Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Cómo funcionan las configuraciones de trabajos
Las configuraciones de despliegue y anulación se utilizan cuando se implementa un trabajo y las configuraciones de tiempo de espera y reintento, para su ejecución. En las siguientes secciones se muestra más información sobre el funcionamiento de estas configuraciones.
Temas
Configuraciones de despliegue, programación y cancelación de trabajos
Puede utilizar las configuraciones de despliegue, programación y anulación de tareas para definir cuántos dispositivos reciben el documento de trabajo, programar el despliegue de un trabajo y determinar los criterios para cancelarlo.
Puede especificar la rapidez con la que se notifica a los destinos la ejecución de un trabajo pendiente. También puede crear un despliegue por etapas para administrar las actualizaciones, los reinicios y otras operaciones. Para especificar cómo se notifican los destinos, utilice las velocidades de despliegue de trabajos.
velocidades de despliegue de trabajos
Puede crear una configuración de despliegue mediante una velocidad de despliegue constante o una velocidad de despliegue exponencial. Para especificar el número máximo de destinos de trabajo de los que se informará por minuto, utilice una velocidad de despliegue constante.
AWS IoT los trabajos se pueden implementar utilizando tasas de implementación exponenciales a medida que se cumplan varios criterios y umbrales. Si el número de trabajos fallidos coincide con un conjunto de criterios especificados, puede cancelar el despliegue de los trabajos. Los criterios de la velocidad de despliegue de trabajos se establecen al crear un trabajo mediante el objeto JobExecutionsRolloutConfig. Los criterios de anulación de un trabajo también se establecen en el momento de crear un trabajo a través del objeto AbortConfig.
El siguiente ejemplo muestra cómo funcionan las velocidades de despliegue. Por ejemplo, el despliegue de un trabajo con una velocidad base de 50 por minuto, un factor de incremento de 2 y un número de dispositivos notificados y completados con éxito de 1000 cada uno funcionaría de la siguiente manera: el trabajo se iniciará a una velocidad de 50 ejecuciones de trabajos por minuto y continuará a ese ritmo hasta que 1000 objetos hayan recibido notificaciones de ejecución de tareas o se hayan realizado 1000 ejecuciones de trabajos correctas.
En la siguiente tabla se muestra cómo se produciría el despliegue durante los primeros cuatro incrementos.
|
Velocidad de despliegue por minuto |
50 |
100 |
200 |
400 |
|
Número de dispositivos notificados o de ejecuciones de tareas realizadas correctamente para justificar un aumento de la velocidad |
1 000 |
2,000 |
3000 |
4.000 |
nota
Si se encuentra en el límite máximo de 500 trabajos simultáneos (isConcurrent = True), todos los trabajos activos permanecerán con el estado de IN-PROGRESS y no se ejecutará ningún trabajo nuevo hasta que el número de trabajos simultáneos sea igual o inferior a 499 (isConcurrent = False)). Esto se aplica a los trabajos instantáneos y continuos.
Si isConcurrent = True, el trabajo actualmente está desplegando las ejecuciones de trabajos en todos los dispositivos del grupo de destino. Si isConcurrent = False, el trabajo ha completado el despliegue de todas las ejecuciones de trabajos en todos los dispositivos del grupo de destino. Actualizará su estado una vez que todos los dispositivos del grupo de destino alcancen un estado terminal, o un porcentaje mínimo del grupo de destino si ha seleccionado una configuración de anulación de trabajo. Los estados del nivel de trabajo para isConcurrent = True y isConcurrent = False son ambos IN_PROGRESS.
Para obtener más información sobre los límites de trabajos activos y simultáneos, consulte Límites de trabajos activos y simultáneos.
Velocidades de despliegue de trabajos continuos que utilizan grupos de objetos dinámicos
Cuando utilizas un trabajo continuo para implementar operaciones remotas en tu flota, AWS IoT Jobs implementa la ejecución de tareas para los dispositivos de tu grupo objetivo. En el caso de los nuevos dispositivos que se añaden al grupo de objetos dinámicos, estas ejecuciones de trabajos se siguen extendiendo a esos dispositivos incluso después de haber creado el trabajo.
La configuración de despliegue puede controlar las velocidades de despliegue solo para los dispositivos que se agreguen al grupo hasta la creación del trabajo. Una vez creado un trabajo, en el caso de los dispositivos nuevos, las ejecuciones del trabajo se crean prácticamente en tiempo real en cuanto los dispositivos se unen al grupo de destino.
