Aviso de fin de soporte: el 31 de octubre de 2025, AWS dejaremos de ofrecer soporte a Amazon Lookout for Vision. Después del 31 de octubre de 2025, ya no podrás acceder a la consola Lookout for Vision ni a los recursos de Lookout for Vision. Para obtener más información, visita esta entrada de blog
Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Análisis Amazon Lookout for Vision
Puede utilizar Amazon Lookout for Vision para encontrar defectos visuales en productos industriales de forma precisa y a escala, para tareas como:
-
Detección de piezas dañadas: detecte los daños en la calidad de la superficie, el color y la forma de un producto durante el proceso de fabricación y ensamblaje.
-
Identificación de los componentes faltantes: determine los componentes faltantes en función de la ausencia, presencia o ubicación de los objetos. Por ejemplo, falta un condensador en una placa de circuito impreso.
-
Detectar problemas del proceso: detecte defectos con patrones repetitivos, como arañazos repetidos en el mismo punto de una oblea de silicio.
Con Lookout for Vision se crea un modelo de visión artificial que predice la presencia de anomalías en una imagen. El usuario proporciona las imágenes que Amazon Lookout for Vision utiliza para entrenar y probar su modelo. Amazon Lookout for Vision proporciona métricas que puede utilizar para evaluar y mejorar su modelo entrenado. Puede alojar el modelo entrenado en la AWS nube o puede implementar el modelo en un dispositivo perimetral. Una API operación sencilla devuelve las predicciones que realiza el modelo.
El flujo de trabajo general para crear, evaluar y usar un modelo es el siguiente:
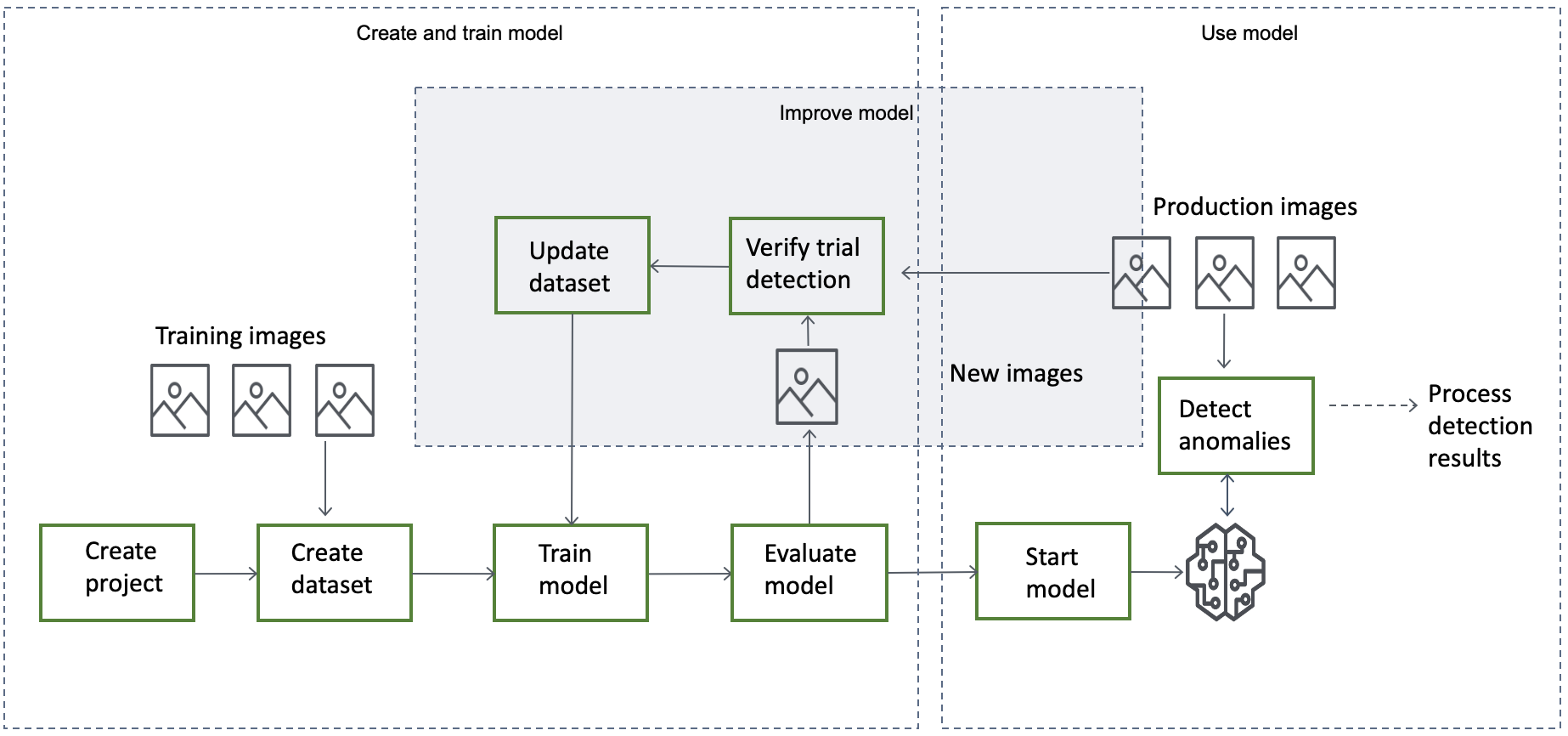
Temas
Elija su tipo de modelo
Antes de poder crear un modelo, debe decidir qué tipo de modelo desea. Puede crear dos tipos de modelo: clasificación de imágenes y segmentación de imágenes. El usuario decide el tipo de modelo que desea crear en función del caso de uso.
Ajuste de un modelo de clasificación de imágenes
Si solo necesita saber si una imagen contiene una anomalía, pero no necesita saber su ubicación, cree un modelo de clasificación de imágenes. Un modelo de clasificación de imágenes predice si una imagen contiene una anomalía. La predicción incluye la confianza del modelo en la precisión de la predicción. El modelo no proporciona ninguna información sobre la ubicación de las anomalías encontradas en la imagen.
