Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Creación de imágenes de algoritmos
Un SageMaker algoritmo de Amazon requiere que el comprador traiga sus propios datos para entrenarse antes de hacer predicciones. Como AWS Marketplace vendedor, puedes usarlo SageMaker para crear algoritmos y modelos de aprendizaje automático (ML) que tus compradores puedan utilizar AWS. En las siguientes secciones se explica cómo crear imágenes de algoritmos AWS Marketplace. Esto incluye la creación de la imagen de entrenamiento de Docker para entrenar el algoritmo y la imagen de inferencia que contiene la lógica de inferencia. Tanto las imágenes de entrenamiento como las de inferencia son obligatorias para publicar un producto de algoritmo.
Temas
Información general
Un algoritmo incluye los siguientes componentes:
-
Una imagen de entrenamiento almacenada en Amazon ECR
-
Una imagen de inferencia almacenada en Amazon Elastic Container Registry (AmazonECR)
nota
En el caso de los productos de algoritmos, el contenedor de entrenamiento genera artefactos del modelo que se cargan en el contenedor de inferencias al implementar el modelo.
En el siguiente diagrama se muestra el flujo de trabajo de publicación y uso de productos de algoritmos.
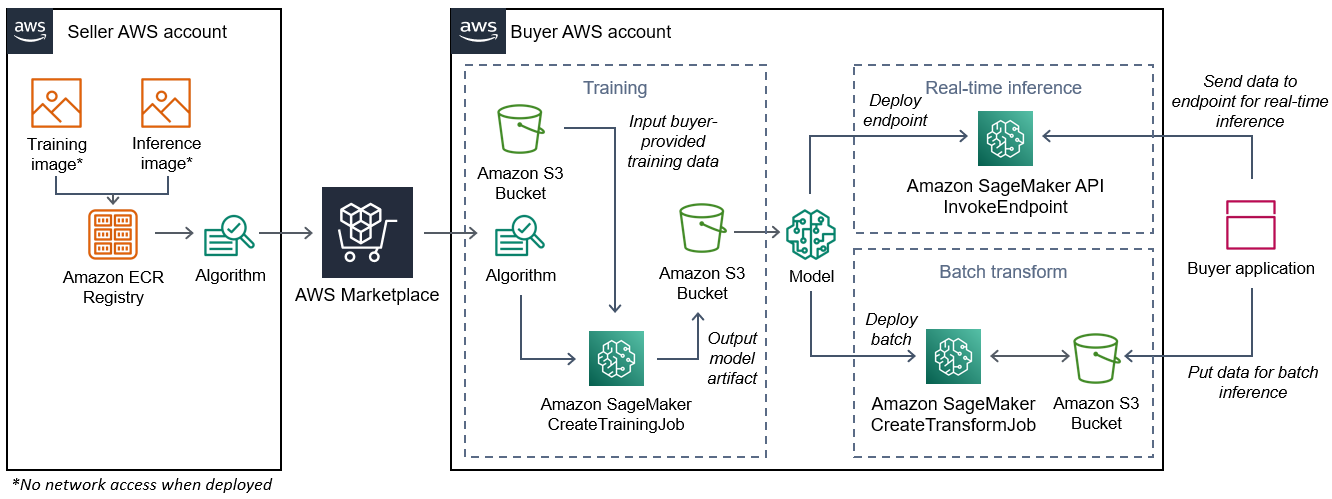
El flujo de trabajo para crear un SageMaker algoritmo AWS Marketplace incluye los siguientes pasos:
-
El vendedor crea una imagen de formación y una imagen de inferencia (no hay acceso a la red cuando se despliega) y las sube al Registro de AmazonECR.
-
A continuación, el vendedor crea un recurso de algoritmo en Amazon SageMaker y publica su producto de aprendizaje automático en él AWS Marketplace.
-
El comprador se suscribe al producto de ML.