Puede programar un trabajo continuo o instantáneo con hasta un año de antelación utilizando una hora de inicio, una hora de finalización y un comportamiento de finalización predeterminados para determinar lo que ocurrirá con la ejecución de cada trabajo al llegar la hora de finalización. Además, puede crear un periodo de mantenimiento periódico opcional con una frecuencia, hora de inicio y duración flexibles para los trabajos continuos a fin de desplegar un documento de trabajo en todos los dispositivos del grupo de destino.
Configuraciones de programación de trabajos
Hora de inicio
La hora de inicio de un trabajo programado es la fecha y hora futuras en que el trabajo comenzará a desplegar el documento de trabajo en todos los dispositivos del grupo de destino. La hora de inicio de un trabajo programado se aplica a los trabajos continuos y a los trabajos instantáneos. Cuando se crea inicialmente un trabajo programado, mantiene un estado de SCHEDULED. Al llegar al startTime que ha seleccionado, se actualiza a IN_PROGRESS y comienza el despliegue del documento de trabajo. El startTime debe ser menor o igual a un año desde la fecha y hora iniciales en que se creó el trabajo programado.
Para obtener más información sobre la sintaxis startTime cuando se utiliza un comando de API o el AWS CLI, consulte Timestamp.
En el caso de un trabajo con la configuración de programación opcional que se lleve a cabo durante un periodo de mantenimiento periódico en una ubicación con horario de verano (DST), la hora cambiará una hora al pasar del horario de verano al horario estándar y viceversa.
nota
La zona horaria que se muestra en AWS Management Console es la zona horaria actual de su sistema. Sin embargo, estas zonas horarias se convertirán a UTC en el sistema.
Hora de finalización
La hora de finalización de un trabajo programado es la fecha y hora futuras en las que el trabajo detendrá el despliegue del documento de trabajo en los dispositivos restantes del grupo de destino. La hora de finalización de un trabajo programado se aplica a los trabajos continuos y a los instantáneos. Una vez que un trabajo programado llega al endTime seleccionado y todas las ejecuciones del trabajo han alcanzado un estado terminal, actualiza su estado de IN_PROGRESS a COMPLETED. El endTime debe ser menor o igual a dos años desde la fecha y hora iniciales en que se creó el trabajo programado. La duración mínima entre startTime y endTime es de 30 minutos. Los reintentos de ejecución del trabajo se realizarán hasta que el trabajo alcance el endTime, a continuación, el endBehavior dictará cómo proceder.
Para obtener más información sobre la sintaxis endTime cuando se utiliza un comando de API o el AWS CLI, consulte Timestamp.
En el caso de un trabajo con la configuración de programación opcional que se lleve a cabo durante un periodo de mantenimiento periódico en una ubicación con horario de verano (DST), la hora cambiará una hora al pasar del horario de verano al horario estándar y viceversa.
nota
La zona horaria que se muestra en AWS Management Console es la zona horaria actual de su sistema. Sin embargo, estas zonas horarias se convertirán a UTC en el sistema.
Comportamiento final
El comportamiento final de un trabajo programado determina lo que ocurre con el trabajo y con todas las ejecuciones de trabajos pendientes cuando el trabajo alcanza el endTime seleccionado.
A continuación se enumeran los comportamientos finales que se pueden seleccionar al crear el trabajo o la plantilla de trabajo:
-
STOP_ROLLOUT-
STOP_ROLLOUTdetiene el despliegue del documento de trabajo en todos los dispositivos restantes del grupo de destino del trabajo. Además, todas las ejecuciones de trabajosQUEUEDyIN_PROGRESScontinuarán hasta que alcancen un estado terminal. Este es el comportamiento final predeterminado a menos que se seleccioneCANCELoFORCE_CANCEL.
-
-
CANCEL-
CANCELdetiene el despliegue del documento de trabajo en todos los dispositivos restantes del grupo de destino del trabajo. Además, todas las ejecuciones de trabajosQUEUEDse cancelarán, mientras que todas las ejecuciones de trabajosIN_PROGRESScontinuarán hasta que alcancen un estado terminal.
-
-
FORCE_CANCEL-
FORCE_CANCELdetiene el despliegue del documento de trabajo en todos los dispositivos restantes del grupo de destino del trabajo. Además, se cancelarán todas las ejecuciones de trabajosQUEUEDyIN_PROGRESS.
