Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Ingerir datos en colecciones de Amazon OpenSearch Serverless
En estas secciones se proporcionan detalles sobre las canalizaciones de ingesta compatibles para la ingesta de datos en las colecciones de Amazon OpenSearch Serverless. También incluyen algunos de los clientes que puede utilizar para interactuar con las operaciones de la API. OpenSearch Sus clientes deben ser compatibles con la versión OpenSearch 2.x para poder integrarse con OpenSearch Serverless.
Temas
Permisos mínimos necesarios
[ { "Rules":[ { "ResourceType":"index", "Resource":[ "index/target-collection/logs" ], "Permission":[ "aoss:CreateIndex", "aoss:WriteDocument", "aoss:UpdateIndex" ] } ], "Principal":[ "arn:aws:iam::123456789012:user/my-user" ] } ]
Los permisos pueden ser más amplios si planea escribir en índices adicionales. Por ejemplo, en lugar de especificar un índice objetivo único, puede conceder permisos a todos los índices (index/ target-collection /*) o a un subconjunto de índices (index//). target-collection logs*
Para obtener una referencia de todas las operaciones de OpenSearch API disponibles y sus permisos asociados, consulte. Operaciones y complementos compatibles en Amazon OpenSearch Serverless
OpenSearch Ingestión
En lugar de utilizar un cliente de terceros para enviar datos directamente a una colección OpenSearch sin servidor, puede utilizar Amazon OpenSearch Ingestion. Usted configura sus generadores de datos para que envíen datos a OpenSearch Ingestion y esta entrega automáticamente los datos a la colección que usted especifique. También puede configurar OpenSearch Ingestion para transformar los datos antes de entregarlos. Para obtener más información, consulte Información general sobre Amazon OpenSearch Ingestion.
Una canalización de OpenSearch ingestión necesita permiso para escribir en una colección OpenSearch sin servidor que esté configurada como sumidero. Estos permisos incluyen la capacidad de describir la colección y enviarle solicitudes HTTP. Para obtener instrucciones sobre cómo usar OpenSearch Ingestión para añadir datos a una colección, consulte. Otorgar a Amazon OpenSearch Ingestion pipelines acceso a las colecciones
Para empezar a usar OpenSearch Ingestion, consulte. Tutorial: Ingerir datos en una colección mediante Amazon OpenSearch Ingestion
Fluent Bit
Puede utilizar la imagen AWS
de Fluent Bit
nota
Debe tener la versión 2.30.0 o posterior de la imagen de Fluent Bit AWS para poder integrarla con Serverless. OpenSearch
Ejemplo de configuración:
Este ejemplo de sección de resultados del archivo de configuración muestra cómo utilizar una colección OpenSearch Serverless como destino. La adición importante es el parámetro AWS_Service_Name, que es aoss. Host es el punto de conexión de la colección.
[OUTPUT] Name opensearch Match * Hostcollection-endpoint.us-west-2.aoss.amazonaws.com Port 443 Indexmy_indexTrace_Error On Trace_Output On AWS_Auth On AWS_Region<region>AWS_Service_Name aoss tls On Suppress_Type_Name On
Amazon Data Firehose
Firehose admite OpenSearch Serverless como destino de entrega. Para obtener instrucciones sobre cómo enviar datos a OpenSearch Serverless, consulte Crear una transmisión de entrega de Kinesis Data Firehose y OpenSearch elegir Serverless para su destino en la Guía para desarrolladores de Amazon Data Firehose.
El rol de IAM que proporcione a Firehose para la entrega se debe especificar dentro de una política de acceso a datos con el permiso mínimo aoss:WriteDocument para la colección de destino y debe tener un índice preexistente al que enviar datos. Para obtener más información, consulte Permisos mínimos necesarios.
Antes de enviar datos a OpenSearch Serverless, es posible que deba realizar transformaciones en los datos. Para obtener más información acerca de cómo utilizar las funciones de Lambda para realizar esta tarea, consulte Amazon Kinesis Data Firehose Data Transformation en la misma guía.