-
El comprador crea un trabajo de formación con un conjunto de datos compatible y los valores de hiperparámetros adecuados. SageMaker ejecuta la imagen de entrenamiento y carga los datos de entrenamiento y los hiperparámetros en el contenedor de entrenamiento. Cuando se completa el trabajo de entrenamiento, los artefactos del modelo que se encuentran en
/opt/ml/model/se comprimen y se copian en el bucket de Amazon S3del comprador. -
El comprador crea un paquete de modelos con los artefactos del modelo de entrenamiento almacenado en Amazon S3 e implementa el modelo.
-
SageMaker ejecuta la imagen de inferencia, extrae los artefactos del modelo comprimido y carga los archivos en la ruta del directorio del contenedor de inferencias,
/opt/ml/model/donde son consumidos por el código que sirve para la inferencia. -
Ya sea que el modelo se despliegue como punto final o como trabajo de transformación por lotes, SageMaker transfiere los datos para su inferencia en nombre del comprador al contenedor a través del HTTP punto final del contenedor y devuelve los resultados de la predicción.
nota
Para obtener más información, consulte Entrenar modelos.
Crear una imagen de entrenamiento para algoritmos
En esta sección se proporciona un tutorial para empaquetar el código de entrenamiento en una imagen de entrenamiento. Se necesita una imagen de entrenamiento para crear un producto de algoritmo.
Una imagen de entrenamiento es una imagen de Docker que contiene su algoritmo de entrenamiento. El contenedor se adhiere a una estructura de archivos específica que permite copiar los datos SageMaker hacia y desde el contenedor.
Tanto las imágenes de entrenamiento como las de inferencia son obligatorias para publicar un producto de algoritmo. Tras crear la imagen de entrenamiento, debe crear una imagen de inferencia. Las dos imágenes se pueden combinar en una sola imagen o permanecer como imágenes independientes. Usted decide si desea combinar las imágenes o separarlas. Por lo general, la inferencia es más sencilla que el entrenamiento, y es posible que desee separar las imágenes para mejorar el rendimiento de la inferencia.
nota
El siguiente es solo un ejemplo de código de empaquetado para una imagen de entrenamiento. Para obtener más información, consulte Utilice sus propios algoritmos y modelos con los AWS MarketplaceAWS Marketplace SageMaker ejemplos incluidos
Paso 1: Creación de la imagen del contenedor
Para que la imagen de entrenamiento sea compatible con Amazon SageMaker, debe seguir una estructura de archivos específica que permita SageMaker copiar los datos de entrenamiento y las entradas de configuración en rutas específicas de tu contenedor. Cuando finaliza el entrenamiento, los artefactos del modelo generados se almacenan en una ruta de directorio específica en el contenedor desde el que se SageMaker copian.
A continuación, se utiliza Docker CLI instalado en un entorno de desarrollo en una distribución Ubuntu de Linux.
Preparar el programa para leer las entradas de configuración
Si su programa de entrenamiento requiere alguna entrada de configuración proporcionada por el comprador, la siguiente es la ubicación en la que se copian dentro del contenedor cuando se ejecuta. Si es necesario, el programa debe leer esas rutas de archivo específicas.
-
/opt/ml/input/configes el directorio que contiene la información que controla el funcionamiento del programa.-
hyperparameters.jsones un diccionario JSON con formato B de nombres y valores de hiperparámetros. Los valores son cadenas, por lo que puede que necesite convertirlos. -
resourceConfig.jsones un archivo con JSON formato K que describe el diseño de la red utilizado para la formación distribuida. Si su imagen de formación no admite la formación distribuida, puede omitir este archivo.
-
nota
Para obtener más información sobre las entradas de configuración, consulta Cómo Amazon SageMaker proporciona información de formación.
Preparar el programa para leer entradas de datos
Los datos de entrenamiento se pueden pasar al contenedor en uno de los dos modos siguientes. El programa de entrenamiento que se ejecuta en el contenedor digiere los datos de entrenamiento en uno de esos dos modos.
