Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Introducción a Amazon Neptune
Amazon Neptune es un servicio de base de datos de gráficos totalmente administrado que se escala para gestionar miles de millones de relaciones y le permite consultarlas con una latencia de milisegundos, a un bajo costo para ese tipo de capacidad.
Si quiere obtener información más detallada sobre Neptune, consulte Información general de las características de Amazon Neptune.
Si ya conoce los gráficos, vaya a Inicio rápido a usar CloudShell oUso de Neptune con cuadernos de gráficos. O bien, si desea crear una base de datos de Neptune de inmediato, consulte Creación de un clúster de Amazon Neptune mediante AWS CloudFormation.
De lo contrario, es posible que desee saber un poco más sobre las bases de datos de gráficos antes de empezar.
Conceptos clave de la base de datos de gráficos
Las bases de datos de gráficos están optimizadas para almacenar y consultar las relaciones entre los elementos de datos.
Almacenan los propios elementos de datos como vértices del gráfico y las relaciones entre ellos como bordes. Cada borde tiene un tipo y se dirige de un vértice (el inicio) a otro (el final). Las relaciones pueden denominarse predicados, así como bordes, y, en ocasiones, los vértices también se denominan nodos. En los denominados gráficos de propiedades, tanto los vértices como los bordes también pueden tener propiedades adicionales asociadas.
A continuación, se muestra un pequeño gráfico que representa amigos y aficiones en una red social:
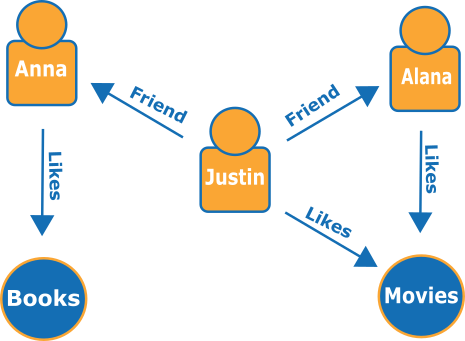
Los bordes se muestran con flechas con nombres y los vértices representan personas y aficiones específicas que conectan.
En un recorrido simple de este gráfico se puede saber qué les gusta a los amigos de Justin.
¿Por qué usar una base de datos de gráficos?
Cuando las conexiones o relaciones entre entidades forman parte fundamental de los datos que intenta modelar, una base de datos de gráficos es la elección más obvia.
Por un lado, es fácil modelar las interconexiones de datos como un gráfico y, después, escribir consultas complejas que extraigan información del mundo real del gráfico.
Para crear una aplicación equivalente mediante una base de datos relacional, es necesario crear muchas tablas con varias claves externas y, a continuación, escribir consultas SQL anidadas y combinaciones complejas. Este enfoque no solo se vuelve difícil de gestionar desde el punto de vista de la codificación, sino que su rendimiento se degrada rápidamente a medida que aumenta la cantidad de datos.
Por el contrario, una base de datos de gráficos como Neptune puede consultar relaciones entre miles de millones de vértices sin bloquearse.
¿Qué se puede hacer con una base de datos de gráficos?
Los gráficos pueden representar las interrelaciones de las entidades del mundo real de muchas maneras, en términos de acciones, propiedad, parentesco, opciones de compra, conexiones personales, vínculos familiares, etc.
A continuación, se muestran algunas de las áreas más comunes en las que se utilizan las bases de datos de gráficos:
-
Gráficos de conocimiento: los gráficos de conocimiento le permiten organizar y consultar todo tipo de información conectada para responder a preguntas generales. Con un gráfico de conocimiento, puede añadir información sobre un tema a los catálogos de productos y modelar información diversa, como la que se encuentra en Wikidata
. Para obtener más información sobre cómo funcionan los gráficos de conocimiento y dónde se utilizan, consulte Gráficos de conocimiento en AWS
. -
Gráficos de identidad: en una base de datos de gráficos, puede almacenar las relaciones entre categorías de información, como los intereses de los clientes, los amigos y el historial de compras, y luego consultar esos datos para hacer recomendaciones personalizadas y relevantes.
Por ejemplo, puede utilizar una base de datos de gráficos para recomendar productos a un usuario a partir de los productos que han comprado otros usuarios que siguen el mismo deporte o que presentan un historial de compras similar. También puede identificar a las personas que tienen un amigo en común, pero que todavía no se conocen, y enviarles una recomendación de amistad.
Los gráficos de este tipo se conocen como gráficos de identidad y se utilizan habitualmente para personalizar las interacciones con los usuarios. Para obtener más información, consulte Gráficos de identidad en AWS
. Para crear su propio gráfico de identidad, puede empezar con el ejemplo Gráfico de identidad mediante Amazon Neptune . -
Gráficos de fraude: se utilizan habitualmente en las bases de datos de gráficos. Pueden ayudarle a realizar un seguimiento de las compras con tarjeta de crédito y los lugares de compra para detectar usos poco habituales o detectar que un comprador está intentando utilizar la misma dirección de correo electrónico y la misma tarjeta de crédito que las utilizadas en un caso de fraude conocido. Le permiten comprobar si hay varias personas asociadas a una dirección de correo electrónico personal o si hay varias personas en diferentes ubicaciones físicas que comparten la misma dirección IP.
