Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Descripción de los conjuntos de imágenes
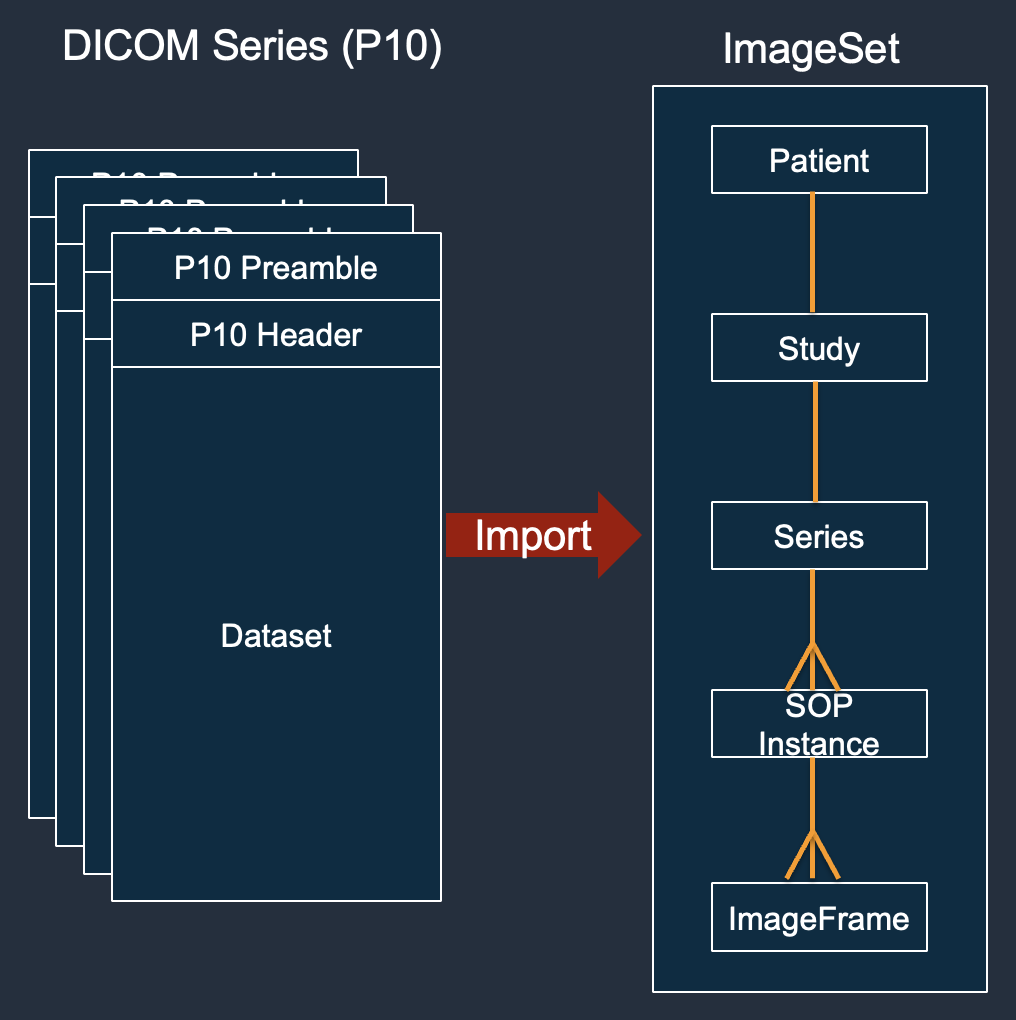
Los conjuntos de imágenes AWS se parecen a los de la serie DICOM y son la base de AWS HealthImaging. Los conjuntos de imágenes se crean al importar los datos DICOM a. HealthImaging El servicio intenta organizar los datos P10 importados según la jerarquía DICOM de estudio, serie e instancia.
Los conjuntos de imágenes se introdujeron por varias razones:
-
Son compatibles con una amplia variedad de flujos de trabajo de imágenes médicas (clínicas y no clínicas) mediante API flexibles.
-
Proporcione un mecanismo para almacenar y conciliar de forma duradera los datos duplicados e inconsistentes. Los datos P10 importados que entren en conflicto con los conjuntos de imágenes principales que ya estén en un almacén se conservarán como datos no principales. Tras resolver los conflictos de metadatos, esos datos pueden pasar a ser principales.
-
Permiten maximizar la seguridad de los pacientes agrupando únicamente los datos relacionados.
-
Fomentar la limpieza de los datos para ofrecer una mayor visibilidad de las incoherencias. Para obtener más información, consulte Modificación de conjuntos de imágenes.
Importante
El uso clínico de los datos DICOM antes de su limpieza puede ser perjudicial para el paciente.
