Aviso de fin de soporte: el 7 de octubre de 2026,AWS suspenderemos el soporte para AWS IoT Greengrass Version 1. Después del 7 de octubre de 2026, ya no podrá acceder a los AWS IoT Greengrass V1 recursos. Para obtener más información, visita Migrar desde AWS IoT Greengrass Version 1.
Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Cómo realizar la inferencia de machine learning
Esta función está disponible para AWS IoT Greengrass Core v1.6 o posterior.
Con ella AWS IoT Greengrass, puede realizar inferencias de aprendizaje automático (ML) en el borde de los datos generados localmente mediante modelos entrenados en la nube. Benefíciese de la baja latencia y el ahorro de costos que supone la ejecución de inferencias locales, aprovechando al mismo tiempo la potencia de cómputo de la nube para el entrenamiento de modelos y el procesamiento complejo.
Para comenzar a realizar la inferencia local, consulte Cómo configurar la inferencia de aprendizaje automático mediante el Consola de administración de AWS.
Cómo AWS IoT Greengrass La inferencia de aprendizaje automático funciona
Puede entrenar sus modelos de inferencia en cualquier lugar, desplegarlos localmente como recursos de machine learning en un grupo de Greengrass y luego acceder a ellos desde las funciones de Lambda de Greengrass. Por ejemplo, puede crear y entrenar modelos de aprendizaje profundo en SageMaker IA
El siguiente diagrama muestra el flujo de trabajo de inferencia de AWS IoT Greengrass aprendizaje automático.
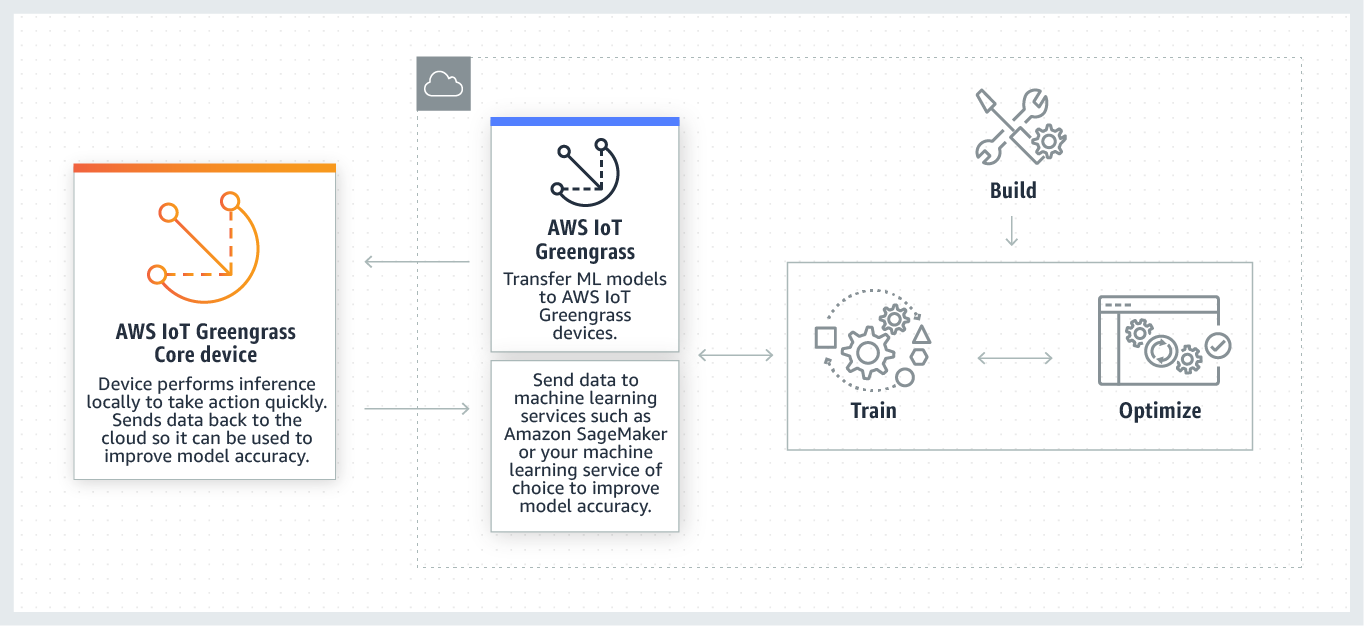
AWS IoT Greengrass La inferencia de aprendizaje automático simplifica cada paso del flujo de trabajo de aprendizaje automático, lo que incluye:
-
La creación e implementación de prototipos de marco de trabajo de machine learning.
-
El acceso a modelos entrenados en la nube y su implementación en dispositivos del núcleo de Greengrass.
-
La creación de aplicaciones de inferencia que pueden obtener acceso a aceleradores de hardware (como GPU y FPGA) como recursos locales.
Recursos de machine learning
Los recursos de aprendizaje automático representan modelos de inferencia entrenados en la nube que se implementan en un núcleo. AWS IoT Greengrass Para implementar recursos de machine learning, primero debe añadirlos a un grupo de Greengrass y, a continuación, definir cómo podrán obtener acceso a ellos las funciones de Lambda de dicho grupo. Durante el despliegue grupal, AWS IoT Greengrass recupera los paquetes del modelo fuente de la nube y los extrae a directorios dentro del espacio de nombres de tiempo de ejecución de Lambda. A continuación, las funciones de Lambda de Greengrass utilizan los modelos implementados localmente para llevar a cabo la inferencia.
Para actualizar un modelo implementado localmente, primero debe actualizar el modelo de origen (en la nube) correspondiente al recurso de machine learning y, a continuación, implementar el grupo. Durante la implementación, AWS IoT Greengrass comprueba si existen cambios en el origen. Si se detectan cambios, AWS IoT Greengrass actualiza el modelo local.
Orígenes de modelos admitidos
AWS IoT Greengrass admite fuentes de modelos de SageMaker IA y Amazon S3 para recursos de aprendizaje automático.
Los siguientes requisitos se aplican a los orígenes de modelos:
-
Los buckets de S3 que almacenan sus fuentes de modelos de SageMaker IA y Amazon S3 no deben cifrarse con SSE-C. En el caso de los buckets que utilizan el cifrado del lado del servidor, la inferencia de AWS IoT Greengrass aprendizaje automático actualmente solo admite las SSE-S3 opciones de cifrado o. SSE-KMS Para obtener más información sobre las opciones de cifrado del lado del servidor, consulte Protección de datos con el cifrado del lado del servidor en la Guía del usuario de Amazon Simple Storage Service.
-
Los nombres de los buckets de S3 que almacenan las fuentes de los modelos SageMaker AI y Amazon S3 no deben incluir puntos (
.). Para obtener más información, consulte la regla sobre el uso de buckets virtuales de estilo host con SSL en Reglas para la nomenclatura del bucket en la Guía del usuario de Amazon Simple Storage Service. -
Service-level Región de AWS el soporte debe estar disponible tanto para la IA como para AWS IoT Greengrassla SageMaker IA. Actualmente, AWS IoT Greengrass es compatible con los modelos de SageMaker IA en las siguientes regiones:
-
Este de EE. UU. (Ohio)
-
Este de EE. UU. (Norte de Virginia)
-
Oeste de EE. UU. (Oregón)
-
Asia-Pacífico (Bombay)
-
Asia-Pacífico (Seúl)
-
Asia-Pacífico (Singapur)
-
Asia-Pacífico (Sídney)
-
Asia-Pacífico (Tokio)
-
Europa (Fráncfort)
-
Europa (Irlanda)
-
Europa (Londres)
-
-
AWS IoT Greengrass debe tener
readpermiso para acceder a la fuente del modelo, tal y como se describe en las siguientes secciones.
- SageMaker IA
-
AWS IoT Greengrass admite modelos que se guardan como trabajos de entrenamiento de SageMaker IA. SageMaker La IA es un servicio de aprendizaje automático totalmente gestionado que se puede utilizar para crear y entrenar modelos mediante algoritmos integrados o personalizados. Para obtener más información, consulta ¿Qué es la SageMaker IA? en la Guía para desarrolladores de SageMaker IA.
Si configuraste tu entorno de SageMaker IA mediante la creación de un bucket cuyo nombre contiene
sagemaker, entonces AWS IoT Greengrass tienes permisos suficientes para acceder a tus trabajos de formación en SageMaker IA. La política administrada deAWSGreengrassResourceAccessRolePolicypermite el acceso a los buckets cuyo nombre contiene la cadenasagemaker. Esta política está asociada al rol de servicio de Greengrass.De lo contrario, debes conceder AWS IoT Greengrass
readpermiso al depósito en el que está almacenado tu trabajo de formación. Para ello, integre la siguiente política insertada en el rol de servicio. Puede incluir varios ARN de bucket. - Amazon S3
-
AWS IoT Greengrass admite modelos que se almacenan en Amazon S3 como
tar.gz.ziparchivos.Para permitir el acceso AWS IoT Greengrass a los modelos que están almacenados en los buckets de Amazon S3, debe conceder AWS IoT Greengrass
readpermiso para acceder a los buckets mediante una de las siguientes acciones:-
Almacene el modelo en un bucket cuyo nombre contenga
greengrass.La política administrada de
AWSGreengrassResourceAccessRolePolicypermite el acceso a los buckets cuyo nombre contiene la cadenagreengrass. Esta política está asociada al rol de servicio de Greengrass. -
Incruste una política insertada en el rol de servicio de Greengrass.
Si el nombre del bucket no contiene
greengrass, añada la siguiente política insertada al rol de servicio. Puede incluir varios ARN de bucket.Para obtener más información, consulte Integración de políticas insertadas en la Guía de usuario de IAM.
