Aviso de fin de soporte: el 7 de octubre de 2026,AWS suspenderemos el soporte para AWS IoT Greengrass Version 1. Después del 7 de octubre de 2026, ya no podrá acceder a los AWS IoT Greengrass V1 recursos. Para obtener más información, visita Migrar desde AWS IoT Greengrass Version 1.
Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Exporte flujos de datos al Nube de AWS (CLI)
En este tutorial, se muestra cómo usarlo AWS CLI para configurar e implementar un AWS IoT Greengrass grupo con el administrador de transmisiones activado. El grupo contiene una función de Lambda definida por el usuario que escribe en una secuencia en el administrador de flujos, que luego se exporta automáticamente a la Nube de AWS.
El administrador de flujos hace que la asimilación, el procesamiento y la exportación de flujos de datos de gran volumen sea más eficiente y fiable. En este tutorial, va a crear una función de Lambda de TransferStream que consume datos de IoT. La función Lambda usa el SDK AWS IoT Greengrass principal para crear una transmisión en el administrador de transmisiones y, a continuación, leer y escribir en ella. El administrador de flujos exporta la secuencia al Flujo de datos Kinesis. En el siguiente diagrama se muestra este flujo de trabajo.
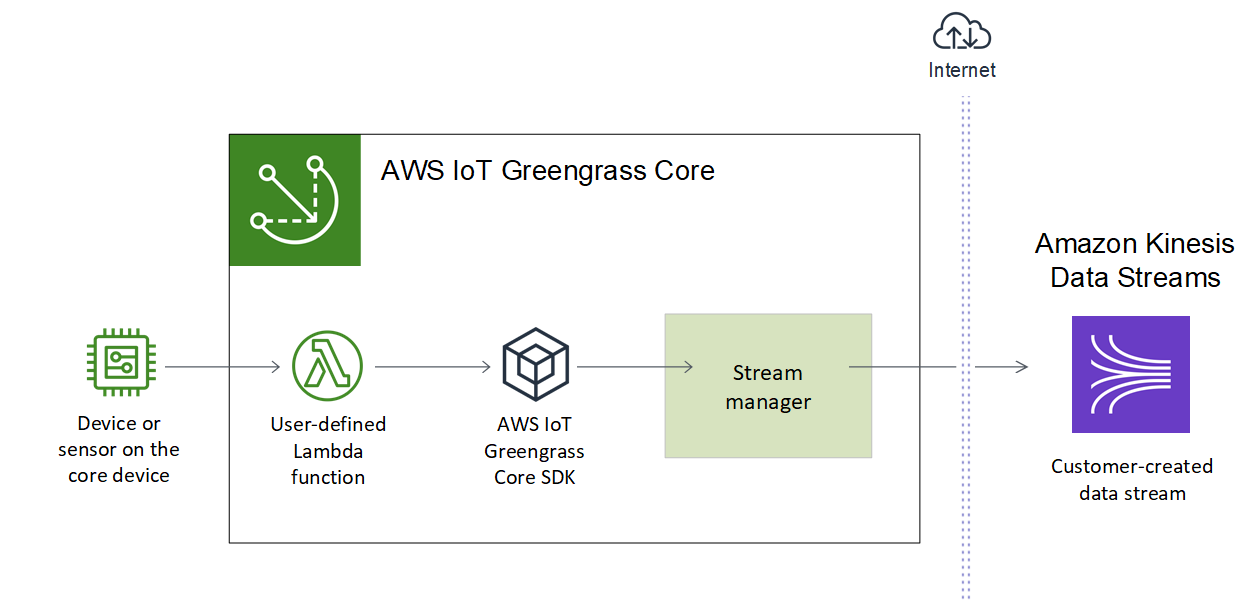
El objetivo de este tutorial es mostrar cómo las funciones Lambda definidas por el usuario utilizan StreamManagerClient el objeto del SDK principal para interactuar con AWS IoT Greengrass el administrador de transmisiones. Para simplificar, la función de Lambda que va a crear en este tutorial genera datos de dispositivos simulados.
