Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Clonación de bases de datos en Neptune
Mediante la clonación de bases de datos, puede crear de una forma rápida y rentable clones de todas las bases de datos en Amazon Neptune. Las bases de datos clonadas requieren un espacio adicional mínimo cuando se crean inicialmente. La clonación de bases de datos utiliza un protocolo de copia en escritura. Los datos se copian en el momento en que cambian, tanto en las bases de datos de origen como en las clonadas. Puede crear varios clones partiendo del mismo clúster de base de datos. También puede crear clones adicionales desde otros clones. Para obtener más información acerca del funcionamiento del protocolo de copia en escritura en el contexto del almacenamiento de Neptune, consulte Protocolo de copia en escritura.
Puede usar la clonación de bases de datos en diversos casos de uso, especialmente cuando no desee que su entorno de producción se vea afectado, como por ejemplo en las siguientes situaciones:
Experimentar con el impacto de los cambios, como por ejemplo los cambios de esquema o los cambios de grupos de parámetros, y valorar dicho impacto.
Realizar operaciones intensivas, como exportar datos o ejecutar consultas analíticas.
Crear una copia de un clúster de base de datos de producción en un entorno que no sea de producción para el desarrollo o las pruebas.
Para crear un clon de un clúster de base de datos con la AWS Management Console
Inicie sesión en la consola de administración de AWS y abra la consola de Amazon Neptune en https://console.aws.amazon.com/neptune/home
. En el panel de navegación, seleccione Instances (Instancias). Elija la instancia principal del clúster de base de datos del que desea crear un clon.
Elija Instance actions (Acciones de instancias) y, a continuación, elija Create clone (Crear clon).
-
En la página Create Clone (Crear clon), escriba un nombre para la instancia principal del clúster de base de datos clonado como DB instance identifier (Identificador de instancias de bases de datos).
Si lo desea, configure los demás ajustes del clúster de base de datos clonado. Para obtener información acerca de los distintos ajustes de clúster de base de datos, consulte Lanzamiento mediante la consola.
Elija Create Clone (Crear clon) para lanzar el clúster de base de datos clonado.
Para crear un clon de un clúster de base de datos con la AWS CLI
-
Llame al comando de la AWS CLI restore-db-cluster-to-point-in-time de Neptune y proporcione los siguientes valores:
--source-db-cluster-identifier: el nombre del clúster de base de datos origen del que desea crear un clon.--db-cluster-identifier: el nombre del clúster de base de datos clonado.--restore-type copy-on-write: el valorcopy-on-writeindica que se debe crear un clúster de base de datos clonado.--use-latest-restorable-time: indica que se utiliza la hora de la última copia de seguridad restaurable.
nota
El comando restore-db-cluster-to-point-in-time de la AWS CLI solo clona el clúster de la base de datos, no las instancias de base de datos dicho clúster.
El ejemplo siguiente de Linux/UNIX crea un clon a partir del clúster de base de datos
source-db-cluster-idy le asigna un nombre al clondb-clone-cluster-id.aws neptune restore-db-cluster-to-point-in-time \ --region us-east-1 \ --source-db-cluster-identifier source-db-cluster-id \ --db-cluster-identifier db-clone-cluster-id \ --restore-type copy-on-write \ --use-latest-restorable-timeEl mismo ejemplo funciona en Windows si el carácter de escape del extremo de la línea
\se sustituye por el^equivalente de Windows:aws neptune restore-db-cluster-to-point-in-time ^ --region us-east-1 ^ --source-db-cluster-identifier source-db-cluster-id ^ --db-cluster-identifier db-clone-cluster-id ^ --restore-type copy-on-write ^ --use-latest-restorable-time
Limitaciones
La clonación de bases de datos en Neptune tiene las siguientes limitaciones:
No puede crear bases de datos clonadas entre regiones de AWS diferentes. Las bases de datos clonadas se deben crear en la misma región que las bases de datos de origen.
Una base de datos clonada siempre utiliza el parche más reciente de la versión del motor de Neptune que utiliza la base de datos a partir del que se ha clonado. Esto se aplica incluso si la base de datos de origen aún no se ha actualizado a esa versión de parche. Sin embargo, la versión del motor no cambia.
Por el momento, existe un límite de no más de 15 clones por copia del clúster de base de datos de Neptune, incluidos los clones basados en otros clones. Una vez alcanzado ese límite, debe hacer otra copia de la base de datos en lugar de clonarla. No obstante, si ace una copia nueva, puede tener también hasta 15 clones.
La clonación de bases de datos entre varias cuentas no se admite actualmente.
Puede proporcionar una Virtual Private Cloud (VPC) diferente para su clon. Sin embargo, las subredes de esas VPC deben estar asignadas al mismo conjunto de zonas de disponibilidad.
Protocolo de copia en escritura para la clonación de bases de datos
Las siguientes situaciones ilustran el funcionamiento del protocolo de copia en escritura.