Go
El siguiente código de ejemplo utiliza el cliente opensearch-go para Goregion y host.
package main import ( "context" "log" "strings" "github.com/aws/aws-sdk-go-v2/aws" "github.com/aws/aws-sdk-go-v2/config" opensearch "github.com/opensearch-project/opensearch-go/v2" opensearchapi "github.com/opensearch-project/opensearch-go/v2/opensearchapi" requestsigner "github.com/opensearch-project/opensearch-go/v2/signer/awsv2" ) const endpoint = "" // serverless collection endpoint func main() { ctx := context.Background() awsCfg, err := config.LoadDefaultConfig(ctx, config.WithRegion("<AWS_REGION>"), config.WithCredentialsProvider( getCredentialProvider("<AWS_ACCESS_KEY>", "<AWS_SECRET_ACCESS_KEY>", "<AWS_SESSION_TOKEN>"), ), ) if err != nil { log.Fatal(err) // don't log.fatal in a production-ready app } // create an AWS request Signer and load AWS configuration using default config folder or env vars. signer, err := requestsigner.NewSignerWithService(awsCfg, "aoss") // "aoss" for Amazon OpenSearch Serverless if err != nil { log.Fatal(err) // don't log.fatal in a production-ready app } // create an opensearch client and use the request-signer client, err := opensearch.NewClient(opensearch.Config{ Addresses: []string{endpoint}, Signer: signer, }) if err != nil { log.Fatal("client creation err", err) } indexName := "go-test-index" // define index mapping mapping := strings.NewReader(`{ "settings": { "index": { "number_of_shards": 4 } } }`) // create an index createIndex := opensearchapi.IndicesCreateRequest{ Index: indexName, Body: mapping, } createIndexResponse, err := createIndex.Do(context.Background(), client) if err != nil { log.Println("Error ", err.Error()) log.Println("failed to create index ", err) log.Fatal("create response body read err", err) } log.Println(createIndexResponse) // delete the index deleteIndex := opensearchapi.IndicesDeleteRequest{ Index: []string{indexName}, } deleteIndexResponse, err := deleteIndex.Do(context.Background(), client) if err != nil { log.Println("failed to delete index ", err) log.Fatal("delete index response body read err", err) } log.Println("deleting index", deleteIndexResponse) } func getCredentialProvider(accessKey, secretAccessKey, token string) aws.CredentialsProviderFunc { return func(ctx context.Context) (aws.Credentials, error) { c := &aws.Credentials{ AccessKeyID: accessKey, SecretAccessKey: secretAccessKey, SessionToken: token, } return *c, nil } }
Java
En el siguiente código de ejemplo, se utiliza el cliente opensearch-java para Javaregion y host.
La diferencia importante en comparación con los dominios de OpenSearch servicio es el nombre del servicio (aossen lugar de). es
// import OpenSearchClient to establish connection to OpenSearch Serverless collection import org.opensearch.client.opensearch.OpenSearchClient; import software.amazon.awssdk.auth.credentials.AwsCredentialsProvider; import software.amazon.awssdk.auth.credentials.DefaultCredentialsProvider; // Configure credential provider AwsCredentialsProvider credentialsProvider = DefaultCredentialsProvider.create(); SdkHttpClient httpClient = ApacheHttpClient.builder().build(); // create an opensearch client and use the request-signer OpenSearchClient client = new OpenSearchClient( new AwsSdk2Transport( httpClient, "...us-west-2.aoss.amazonaws.com", // serverless collection endpoint "aoss" // signing service name Region.US_WEST_2, // signing service region AwsSdk2TransportOptions.builder().build() ) ); String index = "sample-index"; // create an index CreateIndexRequest createIndexRequest = new CreateIndexRequest.Builder().index(index).build(); CreateIndexResponse createIndexResponse = client.indices().create(createIndexRequest); System.out.println("Create index reponse: " + createIndexResponse); // delete the index DeleteIndexRequest deleteIndexRequest = new DeleteIndexRequest.Builder().index(index).build(); DeleteIndexResponse deleteIndexResponse = client.indices().delete(deleteIndexRequest); System.out.println("Delete index reponse: " + deleteIndexResponse); httpClient.close();
El siguiente código de ejemplo vuelve a establecer una conexión segura y, a continuación, busca en un índice.