Cuando utilizas la AWS IoT Greengrass API, que incluye los comandos de Greengrass en AWS CLI, para crear un grupo, el administrador de transmisiones está deshabilitado de forma predeterminada. Para habilitar el administrador de flujos en su núcleo, cree una versión de definición de función que incluya la función de Lambda de GGStreamManager del sistema y una versión de grupo que haga referencia a la nueva versión de definición de función. A continuación, implemente el grupo.
Requisitos previos
Para completar este tutorial, se necesita lo siguiente:
-
Un grupo de Greengrass y un núcleo de Greengrass (versión 1.10 o posterior). Para obtener información acerca de cómo crear un núcleo y un grupo de Greengrass, consulte Introducción al AWS IoT Greengrass. El tutorial de introducción también incluye los pasos para instalar el software AWS IoT Greengrass principal.
nota
El administrador de transmisiones no es compatible con las OpenWrt distribuciones.
-
Java 8 Runtime (JDK 8) instalado en el dispositivo principal.
-
Para Debian-based distribuciones (incluida Raspbian) o Ubuntu-based distribuciones, ejecuta el siguiente comando:
sudo apt install openjdk-8-jdk -
Para Hat-based las distribuciones Red (incluida Amazon Linux), ejecute el siguiente comando:
sudo yum install java-1.8.0-openjdkPara obtener más información, consulte How to download and install prebuilt OpenJDK packages (Cómo descargar e instalar paquetes OpenJDK preconfigurados)
en la documentación de OpenJDK.
-
-
AWS IoT Greengrass Core SDK para Python v1.5.0 o posterior. Para usar
StreamManagerClienten el SDK de AWS IoT Greengrass Core para Python, debe:-
Instalar Python 3.7 o versiones posteriores en el dispositivo principal.
-
Incluya el SDK y sus dependencias en su paquete de implementación de la función de Lambda. Se incluyen las instrucciones en este tutorial.
sugerencia
Puede usar
StreamManagerClientcon Java o NodeJS. Para ver código de ejemplo, consulta el AWS IoT Greengrass Core SDK for Javay el AWS IoT Greengrass Core SDK para más Node.js información GitHub. -
-
Una transmisión de destino denominada
MyKinesisStreamcreada en Amazon Kinesis Data Streams al Región de AWS igual que su grupo de Greengrass. Para obtener más información, consulte Crear un flujo en la Guía para desarrolladores de Amazon Kinesis.nota
En este tutorial, el administrador de flujos exporta datos a Kinesis Data Streams, lo que deriva en cargos a su Cuenta de AWS. Para obtener información acerca de los precios, consulte Precios de Kinesis Data Streams
. Para no incurrir en gastos, puede ejecutar este tutorial sin crear una secuencia de datos Kinesis. En este caso, compruebe los registros para ver si el administrador de flujos intentó exportar la secuencia al flujo de datos Kinesis.
-
Una política de IAM agregada al Rol de grupo de Greengrass que permita la acción de
kinesis:PutRecordsen el flujo de datos de destino, tal y como se muestra en el siguiente ejemplo:
-
La AWS CLI instalada y configurada en su ordenador. Para obtener más información, consulte Instalación de la AWS Command Line Interface y Configuración de la AWS CLI en la Guía del usuario de la AWS Command Line Interface .
Los comandos de ejemplo de este tutorial están escritos para Linux y otros Unix-based sistemas. Si utiliza Windows, consulte Especificar valores de parámetros para la interfaz de línea de AWS comandos para obtener más información sobre las diferencias de sintaxis.
Si el comando contiene una cadena JSON, el tutorial ofrece un ejemplo que tiene el JSON en una sola línea. En algunos sistemas, puede que sea más eficiente editar y ejecutar comandos con este formato.
El tutorial contiene los siguientes pasos generales:
Completar el tutorial debería tomarle aproximadamente 30 minutos.
