Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Exportación de configuraciones compatibles Nube de AWS destinos
User-defined Los componentes de Greengrass se utilizan StreamManagerClient en el SDK de Stream Manager para interactuar con el administrador de transmisiones. Cuando un componente crea un flujo o actualiza un flujo, pasa un objeto MessageStreamDefinition que representa las propiedades del flujo, incluida la definición de exportación. El objeto ExportDefinition contiene las configuraciones de exportación definidas para el flujo. El administrador de flujos utiliza estas configuraciones de exportación para determinar dónde y cómo exportar el flujo.
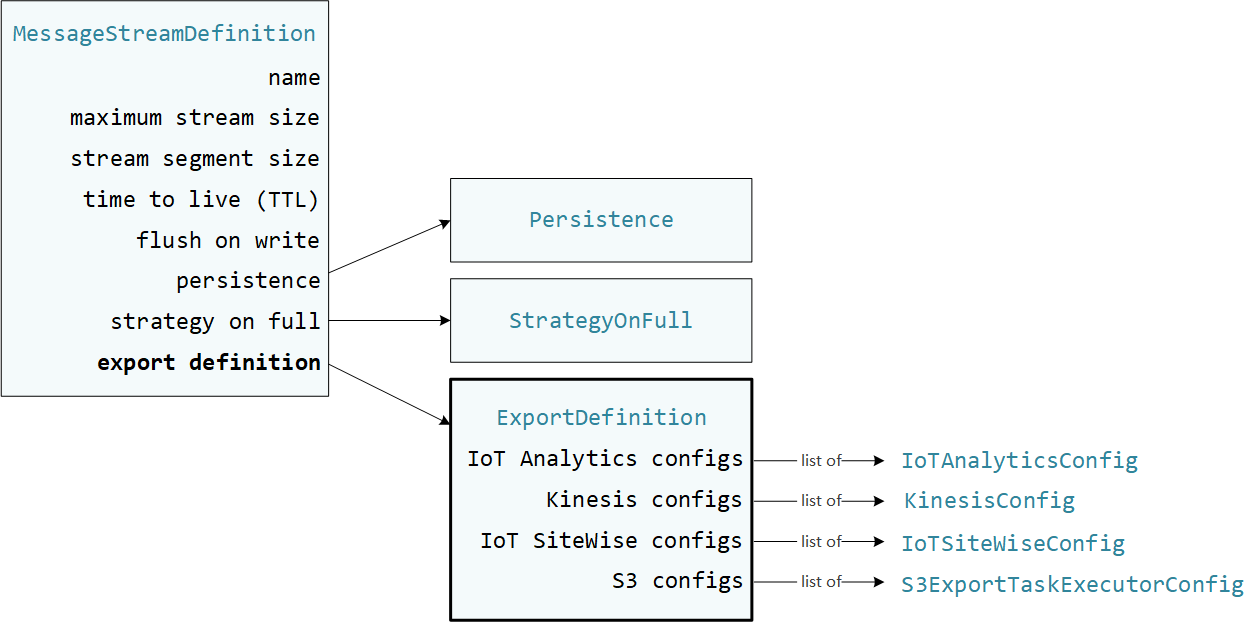
Puede definir cero o más configuraciones de exportación en un flujo, incluidas varias configuraciones de exportación para un único tipo de destino. Por ejemplo, puede exportar un flujo a dos canales AWS IoT Analytics y a un flujo de datos de Kinesis.
En caso de intentos de exportación fallidos, Stream Manager vuelve a intentar exportar los datos continuamente a Nube de AWS intervalos de hasta cinco minutos. La cantidad de reintentos no tiene un límite máximo.
nota
StreamManagerClient también proporciona un destino que puede utilizar para exportar secuencias a un servidor HTTP. Este destino está pensado solo con fines de prueba. No es estable y no se admite para su uso en entornos de producción.
Destinos compatibles Nube de AWS
Usted es responsable de mantener estos Nube de AWS recursos.
AWS IoT Analytics canales
Stream Manager admite la exportación automática a AWS IoT Analytics. AWS IoT Analytics le permite realizar análisis avanzados de sus datos para ayudarle a tomar decisiones empresariales y mejorar los modelos de aprendizaje automático. Para obtener más información, consulte ¿Qué es AWS IoT Analytics? en la Guía AWS IoT Analytics del usuario.