Modo de archivo
-
/opt/ml/input/data/<channel_name>/contiene los datos de entrada de ese canal. Los canales se crean en función de la llamada a la operaciónCreateTrainingJob, pero generalmente es importante que los canales coincidan con lo que espera el algoritmo. Los archivos de cada canal se copian de Amazon S3a este directorio, conservando la estructura de árbol indicada por la estructura de claves de Amazon S3.
Modo de canalización
-
/opt/ml/input/data/<channel_name>_<epoch_number>es la canalización de una fecha de inicio determinada. Las fechas de inicio (epochs) comienzan en cero y aumentan en una cada vez que las lees. No hay límite en cuanto al número de épocas que puede recorrer, pero debe cerrar cada canalización antes de leer la siguiente.
Prepare su programa para escribir los resultados del entrenamiento
El resultado del entrenamiento se escribe en los siguientes directorios de contenedores:
-
/opt/ml/model/es el directorio en el que se escribe el modelo o los artefactos del modelo que genera su algoritmo de entrenamiento. El modelo puede estar en el formato que desee. Puede ser un único archivo o un árbol de directorios completo. SageMaker empaqueta todos los archivos de este directorio en un archivo comprimido (.tar.gz). Este archivo está disponible en la ubicación de Amazon S3 devuelta por laDescribeTrainingJobAPI operación. -
/opt/ml/output/es un directorio en el que el algoritmo puede escribir un archivofailureque describa el motivo del error en la tarea. El contenido de este archivo se devuelve en el campoFailureReasondel resultadoDescribeTrainingJob. En el caso de los trabajos que se realicen correctamente, no hay motivo para escribir este archivo porque se omite.
Crear el script para la ejecución del contenedor
Cree un script de train shell que SageMaker se ejecute cuando ejecute la imagen del contenedor de Docker. Cuando finalice el entrenamiento y los artefactos del modelo estén escritos en sus directorios respectivos, salga del script.
./train
#!/bin/bash # Run your training program here # # # #
Creación del Dockerfile
Cree un Dockerfile en su contexto de compilación. En este ejemplo se usa Ubuntu 18.04 como imagen base, pero puede empezar desde cualquier imagen base que funcione para su framework.
./Dockerfile
FROM ubuntu:18.04 # Add training dependencies and programs # # # # # # Add a script that SageMaker will run # Set run permissions # Prepend program directory to $PATH COPY /train /opt/program/train RUN chmod 755 /opt/program/train ENV PATH=/opt/program:${PATH}
El Dockerfile añade el script train creado anteriormente a la imagen. El directorio del script se agrega al para PATH que pueda ejecutarse cuando se ejecute el contenedor.
En el ejemplo anterior, no existe una lógica de entrenamiento real. Para su imagen de entrenamiento real, añada las dependencias de entrenamiento al Dockerfile y añada la lógica para leer las entradas de entrenamiento para entrenar y generar los artefactos del modelo.
La imagen de entrenamiento debe contener todas las dependencias necesarias, ya que no tendrá acceso a Internet.
Para obtener más información, consulte Utilice sus propios algoritmos y modelos con los AWS MarketplaceAWS Marketplace SageMaker ejemplos
Paso 2: Crear y probar la imagen localmente
En el contexto de la compilación, ahora existen los siguientes archivos:
-
./Dockerfile -
./train -
Su lógica y dependencias de entrenamiento
A continuación, puede crear, ejecutar y probar esta imagen de contenedor.
Compilar la imagen
Ejecute el comando Docker en el contexto de compilación para crear y etiquetar la imagen. En este ejemplo se utiliza la etiqueta my-training-image.
sudo docker build --tag my-training-image ./
Tras ejecutar este comando de Docker para crear la imagen, debería ver el resultado a medida que Docker cree la imagen en función de cada línea de su Dockerfile. Cuando termine, debería ver algo similar a lo siguiente.