Paso 1: Creación de un paquete de implementación de la función de Lambda
En este paso, va a crear un paquete de implementación de funciones de Lambda que contiene código de función y dependencias de Python. Cargará este paquete más adelante cuando cree la función de Lambda en AWS Lambda. La función Lambda usa el SDK AWS IoT Greengrass principal para crear transmisiones locales e interactuar con ellas.
nota
Sus funciones de Lambda definidas por el usuario deben utilizar el SDK de AWS IoT Greengrass Core para interactuar con el administrador de flujos. Para obtener más información sobre los requisitos del administrador de secuencias de Greengrass, consulte Requisitos del administrador de secuencias de Greengrass.
-
Descargue la versión 1.5.0 o posterior del SDK de AWS IoT Greengrass Core para Python.
-
Descomprima el paquete descargado para obtener el SDK. El SDK es la carpeta
greengrasssdk. -
Instale dependencias de paquetes para incluirlas con el SDK en su paquete de implementación de funciones de Lambda.
-
Vaya al directorio de SDK que contiene el archivo de
requirements.txt. Este archivo registra las dependencias. -
Instale las dependencias del SDK. Por ejemplo, ejecute el siguiente comando de
pippara instalarlas en el directorio actual:pip install --target . -r requirements.txt
-
-
Guarde la siguiente función de código de Python en un archivo local llamado "
transfer_stream.py".sugerencia
Para ver un ejemplo de código que usa Java y Nodejs, consulta AWS IoT Greengrass Core SDK for Java AWS IoT Greengrass y Core
SDK para obtener más información. Node.js GitHub import asyncio import logging import random import time from greengrasssdk.stream_manager import ( ExportDefinition, KinesisConfig, MessageStreamDefinition, ReadMessagesOptions, ResourceNotFoundException, StrategyOnFull, StreamManagerClient, ) # This example creates a local stream named "SomeStream". # It starts writing data into that stream and then stream manager automatically exports # the data to a customer-created Kinesis data stream named "MyKinesisStream". # This example runs forever until the program is stopped. # The size of the local stream on disk will not exceed the default (which is 256 MB). # Any data appended after the stream reaches the size limit continues to be appended, and # stream manager deletes the oldest data until the total stream size is back under 256 MB. # The Kinesis data stream in the cloud has no such bound, so all the data from this script is # uploaded to Kinesis and you will be charged for that usage. def main(logger): try: stream_name = "SomeStream" kinesis_stream_name = "MyKinesisStream" # Create a client for the StreamManager client = StreamManagerClient() # Try deleting the stream (if it exists) so that we have a fresh start try: client.delete_message_stream(stream_name=stream_name) except ResourceNotFoundException: pass exports = ExportDefinition( kinesis=[KinesisConfig(identifier="KinesisExport" + stream_name, kinesis_stream_name=kinesis_stream_name)] ) client.create_message_stream( MessageStreamDefinition( name=stream_name, strategy_on_full=StrategyOnFull.OverwriteOldestData, export_definition=exports ) ) # Append two messages and print their sequence numbers logger.info( "Successfully appended message to stream with sequence number %d", client.append_message(stream_name, "ABCDEFGHIJKLMNO".encode("utf-8")), ) logger.info( "Successfully appended message to stream with sequence number %d", client.append_message(stream_name, "PQRSTUVWXYZ".encode("utf-8")), ) # Try reading the two messages we just appended and print them out logger.info( "Successfully read 2 messages: %s", client.read_messages(stream_name, ReadMessagesOptions(min_message_count=2, read_timeout_millis=1000)), ) logger.info("Now going to start writing random integers between 0 and 1000 to the stream") # Now start putting in random data between 0 and 1000 to emulate device sensor input while True: logger.debug("Appending new random integer to stream") client.append_message(stream_name, random.randint(0, 1000).to_bytes(length=4, signed=True, byteorder="big")) time.sleep(1) except asyncio.TimeoutError: logger.exception("Timed out while executing") except Exception: logger.exception("Exception while running") def function_handler(event, context): return logging.basicConfig(level=logging.INFO) # Start up this sample code main(logger=logging.getLogger()) -
Comprima en un archivo ZIP los siguientes elementos en un archivo denominado "
transfer_stream_python.zip". Este es el paquete de implementación de la función de Lambda.-
transfer_stream.py. Lógica de la aplicación.