En el SDK del administrador de flujos, los componentes de Greengrass utilizan IoTAnalyticsConfig para definir la configuración de exportación para este tipo de destino. Para obtener más información, consulte la referencia del SDK para el lenguaje de destino.
-
IoTAnalyticsConfig
en el SDK de Python -
IoTAnalyticsConfig
en el SDK de Java -
IoTAnalyticsConfig
en el Node.js SDK
Requisitos
Este destino de exportación tiene los siguientes requisitos:
-
Los canales de destino AWS IoT Analytics deben estar en el mismo Cuenta de AWS y Región de AWS igual que el dispositivo principal de Greengrass.
-
El Autorizar a los dispositivos principales a interactuar con AWS los servicios debe permitir el permiso
iotanalytics:BatchPutMessagepara segmentar los canales. Por ejemplo:Puede conceder acceso granular o condicional a recursos (por ejemplo, utilizando un esquema de nomenclatura con comodín
*) Para obtener más información, consulte Adición y eliminación de políticas de IAM en la Guía del usuario de IAM.
Exportando a AWS IoT Analytics
Para crear una transmisión a la que se exporte AWS IoT Analytics, sus componentes de Greengrass crean una transmisión con una definición de exportación que incluye uno o más IoTAnalyticsConfig objetos. Este objeto define los ajustes de exportación, como el canal de destino, el tamaño del lote, el intervalo del lote y la prioridad.
Cuando sus componentes de Greengrass reciben datos de los dispositivos, anexan mensajes que contienen una masa de datos al flujo de destino.
A continuación, el administrador de flujos exporta los datos en función de los ajustes del lote y la prioridad definidos en las configuraciones de exportación del flujo.
Amazon Kinesis Data Streams
El administrador de flujos permite exportar automáticamente a Amazon Kinesis Data Streams. Kinesis Data Streams se utiliza normalmente para agregar grandes volúmenes de datos y cargarlos en un almacén MapReduce de datos o un clúster. Para obtener más información, consulte Qué son los Amazon Kinesis Data Streams en la Guía para desarrolladores de Amazon Kinesis.
En el SDK del administrador de flujos, los componentes de Greengrass utilizan KinesisConfig para definir la configuración de exportación para este tipo de destino. Para obtener más información, consulte la referencia del SDK para el lenguaje de destino.
-
KinesisConfig
en el SDK de Python -
KinesisConfig
en el SDK de Java -
KinesisConfig
en el Node.js SDK
Requisitos
Este destino de exportación tiene los siguientes requisitos:
-
Las transmisiones de destino de Kinesis Data Streams deben estar en el Cuenta de AWS mismo dispositivo principal de Greengrass Región de AWS y en el mismo.
-
(Recomendado) A partir de la versión 2.2.1, el administrador de transmisiones mejora el rendimiento de la exportación de transmisiones a destinos de Kinesis Data Streams. La versión 2.3.1 añade un ritmo adaptativo y compatible con los fragmentos, lo que aumenta aún más el rendimiento de las exportaciones. Para utilizar estas mejoras, actualiza tu componente de administrador de transmisiones a la versión más reciente. A continuación, concede el
kinesis:ListShardspermiso en la función de intercambio de fichas de Greengrass. Con este permiso, Stream Manager distribuye los registros entre los fragmentos del flujo de datos de destino y gestiona las solicitudes para mantenerse dentro de los límites por fragmento de Kinesis Data Streams. -
El Autorizar a los dispositivos principales a interactuar con AWS los servicios debe conceder el permiso
kinesis:PutRecordspara destinar flujos de datos. Por ejemplo:Puede conceder acceso granular o condicional a recursos (por ejemplo, utilizando un esquema de nomenclatura con comodín
*) Para obtener más información, consulte Adición y eliminación de políticas de IAM en la Guía del usuario de IAM.
Exportación a Kinesis Data Streams
Para crear un flujo que se exporte a Kinesis Data Streams, sus componentes de Greengrass crean un flujo con una definición de exportación que incluye uno o más objetos KinesisConfig. Este objeto define los ajustes de exportación, como el flujo de datos de destino, el tamaño del lote, el intervalo del lote y la prioridad.
Cuando sus componentes de Greengrass reciben datos de los dispositivos, anexan mensajes que contienen una masa de datos al flujo de destino. A continuación, el administrador de flujos exporta los datos en función de los ajustes del lote y la prioridad definidos en las configuraciones de exportación del flujo.