Los siguientes menús describen los conjuntos de imágenes con más detalle y proporcionan ejemplos y diagramas para ayudarle a comprender su funcionalidad y propósito. HealthImaging
Un conjunto de imágenes es un AWS concepto que define un mecanismo de agrupación abstracto para optimizar los datos de imágenes médicas relacionados que se parece mucho a los de la serie DICOM. Al importar los datos de imágenes del DICOM P10 a un almacén de HealthImaging datos de AWS, se transforman en conjuntos de imágenes compuestos por metadatos y marcos de imágenes (datos de píxeles).
nota
Los metadatos de los conjuntos de imágenes están normalizados. En otras palabras, un conjunto común de atributos y valores corresponde a los elementos a nivel de paciente, estudio y serie que figuran en el Registro de elementos de datos DICOM
| Nombre del elemento | Etiqueta de elemento |
|---|---|
| Elementos a nivel de estudio | |
Study Date |
(0008,0020) |
Accession Number |
(0008,0050) |
Patient ID |
(0010,0020) |
Study Instance UID |
(0020,000D) |
Study ID |
(0020,0010) |
| Elementos a nivel de serie | |
Series Instance UID |
(0020,000E) |
Series Number |
(0020,0011) |
Durante la importación, algunos conjuntos de imágenes conservan su codificación de sintaxis de transferencia original, mientras que otros se transcodifican a High-Throughput JPEG 2000 (HTJ2K) sin pérdidas de forma predeterminada. Si un conjunto de imágenes está codificado en HTJ2K, debe decodificarse antes de visualizarlo. Para obtener más información, consulte Sintaxis de transferencia compatibles y Bibliotecas de decodificación de marcos de imágenes.
Los conjuntos de imágenes son AWS recursos, por lo que se les asignan nombres de recursos de Amazon (ARN). Se pueden etiquetar con hasta 50 pares de clave-valor y se les puede conceder control de acceso basado en roles (RBAC) y control de acceso basado en atributos (ABAC) mediante IAM. Además, los conjuntos de imágenes tienen control de versiones para conservar todos los cambios y poder acceder a las versiones anteriores.
La importación de datos de DICOM P10 da como resultado conjuntos de imágenes que contienen metadatos DICOM y marcos de imágenes para una o más instancias de Service-Object Pair (SOP) de la misma serie DICOM.
nota
Trabajos de importación DICOM:
-
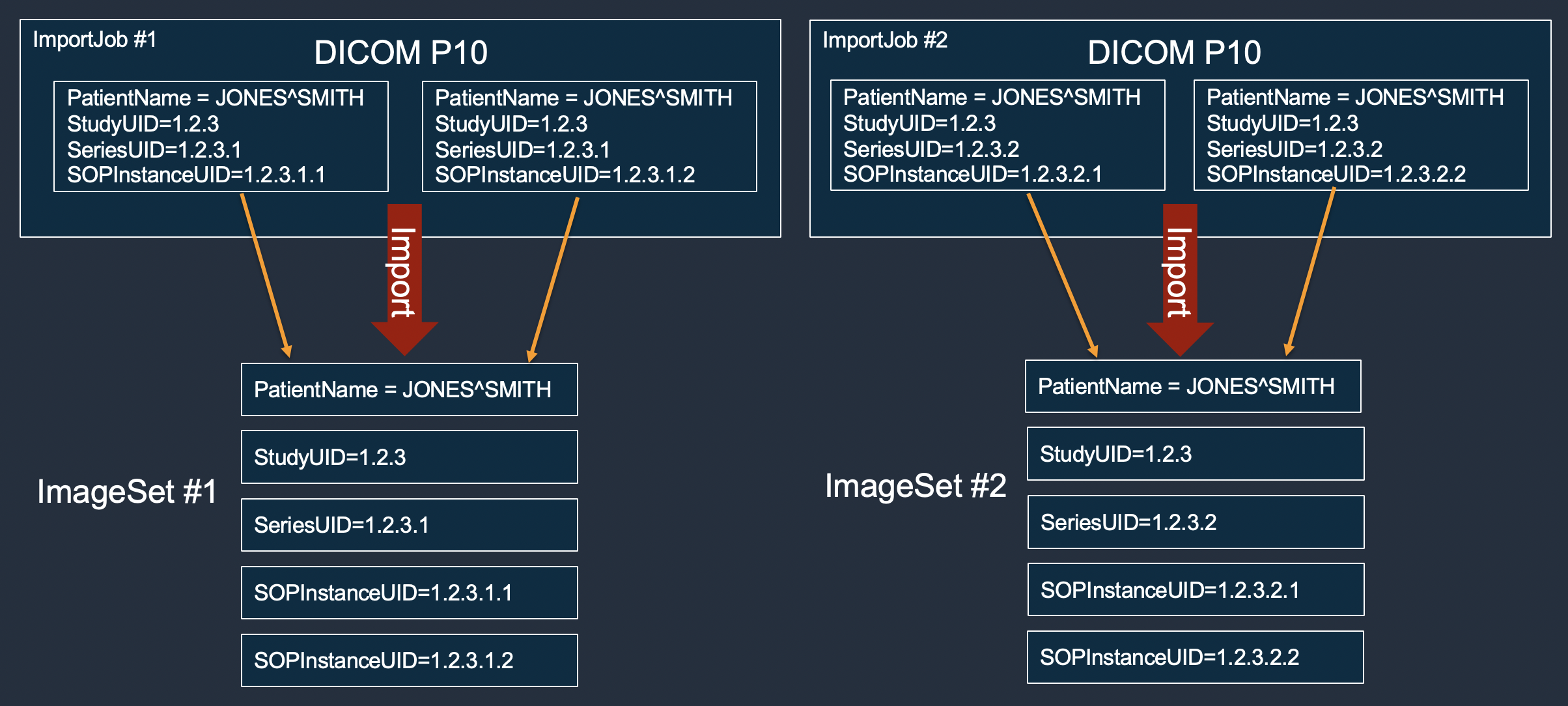
Cree siempre nuevos conjuntos de imágenes o incremente la versión de los conjuntos de imágenes existentes.
