f""" SELECT *, try_to_binary(split(product_name, ' ')[0], 'base64') as product_name_decoded, try_to_binary(split(unique_category, '-')[1], 'base64') as subcategory_decoded FROM {products_temp_view_name} """ ) product_df_attribution.show() product_df_attribution.write.mode("overwrite").option("header", "true").option( "path", f"{gdc_database}spark_upgrade_demo_product_agg/" ).saveAsTable("spark_upgrade_demo_product_agg", external=True) spark_upgrade_demo_product_agg_table_df = spark.sql( f"SHOW TABLE EXTENDED in default like 'spark_upgrade_demo_product_agg'" ) spark_upgrade_demo_product_agg_table_df.show() job.commit()

Según el resumen, hay cuatro cambios propuestos por AWS Glue para actualizar correctamente el script de AWS Glue 2.0 a AWS Glue 4.0:
-
Configuración de Spark SQL (spark.sql.adaptive.enabled): este cambio tiene por objeto restaurar el comportamiento de la aplicación. A partir de Spark 3.2, se ha introducido una nueva característica para la ejecución adaptativa de consultas de Spark SQL. Puede inspeccionar este cambio de configuración y habilitarlo o deshabilitarlo según sus preferencias.
-
Cambio de la API de DataFrame: la opción de ruta no puede coexistir con otras operaciones de DataFrameReader como
load(). Para retener el comportamiento anterior, AWS Glue actualizó el script para agregar una nueva configuración de SQL (spark.sql.legacy.pathOptionBehavior.enabled). -
Cambio de la API de Spark SQL: se ha actualizado el comportamiento de
strfmtenformat_string(strfmt, obj, ...)para que no se permita0$como primer argumento. Para garantizar la compatibilidad, AWS Glue ha modificado el script para usar1$como primer argumento. -
Cambio de la API de SQL de Spark: la función
unbase64no permite ingresar cadenas mal formadas. Para retener el comportamiento anterior, AWS Glue actualizó el script para usar la funcióntry_to_binary.
Detención de un análisis de actualización en curso
Puede cancelar un análisis de actualización en curso o simplemente detenerlo.
-
Elija la pestaña Análisis de actualizaciones.
-
Seleccione el trabajo que se está ejecutando y, a continuación, elija Detener. Esto detendrá el análisis. A continuación, puede ejecutar otro análisis de actualizaciones en el mismo trabajo.

Consideraciones
Al comenzar a usar las actualizaciones de Spark, hay varios aspectos importantes que debe tener en cuenta para un uso óptimo del servicio.
-
Alcance y limitaciones del servicio: la versión actual se centra en la actualización de código PySpark desde la versión 2.0 hasta la versión 5.0 de AWS Glue. En este momento, el servicio gestiona el código de PySpark que no depende de dependencias de biblioteca adicionales. Puede ejecutar actualizaciones automatizadas de hasta 10 trabajos simultáneamente en una cuenta de AWS, lo que le permite actualizar varios trabajos de manera eficiente y, al mismo tiempo, mantener la estabilidad del sistema.
-
Solo se admiten trabajos de PySpark.
-
El tiempo de espera del análisis de actualizaciones se agota después de 24 horas.
-
Solo se puede ejecutar un análisis de actualización activo a la vez para un trabajo. Se pueden ejecutar hasta 10 análisis de actualización activos a la vez por cuenta.
-
-
Optimización de los costos durante el proceso de actualización: dado que las actualizaciones de Spark utilizan IA generativa para validar el plan de actualización en varias iteraciones, y cada iteración se ejecuta como una tarea de AWS Glue en su cuenta, es esencial optimizar las configuraciones de ejecución de las tareas de validación para lograr una mayor rentabilidad. Para lograrlo, le recomendamos que especifique una configuración de ejecución al iniciar un análisis de actualización de la siguiente manera:
-
Utilice cuentas de desarrolladores que no sean de producción y seleccione conjuntos de datos simulados de muestra que representen los datos de producción, pero que sean más pequeños para validarlos con la función Actualizaciones de Spark.
