Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Creación de un flujo de trabajo
Antes de empezar, asegúrese de que ha concedido los permisos de datos y de ubicación de datos necesarios al rol LakeFormationWorkflowRole. Esto es para que el flujo de trabajo pueda crear tablas de metadatos en el Catálogo de datos y escribir datos en ubicaciones de destino en Amazon S3. Para obtener más información, consulte (Opcional) Crear un rol de IAM para flujos de trabajo y Descripción general de los permisos de Lake Formation.
nota
Lake Formation usa las operaciones GetTemplateInstance, GetTemplateInstances e InstantiateTemplate para crear flujos de trabajo a partir de esquemas. Estas operaciones no son de ámbito público, y solo se utilizan internamente para crear recursos en su nombre. Recibe CloudTrail eventos para crear flujos de trabajo.
Para crear un flujo de trabajo a partir de un esquema
-
Abre la AWS Lake Formation consola en https://console.aws.amazon.com/lakeformation/
. Inicie sesión como administrador del lago de datos o como usuario con permisos de ingeniero de datos. Para obtener más información, consulte Personas de Lake Formation y referencia de permisos IAM. -
En el panel de navegación, seleccione Esquemas y, a continuación, seleccione Utilizar esquema.
-
En la página Usar un esquema, elija un mosaico para seleccionar el tipo de esquema.
-
En Origen de importación, especifique el origen de datos.
Si está importando desde un origen JDBC, especifique lo siguiente:
-
Conexión a la base de datos. Elija una conexión de la lista. Cree conexiones adicionales utilizando la consola de AWS Glue. El nombre de usuario JDBC y la contraseña de la conexión determinan los objetos de la base de datos a los que tiene acceso el flujo de trabajo.
-
Ruta de datos de origen: introduzca
<database>/<schema>/<table>o<database>/<table>, según el producto de la base de datos. Oracle Database y MySQL no permiten utilizar un esquema en la ruta. Puede sustituir el carácter de porcentaje (%) por<schema>o<table>. Por ejemplo, para una base de datos Oracle con un identificador del sistema (SID) deorcl, introduzcaorcl/%para importar todas las tablas a las que tenga acceso el usuario nombrado en la conexión.importante
Este campo distingue entre mayúsculas y minúsculas. El flujo de trabajo fallará si no coincide entre mayúsculas y minúsculas en alguno de los componentes.
Si especifica una base de datos MySQL, AWS Glue ETL utiliza el controlador JDBC Mysql5 de forma predeterminada, por lo que MySQL8 no es compatible de forma nativa. Puede editar el script del trabajo ETL para utilizar un parámetro
customJdbcDriverS3Pathcomo el descrito en Valores de tipo de conexión JDBC en la Guía para desarrolladores de AWS Glue para utilizar un controlador JDBC diferente que sea compatible con MySQL8.
Si está importando desde un archivo de registro, asegúrese de que el rol que especifique para el flujo de trabajo (el "rol del flujo de trabajo") tenga los permisos IAM necesarios para acceder a los orígenes de datos. Por ejemplo, para importar AWS CloudTrail registros, el usuario debe tener los
cloudtrail:LookupEventspermisoscloudtrail:DescribeTrailsy para ver la lista de CloudTrail registros al crear el flujo de trabajo, y el rol del flujo de trabajo debe tener permisos en la CloudTrail ubicación de Amazon S3. -
-
Realice una de las siguientes acciones:
-
Para el tipo de esquema Instantánea de base de datos, identifique de forma opcional un subconjunto de datos a importar especificando uno o varios patrones de exclusión. Estos patrones de exclusión son Unix-style
globpatrones. Se almacenan como una propiedad de las tablas creadas por el flujo de trabajo.Para obtener más información sobre los patrones de exclusión disponibles, consulte Incluir y excluir patrones en la Guía para desarrolladores de AWS Glue .
-
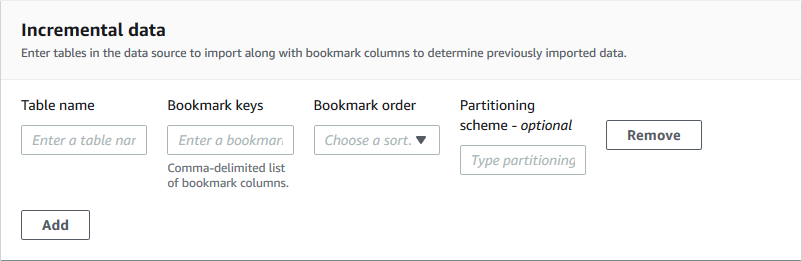
Para el tipo de esquema de base de datos incremental, especifique los siguientes campos. Agregue una fila para cada tabla que desee importar.
- Nombre de la tabla
-
Tabla que se va a importar. Debe estar en minúscula.
- Claves de marcadores
-
Comma-delimited lista de nombres de columnas que definen las claves de los marcadores. Si está en blanco, la clave principal se utiliza para determinar los datos nuevos. Las mayúsculas y minúsculas de cada columna deben coincidir con las definidas en los orígenes de datos.
nota
La clave principal se califica como clave marcadora predeterminada solo si es secuencialmente creciente o decreciente (sin huecos). Si desea utilizar la clave principal como clave de marcador y tiene huecos, debe nombrar la columna de clave principal como clave de marcador.
- Orden de los marcadores
-
Si elige Ascendente, las filas con valores superiores a los marcados se identifican como nuevas filas. Si elige Descendente, las filas con valores inferiores a los marcados se identifican como nuevas filas.
- Esquema de partición
-
(Opcional) Lista de columnas de claves de partición, delimitadas por barras (/). Ejemplo:
year/month/day.
Para más información, consulte Seguimiento de los datos procesados mediante marcadores de trabajo en la Guía para desarrolladores de AWS Glue .
-
-
En Importar destino, especifique la base de datos de destino, la ubicación de Amazon S3 de destino y el formato de datos.
Asegúrese de que el rol de flujo de trabajo tenga los permisos de Lake Formation necesarios en la base de datos y en la ubicación de destino de Amazon S3.
nota
Actualmente, los esquemas no admiten el cifrado de datos en el destino.
-
Elija una frecuencia de importación.
Puede especificar una expresión
croncon la opción Personalizada. -
En Opciones de importación:
-
Introduzca un nombre de flujo de trabajo.
-
Para el rol, elija el rol
LakeFormationWorkflowRole, que creó en (Opcional) Crear un rol de IAM para flujos de trabajo. -
Si lo desea, especifique un prefijo de tabla. El prefijo se antepone a los nombres de las tablas del Catálogo de datos que crea el flujo de trabajo.
-
-
Seleccione Crear y espere a que la consola informe de que el flujo de trabajo se ha creado correctamente.
sugerencia
¿Ha recibido este mensaje de error?
User: arn:aws:iam::<account-id>:user/<username>is not authorized to perform: iam:PassRole on resource:arn:aws:iam::<account-id>:role/<rolename>...Si es así, compruebe que lo ha sustituido por
<account-id>un número de AWS cuenta válido en todas las políticas.
Véase también:
