Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
AWS Lake Formation: Cómo funciona
AWS Lake Formation proporciona un modelo de permisos del sistema de administración de bases de datos relacionales (RDBMS) para conceder o revocar el acceso a los recursos del catálogo de datos, como bases de datos, tablas y columnas con datos subyacentes en Amazon S3. Los permisos de Lake Formation, fáciles de gestionar, sustituyen a las complejas políticas de bucket de Amazon S3 y a las correspondientes políticas de IAM.
En Lake Formation, puede implementar permisos en dos niveles:
Aplicación de permisos a nivel de metadatos en los recursos del Catálogo de datos, como bases de datos y tablas
Administración de los permisos de acceso al almacenamiento en los datos subyacentes guardados en Amazon S3 en nombre de los motores integrados
Flujo de trabajo de administración de permisos de Lake Formation
Lake Formation se integra con motores de análisis para consultar almacenes de datos de Amazon S3 y objetos de metadatos que están registrados en Lake Formation. El diagrama siguiente ilustra cómo funciona la administración de permisos en Lake Formation.
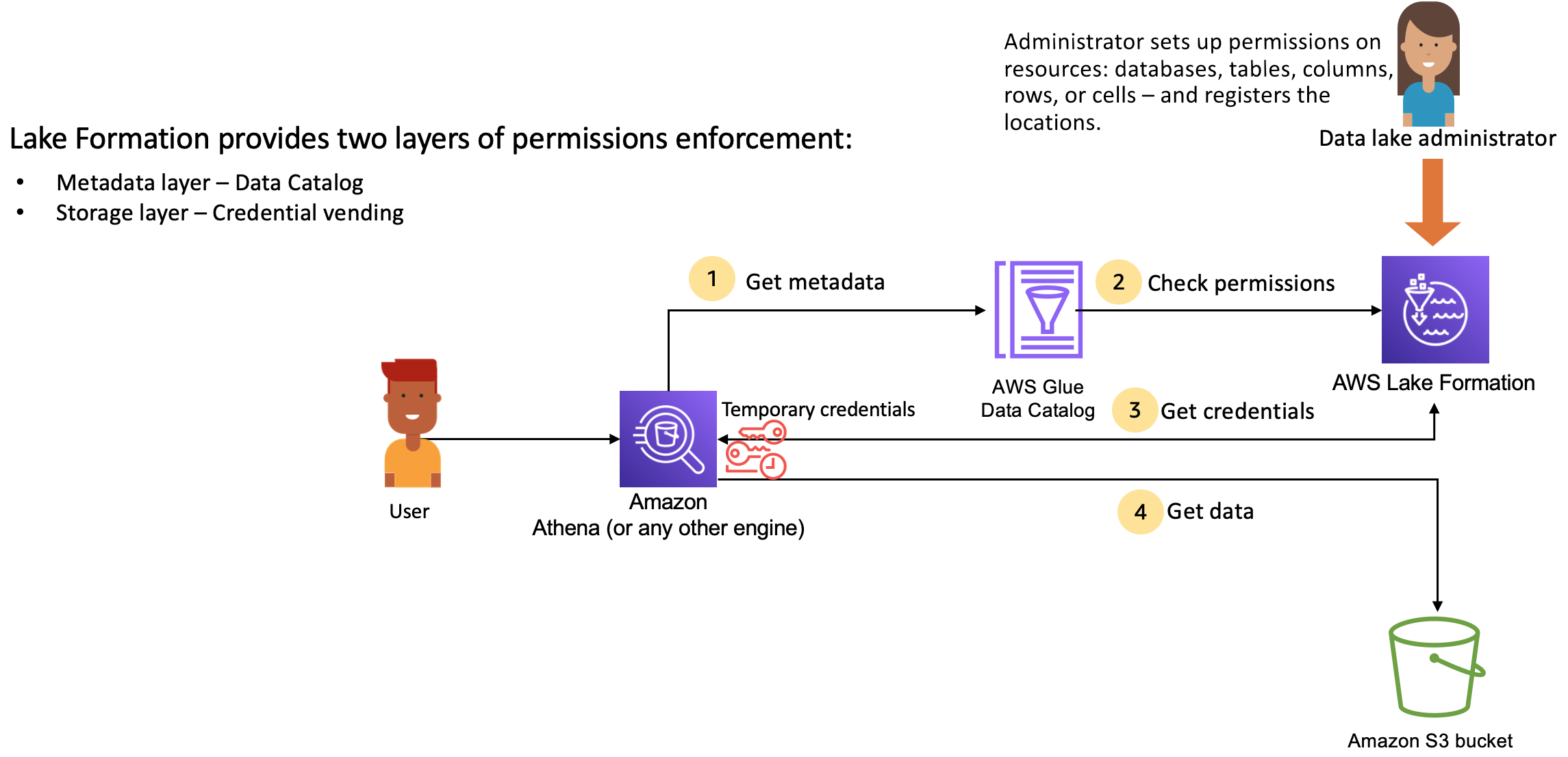
Pasos generales para la gestión de permisos de Lake Formation
Antes de que Lake Formation pueda proporcionar controles de acceso para los datos de su lago de datos, un administrador del lago de datos o un usuario con permisos administrativos configura las políticas de usuario individuales de las tablas del Catálogo de datos para permitir o denegar el acceso a las tablas del Catálogo de datos utilizando los permisos de Lake Formation.
A continuación, el administrador del lago de datos o un usuario delegado por el administrador concede permisos de Lake Formation a los usuarios en las bases de datos y tablas del Catálogo de datos y registra la ubicación de Amazon S3 de la tabla en Lake Formation.
Obtener metadatos: un director (usuario) envía una consulta o un script de ETL a un motor de análisis integrado, como Amazon Athena AWS Glue, Amazon EMR o Amazon Redshift Spectrum. El motor analítico integrado identifica la tabla que se solicita y envía una petición de metadatos al Catálogo de datos.
-
Comprobar permisos. El Catálogo de datos comprueba los permisos del usuario con Lake Formation, y si el usuario está autorizado a acceder a la tabla, devuelve al motor los metadatos que el usuario está autorizado a ver.
-
Obtener credenciales. El Catálogo de datos permite al motor saber si la tabla está administrada por Lake Formation o no. Si los datos subyacentes están registrados en Lake Formation, el motor analítico solicita a Lake Formation que proporcione acceso a los datos mediante la concesión de un acceso temporal.
-
Obtener datos. Si el usuario está autorizado a acceder a la tabla, Lake Formation proporciona acceso temporal al motor analítico integrado. Mediante el acceso temporal, el motor analítico obtiene los datos de Amazon S3 y aplica el filtrado necesario, como el de columnas, filas o celdas. Cuando el motor termina de ejecutar el trabajo, devuelve los resultados al usuario. Este proceso se denomina expedición de credenciales.
Si la tabla no está administrada por Lake Formation, la segunda llamada del motor analítico se hace directamente a Amazon S3. Para el acceso a los datos se evalúan la política de buckets de Amazon S3 y la política de usuarios de IAM correspondientes.
Siempre que utilice políticas de IAM, compruebe que sigue las mejores prácticas IAM. Para más información, consulte Prácticas recomendadas de seguridad en IAM en la Guía del usuario de IAM.
Temas