Successfully built abcdef123456
Successfully tagged my-training-image:latestEjecutar localmente
Una vez finalizado, pruebe la imagen de forma local, como se muestra en el siguiente ejemplo.
sudo docker run \ --rm \ --volume '<path_to_input>:/opt/ml/input:ro' \ --volume '<path_to_model>:/opt/ml/model' \ --volume '<path_to_output>:/opt/ml/output' \ --name my-training-container \ my-training-image \ train
A continuación se muestran los detalles del comando:
-
--rm: eliminar automáticamente el contenedor una vez que se detenga. -
--volume '<path_to_input>:/opt/ml/input:ro': hacer que el directorio de entrada de prueba esté disponible para el contenedor como de solo lectura. -
--volume '<path_to_model>:/opt/ml/model': monta de forma vinculada la ruta en la que se almacenan los artefactos del modelo en la máquina host una vez finalizada la prueba de entrenamiento. -
--volume '<path_to_output>:/opt/ml/output': monta de forma vinculada la ruta en la que se escribe el motivo del error en un archivofailureen la máquina host. -
--name my-training-container: asigna un nombre a este contenedor en ejecución. -
my-training-image: ejecuta la imagen creada. -
train— Ejecute el mismo script SageMaker al ejecutar el contenedor.
Tras ejecutar este comando, Docker crea un contenedor a partir de la imagen de entrenamiento creada y lo ejecuta. El contenedor ejecuta el script train, que inicia el programa de entrenamiento.
Cuando el programa de entrenamiento finalice y el contenedor salga, comprueba que los artefactos del modelo de salida sean correctos. Además, comprueba los resultados del registro para confirmar que no están produciendo registros no deseados y, al mismo tiempo, asegurarse de que se proporcione suficiente información sobre el trabajo de entrenamiento.
Esto completa el empaquetado del código de entrenamiento para un producto algorítmico. Como un producto de algoritmo también incluye una imagen de inferencia, continúe con la siguiente sección, Crear una imagen de inferencia para algoritmos.
Crear una imagen de inferencia para algoritmos
En esta sección se proporciona un tutorial para empaquetar el código de inferencia en una imagen de inferencia para el producto de su algoritmo.
La imagen de inferencia es una imagen de Docker que contiene la lógica de inferencia. En tiempo de ejecución, el contenedor expone HTTP los puntos finales SageMaker para permitir el paso de datos hacia y desde el contenedor.
Tanto las imágenes de entrenamiento como las de inferencia son obligatorias para publicar un producto de algoritmo. Si aún no lo ha hecho, consulte la sección anterior sobre Crear una imagen de entrenamiento para algoritmos. Las dos imágenes se pueden combinar en una sola imagen o permanecer como imágenes separadas. Usted decide si desea combinar las imágenes o separarlas. Por lo general, la inferencia es más sencilla que el entrenamiento, y es posible que desee separar las imágenes para mejorar el rendimiento de la inferencia.
nota
El siguiente es solo un ejemplo de código de empaquetado para una imagen de inferencia. Para obtener más información, consulte Utilice sus propios algoritmos y modelos con los AWS MarketplaceAWS Marketplace SageMaker ejemplos
En el siguiente ejemplo se utiliza un servicio web, Flask
Paso 1: Creación de la imagen de inferencia
Para que la imagen de inferencia sea compatible SageMaker, la imagen de Docker debe exponer HTTP los puntos finales. Mientras el contenedor está en funcionamiento, SageMaker transfiere los datos de inferencia proporcionados por el comprador al punto final del contenedor. HTTP El resultado de la inferencia se devuelve en el cuerpo de la HTTP respuesta.
A continuación, se utiliza Docker CLI instalado en un entorno de desarrollo en una distribución Ubuntu de Linux.