Métricas del modelo de segmentación de imágenes
Si necesita conocer la ubicación de una anomalía, como la ubicación de un arañazo, cree un modelo de segmentación de imágenes. Los modelos de Amazon Lookout for Vision utilizan la segmentación semántica para identificar los píxeles de una imagen en los que se encuentran los tipos de anomalías (como un arañazo o una pieza faltante).
nota
Un modelo de segmentación semántica localiza diferentes tipos de anomalías. No proporciona información de instancia para anomalías individuales. Por ejemplo, si una imagen contiene dos abolladuras, Lookout for Vision devuelve información sobre ambas abolladuras en una sola entidad que representa el tipo de anomalía de abolladura.
Un modelo de segmentación de Amazon Lookout for Vision predice lo siguiente:
Clasificación
El modelo devuelve una clasificación para una imagen analizada (normal/anomalía), que incluye la confianza del modelo en la predicción. La información de clasificación se calcula por separado de la información de segmentación y no se debe suponer que existe una relación entre ambas.
Segmentación
El modelo devuelve una máscara de imagen que marca los píxeles en los que se producen las anomalías en la imagen. Los diferentes tipos de anomalías se codifican por colores según el color asignado a la etiqueta de anomalía en el conjunto de datos. Una etiqueta de anomalía representa el tipo de anomalía. Por ejemplo, la máscara azul de la siguiente imagen marca la ubicación de un tipo de anomalía por arañazo que se encuentra en un automóvil.

El modelo devuelve el código de color de cada etiqueta de anomalía de la máscara. El modelo también devuelve el porcentaje de cobertura de la imagen que tiene una etiqueta de anomalía.
Con un modelo de segmentación de Lookout for Vision, puede utilizar varios criterios para analizar los resultados del análisis del modelo. Por ejemplo:
-
Ubicación de las anomalías: si necesita saber la ubicación de las anomalías, utilice la información de segmentación para ver máscaras que las cubran.
-
Tipos de anomalías: utilice la información de segmentación para decidir si una imagen contiene más de un número aceptable de tipos de anomalías.
-
Área de cobertura: utilice la información de segmentación para decidir si un tipo de anomalía cubre más de un área aceptable de una imagen.