-
Requisitos
Los siguientes requisitos se aplican para crear y utilizar recursos de machine learning:
-
Debe utilizar AWS IoT Greengrass Core v1.6 o una versión posterior.
-
User-defined Las funciones Lambda pueden realizar
readuread and writeoperaciones en el recurso. Los permisos para otras operaciones no están disponibles. El modo de creación de contenedores de las funciones de Lambda afiliadas determina cómo configura los permisos de acceso. Para obtener más información, consulte Acceso a recursos de machine learning desde funciones de Lamba. -
Debe proporcionar la ruta completa del recurso en el sistema operativo del dispositivo del núcleo.
-
Un nombre o ID de recursos debe tener un máximo de 128 caracteres y utilizar el patrón
[a-zA-Z0-9:_-]+.
Entornos de ejecución y bibliotecas para la inferencia de machine learning
Puede utilizar los siguientes tiempos de ejecución y bibliotecas de aprendizaje automático con. AWS IoT Greengrass
-
Tiempo de ejecución de aprendizaje profundo de Amazon SageMaker Neo
-
Apache MXNet
-
TensorFlow
Estas bibliotecas y entornos de ejecución precompilados se pueden instalar en plataformas NVIDIA Jetson TX2, Intel Atom y Raspberry Pi. Para obtener información sobre la descarga, consulte Bibliotecas y entornos de ejecución de aprendizaje automático compatibles. Puede instalarlos directamente en el dispositivo central.
Asegúrese de leer la siguiente información sobre la compatibilidad y las limitaciones.
SageMaker Tiempo de ejecución de aprendizaje profundo de AI Neo
Puede utilizar el tiempo de ejecución de aprendizaje profundo de SageMaker AI Neo para realizar inferencias con modelos de aprendizaje automático optimizados en sus AWS IoT Greengrass dispositivos. Estos modelos se optimizan con el compilador de aprendizaje profundo SageMaker AI Neo para mejorar las velocidades de predicción de inferencias del aprendizaje automático. Para obtener más información sobre la optimización de modelos en SageMaker IA, consulte la documentación de SageMaker AI Neo.
nota
Actualmente, puede optimizar los modelos de machine learning utilizando el compilador de aprendizaje profundo Neo únicamente en regiones específicas de Amazon Web Services. Sin embargo, puede utilizar el entorno de ejecución de aprendizaje profundo de Neo con modelos optimizados en todos los Región de AWS casos en los que se admita el AWS IoT Greengrass núcleo. Para obtener más información, consulte cómo configurar la inferencia de machine learning optimizado.
Control de versiones de MXNet
Apache MXNet no garantiza actualmente la compatibilidad con versiones posteriores, por lo que es posible que los modelos que entrene utilizando versiones posteriores del marco de trabajo no funcionen correctamente en versiones anteriores de dicho marco de trabajo. Para evitar conflictos entre el entrenamiento de modelos y las etapas de distribución de modelos, así como para proporcionar una experiencia integral uniforme, utilice la misma versión del marco de trabajo MXNet en ambas etapas.
MXNet en Raspberry Pi
Las funciones de Lambda de Greengrass que obtienen acceso a los modelos de MXNet locales deben definir la siguiente variable de entorno:
MXNET_ENGINE_TYPE=NativeEngine
Puede definir la variable de entorno en el código de la característica o agregarla a la configuración específica del grupo de la característica. Para ver un ejemplo acerca de cómo agregarla como una opción de configuración, consulte este paso.
nota
Para hacer un uso general del marco MXNet (por ejemplo, ejecutar un ejemplo de código de terceros), la variable de entorno debe estar configurada en Raspberry Pi.
TensorFlow limitaciones de servicio de modelos en Raspberry Pi
Las siguientes recomendaciones para mejorar los resultados de las inferencias se basan en nuestras pruebas con las bibliotecas Arm de TensorFlow 32 bits de la plataforma Raspberry Pi. Estas recomendaciones van dirigidas a usuarios avanzados únicamente a modo de referencia, sin garantías de ningún tipo.
-
Los modelos que se entrenan con el formato de punto de comprobación
deberían "congelarse" en el formato del búfer del protocolo antes de su distribución. Para ver un ejemplo, consulte la biblioteca de modelos TensorFlow-Slim de clasificación de imágenes . -
No utilices las TF-Slim bibliotecas TF-Estimator y ni en el código de entrenamiento ni en el de inferencia. En su lugar, utilice el patrón de archivo de carga de modelos
.pbque se muestra en el ejemplo siguiente.graph = tf.Graph() graph_def = tf.GraphDef() graph_def.ParseFromString(pb_file.read()) with graph.as_default(): tf.import_graph_def(graph_def)
nota
Para obtener más información sobre las plataformas compatibles TensorFlow, consulte Instalación TensorFlow