-
nota
Para seleccionar unaendbehavior, debe seleccionar una endtime
Duración máxima
La duración máxima de un trabajo programado debe ser inferior o igual a dos años, independientemente del startTime y endTime.
En la siguiente tabla se enumeran los escenarios de duración más comunes de un trabajo programado:
| Número de ejemplo de trabajo programado | startTime | endTime | Duración máxima |
|---|---|---|---|
|
1 |
Inmediatamente después de la creación inicial del trabajo. |
Un año después de la creación inicial del trabajo. |
Un año |
|
2 |
Un mes después de la creación inicial del trabajo. |
13 meses después de la creación inicial del trabajo. |
Un año |
|
3 |
Un año después de la creación inicial del trabajo. |
Dos años después de la creación inicial del trabajo. |
Un año |
|
4 |
Inmediatamente después de la creación inicial del trabajo. |
Dos años después de la creación inicial del trabajo. |
Dos años |
Periodo de mantenimiento periódico
El período de mantenimiento es una configuración opcional dentro de la configuración de programación de las API AWS Management Console y SchedulingConfig de CreateJobTemplate las API CreateJob y. Puede configurar un periodo de mantenimiento periódico con una hora de inicio, una duración y una frecuencia predeterminados (diaria, semanal o mensual) en que tendrá lugar. Los periodos de mantenimiento solo se aplican a los trabajos continuos. La duración máxima de un periodo de mantenimiento periódico es de 23 horas y 50 minutos.
El siguiente diagrama ilustra los estados de los trabajos en varios escenarios de trabajos programados con un intervalo de mantenimiento opcional:
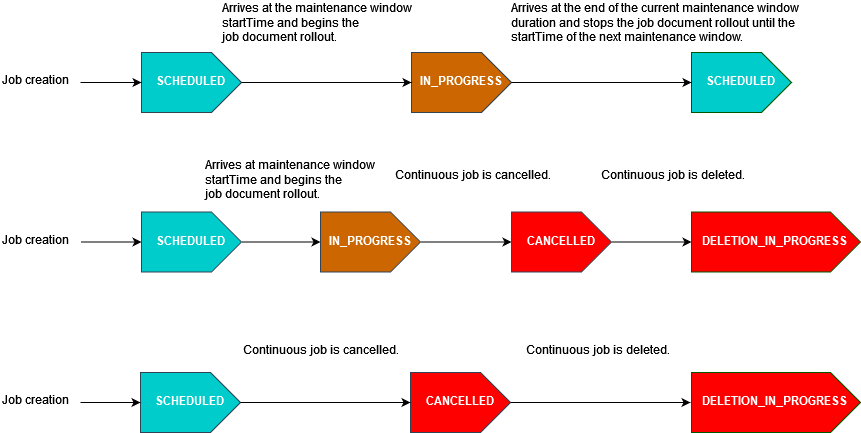
Para obtener más información acerca de los estados de un trabajo, consulte Trabajos y estados de ejecución de los trabajos.
nota
Si un trabajo llega al endTime durante un periodo de mantenimiento, se actualizará de IN_PROGRESS a COMPLETED. Además, las ejecuciones de los trabajos restantes seguirán el endBehavior del trabajo.
Expresiones cron
En el caso de los trabajos programados que despliegan el documento de trabajo durante un periodo de mantenimiento con una frecuencia personalizada, esta se introduce mediante una expresión cron. Una expresión cron tiene seis campos obligatorios, que están separados por un espacio en blanco.
Sintaxis
cron(fields)
| Campo | Valores | Caracteres comodín |
|---|---|---|
|
Minutos |
0-59 |
, - * / |
|
Horas |
0-23 |
, - * / |
|
D ay-of-month |
1-31 |
, - * ? / L W |
|
Mes |
1-12 o JAN-DEC |
, - * / |
|
D ay-of-week |
1-7 o SUN-SAT |
, - * ? L # |
|
Año |
1970-2199 |
, - * / |
Caracteres comodín
-
El carácter comodín , (coma) incluye valores adicionales. En el campo Month, JAN, FEB, MAR incluiría enero, febrero y marzo.
-
El carácter comodín - (guion) especifica los intervalos. En el campo Day, 1-15 incluiría los días del 1 al 15 del mes especificado.
-
El * (asterisco) incluye todos los valores del campo. En el campo Hours, * incluiría cada hora. No puedes usar * en los ay-of-week campos D ay-of-month y D. Si lo utiliza en uno, debe utilizar ? en el otro.