-
Clasificación de imágenes: si no necesita saber la ubicación de las anomalías, utilice la información de clasificación para determinar si una imagen contiene anomalías.
Para ver el código de ejemplo, consulte Detección de anomalías en una imagen.
Una vez que haya decidido qué tipo de modelo desea, cree un proyecto y un conjunto de datos para administrar el modelo. Con las etiquetas, puede clasificar las imágenes como normales o anómalas. Las etiquetas también identifican la información de segmentación, como las máscaras y los tipos de anomalías. La forma en que se etiquetan las imágenes en el conjunto de datos determina el tipo de modelo que Lookout for Vision crea.
Etiquetar un modelo de segmentación de imágenes es más complejo que etiquetar un modelo de clasificación de imágenes. Para entrenar un modelo de segmentación, hay que clasificar las imágenes de entrenamiento como normales o anómalas. También debe definir máscaras de anomalías y tipos de anomalías para cada imagen anómala. Un modelo de clasificación solo requiere que identifique las imágenes de entrenamiento como normales o anómalas.
Cree el modelo
El procedimiento para crear un modelo consiste en crear un conjunto de datos, crear conjuntos de datos de entrenamiento y de prueba y entrenar el modelo:
Crear un proyecto
Cree un proyecto para administrar los conjuntos de datos y los modelos que cree. Un proyecto debe utilizarse para un único caso de uso, como la detección de anomalías en un único tipo de pieza de la máquina.
Use el panel de control para obtener una visión general de los proyectos. Para obtener más información, consulte Uso del panel de Amazon Lookout for Vision.
Más información: Cree su proyecto.
Creación de un conjunto de datos
Para entrenar un modelo, Amazon Lookout for Vision necesita imágenes de objetos normales y anómalos para su caso de uso. Usted suministra estas imágenes en un conjunto de datos.
Un conjunto de datos es un conjunto de imágenes y etiquetas que describen esas imágenes. Las imágenes deben representar un único tipo de objeto en el que puedan producirse anomalías. Para obtener más información, consulte Preparación de imágenes para un conjunto de datos.
Con Amazon Lookout for Vision, puede tener un proyecto que utilice un único conjunto de datos o un proyecto que tenga conjuntos de datos de entrenamiento y prueba independientes. Recomendamos usar un proyecto de conjunto de datos único, a menos que desee tener un mayor control sobre el entrenamiento, las pruebas y el ajuste del rendimiento.
Para crear un conjunto de datos, importa las imágenes. Según cómo importe las imágenes, es posible que las imágenes también estén etiquetadas. De lo contrario, utilice la consola para etiquetar las imágenes.
Importación de imágenes
Si crea el conjunto de datos con la consola de Lookout for Vision, puede importar las imágenes de una de las siguientes maneras:
-
Importar imágenes de un equipo local. Las imágenes no están etiquetadas.
-
Importar imágenes de un bucket de S3. Amazon Lookout for Vision puede clasificar las imágenes mediante los nombres de las carpetas que las contienen. Use
normalpara imágenes normales. Se utilizaanomalypara imágenes anómalas. No puede asignar etiquetas de segmentación automáticamente. -
Importa un archivo de manifiesto de Amazon SageMaker AI Ground Truth. Las imágenes de un archivo de manifiesto están etiquetadas. Puede crear e importar su propio archivo de manifiesto. Si tiene muchas imágenes, considere utilizar el servicio de etiquetado SageMaker AI Ground Truth. A continuación, importas el archivo de manifiesto de salida del trabajo de Amazon SageMaker AI Ground Truth.
Etiquetado de imágenes
Las etiquetas describen una imagen de un conjunto de datos. Las etiquetas especifican si una imagen es normal o anómala (clasificación). Las etiquetas también describen la ubicación de las anomalías en una imagen (segmentación).
Si las imágenes no están etiquetadas, puede usar la consola para etiquetarlas.
Las etiquetas que asigna a las imágenes en el conjunto de datos determina el tipo de modelo que Lookout for Vision crea:
Clasificación de imágenes
Para crear un modelo de clasificación de imágenes, utilice la consola de Lookout for Vision para clasificar las imágenes del conjunto de datos como normales o anómalas.