import org.opensearch.client.opensearch.OpenSearchClient; SdkHttpClient httpClient = ApacheHttpClient.builder().build(); OpenSearchClient client = new OpenSearchClient( new AwsSdk2Transport( httpClient, "...us-west-2.aoss.amazonaws.com", // serverless collection endpoint "aoss" // signing service name Region.US_WEST_2, // signing service region AwsSdk2TransportOptions.builder().build() ) ); Response response = client.generic() .execute( Requests.builder() .endpoint("/" + "users" + "/_search?typed_keys=true") .method("GET") .json("{" + " \"query\": {" + " \"match_all\": {}" + " }" + "}") .build()); httpClient.close();
El siguiente código de ejemplo establece una conexión segura e indexa un documento en una colección.
import org.opensearch.client.opensearch.OpenSearchClient; import org.opensearch.client.opensearch.core.IndexRequest; import org.opensearch.client.opensearch.core.IndexResponse; import java.util.HashMap; import java.util.Map; SdkHttpClient httpClient = ApacheHttpClient.builder().build(); OpenSearchClient client = new OpenSearchClient( new AwsSdk2Transport( httpClient, "...us-west-2.aoss.amazonaws.com", // serverless collection endpoint "aoss" // signing service name Region.US_WEST_2, // signing service region AwsSdk2TransportOptions.builder().build() ) ); // index a document Map<String, Object> document = new HashMap<>(); document.put("title", "The Green Mile"); document.put("director", "Frank Darabont"); document.put("year", "1999"); IndexRequest<Map<String, Object>> indexRequest = IndexRequest.of(i -> i .index("books-index") .document(document) ); IndexResponse indexResponse = client.index(indexRequest); System.out.println("Index response: " + indexResponse.result()); httpClient.close();
JavaScript
El siguiente código de ejemplo utiliza el cliente opensearch-jsnode y region.
La diferencia importante en comparación con los dominios de OpenSearch servicio es el nombre del servicio (aossen lugar de). es
Logstash
Puede usar el OpenSearch complemento Logstash
Para usar Logstash para enviar datos a Serverless OpenSearch
-
Instale la versión 2.0.0 o posterior del complemento logstash-output-opensearch
con Docker o Linux. -
Para que el complemento de OpenSearch salida funcione con OpenSearch Serverless, debes realizar las siguientes modificaciones en la sección de salida de logstash.conf:
opensearch-
Especifique
aosscomo elservice_nameenauth_type. -
Especifique el punto de conexión de la colección para
hosts. -
Agregue los parámetros
default_server_major_versionylegacy_template. Estos parámetros son necesarios para que el complemento funcione con Serverless. OpenSearch
output { opensearch { hosts => "collection-endpoint:443" auth_type => { ... service_name => 'aoss' } default_server_major_version => 2 legacy_template => false } }Este ejemplo de archivo de configuración toma las entradas de los archivos de un bucket de S3 y las envía a una colección OpenSearch Serverless:
input { s3 { bucket => "my-s3-bucket" region => "us-east-1" } } output { opensearch { ecs_compatibility => disabled hosts => "https://my-collection-endpoint.us-east-1.aoss.amazonaws.com:443" index =>my-indexauth_type => { type => 'aws_iam' aws_access_key_id => 'your-access-key' aws_secret_access_key => 'your-secret-key' region => 'us-east-1' service_name => 'aoss' } default_server_major_version => 2 legacy_template => false } } -
-
A continuación, ejecute Logstash con la nueva configuración para probar el complemento:
bin/logstash -f config/test-plugin.conf
Python
El siguiente código de ejemplo usa el cliente opensearch-pyregion y host.
