Ya no actualizamos el servicio Amazon Machine Learning ni aceptamos nuevos usuarios para él. Esta documentación está disponible para los usuarios actuales, pero ya no la actualizamos. Para obtener más información, consulte Qué es Amazon Machine Learning.
Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Análisis de datos
Amazon ML procesa estadísticas descriptivas de los datos de entrada que puede utilizar para comprender los datos.
Estadísticas descriptivas
Amazon ML procesa las siguientes estadísticas descriptivas de diferentes tipos de atributo:
Numérico:
-
Histogramas de la distribución
-
Número de valores no válidos
-
Valores mínimos, medios y máximos
Binario y categórico:
-
Cantidad (de valores distintos por categoría)
-
Histogramas de la distribución de valores
-
Valores más frecuentes
-
Cantidad de valores exclusivos
-
Porcentaje del valor "true" (solo binario)
-
Palabras más destacadas
-
Palabras más frecuentes
Texto:
-
Nombre del atributo
-
Correlación con el destino (si el destino está establecido)
-
Total de palabras
-
Palabras exclusivas
-
Alcance del número de palabras en una línea
-
Alcance de la longitud de palabra
-
Palabras más destacadas
Estadísticas de los datos de acceso de la consola Amazon ML
En la consola Amazon ML, puede elegir el nombre o ID de cualquier origen de datos para ver la página Estadísticas de datos. Esta página proporciona métricas y visualizaciones que permiten obtener más información acerca de los datos de entrada asociados a la fuente de datos, incluyendo la siguiente información:
-
Resumen de datos
-
Distribuciones de destino
-
Valores faltantes
-
Valores no válidos
-
Estadísticas de resumen de las variables por tipo de datos
-
Distribuciones de variables por tipo de datos
Las siguientes secciones describen las métricas y visualizaciones de forma más detallada.
Resumen de datos
El informe del resumen de los datos de una fuente de datos muestra información resumida, incluido el ID y el nombre de la fuente de datos, dónde se ha completado, el estado actual, el atributo de destino, la información de los datos de entrada (la ubicación del depósito de S3, el formato de datos, el número de registros procesados y el número de registros incorrectos encontrados durante el procesamiento), así como el número de variables por tipo de datos.
Distribuciones de destino
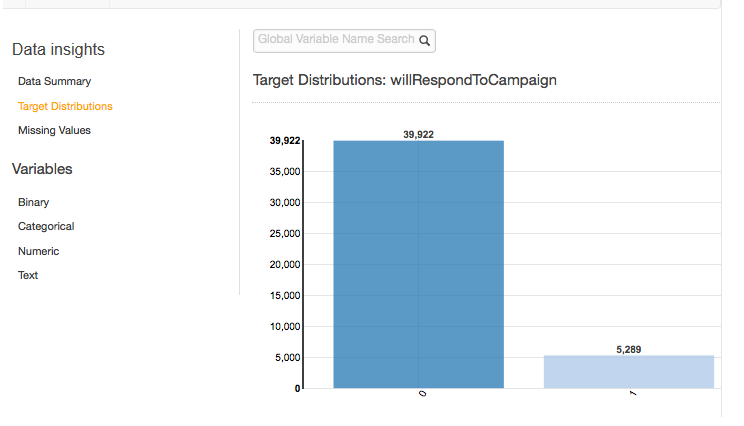
El informe de las distribuciones de destino muestra la distribución del atributo de destino de la fuente de datos. En el siguiente ejemplo, hay 39.922 observaciones en las que el atributo will RespondToCampaign target es igual a 0. Este es el número de clientes que no han respondido a la campaña de correo electrónico. Hay 5.289 observaciones en las que will es igual a RespondToCampaign 1. Este es el número de clientes que han respondido a la campaña de correo electrónico.
Valores que faltan
El informe de los valores que faltan muestra una lista de los atributos de los datos de entrada para los que faltan valores. Solo pueden faltar valores a los atributos con tipos numéricos de datos. Teniendo en cuenta que los valores que faltan pueden influir a la calidad del entrenamiento de un modelo de ML, recomendamos que se proporcionen a ser posible.