-
El comodín / (barra inclinada) especifica incrementos. En el campo Minutos, puede escribir 1/10 para especificar cada décimo minuto, empezando desde el primer minuto de la hora (por ejemplo, los minutos 11, 21 y 31, etc.).
-
El comodín ? (signo de interrogación) especifica uno u otro. En el ay-of-month campo D, puede escribir 7 y, si no le importa qué día de la semana es el 7, ¿puede escribir? en el ay-of-week campo D.
-
El comodín L de los ay-of-week campos D ay-of-month o D especifica el último día del mes o de la semana.
-
El
Wcomodín del ay-of-month campo D especifica un día de la semana. En el ay-of-month campo D,3Wespecifica el día de la semana más cercano al tercer día del mes. -
El comodín # en el ay-of-week campo D especifica una instancia determinada del día de la semana especificado dentro de un mes. Por ejemplo, 3#2 sería el segundo martes del mes: el número 3 hace referencia al martes, ya que es el tercer día de la semana en el calendario anglosajón, mientras que 2 hace referencia al segundo día de ese tipo dentro de un mes.
nota
Si utiliza el carácter «#», solo puede definir una expresión en el day-of-week campo. Por ejemplo,
"3#1,6#3"no es válido porque se interpreta como dos expresiones.
Restricciones
-
No puede especificar los ay-of-week campos D ay-of-month y D en la misma expresión cron. Si especifica un valor o (o un *) en uno de estos campos, debe utilizar un ? en el otro.
Ejemplos
Consulte los siguientes ejemplos de cadenas cron cuando utilice una expresión cron para el startTime de un periodo de mantenimiento periódico.
| Minutos | Horas | Día del mes | Mes | Día de la semana | Año | Significado |
|---|---|---|---|---|---|---|
| 0 | 10 | * | * | ? | * |
Ejecutar a las 10:00 h (UTC) todos los días |
| 15 | 12 | * | * | ? | * |
Ejecutar a las 12:15 h (UTC) todos los días |
| 0 | 18 | ? | * | MON-FRI | * |
Ejecutar a las 18:00 h (UTC) de lunes a viernes |
| 0 | 8 | 1 | * | ? | * |
Ejecutar a las 08:00 horas (UTC) todos los primeros de mes |
Lógica de finalización de la duración del periodo de mantenimiento periódico
Cuando el despliegue de un trabajo durante un periodo de mantenimiento llegue al final de la duración del periodo de mantenimiento actual, se llevarán a cabo las siguientes acciones:
-
El trabajo detendrá todos los despliegues del documento de trabajo a los dispositivos restantes del grupo de destino. Se reanudará en el
startTimedel próximo periodo de mantenimiento. -
Todas las ejecuciones de trabajos con un estado de
QUEUEDpermanecerán enQUEUEDhasta elstartTimedel siguiente periodo de mantenimiento. En él, pueden cambiar aIN_PROGRESScuando el dispositivo esté listo para empezar a realizar las acciones especificadas en el documento de trabajo. -
Todas las ejecuciones de tareas con un estado de
IN_PROGRESSseguirán realizando las acciones especificadas en el documento de trabajo hasta que alcancen un estado terminal. Cualquier reintento, tal como se especifica enJobExecutionsRetryConfig, se realizará en elstartTimedel siguiente periodo de mantenimiento.
Esta configuración se utiliza para crear un criterio para cancelar un trabajo cuando un porcentaje umbral de dispositivos lo cumple. Por ejemplo, puede usar esta configuración para cancelar un trabajo en los siguientes casos:
-
Cuando un porcentaje umbral de dispositivos no recibe las notificaciones de ejecución de trabajos, como cuando el dispositivo no es compatible con una actualización vía inalámbrica (OTA). En este caso, el dispositivo puede informar de un estado
REJECTED. -
Cuando un porcentaje umbral de dispositivos informa de un error en la ejecución de sus trabajos, como cuando el dispositivo se desconecta al intentar descargar el documento de trabajo desde una URL de Amazon S3. En esos casos, el dispositivo debe estar programado para informar del estado
FAILUREa AWS IoT. -
Cuando se informa de un estado
TIMED_OUTporque se agota el tiempo de espera para la ejecución del trabajo en un porcentaje umbral de dispositivos una vez iniciadas las ejecuciones del trabajo. -
Cuando se producen varios errores en los reintentos. Al añadir una configuración de reintentos, cada reintento puede suponer un coste adicional para la Cuenta de AWS. En esos casos, cancelar el trabajo puede cancelar las ejecuciones de trabajos en cola y evitar que se vuelvan a intentar estas ejecuciones. Para obtener más información sobre la configuración de los reintentos y su uso con la configuración de anulación, consulte Configuraciones de tiempo de espera y reintento de ejecución de trabajos.