-
greengrasssdk. Biblioteca necesaria para las funciones de Lambda Greengrass de Python que publican mensajes MQTT.
Las operaciones de Stream Manager están disponibles en la versión 1.5.0 o posterior del AWS IoT Greengrass Core SDK para Python.
-
Las dependencias que instalaste para el SDK AWS IoT Greengrass principal para Python (por ejemplo, los
cbor2directorios).
Al crear el archivo de
zip, incluya solo estos elementos, no la carpeta que los contiene. -
Paso 2: creación de una función de Lambda
-
Cree un rol de IAM para poder pasar el ARN del rol cuando cree la función.
nota
AWS IoT Greengrass no usa este rol porque los permisos para sus funciones Lambda de Greengrass se especifican en el rol de grupo de Greengrass. En este tutorial, va a crear un rol vacío.
-
Copie la
Arndel resultado. -
Utilice la AWS Lambda API para crear la función.
TransferStreamEl siguiente comando da por hecho que el archivo ZIP está en el directorio actual.-
Reemplace
role-arnpor elArnque ha copiado.
aws lambda create-function \ --function-name TransferStream \ --zip-file fileb://transfer_stream_python.zip \ --rolerole-arn\ --handler transfer_stream.function_handler \ --runtime python3.7 -
-
Publique una versión de la función.
aws lambda publish-version --function-name TransferStream --description 'First version' -
Cree un alias a la versión publicada.
Los grupos de Greengrass pueden hacer referencia a una función de Lambda por versión o alias (recomendado). El uso de un alias facilita la gestión de las actualizaciones del código porque no tiene que cambiar la tabla de suscripción o la definición del grupo cuando se actualiza el código de la función. En su lugar, basta con apuntar el alias a la nueva versión de la función.
aws lambda create-alias --function-name TransferStream --name GG_TransferStream --function-version 1nota
AWS IoT Greengrass no admite los alias de Lambda para las versiones $LATEST.
-
Copie la
AliasArndel resultado. Este valor se utiliza al configurar la función para. AWS IoT Greengrass
Ahora está listo para configurar la función para AWS IoT Greengrass.
Paso 3: Crear una versión y una definición de la función
Este paso crea una versión de definición de función que hace referencia a la función de Lambda GGStreamManager del sistema y a la función de Lambda TransferStream definida por el usuario. Para habilitar el administrador de transmisiones al usar la AWS IoT Greengrass API, la versión de definición de funciones debe incluir la GGStreamManager función.
-
Cree una definición de función con una versión inicial que contenga las funciones de Lambda del sistema y definidas por el usuario.
Con la siguiente versión de definición se habilita al administrador de flujos con la configuración de parámetros predeterminada. Para configurar parámetros personalizados, debe definir variables de entorno para los parámetros correspondientes del administrador de flujos. Para ver un ejemplo, consultePara habilitar, deshabilitar o configurar el administrador de flujos (CLI). AWS IoT Greengrass utiliza la configuración predeterminada para los parámetros que se omiten.
MemorySizedebería ser al menos128000.Pinneddebe estar configurado entrue.nota
Una función Lambda de larga duración (o anclada) se inicia automáticamente después AWS IoT Greengrass del inicio y sigue ejecutándose en su propio contenedor. Esto contrasta con una función de Lambda bajo demanda, que se inicia cuando se la invoca y se detiene cuando no quedan tareas que ejecutar. Para obtener más información, consulte Configuración del ciclo de vida de las funciones de Lambda de Greengrass.
