Ya no actualizamos el servicio Amazon Machine Learning ni aceptamos nuevos usuarios para él. Esta documentación está disponible para los usuarios actuales, pero ya no la actualizamos. Para obtener más información, consulte Qué es Amazon Machine Learning.
Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
División de datos
El objetivo fundamental de un modelo de ML es realizar predicciones precisas sobre futuras instancias de datos más allá de aquellos que se utilizan para entrenar modelos. Antes de utilizar un modelo de ML para realizar predicciones, debemos evaluar el rendimiento predictivo del modelo. Para valorar la calidad de las predicciones de un modelo de ML con datos que no ha visto, podemos reservar, o dividir, una parte de los datos de los que ya sabemos la respuesta como un proxy para futuros datos y evaluar la capacidad del modelo de ML para predecir las respuestas correctas para dichos datos. El origen de datos se divide en una parte para el entrenamiento del origen de datos y otra parte para la evaluación del origen de datos.
Amazon ML ofrece tres opciones para dividir los datos:
-
Pre-split los datos: puede dividir los datos en dos ubicaciones de entrada de datos antes de cargarlos en Amazon Simple Storage Service (Amazon S3) y crear dos fuentes de datos independientes con ellos.
-
División secuencial de Amazon ML: podemos pedirle a Amazon ML que divida los datos de forma secuencial durante la creación de fuentes de datos para la formación y la evaluación.
-
División aleatoria de Amazon ML: podemos pedirle a Amazon ML que divida los datos con un método aleatorio durante la creación de orígenes de datos para el entrenamiento y la evaluación.
Pre-splitting Sus datos
Si desea tener un control explícito de los datos durante el entrenamiento y la evaluación de las fuentes de datos, divida los datos en diferentes ubicaciones de datos y cree otra fuente de datos para las ubicaciones de entrada y de evaluación.
División secuencial de datos
Una manera sencilla de dividir los datos de entrada para el entrenamiento y la evaluación consiste en seleccionar subconjuntos de datos que no se solapen y, al mismo tiempo, preservar el orden de los registros de datos. Este enfoque resulta útil si desea evaluar sus modelos de ML en relación con los datos de una determinada fecha o dentro de un determinado