Durante el entrenamiento del modelo de ML, si falta el atributo de destino, Amazon ML rechaza el registro correspondiente. Si el atributo de destino está en el registro, pero falta un valor de otro atributo numérico, Amazon ML ignora el valor que falta. En este caso, Amazon ML crea un atributo sustituto y lo establece a 1 para indicar que este atributo falta. Esto permite que Amazon ML aprenda patrones a partir de la aparición de valores que faltan.
Valores no válidos
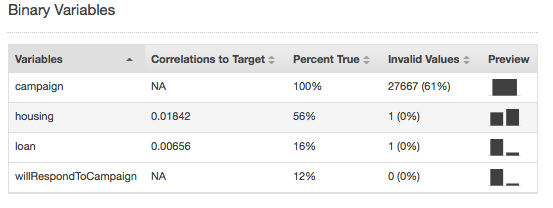
Los valores no válidos solo pueden aparecer con los tipos de datos numéricos y binarios. Puede encontrar valores no válidos si consulta las estadísticas de resumen de las variables de los informes de tipos de datos. En los siguientes ejemplos, aparecen un valor no válido para el atributo numérico de duración y dos valores no válidos para el tipo de datos binario (uno en el atributo del alojamiento y otro en el atributo de préstamo).

Variable-Target Correlación
Después de crear una fuente de datos, Amazon ML puede evaluar la fuente de datos e identificar la correlación, o el impacto, entre las variables y el destino. Por ejemplo, el precio de un producto podría tener un impacto significativo sobre el hecho de si es un éxito de ventas o no, mientras que las dimensiones del producto tendrían poco poder predictivo.
Se suele recomendar incluir tantas variables como sea posible en los datos de aprendizaje. Sin embargo, el ruido que se genera al incluir muchas variables con poco poder predictivo podría afectar negativamente a la calidad y precisión del modelo de ML.
Puede que pueda mejorar el rendimiento predictivo del modelo eliminando variables que tengan poco impacto cuando formes el modelo. Puede definir las variables que estarán disponibles para el proceso de machine learning en una receta, que consiste en un mecanismo de transformación de Amazon ML. Para obtener más información acerca de las recetas, consulte la Transformación de datos para el aprendizaje automático.
Estadísticas de resumen de los atributos por tipo de datos
En el informe de las estadísticas de datos, puede ver las estadísticas de resumen de los atributos por los siguientes tipos de datos:
-
Binario
-
Categórico
-
Numérico
-
Texto
Las estadísticas de resumen del tipo de datos binario muestran todos los atributos binarios. La columna Correlations to target (Correlaciones con el destino) muestra la información que comparten la columna del destino y la columna del atributo. La columna Percent true (Porcentaje de "true") muestra el porcentaje de las observaciones que tienen el valor 1. La columna Invalid values (Valores no válidos) muestra el número de valores no válidos, así como el porcentaje de valores no válidos para cada atributo. La columna Preview (Vista previa) proporciona un enlace a una distribución gráfica para cada atributo.
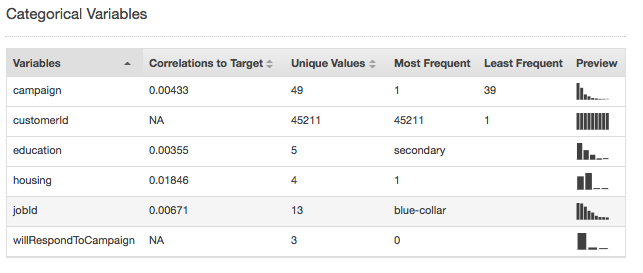
Las estadísticas de resumen del tipo de datos categórico muestran todos los atributos categóricos con la cantidad de valores únicos, el valor más frecuente y el valor menos frecuente. La columna Preview (Vista previa) proporciona un enlace a una distribución gráfica para cada atributo.
Las estadísticas de resumen del tipo de datos numérico muestran todos los atributos numéricos con el número de valores que faltan, de valores no válidos, del alcance de los valores y la media. La columna Preview (Vista previa) proporciona un enlace a una distribución gráfica para cada atributo.