-
arbitrary-function-idSustitúyala por un nombre para la función, como.stream-manager -
alias-arnSustitúyalo por elAliasArnque copió al crear el alias de laTransferStreamfunción Lambda.
nota
Timeoutes necesario para la versión de definición de característica, peroGGStreamManagerno lo usa. Para obtener más información sobreTimeouty otras configuraciones a nivel de grupo, consulte Control de la ejecución de funciones de Lambda de Greengrass utilizando la configuración específica del grupo. -
-
Copie la
LatestVersionArndel resultado. Este valor se usa para añadir la versión de la definición de función a la versión de grupo que implementó en el núcleo.
Paso 4: Crear una versión y una definición del registrador
Defina la configuración de registro del grupo. En este tutorial, configurará los componentes AWS IoT Greengrass del sistema, las funciones Lambda definidas por el usuario y los conectores para escribir registros en el sistema de archivos del dispositivo principal. Puede usar registros para solucionar cualquier problema que pueda surgir. Para obtener más información, consulte Monitoreo con AWS IoT Greengrass registros.
-
Cree una definición del registro que incluya una versión inicial.
-
Copie el
LatestVersionArnde la definición del registro del resultado. Este valor se usa para añadir la versión de definición del registro a la versión del grupo que implementa en el núcleo.
Paso 5: Obtener el ARN de la versión de la definición del núcleo
Obtenga el ARN de la versión de definición del núcleo para agregar a su nueva versión de grupo. Para implementar una versión de grupo, debe hacer referencia a una versión de definición de núcleo que contenga exactamente un núcleo.
-
Obtenga los ID de la versión de grupo y grupo de Greengrass de destino. En este procedimiento, suponemos que estos son el último grupo y la última versión de grupo. La siguiente consulta devuelve el grupo creado más recientemente.
aws greengrass list-groups --query "reverse(sort_by(Groups, &CreationTimestamp))[0]"También puede hacer la consulta por nombre. No es necesario que los nombres de grupo sean únicos, por lo que podrían devolverse varios grupos.
aws greengrass list-groups --query "Groups[?Name=='MyGroup']"nota
También puede encontrar estos valores en la AWS IoT consola. El ID de grupo se muestra en la página Settings (Configuración) del grupo. Los ID de versión del grupo se muestran en la pestaña Implementaciones del grupo.
-
Copie el
Iddel grupo de destino de la salida. Puede utilizar esto para obtener la versión de la definición de núcleo y al implementar el grupo. -
Copie el
LatestVersiondel resultado, que es el ID de la última versión añadida al grupo. Puede utilizar esto para obtener la versión de la definición de núcleo. -
Obtenga el ARN de la versión de la definición principal:
-
Obtenga la versión de grupo.
-
group-idSustitúyalos por elIdque copió para el grupo. -
group-version-idSustitúyala por laLatestVersionque copiaste para el grupo.
aws greengrass get-group-version \ --group-idgroup-id\ --group-version-idgroup-version-id -
-
Copie la
CoreDefinitionVersionArndel resultado. Este valor se usa para añadir la versión de la definición del núcleo a la versión de grupo que implementó en el núcleo.
-
Paso 6: Crear una versión del grupo
Ahora, puede crear una versión de grupo que contenga las entidades que desea implementar. Para ello, cree una versión de grupo que haga referencia a la versión de destino de cada tipo de componente. Para este tutorial, incluirá una versión de definición de núcleo, una versión de definición de función y una versión de definición de registrador.
-
Cree una versión de grupo.
-
group-idSustitúyala por laIdque copiaste para el grupo. -
core-definition-version-arnSustitúyalo por elCoreDefinitionVersionArnque copió para la versión de definición básica. -
function-definition-version-arnSustitúyala por laLatestVersionArnque copiaste para la nueva versión de definición de funciones. -
logger-definition-version-arnSustitúyala por laLatestVersionArnque copiaste para tu nueva versión de definición de registrador.
aws greengrass create-group-version \ --group-idgroup-id\ --core-definition-version-arncore-definition-version-arn\ --function-definition-version-arnfunction-definition-version-arn\ --logger-definition-version-arnlogger-definition-version-arn -
-
Copie la
Versiondel resultado. Este es el ID de la nueva versión del grupo.