-
Utilice recursos de computación del tamaño adecuado, como los trabajadores de G.1X, y seleccione un número adecuado de procesos de trabajo para procesar los datos de la muestra.
-
Habilite el escalado automático de los trabajos de AWS Glue cuando sea aplicable para ajustar automáticamente los recursos en función de la carga de trabajo.
Por ejemplo, si el trabajo de producción procesa terabytes de datos con 20 procesos de trabajo de G.2X, puede configurar el trabajo de actualización para procesar unos pocos gigabytes de datos representativos con 2 procesos de trabajo de G.2X y activar el escalado automático para la validación.
-
-
Prácticas recomendadas: se recomienda iniciar el proceso de actualización con trabajos que no estén en producción. Este enfoque le permite familiarizarse con el flujo de trabajo de actualización y entender cómo el servicio gestiona los distintos tipos de patrones de código de Spark.
-
Alarmas y notificaciones: cuando utilice la característica de actualizaciones con IA generativa en un trabajo, asegúrese de que estén desactivadas las alarmas o notificaciones en caso de ejecución con errores de un trabajo. Durante el proceso de actualización, es posible que se produzcan errores al ejecutar hasta 10 trabajos en su cuenta antes de que se proporcionen los artefactos actualizados.
-
Reglas de detección de anomalías: desactive también las reglas de detección de anomalías en el trabajo que se está actualizando, ya que los datos escritos en las carpetas de salida durante las ejecuciones intermedias del trabajo podrían no tener el formato esperado mientras la validación de la actualización se encuentra en curso.
-
Utilice el análisis de actualización con trabajos de idempotencia: utilice el análisis de actualización con trabajos de idempotencia para garantizar que cada intento de ejecución posterior de un trabajo de validación sea similar al anterior y no presente problemas. Los trabajos de idempotencia son trabajos que se pueden ejecutar varias veces con los mismos datos de entrada y que producirán el mismo resultado cada vez. Cuando se utilicen las actualizaciones de IA generativa para Apache Spark en AWS Glue, el servicio ejecutará varias iteraciones de su trabajo como parte del proceso de validación. Durante cada iteración, realizará cambios en el código y las configuraciones de Spark para validar el plan de actualización. Si su trabajo de Spark no es de idempotencia, ejecutarlo varias veces con los mismos datos de entrada podría provocar problemas.
Regiones admitidas
Las actualizaciones con IA generativa para Apache Spark están disponibles en las siguientes regiones:
-
Asia-Pacífico: Tokio (ap-northeast-1), Seúl (ap-northeast-2), Mumbai (ap-south-1), Singapur (ap-southeast-1) y Sídney (ap-southeast-2)
-
América del Norte: Canadá (ca-central-1)
-
Europa: Fráncfort (eu-central-1), Estocolmo (eu-north-1), Irlanda (eu-west-1), Londres (eu-west-2) y París (eu-west-3)
-
América del Sur: São Paulo (sa-east-1)
-
Estados Unidos: norte de Virginia (us-east-1), Ohio (us-east-2) y Oregón (us-west-2)
Inferencia entre regiones en Spark Upgrades
Spark Upgrades funciona con Amazon Bedrock y aprovecha la inferencia entre regiones (CRIS). Con CRIS, Spark Upgrades seleccionará automáticamente la región óptima de su zona geográfica (tal y como se describe con más detalle aquí) para procesar su solicitud de inferencia, maximizar los recursos de computación disponibles y la disponibilidad del modelo, además de ofrecer la mejor experiencia al cliente. El uso de la inferencia entre regiones no conlleva ningún costo adicional.
Las solicitudes de inferencia entre regiones se mantienen dentro de las regiones de AWS que forman parte de la zona geográfica en la que se encuentran originalmente los datos. Por ejemplo, una solicitud realizada en EE. UU. se mantiene dentro de las regiones de AWS de EE. UU. Si bien los datos solo permanecen almacenados en la región principal, cuando utiliza la inferencia entre regiones, las peticiones de entrada y los resultados de salida pueden llevarse fuera de la región principal. Todos los datos se transmitirán cifrados a través de la red segura de Amazon.