Crear el script del servidor web
Este ejemplo usa un servidor de Python llamado Flask
nota
Aquí se usa Flask
Cree el script del servidor web Flask que sirva a los dos HTTP puntos finales del TCP puerto 8080 que utiliza. SageMaker Los dos puntos de conexión esperados son los siguientes:
-
/ping— SageMaker realiza HTTP GET solicitudes a este punto final para comprobar si su contenedor está listo. Cuando el contenedor esté listo, responderá a HTTP GET las solicitudes de este punto final con un código de respuesta de HTTP 200. -
/invocations— envía SageMaker HTTP POST solicitudes a este punto final para realizar inferencias. Los datos de entrada para la inferencia se envían en el cuerpo de la solicitud. El tipo de contenido especificado por el usuario se incluye en el HTTP encabezado. El cuerpo de la respuesta es el resultado de la inferencia.
./web_app_serve.py
# Import modules import json import re from flask import Flask from flask import request app = Flask(__name__) # Create a path for health checks @app.route("/ping") def endpoint_ping(): return "" # Create a path for inference @app.route("/invocations", methods=["POST"]) def endpoint_invocations(): # Read the input input_str = request.get_data().decode("utf8") # Add your inference code here. # # # # # # Add your inference code here. # Return a response with a prediction response = {"prediction":"a","text":input_str} return json.dumps(response)
En el ejemplo anterior, no existe una lógica de inferencia real. Para la imagen de inferencia real, añada la lógica de inferencia a la aplicación web para que procese la entrada y devuelva la predicción.
La imagen de inferencia debe contener todas las dependencias necesarias, ya que no tendrá acceso a Internet.
Crear el script para la ejecución del contenedor
Cree un script con el nombre serve que SageMaker se ejecute cuando ejecute la imagen del contenedor de Docker. En este script, inicie el servidor HTTP web.
./serve
#!/bin/bash # Run flask server on port 8080 for SageMaker flask run --host 0.0.0.0 --port 8080
Creación del Dockerfile
Cree un Dockerfile en su contexto de compilación. En este ejemplo se usa Ubuntu 18.04, pero puede empezar desde cualquier imagen base que funcione para su framework.
./Dockerfile
FROM ubuntu:18.04 # Specify encoding ENV LC_ALL=C.UTF-8 ENV LANG=C.UTF-8 # Install python-pip RUN apt-get update \ && apt-get install -y python3.6 python3-pip \ && ln -s /usr/bin/python3.6 /usr/bin/python \ && ln -s /usr/bin/pip3 /usr/bin/pip; # Install flask server RUN pip install -U Flask; # Add a web server script to the image # Set an environment to tell flask the script to run COPY /web_app_serve.py /web_app_serve.py ENV FLASK_APP=/web_app_serve.py # Add a script that Amazon SageMaker will run # Set run permissions # Prepend program directory to $PATH COPY /serve /opt/program/serve RUN chmod 755 /opt/program/serve ENV PATH=/opt/program:${PATH}
El Dockerfile añade los dos scripts creados anteriormente a la imagen. El directorio del serve script se agrega al para PATH que pueda ejecutarse cuando se ejecute el contenedor.
Preparar el programa para cargar dinámicamente los artefactos del modelo
En el caso de los productos algorítmicos, el comprador utiliza sus propios conjuntos de datos con la imagen de entrenamiento para generar artefactos de modelo únicos. Cuando se complete el proceso de entrenamiento, el contenedor de entrenamiento envía los artefactos del modelo al directorio del contenedor
/opt/ml/model/. SageMaker comprime el contenido de ese directorio en un archivo.tar.gz y lo almacena en Amazon S3 del comprador. Cuenta de AWS
Cuando el modelo se despliega, SageMaker ejecuta la imagen de inferencia, extrae los artefactos del modelo del archivo .tar.gz almacenado en la cuenta del comprador en Amazon S3 y los carga en el contenedor de inferencia del directorio. /opt/ml/model/ En tiempo de ejecución, el código del contenedor de inferencias utiliza los datos del modelo.
nota
Para proteger cualquier propiedad intelectual que pueda contener los archivos del artefacto, puede elegir cifrarlos antes de publicarlos. Para obtener más información, consulte Seguridad y propiedad intelectual con Amazon SageMaker.