Cuando el administrador de transmisiones puede determinar el diseño de las particiones de la transmisión de datos de destino, distribuye los registros entre las particiones disponibles. Stream Manager también ajusta el ritmo de las solicitudes para mantenerse dentro de los límites por fragmento de Kinesis Data Streams. Si el administrador de transmisiones no puede determinar el diseño del fragmento, asigna un UUID aleatorio y único como clave de partición para cada registro que carga en Amazon Kinesis.
AWS IoT SiteWise propiedades de los activos
Stream Manager admite la exportación automática a AWS IoT SiteWise. AWS IoT SiteWise le permite recopilar, organizar y analizar datos de equipos industriales a escala. Para obtener más información, consulte ¿Qué es AWS IoT SiteWise? en la Guía AWS IoT SiteWise del usuario.
En el SDK del administrador de flujos, los componentes de Greengrass utilizan IoTSiteWiseConfig para definir la configuración de exportación para este tipo de destino. Para obtener más información, consulte la referencia del SDK para el lenguaje de destino.
-
IoTSiteWiseConfig
en el SDK de Python -
IoTSiteWiseConfig
en el SDK de Java -
IoTSiteWiseConfig
en el Node.js SDK
nota
AWS también proporciona AWS IoT SiteWise componentes, que ofrecen una solución prediseñada que puede utilizar para transmitir datos desde OPC-UA las fuentes. Para obtener más información, consulte Colector IoT SiteWise OPC UA.
Requisitos
Este destino de exportación tiene los siguientes requisitos:
-
Las propiedades de los activos de destino AWS IoT SiteWise deben estar en el mismo Cuenta de AWS y Región de AWS igual que el dispositivo principal de Greengrass.
nota
Para ver la lista de Región de AWS dispositivos AWS IoT SiteWise compatibles, consulte los AWS IoT SiteWise puntos finales y las cuotas en la Referencia AWS general.
-
Autorizar a los dispositivos principales a interactuar con AWS los serviciosEl
iotsitewise:BatchPutAssetPropertyValuedebe permitir que el permiso se dirija a las propiedades de los activos. El siguiente ejemplo de política utiliza la claveiotsitewise:assetHierarchyPathde condición para conceder acceso a un activo raíz de destino y a sus elementos secundarios. Puede eliminarlosConditionde la política para permitir el acceso a todos sus AWS IoT SiteWise activos o especificar los ARN de los activos individuales.Puede conceder acceso granular o condicional a recursos (por ejemplo, utilizando un esquema de nomenclatura con comodín
*) Para obtener más información, consulte Adición y eliminación de políticas de IAM en la Guía del usuario de IAM.Para obtener información de seguridad importante, consulte la BatchPutAssetPropertyValue autorización en la Guía del AWS IoT SiteWise usuario.
Exportación a AWS IoT SiteWise
Para crear una transmisión a la que se exporte AWS IoT SiteWise, sus componentes de Greengrass crean una transmisión con una definición de exportación que incluye uno o más IoTSiteWiseConfig objetos. Este objeto define los ajustes de exportación, como el tamaño del lote, el intervalo del lote y la prioridad.
Cuando sus componentes de Greengrass reciben datos de propiedad de activos, anexan mensajes que contienen datos al flujo de destino. Los mensajes son JSON-serialized PutAssetPropertyValueEntry objetos que contienen los valores de propiedad de una o más propiedades de un activo. Para obtener más información, consulte Añadir un mensaje para los AWS IoT SiteWise
destinos de exportación.
nota
Al enviar datos a AWS IoT SiteWise, estos deben cumplir los requisitos de la BatchPutAssetPropertyValue acción. Para obtener más información, consulta BatchPutAssetPropertyValue en la AWS IoT SiteWise Referencia de la API de .
A continuación, el administrador de flujos exporta los datos en función de los ajustes del lote y la prioridad definidos en las configuraciones de exportación del flujo.
Puede ajustar la configuración del administrador de flujos y la lógica del componente de Greengrass para diseñar su estrategia de exportación. Por ejemplo:
-
Para realizar exportaciones prácticamente en tiempo real, establezca ajustes del tamaño de lote e intervalos bajos y añada los datos al flujo cuando lo reciba.
-
Para optimizar el procesamiento por lotes, mitigar las restricciones de ancho de banda o minimizar los costos, los componentes de Greengrass pueden agrupar los puntos de datos de marca temporal, calidad y valor (TQV) recibidos para una sola propiedad de activo antes de agregar los datos al flujo. Una estrategia consiste en agrupar las entradas de hasta 10 combinaciones diferentes de propiedades y activos (o alias de propiedades) en un mensaje, en lugar de enviar más de una entrada para la misma propiedad. Esto ayuda al Administrador de flujos a mantenerse dentro de las cuotas de AWS IoT SiteWise.