Puede configurar una condición de cancelación de tareas mediante la AWS IoT consola o la API de AWS IoT Jobs.
Configuraciones de tiempo de espera y reintento de ejecución de trabajos
Utilice la configuración de tiempo de espera de ejecución de tareas para enviarle Notificaciones de trabajos cuando la ejecución de un trabajo haya estado en curso durante más tiempo del establecido. Utilice la configuración de reintento de ejecución del trabajo para reintentar la ejecución cuando el trabajo falle o se agote el tiempo de espera.
Utilice la configuración del tiempo de espera de las ejecuciones de trabajo cada vez que la ejecución de un trabajo se bloquee en el estado IN_PROGRESS durante un periodo de tiempo más largo de lo previsto. Una vez que el trabajo esté IN_PROGRESS, puede monitorizar el progreso de su ejecución.
Temporizadores para los tiempos de espera de los trabajos
Existen dos tipos de temporizadores: temporizadores en curso y temporizadores de pasos.
Temporizadores en curso
Al crear un trabajo o una plantilla de trabajo, puede especificar un valor para el temporizador en curso que oscile entre 1 minuto y 7 días. Puede actualizar el valor de este temporizador hasta el inicio de la ejecución del trabajo. Una vez iniciado el temporizador, no se puede actualizar y el valor del temporizador se aplica a todas las ejecuciones del trabajo. Siempre que la ejecución de un trabajo permanezca en ese IN_PROGRESS estado durante más tiempo que este intervalo, se producirá un error en la ejecución del trabajo y pasará al TIMED_OUT estado terminal. AWS IoT también publica una notificación MQTT.
Temporizador de pasos
También puede configurar un temporizador de pasos que se aplique únicamente a la ejecución del trabajo que desee actualizar. Este temporizador no tiene efecto en el temporizador en curso. Puede establecer un nuevo valor para este temporizador cada vez que actualice la ejecución de un trabajo. También puede crear un nuevo temporizador de pasos al iniciar la próxima ejecución de trabajo pendiente para un objeto. Si la ejecución del trabajo permanece en estado IN_PROGRESS durante un periodo superior a este intervalo del temporizador de pasos, generará un error y cambiará al estado terminal TIMED_OUT.
nota
Puede configurar el temporizador en curso mediante la AWS IoT consola o la API de AWS IoT Jobs. Para especificar el temporizador de pasos, use la API.
Cómo funcionan los temporizadores para los tiempos de espera de los trabajos
A continuación, se ilustran las formas en las que los tiempos de espera en curso y de pasos interactúan entre sí en un periodo de espera de 20 minutos.
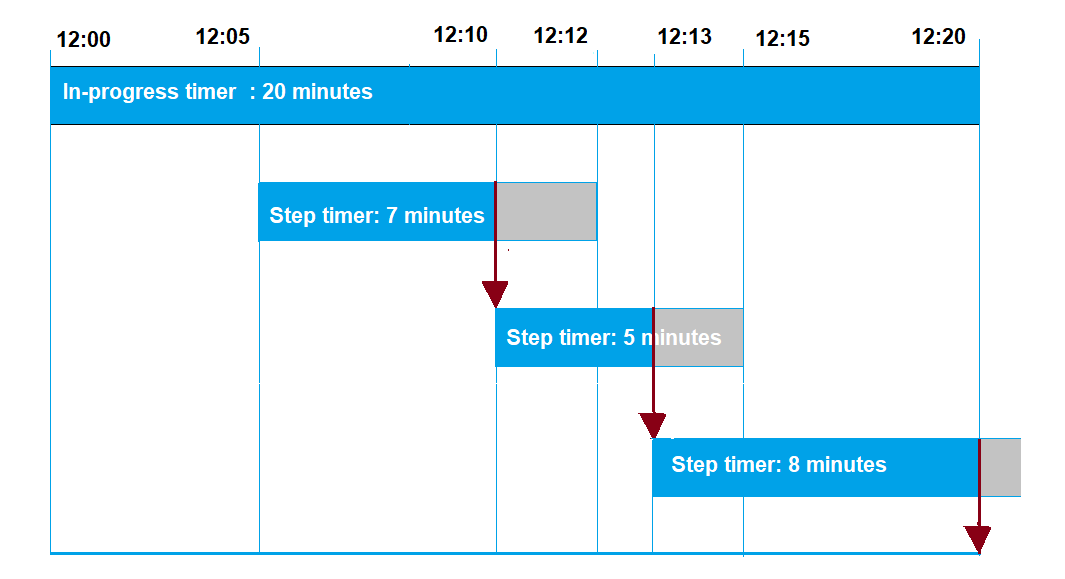
Lo siguiente muestra los diferentes pasos:
-
12:00
Al crear un trabajo, se crea un nuevo trabajo y se activa un temporizador de veinte minutos en curso. El temporizador en curso comienza a correr y la ejecución del trabajo pasa al estado
IN_PROGRESS. -
12:05
Se crea un nuevo temporizador de pasos con un valor de 7 minutos. La ejecución del trabajo finalizará ahora a las 12:12.