Tenga en cuenta el siguiente gráfico. Muestra la relación de tres personas y la información relacionada con su identidad. Cada persona tiene una dirección, una cuenta bancaria y un número de la seguridad social. Sin embargo, vemos que Matt y Justin comparten el mismo número de la seguridad social, lo cual no es normal e indica un posible fraude por parte de uno de ellos. Una consulta a un gráfico de fraude puede revelar conexiones de este tipo que pueden revisarse.
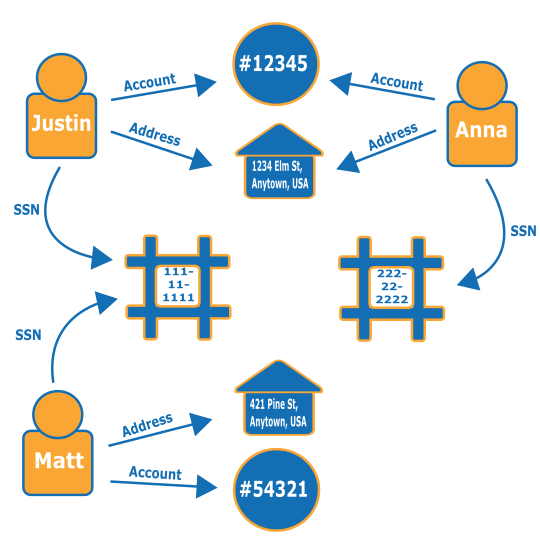
Para obtener más información sobre cómo los gráficos de fraude y dónde se utilizan, consulte Gráficos de fraude en AWS
. -
Redes sociales: una de las primeras y más comunes áreas en las que se utilizan las bases de datos de gráficos es en las aplicaciones de redes sociales.
Por ejemplo, supongamos que desea crear una fuente social en un sitio web. Puede utilizar fácilmente una base de datos de gráficos en el backend para ofrecer a los usuarios resultados que reflejen las últimas actualizaciones de sus familiares, sus amigos, las personas cuyas actualizaciones les “gustan” y las personas que viven cerca de ellos.
Indicaciones: un gráfico puede ayudar a encontrar la mejor ruta desde un punto de partida hasta un destino, teniendo en cuenta el tráfico actual y los patrones de tráfico habituales.
Logística: los gráficos pueden ayudar a identificar la forma más eficaz de utilizar los recursos de envío y distribución disponibles para cumplir con los requisitos de los clientes.
Diagnósticos: los gráficos pueden representar árboles de diagnóstico complejos que se pueden consultar para identificar el origen de los problemas y errores observados.
Investigación científica: con una base de datos de gráficos, puede crear aplicaciones que almacenen y naveguen por datos científicos e incluso información médica confidencial mediante el cifrado en reposo. Por ejemplo, puede almacenar modelos de interacciones de enfermedades y genes. Puede buscar patrones de gráficos dentro de las cadenas de proteínas para encontrar otros genes que podrían estar relacionados con una enfermedad. Puede modelar compuestos químicos como un gráfico y consultar patrones en las estructuras moleculares. Puede correlacionar los datos de los pacientes con los registros médicos en diferentes sistemas. Puede organizar las publicaciones de investigación por temas para encontrar información pertinente con rapidez.
Reglas normativas. puede almacenar requisitos normativos complejos en forma de gráficos y consultarlos para detectar situaciones en las que podrían aplicarse a sus operaciones empresariales diarias.
-
Topología y eventos de la red: una base de datos de gráficos puede ayudarlo a administrar y proteger una red de TI. Al almacenar la topología de la red como un gráfico, también puede almacenar y procesar muchos tipos diferentes de eventos en la red. Puede responder a preguntas como cuántos hosts ejecutan una aplicación determinada. Puede buscar patrones que puedan indicar que un determinado host se ha visto afectado por un programa malintencionado y consultar datos de conexión que puedan ayudar a realizar un seguimiento del programa hasta el host original que lo descargó.
¿Cómo se consulta un gráfico?
Neptune admite tres lenguajes de consulta especiales diseñados para consultar datos de gráficos de diferentes tipos. Puede usar estos lenguajes para añadir, modificar, eliminar y consultar datos en una base de datos de gráficos de Neptune:
-
Gremlin es un lenguaje de recorrido de gráficos para gráficos de propiedades. En Gremlin, una consulta es un recorrido compuesto por pasos discretos, cada uno de los cuales sigue un borde hasta un nodo. Consulte la documentación de Gremlin en Apache TinkerPop
para obtener más información. La implementación de Gremlin en Neptune tiene algunas diferencias con respecto a otras implementaciones, especialmente cuando se utiliza Gremlin-Groovy (las consultas de Gremlin se envían como texto serializado). Para obtener más información, consulte Conformidad con los estándares de Gremlin en Amazon Neptune.