Objetos de Amazon S3
El administrador de flujos permite exportar automáticamente a Amazon S3. Puede utilizar Amazon S3 para almacenar y recuperar grandes cantidades de datos. Para obtener más información, consulte ¿Qué es Amazon S3? en la Guía para desarrolladores de Amazon Simple Storage Service.
En el SDK del administrador de flujos, los componentes de Greengrass utilizan S3ExportTaskExecutorConfig para definir la configuración de exportación para este tipo de destino. Para obtener más información, consulte la referencia del SDK para el lenguaje de destino.
-
S3ExportTaskExecutorConfig
en el SDK de Python -
S3ExportTaskExecutorConfig
en el SDK de Java -
S3ExportTaskExecutorConfig
en el Node.js SDK
Requisitos
Este destino de exportación tiene los siguientes requisitos:
-
Los buckets Amazon S3 de destino deben estar en el mismo lugar Cuenta de AWS que el dispositivo principal de Greengrass.
-
Si una función de Lambda que se ejecuta en el modo contenedor de Greengrass escribe archivos de entrada en el directorio de archivos de entrada, usted debe crear el directorio como un volumen en el contenedor con permisos de escritura. Esto garantiza que los archivos se escriban en el sistema de archivos raíz y que sean visibles en el componente administrador de flujos, que se ejecuta fuera del contenedor.
-
Si un componente contenedor de Docker escribe archivos de entrada en un directorio de archivos de entrada, usted debe montar el directorio como un volumen en el contenedor con permisos de escritura. Esto garantiza que los archivos se escriban en el sistema de archivos raíz y que sean visibles en el componente administrador de flujos, que se ejecuta fuera del contenedor.
-
El Autorizar a los dispositivos principales a interactuar con AWS los servicios debe permitir los siguientes permisos para los buckets de destino. Por ejemplo:
Puede conceder acceso granular o condicional a recursos (por ejemplo, utilizando un esquema de nomenclatura con comodín
*) Para obtener más información, consulte Adición y eliminación de políticas de IAM en la Guía del usuario de IAM.
Exportación a Amazon S3
Para crear un flujo que se exporte a Amazon S3, sus componentes de Greengrass utilizan el objeto S3ExportTaskExecutorConfig para configurar la política de exportación. La política define los ajustes de exportación, como el umbral de carga multiparte y la prioridad. Para las exportaciones de Amazon S3, el administrador de flujos carga los datos que lee de los archivos locales en el dispositivo principal. Para iniciar una carga, sus componentes de Greengrass anexan una tarea de exportación al flujo de destino. La tarea de exportación contiene información sobre el archivo de entrada y el objeto Amazon S3 de destino. El administrador de flujos ejecuta las tareas en la secuencia en que se anexan al flujo.
nota
El depósito de destino ya debe existir en su. Cuenta de AWS Si no existe un objeto para la clave especificada, el administrador de flujos crea el objeto automáticamente.
El administrador de flujos utiliza la propiedad de umbral de carga multiparte, el ajuste del tamaño mínimo de las piezas y el tamaño del archivo de entrada para determinar cómo cargar los datos. El umbral de carga multiparte debe ser igual o mayor que el tamaño mínimo de la pieza. Si desea cargar datos en paralelo, puede crear varios flujos.
Las claves que especifican los objetos de Amazon S3 de destino pueden incluir DateTimeFormatter cadenas Java!{timestamp: los marcadores de posición. Puede utilizar estos marcadores de fecha y hora para particionar los datos en Amazon S3 en función de la hora en la que se cargaron los datos del archivo de entrada. Por ejemplo, el siguiente nombre de clave se resuelve en un valor como value}my-key/2020/12/31/data.txt.
my-key/!{timestamp:YYYY}/!{timestamp:MM}/!{timestamp:dd}/data.txt
nota
Si desea supervisar el estado de exportación de un flujo, cree primero un flujo de estado y, a continuación, configure el flujo de exportación para utilizarlo. Para obtener más información, consulte Supervise las tareas de exportación.
Administración de datos de entrada
Puede crear un código que las aplicaciones de IoT usen para administrar el ciclo de vida de los datos de entrada. El siguiente ejemplo de flujo de trabajo muestra cómo se pueden utilizar los componentes de Greengrass para administrar estos datos.
-
Un proceso local recibe datos de dispositivos o periféricos y, a continuación, los escribe en los archivos de un directorio del dispositivo principal. Estos son los archivos de entrada del administrador de flujos.
-
Un componente de Greengrass escanea el directorio y anexa una tarea de exportación al flujo de destino cuando se crea un archivo nuevo. La tarea es un JSON-serialized
S3ExportTaskDefinitionobjeto que especifica la URL del archivo de entrada, el bucket y la clave de Amazon S3 de destino y los metadatos de usuario opcionales. -
El administrador de flujos lee el archivo de entrada y exporta los datos a Amazon S3 en el orden de las tareas anexas. El bucket de destino ya debe existir en tu Cuenta de AWS. Si no existe un objeto para la clave especificada, el administrador de flujos crea el objeto automáticamente.
-
El componente de Greengrass lee los mensajes de un flujo de estado para supervisar el estado de la exportación. Una vez finalizadas las tareas de exportación, el componente de Greengrass puede eliminar los archivos de entrada correspondientes. Para obtener más información, consulte Supervise las tareas de exportación.
Supervise las tareas de exportación
Puede crear un código que las aplicaciones de IoT utilizan para monitorear el estado de sus exportaciones de Amazon S3. Sus componentes de Greengrass deben crear un flujo de estado y, a continuación, configurar el flujo de exportación para escribir actualizaciones de estado en el flujo de estado. Una sola transmisión de estado puede recibir actualizaciones de estado de varias transmisiones que se exportan a Amazon S3.
En primer lugar, cree un flujo para utilizarlo como flujo de estado. Puede configurar las políticas de tamaño y retención del flujo para controlar la vida útil de los mensajes de estado. Por ejemplo:
-
Configure
PersistenceenMemorysi no desea guardar los mensajes de estado. -
Configure
StrategyOnFullenOverwriteOldestDatapara que no se pierdan los nuevos mensajes de estado.
A continuación, cree o actualice el flujo de exportación para usar el flujo de estado. En concreto, defina la propiedad de configuración de estado de la configuración de S3ExportTaskExecutorConfig exportación del flujo. Esto le indica al administrador del flujo que escriba mensajes de estado sobre las tareas de exportación en el flujo de estado. En el objeto StatusConfig, especifique el nombre del flujo de estado y el nivel de detalle. Los siguientes valores admitidos van desde el menos detallado (ERROR) al más detallado (). TRACE El valor predeterminado es INFO.
-
ERROR -
WARN -
INFO -
DEBUG -
TRACE
El siguiente ejemplo de flujo de trabajo muestra cómo los componentes de Greengrass pueden utilizar un flujo de estado para supervisar el estado de exportación.
-
Como se describió en el flujo de trabajo anterior, un componente de Greengrass anexa una tarea de exportación a un flujo que está configurado para escribir mensajes de estado sobre las tareas de exportación en un flujo de estado. La operación de incorporación devuelve un número de secuencia que representa el ID de la tarea.
-
Un componente de Greengrass lee los mensajes secuencialmente del flujo de estado y, a continuación, filtra los mensajes en función del nombre del flujo y el identificador de la tarea o en función de una propiedad de la tarea de exportación del contexto del mensaje. Por ejemplo, el componente de Greengrass puede filtrar por la URL del archivo de entrada de la tarea de exportación, que está representada por el objeto
S3ExportTaskDefinitionen el contexto del mensaje.Los siguientes códigos de estado indican que una tarea de exportación ha alcanzado un estado completo:
-
Success. Se ha completado correctamente la carga. -
Failure. El administrador de flujos detectó un error; por ejemplo, el bucket especificado no existe. Tras resolver el problema, puede volver a añadir la tarea de exportación al flujo. -
Canceled. La tarea se canceló porque se eliminó el flujo o la definición de exportación o porque venció el periodo de vida (TTL) de la tarea.
nota
La tarea también puede tener un estado de
InProgressoWarning. El administrador de flujos emite advertencias cuando un evento devuelve un error que no afecta a la ejecución de la tarea. Por ejemplo, si no se borra una carga parcial cancelada, aparecerá una advertencia. -
-
Una vez finalizadas las tareas de exportación, el componente de Greengrass puede eliminar los archivos de entrada correspondientes.
En el siguiente ejemplo, se muestra cómo un componente de Greengrass puede leer y procesar los mensajes de estado.