Paso 7: Crear una implementación
Implemente el grupo en el dispositivo del núcleo.
-
Cree una implementación de .
group-idSustitúyala por laIdque copiaste para el grupo.group-version-idSustitúyala por laVersionque copiaste para la nueva versión del grupo.
aws greengrass create-deployment \ --deployment-type NewDeployment \ --group-idgroup-id\ --group-version-idgroup-version-id -
Copie la
DeploymentIddel resultado. -
Obtenga el estado de las implementaciones.
group-idSustitúyala por laIdque copiaste para el grupo.deployment-idSustitúyalo por elDeploymentIdque copió para la implementación.
aws greengrass get-deployment-status \ --group-idgroup-id\ --deployment-iddeployment-idSi el estado es
Success, la implementación fue correcta. Para obtener ayuda sobre la resolución de problemas, consulte Resolución de problemas AWS IoT Greengrass.
Paso 8: Probar la aplicación
La función de Lambda TransferStream genera datos simulados del dispositivo. Escribe datos en una secuencia que el administrador de secuencias exporta a la secuencia de datos de Kinesis de destino.
-
En la consola de Amazon Kinesis, en Kinesis data Streams, elija. MyKinesisStream
nota
Si ejecutó el tutorial sin una secuencia de datos de Kinesis de destino, compruebe el archivo de registro del administrador de secuencias (
GGStreamManager). Si contieneexport stream MyKinesisStream doesn't existen un mensaje de error, la prueba se ha realizado correctamente. Este error significa que el servicio intentó exportar a la secuencia, pero que la secuencia no existe. -
En la MyKinesisStreampágina, elija Monitorización. Si la prueba se realiza correctamente, debería ver los datos en los gráficos Put Records. En función de la conexión, es posible que tarde un minuto en mostrar los datos.
importante
Cuando haya terminado la prueba, elimine la secuencia de datos de Kinesis para evitar incurrir en más gastos.
O ejecute el siguiente comando para detener el daemon de Greengrass. Así evitará que el núcleo envíe mensajes hasta que esté listo para continuar las pruebas.
cd /greengrass/ggc/core/ sudo ./greengrassd stop -
Elimine la función TransferStreamLambda del núcleo.
Siga Paso 6: Crear una versión del grupo para crear una nueva versión de grupo. pero elimine la opción
--function-definition-version-arnen el comandocreate-group-version. O bien, cree una versión de definición de función que no incluya la función TransferStreamLambda.nota
Al omitir la función de Lambda de
GGStreamManagerdel sistema de la versión de grupo implementada, se deshabilita la administración de secuencias en el núcleo.-
Siga Paso 7: Crear una implementación para implementar la nueva versión de grupo.
Para ver la información de registro o solucionar problemas con las secuencias, compruebe los registros para las funciones TransferStream y GGStreamManager. Debe tener root permisos para leer los AWS IoT Greengrass registros del sistema de archivos.
TransferStreamescribe entradas de registro engreengrass-root/ggc/var/log/user/region/account-id/TransferStream.logGGStreamManagerescribe entradas de registro engreengrass-root/ggc/var/log/system/GGStreamManager.log
Si necesita más información sobre la solución de problemas, puede establecer el nivel de registro de Lambda a DEBUG y, a continuación, crear e implementar una nueva versión de grupo.
Véase también
-
Exportación de configuraciones compatibles Nube de AWS destinos
-
Configuración AWS IoT Greengrass administrador de transmisiones
-
AWS Identity and Access Management (IAM) de la Referencia de AWS CLI comandos
-
AWS Lambda comandos de la Referencia de AWS CLI comandos
-
AWS IoT Greengrass comandos de la Referencia de AWS CLI comandos