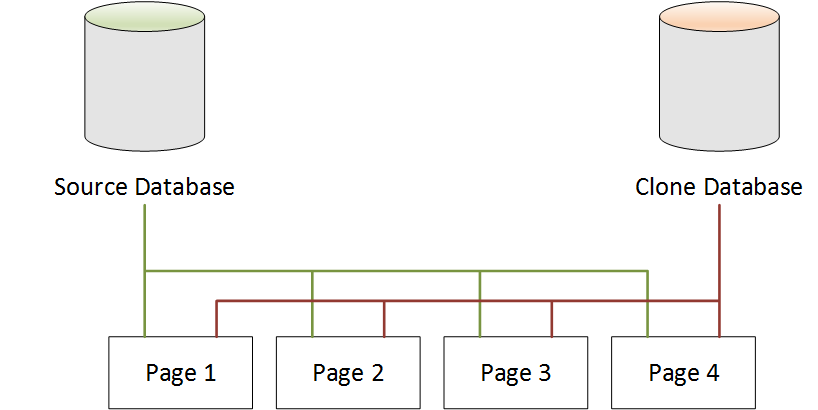
Base de datos de Neptune antes de la clonación
En una base de datos de origen, los datos se almacenan en páginas. En el diagrama siguiente, la base de datos de origen tiene cuatro páginas.

Base de datos de Neptune después de la clonación
Como se muestra en el diagrama siguiente, no se producen cambios en la base de datos de origen después de la clonación. Tanto la base de datos de origen como la base de datos clonada apuntan a las mismas cuatro páginas. Ninguna página se ha copiado físicamente, por lo que no se necesita almacenamiento adicional.
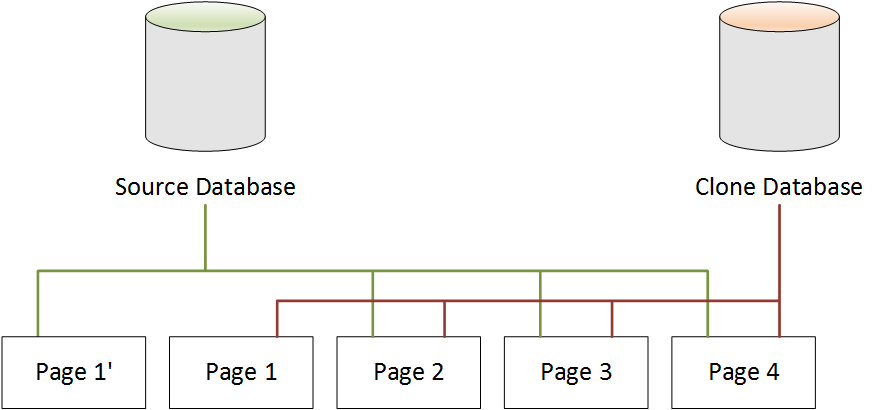
Cuando se efectúa un cambio en la base de datos de origen
En el siguiente ejemplo, la base de datos de origen realiza un cambio en los datos de la Page
1. En lugar de escribir en la Page 1 original, usa almacenamiento adicional para crear una nueva página denominada Page 1'. Ahora, la base de datos de origen apunta a la nueva Page 1' y también a la Page 2, la Page 3 y la Page 4. La base de datos clonada sigue apuntando a la Page 1 a través de la Page 4.
Cuando se realiza un cambio en la base de datos clonada
En el siguiente diagrama, la base de datos clonada también ha cambiado, esta vez en la Page 4. En lugar de escribir en la Page 4 original, se usa almacenamiento adicional para crear una nueva página denominada Page 4'. La base de datos de origen sigue apuntando a la Page 1' y también a la Page 2 a través de la Page 4, pero ahora la base de datos clonada apunta a la Page 1 a través de la Page 3 y también de la Page 4'.
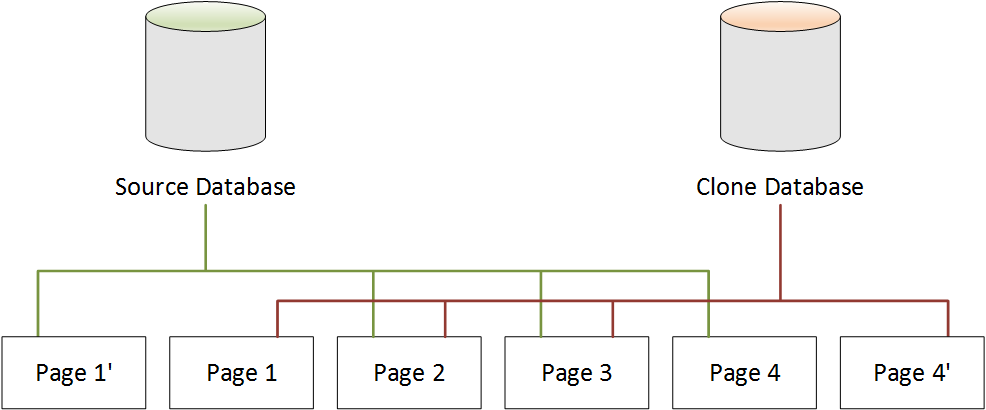
Como se muestra en la segunda situación, después de la clonación de la base de datos no se requiere almacenamiento adicional en el momento de la creación del clon. Sin embargo, a medida que se producen cambios en la base de datos de origen y en la base de datos clonada, solo se crean las páginas modificadas, como se muestra en las situaciones tercera y cuarta. A medida que se producen más cambios a lo largo del tiempo tanto en la base de datos de origen como en la base de datos clonada, irá necesitando más almacenamiento para capturar y almacenar los cambios.
Eliminación de una base de datos de origen
La eliminación de una base de datos de origen no afecta a las bases de datos clonadas asociadas a ella. Las bases de datos clonadas siguen apuntando a las páginas que antes pertenecían a la base de datos de origen.