-
openCypher: openCypher es un lenguaje de consulta declarativo para gráficos de propiedades que desarrolló originalmente Neo4j, luego de código abierto en 2015, y que contribuyó al proyecto openCypher
en virtud de una licencia de código abierto Apache 2. Consulte la Referencia del lenguaje de consultas de Cypher (versión 9) para la especificación del lenguaje, así como la Guía de estilo de Cypher para obtener información adicional. -
SPARQL es un lenguaje de consulta declarativo para datos RDF
, que se basa en la coincidencia de patrones gráficos que se ajusta al estándar World Wide Web Consortium (W3C) y se describe en SPARQL 1.1 Overview y en la especificación de SPARQL 1.1 Query Language . Consulte Conformidad con los estándares de SPARQL en Amazon Neptune para obtener información específica sobre la implementación de SPARQL en Neptune.
Ejemplos de consultas coincidentes de Gremlin y SPARQL
En el siguiente gráfico de personas (nodos) y sus relaciones (bordes), puede encontrar quiénes son los “amigos de amigos” de una persona determinada, por ejemplo, los amigos de los amigos de Howard.
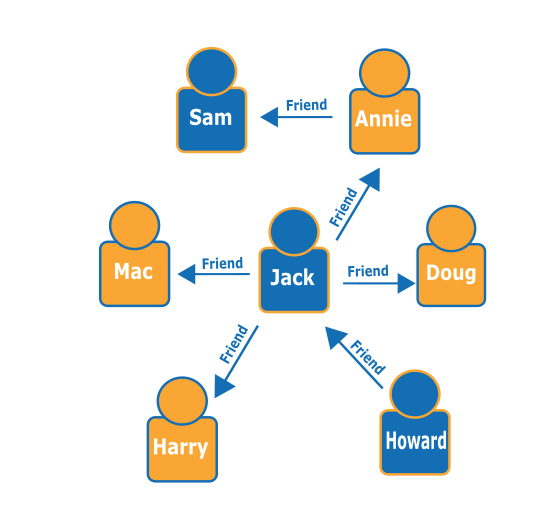
Al examinar el gráfico, puede ver que Howard tiene un amigo, Jack, que a su vez tiene cuatro amigos: Annie, Harry, Doug y Mac. Este es un ejemplo sencillo con un gráfico simple, pero la complejidad y el tamaño del conjunto de datos y de los resultados de estos tipos de consultas pueden aumentar considerablemente.
A continuación, se muestra una consulta de recorrido Gremlin que devuelve los nombres de los amigos de los amigos de Howard:
g.V().has('name', 'Howard').out('friend').out('friend').values('name')
A continuación, se muestra una consulta de SPARQL que devuelve los nombres de los amigos de amigos de Howard:
prefix : <#> select ?names where { ?howard :name "Howard" . ?howard :friend/:friend/:name ?names . }
nota
Cada una de las partes de un triple del marco de descripción de recursos (RDF) tiene un URI asociado. En el ejemplo anterior, el prefijo del URI es corto a propósito.
Realice un curso en línea sobre el uso de Amazon Neptune
Si te gusta aprender con vídeos, AWS ofrece cursos online en las AWS Online Tech Talks para ayudarte a ponerte manos a la obra
Introducción, análisis detallado y demostración de bases de datos de gráficos con Amazon Neptune
Profundizar más en la arquitectura de referencia de gráficos
Al pensar en los problemas que podría resolver una base de datos de gráficos y en cómo abordarlos, uno de los mejores puntos de partida es el proyecto de arquitecturas GitHub de referencia de gráficos de Neptune
Allí encontrará descripciones detalladas de los tipos de carga de trabajo de gráficos y tres secciones que le ayudarán a diseñar una base de datos de gráficos eficaz:
Modelos de datos y lenguajes de consulta
: en esta sección se explican las diferencias entre Gremlin y SPARQL y cómo elegir entre una de estas opciones. Modelado de datos gráficos
: se trata de una explicación más detallada sobre cómo tomar decisiones de modelado de datos gráficos, que incluye tutoriales detallados sobre el modelado de gráficos de propiedades con Gremlin y el modelado RDF con SPARQL. Conversión de otros modelos de datos en un modelo de gráfico
: aquí encontrará información sobre cómo traducir un modelo de datos relacional en un modelo de gráfico.
También hay tres secciones que explican los pasos específicos para usar Neptune:
Conexión a Amazon Neptune desde clientes ajenos a la VPC de Neptune
: en esta sección se muestran varias opciones para conectarse a Neptune desde fuera de la VPC en la que se encuentra el clúster de base de datos. Acceso a Amazon Neptune desde funciones de AWS Lambda
: aquí encontrará información sobre cómo conectarse de forma fiable a Neptune desde funciones de Lambda. Escribir en Amazon Neptune desde una transmisión de Amazon Kinesis Data Streams
: en esta sección puede obtener información sobre cómo gestionar escenarios de alto rendimiento de escritura con Neptune.