-
12:10
Se crea un nuevo temporizador de pasos con un valor de 5 minutos. Cuando se crea un nuevo temporizador de pasos, se descarta el anterior y la ejecución del trabajo acabará ahora a las 12:15 h.
-
12:13
Se crea un nuevo temporizador de pasos con un valor de 9 minutos. El temporizador de pasos anterior se descarta y la ejecución del trabajo acaba ahora a las 12:20 h, ya que el temporizador en curso finaliza a esa hora. El temporizador de pasos no puede superar el límite absoluto del temporizador en curso.
Puede utilizar la configuración de reintento para reintentar la ejecución del trabajo cuando se cumpla un determinado conjunto de criterios. El reintento se puede realizar cuando se agote el tiempo de espera de un trabajo o cuando el dispositivo falle. Para reintentar la ejecución debido a un error en el tiempo de espera, debe habilitar la configuración del tiempo de espera.
Cómo utilizar la configuración de reintentos
Siga los pasos siguientes para configurar los reintentos:
-
Determine si se debe utilizar la configuración de reintento para
FAILED,TIMED_OUTo ambos criterios de error. En cuanto alTIMED_OUT -
Respecto del estado
FAILED, compruebe si se puede reintentar el error de ejecución del trabajo. Si se puede reintentar, programe el dispositivo para que informe de un estadoFAILUREa AWS IoT. En la siguiente sección se describe más información sobre los errores que se pueden reintentar y los que no. -
Para especificar el número de reintentos que se van a utilizar para cada tipo de error, utilice la información anterior. Para un solo dispositivo, puede especificar hasta 10 reintentos para ambos tipos de error combinados. Los reintentos se detienen automáticamente cuando una ejecución se realiza correctamente o cuando se alcanza el número de intentos especificado.
-
Añada una configuración de cancelación para cancelar el trabajo en caso de que se produzcan errores repetidos en los reintentos, a fin de evitar que se generen cargos adicionales por un gran número de reintentos.
nota
Cuando un trabajo llega al final de un periodo de mantenimiento periódico, todas las ejecuciones de trabajos IN_PROGRESS seguirán realizando las acciones identificadas en el documento de trabajo hasta que alcancen un estado terminal. Si la ejecución de un trabajo alcanza un estado terminal FAILED o TIMED_OUT fuera de un periodo de mantenimiento, se volverá a intentar en el siguiente periodo si no se agotan los intentos. En el startTime del siguiente periodo de mantenimiento, se creará una nueva ejecución de trabajo y pasará a un estado QUEUED hasta que el dispositivo esté listo para empezar.
Configuración de reintentos y anulaciones
Cada reintento supone un coste adicional para usted. Cuenta de AWS Para evitar incurrir en cargos adicionales por errores repetidos en los reintentos, recomendamos añadir una configuración de anulación. Para obtener más información acerca de los precios, consulte Precios de AWS IoT Device Management
Es posible que se produzcan varios errores en los reintentos cuando un porcentaje elevado de dispositivos agote el tiempo de espera o notifique un error. En este caso, se puede usar la configuración de anulación para cancelar el trabajo y evitar que se ejecute un trabajo en cola o que se vuelva a intentar.
nota
Cuando se cumplen los criterios de anulación para cancelar la ejecución de un trabajo, solo se cancelan las ejecuciones de trabajos QUEUED. No se realizará ningún reintento de dispositivos que estén en cola. Sin embargo, las ejecuciones de trabajos actuales que tengan un estado IN_PROGRESS no se cancelarán.