También puede usar la operación CreateDataset para crear un conjunto de datos a partir de un archivo de manifiesto que incluya información de clasificación.
Segmentación de imágenes
Para crear un modelo de clasificación de imágenes, utilice la consola de Lookout for Vision para clasificar las imágenes del conjunto de datos como normales o anómalas. También especificas máscaras de píxeles para las áreas anómalas de la imagen (si existen), así como una etiqueta de anomalía para las máscaras de anomalías individuales.
También puede usar la operación CreateDataset para crear un conjunto de datos a partir de un archivo de manifiesto que incluya información de segmentación y clasificación.
Si su proyecto tiene conjuntos de datos de entrenamiento y de prueba independientes, Lookout for Vision usa el conjunto de datos de entrenamiento para aprender y determinar el tipo de modelo. Debería etiquetar las imágenes del conjunto de datos de prueba de la misma manera.
Más información: Cómo crear un conjunto de datos.
Entrenamiento de su modelo
El entrenamiento crea un modelo y lo entrena para predecir la presencia de anomalías en las imágenes. Se creará una nueva versión del modelo cada vez que se entrena.
Al inicio del entrenamiento, Amazon Lookout for Vision elija el algoritmo más adecuado para entrenar el modelo. El modelo se entrena y, a continuación, se prueba. Si entrenas un único proyecto de conjunto de datos, el conjunto de datos se divide internamente para crear un conjunto de datos de entrenamiento y un conjunto de datos de prueba. Introducción a Amazon Lookout for Vision También puede crear un proyecto que tenga conjuntos de datos de entrenamiento y de prueba independientes. En esta configuración, Amazon Lookout for Vision entrena el modelo con el conjunto de datos de entrenamiento y prueba el modelo con el conjunto de datos de prueba.
importante
Se le cobrará por el tiempo que se tarde en entrenar correctamente un modelo.
Más información: Entrene su modelo.
Evaluar el modelo
Evalúe el rendimiento del modelo mediante las métricas de rendimiento creadas durante las pruebas.
Al utilizar las métricas de rendimiento, puede comprender mejor el rendimiento de su modelo entrenado y decidir si está preparado para usarlo en producción.
Más información: Cómo mejorar su modelo.
Si las métricas de rendimiento indican que es necesario realizar mejoras, puede añadir más datos de entrenamiento realizando una tarea de pruebas de detección con imágenes nuevas. Una vez finalizada la tarea, puede verificar los resultados y añadir las imágenes verificadas a su conjunto de datos de entrenamiento. Como alternativa, puede añadir nuevas imágenes de entrenamiento directamente al conjunto de datos. A continuación, vuelve a entrenar el modelo y vuelve a comprobar las métricas de rendimiento.
Más información: Verificar el modelo con una tarea de detección de prueba.
Use su modelo
Antes de poder usar el modelo en la AWS nube, hay que iniciarlo con la StartModeloperación. Puede obtener el StartModel CLI comando de su modelo desde la consola.
Más información: Inicie el modelo.
Un modelo entrenado de Amazon Lookout for Vision predice si una imagen de entrada contiene contenido normal o anómalo. Si su modelo es un modelo de segmentación, la predicción incluye una máscara de anomalías que marca los píxeles en los que se encuentran las anomalías.
Para hacer una predicción con su modelo, llame a la DetectAnomaliesoperación y pase una imagen de entrada desde su ordenador local. Puede obtener el CLI comando que llama DetectAnomalies desde la consola.
Más información: Detecta anomalías en una imagen.
importante
Se le cobrará por el tiempo de ejecución del modelo.
Si ya no utiliza el modelo, utilice la StopModeloperación para detenerlo. Puede obtener el CLI comando desde la consola.
Más información: Detenga su modelo.
Use su modelo en un dispositivo de borde
Puedes usar un modelo Lookout for Vision en AWS IoT Greengrass Version 2 un dispositivo principal.
Más información: Uso del modelo Amazon Lookout for Vision en un dispositivo de borde.
Cómo usar el panel
Puede utilizar el panel de control para obtener una visión general de todos sus proyectos e información general de los proyectos individuales.
Más información: Usar el panel de control.