-
No deduplique el almacenamiento de instancias SOP. Cada importación de la misma instancia de SOP utiliza almacenamiento adicional como un nuevo conjunto de imágenes no principal o una versión incrementada de un conjunto de imágenes principal existente.
-
Organice automáticamente las instancias SOP con metadatos consistentes y no conflictivos como conjuntos de imágenes principales, que contienen instancias con elementos de metadatos consistentes de pacientes, estudios y series.
-
Si las instancias que componen una serie DICOM se importan en dos o más trabajos de importación y las instancias no entran en conflicto con las que ya se encuentran en el almacén de datos, todas las instancias se organizarán en un conjunto de imágenes principal.
-
-
Cree conjuntos de imágenes no principales que contengan datos del DICOM P10 que entren en conflicto con los conjuntos de imágenes principales que ya están en el almacén de datos.
-
Conserve los datos recibidos más recientemente como la última versión de un conjunto de imágenes principal.
-
Si las instancias que componen una serie DICOM son conjuntos de imágenes principales y se vuelve a importar una instancia, la nueva copia se insertará en el conjunto de imágenes principal y se incrementará la versión.
-
Utilice la GetImageSetMetadata acción para recuperar los metadatos del conjunto de imágenes. Los metadatos devueltos se comprimen congzip, por lo que debe descomprimirlos antes de verlos. Para obtener más información, consulte Obtención de metadatos de conjuntos de imágenes.
El siguiente ejemplo muestra la estructura de los metadatos del conjunto de imágenes en formato JSON.
{ "SchemaVersion": "1.1", "DatastoreID": "2aa75d103f7f45ab977b0e93f00e6fe9", "ImageSetID": "46923b66d5522e4241615ecd64637584", "Patient": { "DICOM": { "PatientBirthDate": null, "PatientSex": null, "PatientID": "2178309", "PatientName": "MISTER^CT" } }, "Study": { "DICOM": { "StudyTime": "083501", "PatientWeight": null }, "Series": { "1.2.840.113619.2.30.1.1762295590.1623.978668949.887": { "DICOM": { "Modality": "CT", "PatientPosition": "FFS" }, "Instances": { "1.2.840.113619.2.30.1.1762295590.1623.978668949.888": { "DICOM": { "SourceApplicationEntityTitle": null, "SOPClassUID": "1.2.840.10008.5.1.4.1.1.2", "HighBit": 15, "PixelData": null, "Exposure": "40", "RescaleSlope": "1", "ImageFrames": [ { "ID": "0d1c97c51b773198a3df44383a5fd306", "PixelDataChecksumFromBaseToFullResolution": [ { "Width": 256, "Height": 188, "Checksum": 2598394845 }, { "Width": 512, "Height": 375, "Checksum": 1227709180 } ], "MinPixelValue": 451, "MaxPixelValue": 1466, "FrameSizeInBytes": 384000 } ] } } } } } }
El ejemplo siguiente muestra cómo varios trabajos de importación crean siempre nuevos conjuntos de imágenes y nunca los agregan a los existentes.
El siguiente ejemplo muestra un único trabajo de importación que no se combinaría en un único conjunto de imágenes porque las instancias 1 y 3 tienen identificadores de paciente diferentes a los de las instancias 2 y 4. Para resolver este problema, puede utilizar la UpdateImageSetMetadata acción para resolver el conflicto de identificación del paciente con el conjunto de imágenes principal existente. Una vez resueltos los conflictos, puede utilizar la CopyImageSet acción con el argumento --promoteToPrimary para añadir el conjunto de imágenes al conjunto de imágenes principal.

El ejemplo siguiente muestra un único trabajo de importación que crea dos conjuntos de imágenes para mejorar el rendimiento, aunque los nombres de los pacientes coincidan.