Las estadísticas de resumen del tipo de datos textual muestran todos los atributos textuales, el número total de palabras de dicho atributo, el número de palabras de dicho atributo exclusivo, el alcance de las palabras de un atributo, el alcance de la longitud de palabra y las palabras más destacadas. La columna Preview (Vista previa) proporciona un enlace a una distribución gráfica para cada atributo.
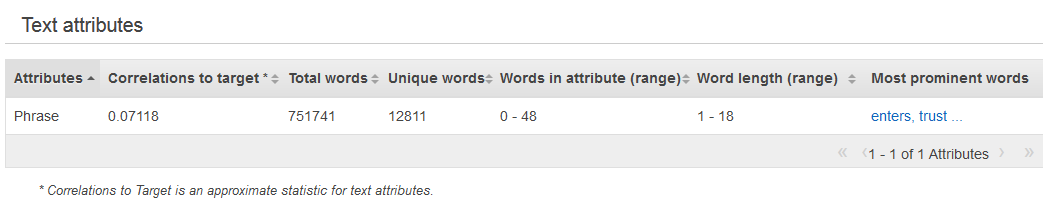
El siguiente ejemplo muestra las estadísticas del tipo de datos textual para una variable textual denominada "review", con cuatro registros.
1. The fox jumped over the fence. 2. This movie is intriguing. 3. 4. Fascinating movie.
Las columnas de este ejemplo muestran la siguiente información.
-
La columna Attributes (Atributos) muestra el nombre de la variable. En este ejemplo, en esta columna aparecería "review".
-
La columna Correlations to target (Correlaciones con el destino) solo existe si se especifica un destino. La correlación calcula la cantidad de información que proporciona este atributo sobre el destino. Cuanto mayor sea la correlación, más información proporciona este atributo sobre el destino. La correlación se calcula en términos de información mutua entre una representación del atributo del texto y el destino.
-
La columna Total words (Total de palabras) muestra el número de palabras generadas a partir de la tokenización de cada registro, delimitando las palabras con espacios en blanco. En este ejemplo, en esta columna aparecería "12".
-
La columna Unique word (Palabra única) muestra el número de palabras únicas de un atributo. En este ejemplo, en esta columna aparecería "10".
-
La columna Words in attribute (range) (Palabras en el atributo [rango]) muestra el número de palabras en una sola fila del atributo. En este ejemplo, en esta columna aparecería "0-6".
-
La columna Word length (range) (Longitud de palabra [rango]) muestra cuántos caracteres hay en las palabras. En este ejemplo, en esta columna aparecería "2-11".
-
La columna Most prominent words (Palabras más destacadas) muestra una lista ordenada por importancia de las palabras que aparecen en el atributo. Si existe un atributo de destino, las palabras se clasifican según su correlación con el destino, lo que significa que las palabras con mayor correlación se enumerarán en primer lugar. Si no hay destino en los datos, las palabras se clasifican según su entropía.
Distribución de atributos binarios y categóricos
Al hacer clic en el enlace Preview (Vista previa) asociado a un atributo categórico o binario, puede ver la distribución de dicho atributo, así como los datos de muestra del archivo inicial de cada valor categórico del atributo.
Por ejemplo, la siguiente instantánea muestra la distribución del atributo categórico jobId. La distribución muestra los 10 valores categóricos más importantes, con todos los demás valores agrupados como "other". Clasifica cada uno de los 10 valores categóricos más importantes con el número de observaciones del archivo de entrada que contiene dicho valor, así como un enlace para ver ejemplos de observaciones de los archivos de los datos de entrada.
