Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Descripción de los conectores
Un conector integra sistemas externos y servicios de Amazon con Apache Kafka copiando continuamente los datos de streaming de un origen de datos a su clúster de Apache Kafka o copiando continuamente los datos de su clúster a un receptor de datos. Un conector también puede realizar una lógica ligera, como la transformación, la conversión de formato o el filtrado de datos antes de entregarlos a un destino. Los conectores de origen extraen datos de un origen de datos y los envían al clúster, mientras que los conectores de destino extraen datos del clúster y los envían a un receptor de datos.
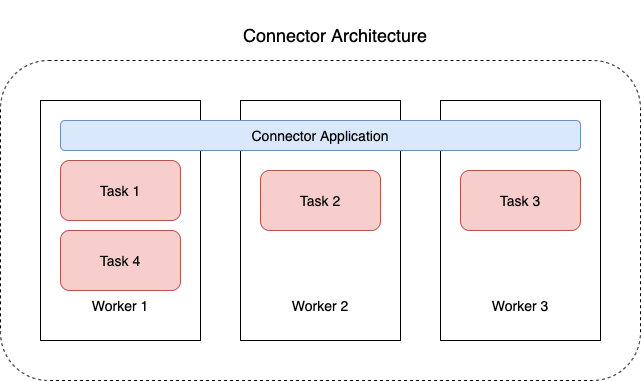
En el siguiente diagrama, se ilustra la arquitectura de un conector. Un proceso de trabajo es un proceso de máquina virtual Java (JVM) que ejecuta la lógica del conector. Cada proceso de trabajo crea un conjunto de tareas que se ejecutan en subprocesos paralelos y realizan el trabajo de copiar los datos. Las tareas no almacenan el estado y, por lo tanto, se pueden iniciar, detener o reiniciar en cualquier momento para proporcionar una canalización de datos flexible y escalable.