Ya no actualizamos el servicio Amazon Machine Learning ni aceptamos nuevos usuarios para él. Esta documentación está disponible para los usuarios actuales, pero ya no la actualizamos. Para obtener más información, consulte Qué es Amazon Machine Learning.
Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Informaciones sobre el modelo de regresión
Interpretación de las predicciones
La salida de un modelo de regresión de ML es un valor numérico para la predicción del destino que hace el modelo. Por ejemplo, si prevé precios inmobiliarios, la predicción del modelo podría ser un valor como 254 013.
nota
El rango de las predicciones puede ser diferente del rango del destino en los datos de entrenamiento. Por ejemplo, supongamos que está prediciendo precios inmobiliarios y que el destino en los datos de entrenamiento tenía valores con un rango de 0 a 450 000. El destino predicho no tiene por qué encontrarse en el mismo rango y puede tener cualquier valor positivo (mayor que 450 000) o valor negativo (inferior a cero). Es importante planificar cómo afrontar los valores de predicciones que superen un rango aceptable para su aplicación.
Medición de la precisión del modelo de ML
Para las tareas de regresión, Amazon ML utiliza la métrica estándar en el sector, la desviación cuadrática media o, en inglés, "root mean square error" (RMSE). Es una medida de distancia entre el destino numérico predicho y la respuesta numérica real (dato real). Cuanto más pequeño sea el valor RMSE, mejor será la exactitud predictiva del modelo. Un modelo con unas predicciones perfectamente correctas tendría un valor RMSE de 0. El siguiente ejemplo muestra los datos de evaluación que contienen N registros:

RMSE de referencia
Amazon ML proporciona una métrica de referencia para modelos de regresión. Es el valor RMSE para un modelo de regresión hipotético que predeciría siempre la media del destino como respuesta. Por ejemplo, si estuviera prediciendo la edad de un comprador de una casa y la edad media para las observaciones en sus datos de entrenamiento fuera 35, el modelo de referencia siempre predeciría la respuesta como 35. Compararía entonces su modelo de ML con esta referencia para validar si el modelo de ML es mejor que un modelo de ML que predice esta respuesta constante.
Uso de la visualización del desempeño
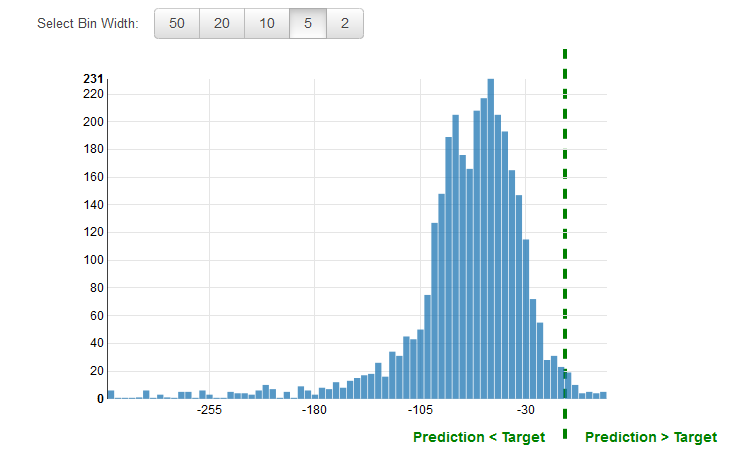
Es una práctica común repasar los residuales para los problemas de regresión. Un residual para una observación en los datos de evaluación es la diferencia entre el destino verdadero y el destino predicho. Los residuales representan la parte del destino que el modelo no puede predecir. Un residual positivo indica que el modelo está subestimando el destino (el destino real es mayor que el destino predicho). Un residual negativo indica una sobreestimación (el destino real es menor que el destino predicho). El histograma de los residuales en los datos de evaluación distribuido en forma de campana y centrado en el cero indica que el modelo comete errores de forma aleatoria y no subestima o sobreestima sistemáticamente un rango determinado de valores de destino. Si los residuales no dibujan una forma de campana centrada en el cero, existe una estructura en el error de predicción del modelo. Añadir más variables al modelo podría ayudar a este a capturar el patrón que no captura el modelo actual. En la siguiente ilustración aparecen los residuales que no están centrados en el cero.