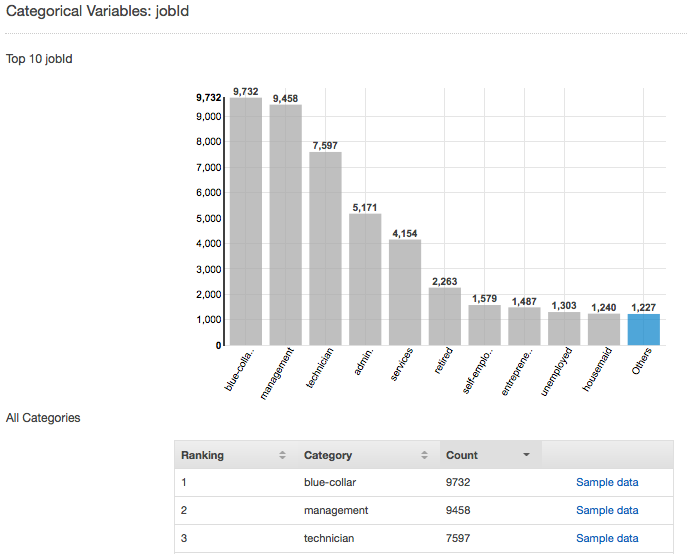
Distribución de atributos numéricos
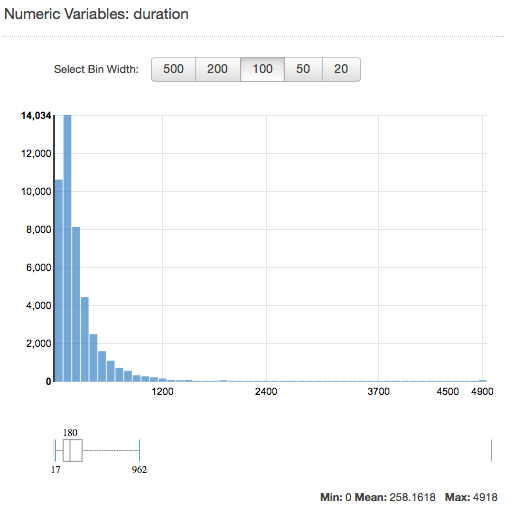
Para consultar la distribución de un atributo numérico, haga clic en el enlace Preview (Vista previa) del atributo. Cuando vea la distribución de un atributo numérico, puede elegir el tamaño de la papelera entre 500, 200, 100, 50 o 20. Cuanto mayor sea el tamaño de la papelera, menor será el número de gráficos de barras que se mostrará. Además, la resolución de la distribución será amplia para los tamaños de la papelera más grandes. En cambio, ajustando el tamaño del depósito a 20 aumenta la resolución de la distribución que se muestra.
También se muestran los valores mínimos, medios y máximos, tal como se muestra en la siguiente captura de pantalla.
Distribución de atributos textuales
Para consultar la distribución de un atributo textual, haga clic en el enlace Preview (Vista previa) del atributo. Cuando vea la distribución de un atributo de texto, verá la siguiente información.
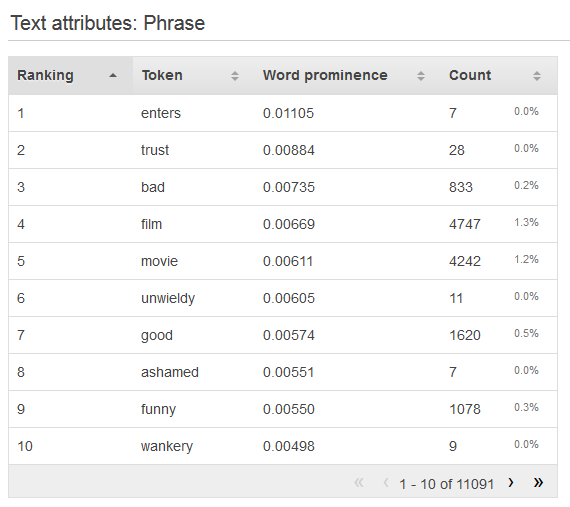
- Clasificación
-
Los tokens textuales se clasifican según la cantidad de información que transmiten, del más informativo al menos informativo.
- Token
-
Los tokens muestran la palabra del texto de entrada sobre la fila de las estadísticas.
- Importancia de las palabras
-
Si existe un atributo de destino, las palabras se clasificarán según su correlación con el destino, lo que significa que las palabras que tengan mayor correlación se enumerarán en primer lugar. Si no hay destino en los datos, las palabras se clasificarán según su entropía, es decir, según la cantidad de información que pueden comunicar.
- Cantidad
-
La cantidad muestra el número de registros de entrada en los que apareció el token.
- Porcentaje
-
El porcentaje muestra el porcentaje de las líneas de los datos de entrada en los que apareció el token.