La diferencia importante en comparación con los dominios de OpenSearch servicio es el nombre del servicio (aossen lugar de). es
from opensearchpy import OpenSearch, RequestsHttpConnection, AWSV4SignerAuth import boto3 host = '' # serverless collection endpoint, without https:// region = '' # e.g. us-east-1 service = 'aoss' credentials = boto3.Session().get_credentials() auth = AWSV4SignerAuth(credentials, region, service) # create an opensearch client and use the request-signer client = OpenSearch( hosts=[{'host': host, 'port': 443}], http_auth=auth, use_ssl=True, verify_certs=True, connection_class=RequestsHttpConnection, pool_maxsize=20, ) # create an index index_name = 'books-index' create_response = client.indices.create( index_name ) print('\nCreating index:') print(create_response) # index a document document = { 'title': 'The Green Mile', 'director': 'Stephen King', 'year': '1996' } response = client.index( index = 'books-index', body = document, id = '1' ) delete_response = client.indices.delete( index_name ) print('\nDeleting index:') print(delete_response)
nota
El id = '1' parámetro de este ejemplo especifica un identificador de documento personalizado. Los identificadores de documentos personalizados solo se admiten en las colecciones de búsqueda. En el caso de las colecciones de búsquedas vectoriales y de series temporales, no se admite la indexación con un identificador de documento personalizado y devolverá un error. Omita el id parámetro al indexar en series temporales o colecciones de búsquedas vectoriales.
Ruby
La opensearch-aws-sigv4 gema proporciona acceso a OpenSearch Serverless, junto con OpenSearch Service, de forma inmediata. Dispone de todas las funciones del cliente opensearch-ruby
Cuando cree una instancia del firmante de Sigv4, especifique aoss como nombre del servicio:
require 'opensearch-aws-sigv4' require 'aws-sigv4' signer = Aws::Sigv4::Signer.new(service: 'aoss', region: 'us-west-2', access_key_id: 'key_id', secret_access_key: 'secret') # create an opensearch client and use the request-signer client = OpenSearch::Aws::Sigv4Client.new( { host: 'https://your.amz-opensearch-serverless.endpoint', log: true }, signer) # create an index index = 'prime' client.indices.create(index: index) # insert data client.index(index: index, id: '1', body: { name: 'Amazon Echo', msrp: '5999', year: 2011 }) # query the index client.search(body: { query: { match: { name: 'Echo' } } }) # delete index entry client.delete(index: index, id: '1') # delete the index client.indices.delete(index: index)
Firma de solicitudes HTTP con otros clientes
Los siguientes requisitos se aplican a la hora de firmar solicitudes en colecciones OpenSearch sin servidor cuando se crean solicitudes HTTP con otros clientes.
-
Debe especificar el nombre del servicio como
aoss. -
El encabezado
x-amz-content-sha256es obligatorio para todas las solicitudes de Signature Version 4 de AWS . Proporciona un hash de la carga de solicitud. Si hay una carga de solicitud, establezca el valor en su hash criptográfico del algoritmo de hash seguro (SHA) (SHA256). Si no hay ninguna carga de solicitud, establezca el valor ene3b0c44298fc1c149afbf4c8996fb92427ae41e4649b934ca495991b7852b855, que es el hash de una cadena vacía.