intervalo de tiempo. Por ejemplo, digamos que tiene los datos de compromiso de los clientes de los últimos cinco meses y que desea utilizar estos datos históricos para predecir el compromiso de los clientes del siguiente mes. Con el principio del rango para la formación y los datos del final del rango para la evaluación podría producirse una estimación más precisa de la calidad del modelo de datos que no utilizando los datos de los registros de todo el rango de datos.
La siguiente figura muestra ejemplos de cuándo debe utilizar una estrategia de división secuencial y cuándo debe utilizar una estrategia aleatoria.
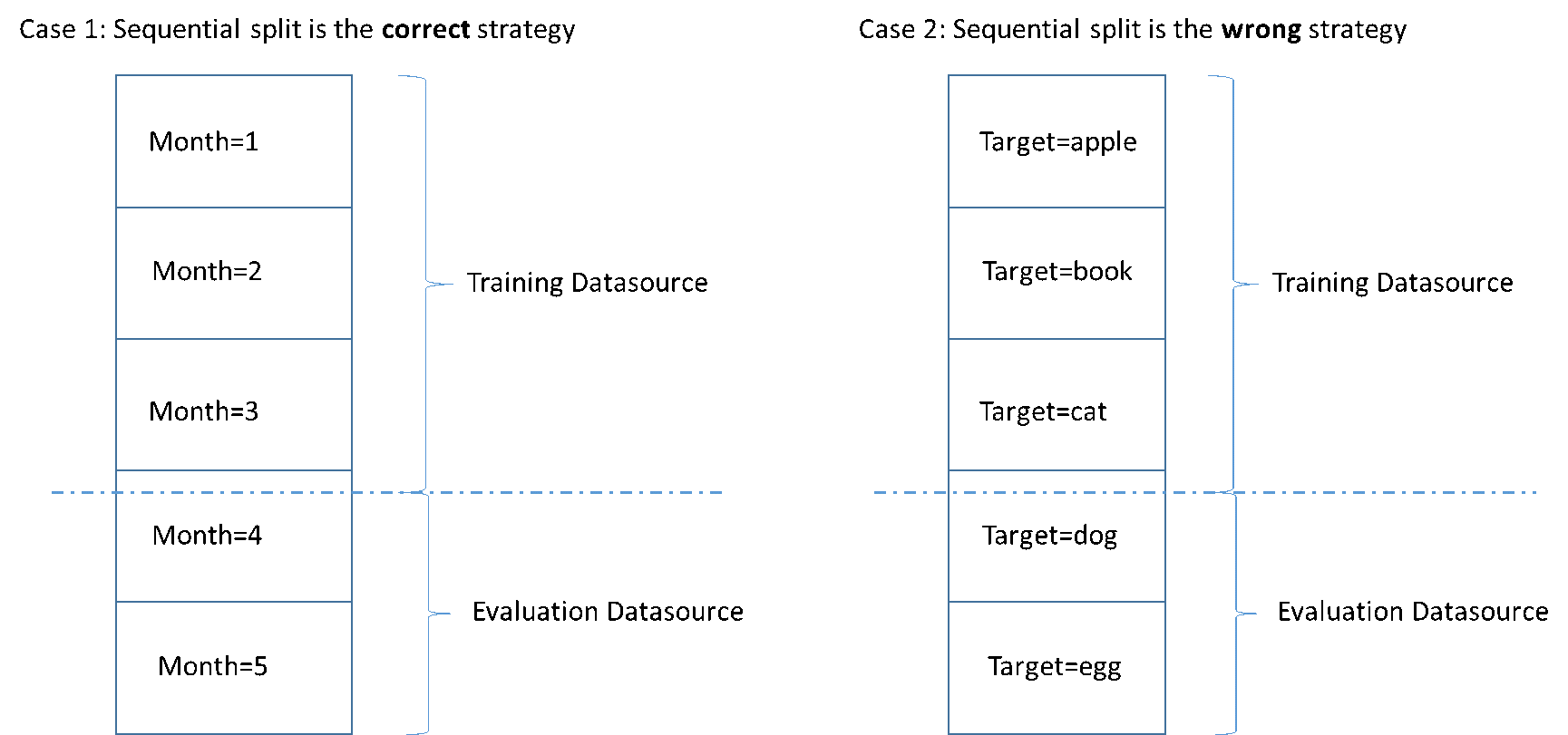
Cuando crea una fuente de datos, puede optar por dividir su fuente de datos de forma secuencial, y Amazon ML utilizará el primer 70 % de los datos para la formación y el 30 restante de los datos para la evaluación. Este es el enfoque predeterminado cuando utilizar la consola de Amazon ML para dividir los datos.
División aleatoria de datos
Dividir los datos de entrada de forma aleatoria en fuentes de datos para la formación y la evaluación garantiza que la distribución de los datos sea similar en la formación y en la evaluación de fuentes de datos. Elija esta opción cuando no necesite conservar el orden de los datos de entrada.
Amazon ML usa un método pseudo-aleatorio para la generación de números para dividir los datos. El origen se basa en parte, en el valor de una cadena de entrada y, en parte, en el contenido de los propios datos. Por defecto, la consola Amazon ML usa la ubicación S3 de los datos de entrada de la cadena. Los usuarios de la API pueden proporcionar una cadena personalizada. Esto quiere decir que proporcionando el mismo bucket de S3 y datos, Amazon ML divide los datos de la misma forma cada vez. Para cambiar la manera en la que Amazon ML divide los datos, puede utilizar la API CreateDatasourceFromS3, CreateDatasourceFromRedshift o CreateDatasourceFromRDS y proporcionar un valor para la cadena de origen. Al utilizar estas API para crear fuentes de datos independientes para la formación y la evaluación, es importante utilizar el mismo valor de la cadena de origen tanto para las fuentes de datos como para el marcador del complemento de una fuente de datos, para garantizar que los datos para la formación y para la evaluación no se solapen.