Antes de reintentar ejecutar un trabajo fallido, también recomendamos comprobar si la ejecución fallida se puede reintentar, tal y como se describe en la siguiente sección.
Reintento del tipo de error FAILED
Para realizar reintentos en caso de error FAILED, los dispositivos deben estar programados para informar del estado FAILURE sobre una ejecución fallida de un trabajo a AWS IoT. Defina la configuración de reintentos con los criterios para reintentar ejecutar los trabajos FAILED y especifique el número de reintentos que se van a realizar. Cuando AWS IoT Jobs detecte el FAILURE estado, intentará automáticamente volver a intentar ejecutar el trabajo en el dispositivo. Los reintentos continúan hasta que la ejecución del trabajo se realice correctamente o se alcance el número máximo de reintentos.
Puede realizar un seguimiento de cada reintento y del trabajo que se está ejecutando en estos dispositivos. Al hacer un seguimiento del estado de la ejecución, una vez que se haya intentado realizar el número especificado de reintentos, puede usar el dispositivo para informar de los errores e iniciar otro reintento.
Errores que se pueden reintentar y que no
Un error en la ejecución del trabajo puede volver a reintentarse o no. Cada reintento puede generar cargos en la Cuenta de AWS. Para evitar incurrir en cargos adicionales por múltiples reintentos, primero considere comprobar si el error en la ejecución del trabajo se puede reintentar. Un ejemplo de error que se puede reintentar puede ser un error de conexión que el dispositivo detecta al intentar descargar el documento de trabajo desde una URL de Amazon S3. Si se puede reintentar ejecutar un trabajo fallido, programe el dispositivo para que notifique un estado FAILURE en caso de que la ejecución del trabajo falle. A continuación, defina la configuración de reintentos para reintentar las ejecuciones FAILED.
Si no puede reintentar la ejecución, le recomendamos que programe el dispositivo para que informe de un estado REJECTED a AWS IoT y así evitar que se efectúen cargos adicionales en su cuenta. Algunos ejemplos de errores que no se pueden reintentar son los casos en los que el dispositivo no puede recibir una actualización del trabajo o cuando se produce un error de memoria al ejecutar un trabajo. En estos casos, AWS IoT Jobs no volverá a intentar la ejecución del trabajo porque solo lo volverá a intentar cuando detecte un FAILED estado o. TIMED_OUT
Una vez que haya determinado que un error en la ejecución de un trabajo se puede reintentar, si el reintento sigue fallando, considere la posibilidad de comprobar los registros del dispositivo.
nota
Cuando un trabajo con la configuración de programación opcional alcance su endTime, el endBehavior seleccionado detendrá el despliegue del documento de trabajo en todos los dispositivos restantes del grupo de destino y determinará cómo proceder con las ejecuciones restantes del trabajo. Los reintentos se realizan si se seleccionan mediante la configuración correspondiente.
Reintento del tipo de error TIMEOUT
Si habilita el tiempo de espera al crear un trabajo, AWS IoT Jobs intentará volver a intentar la ejecución del trabajo en el dispositivo cuando el estado cambie de a. IN_PROGRESS TIMED_OUT Este cambio de estado puede producirse cuando se agota el tiempo de espera del temporizador en curso o cuando se activa un temporizador de pasos que especificado en IN_PROGRESS y este finaliza. Los reintentos continúan hasta que la ejecución del trabajo se realice correctamente o se alcance el número máximo de reintentos para el tipo de error en cuestión.
Actualizaciones de trabajos continuos y de la suscripción a grupos de objetos
En el caso de los trabajos continuos cuyo estado sea IN_PROGRESS, el número de reintentos se restablece a cero cuando se actualiza la suscripción a un grupo. Por ejemplo, imagine que especificó cinco reintentos y ya se han realizado tres. Si ahora se elimina un objeto del grupo de objetos y, a continuación, vuelve a entrar en él, por ejemplo, en el caso de los grupos de objetos dinámicos, el número de reintentos se restablece a cero. Ahora puede realizar cinco reintentos para el grupo de objetos en lugar de los dos que quedaban por hacer. Además, cuando se elimina un objeto del grupo correspondiente, se cancelan los reintentos adicionales.