Indexación con cURL
La siguiente solicitud de ejemplo utiliza la biblioteca de solicitudes de URL de cliente (cURL) para enviar un único documento a un índice denominado movies-index dentro de una colección:
curl -XPOST \ --user "$AWS_ACCESS_KEY_ID":"$AWS_SECRET_ACCESS_KEY" \ --aws-sigv4 "aws:amz:us-east-1:aoss" \ --header "x-amz-content-sha256: $REQUEST_PAYLOAD_SHA_HASH" \ --header "x-amz-security-token: $AWS_SESSION_TOKEN" \ "https://my-collection-endpoint.us-east-1.aoss.amazonaws.com/movies-index/_doc" \ -H "Content-Type: application/json" -d '{"title": "Shawshank Redemption"}'
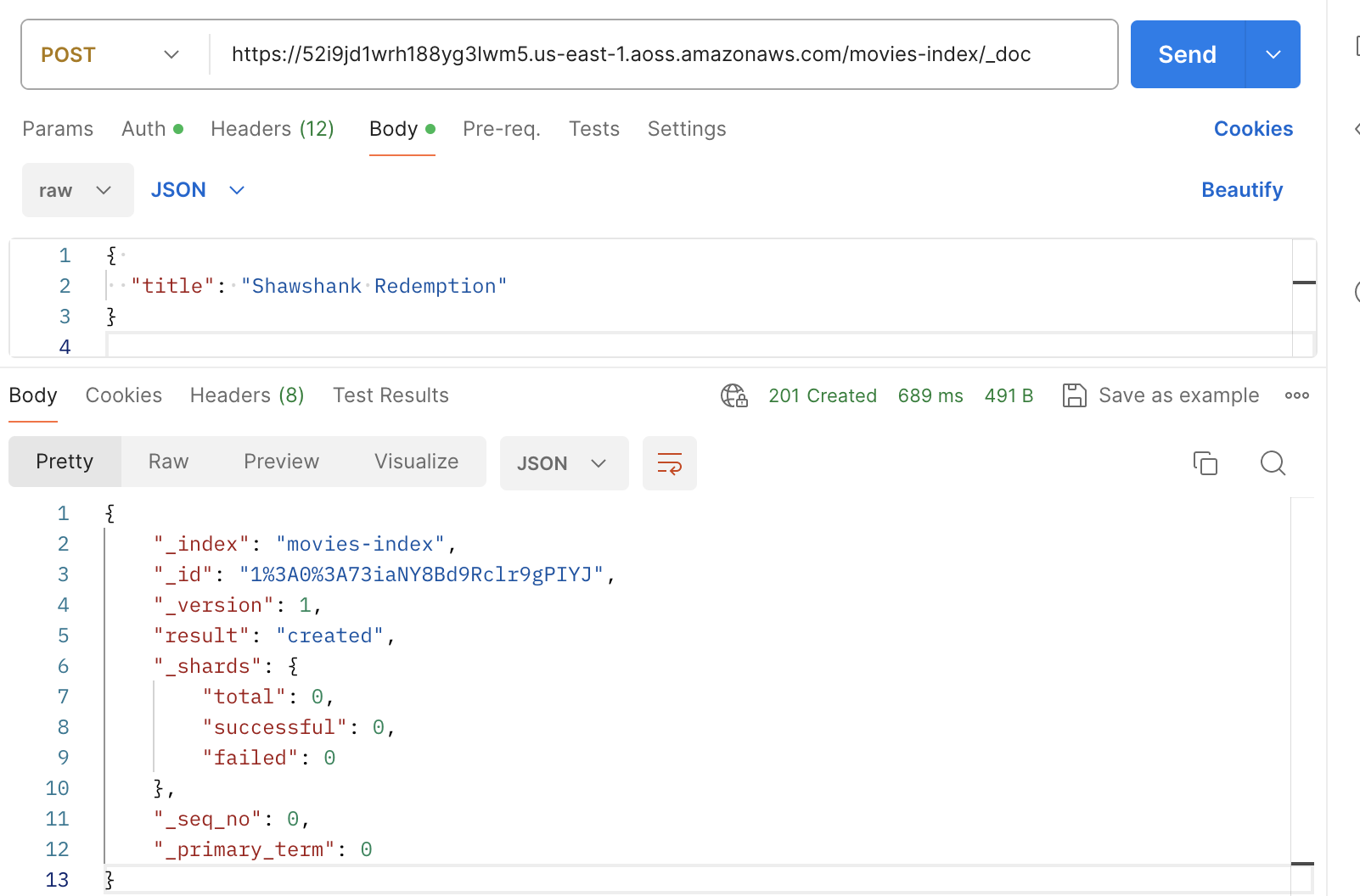
Indexación con Postman
La siguiente imagen muestra cómo enviar solicitudes a una colección con Postman. Para obtener instrucciones sobre la autenticación, consulte el flujo de trabajo de autenticación con AWS firma