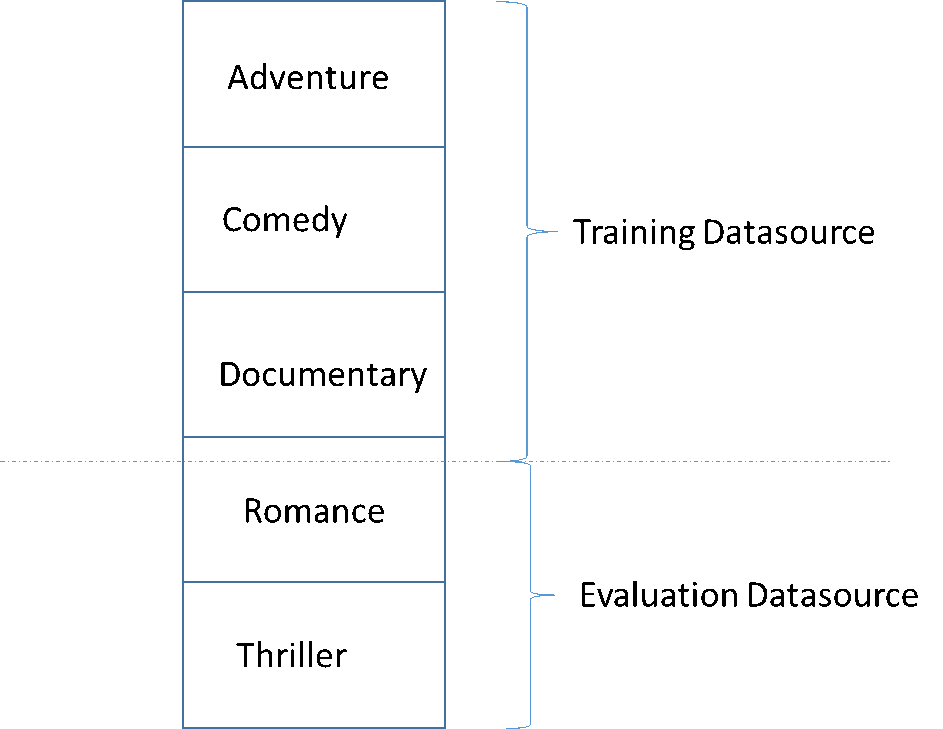
Un problema común en el desarrollo de un modelo de ML de alta calidad es la evaluación del modelo de ML en relación con los datos que no se parecen a los datos utilizados para la formación. Por ejemplo, digamos que está utilizando ML para predecir el género de películas y que sus datos de formación contienen películas de aventuras, comedias y documentales. Sin embargo, los datos de evaluación solo contienen datos de películas románticas y de suspense. En este caso, el modelo de ML no había almacenado ninguna información sobre las películas románticas y de suspense, y en la evaluación no se ha evaluado la eficacia del modelo con el aprendizaje de patrones para películas de aventuras, comedias y documentales. Como resultado, la información sobre el género no es útil y la calidad de las predicciones del modelo de ML para todos los géneros no es fiable. El modelo y la evaluación son demasiado diferentes (tienen estadísticas descriptivas extremadamente diferentes) para ser útiles. Esto puede ocurrir cuando los datos de entrada se ordenan por una de las columnas del conjunto de datos y, a continuación, se dividen de forma secuencial.
Si las fuentes de datos para el entrenamiento y la evaluación tienen diferentes distribuciones de datos, verá una alerta de evaluación en la evaluación de su modelo. Para obtener más información sobre las alertas de evaluación, consulte Alertas de evaluación.
No es necesario utilizar la división aleatoria de Amazon ML si ya se han aleatorizado los datos de entrada, por ejemplo, mediante la transferencia aleatoria de los datos de entrada a Amazon S3, o mediante la utilización de la random() función de una consulta SQL de Amazon Redshift o la función rand() de una consulta MySQL de SQL al crear orígenes de datos. En estos casos, puede confiar en la opción de la división secuencial para crear fuentes de datos para la formación y la evaluación con distribuciones similares.