Paso 2: Crear y probar la imagen localmente
En el contexto de la compilación, ahora existen los siguientes archivos:
-
./Dockerfile -
./web_app_serve.py -
./serve
A continuación, puede crear, ejecutar y probar esta imagen de contenedor.
Compilar la imagen
Ejecuta el comando de Docker para compilar y etiquetar la imagen. En este ejemplo se utiliza la etiqueta my-inference-image.
sudo docker build --tag my-inference-image ./
Tras ejecutar este comando de Docker para crear la imagen, debería ver el resultado a medida que Docker cree la imagen en función de cada línea de su Dockerfile. Cuando termine, debería ver algo similar a lo siguiente.
Successfully built abcdef123456
Successfully tagged my-inference-image:latestEjecutar localmente
Una vez completada la compilación, puede probar la imagen localmente.
sudo docker run \ --rm \ --publish 8080:8080/tcp \ --volume '<path_to_model>:/opt/ml/model:ro' \ --detach \ --name my-inference-container \ my-inference-image \ serve
A continuación se muestran los detalles del comando:
-
--rm: eliminar automáticamente el contenedor una vez que se detenga. -
--publish 8080:8080/tcp— Exponga el puerto 8080 para simular el puerto al que se envían las solicitudes. SageMaker HTTP -
--volume '<path_to_model>:/opt/ml/model:ro': monta de forma vinculada la ruta donde se almacenan los artefactos del modelo de prueba en la máquina host como de solo lectura para que estén disponibles en el código de inferencia en el contenedor. -
--detach: ejecuta el contenedor en segundo plano. -
--name my-inference-container: asigna un nombre a este contenedor en ejecución. -
my-inference-image: ejecuta la imagen creada. -
serve— Ejecute el mismo script que SageMaker se ejecuta cuando se ejecuta el contenedor.
Tras ejecutar este comando, Docker crea un contenedor a partir de la imagen de inferencia y lo ejecuta en segundo plano. El contenedor ejecuta el script serve, que inicia el servidor web con fines de prueba.
Pruebe el HTTP punto final del ping
Cuando SageMaker ejecuta el contenedor, hace ping periódicamente al punto final. Cuando el punto final devuelve una HTTP respuesta con el código de estado 200, indica SageMaker que el contenedor está listo para la inferencia.
Ejecute el siguiente comando para probar el punto de conexión e incluir el encabezado de respuesta.
curl --include http://127.0.0.1:8080/ping
Por ejemplo, en el ejemplo siguiente se muestra el resultado.
HTTP/1.0 200 OK
Content-Type: text/html; charset=utf-8
Content-Length: 0
Server: MyServer/0.16.0 Python/3.6.8
Date: Mon, 21 Oct 2019 06:58:54 GMTPruebe el punto final de la inferencia HTTP
Cuando el contenedor indica que está listo devolviendo un código de estado 200, SageMaker pasa los datos de inferencia al /invocations HTTP punto final mediante una POST solicitud.
Ejecute el siguiente comando para probar el punto de conexión de inferencia.
curl \ --request POST \ --data "hello world" \ http://127.0.0.1:8080/invocations
Por ejemplo, en el ejemplo siguiente se muestra el resultado.
{"prediction": "a", "text": "hello world"}Con estos dos HTTP puntos finales en funcionamiento, la imagen de inferencia ahora es compatible con ellos. SageMaker
nota
El modelo de su producto de algoritmo se puede implementar de dos maneras: en tiempo real y por lotes. Para ambas implementaciones, SageMaker utiliza los mismos HTTP puntos de conexión al ejecutar el contenedor de Docker.
Para detener el contenedor, ejecute el siguiente comando.
sudo docker container stop my-inference-container
Una vez que las imágenes de entrenamiento e inferencia del producto de algoritmo estén listas y probadas, continúe con Carga de tus imágenes a Amazon Elastic Container Registry.
