Aviso de fin de soporte: el 31 de mayo de 2026, AWS finalizará el soporte para AWS Panorama. Después del 31 de mayo de 2026, ya no podrás acceder a la AWS Panorama consola ni a AWS Panorama los recursos. Para obtener más información, consulta AWS Panorama el fin del soporte.
Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Modelos de visión artificial
Un modelo de visión artificial es un programa de software que está entrenado para detectar objetos en imágenes. Un modelo aprende a reconocer un conjunto de objetos analizando primero las imágenes de esos objetos mediante el entrenamiento. Un modelo de visión artificial toma una imagen como entrada y genera información sobre los objetos que detecta, como el tipo de objeto y su ubicación. AWS Panorama admite modelos de visión artificial creados con PyTorch Apache MXNet y TensorFlow.
nota
Para ver una lista de los modelos prediseñados que se han probado con AWS Panorama, consulte Compatibilidad del modelo
Secciones
Uso de modelos en código
Un modelo devuelve uno o más resultados, que pueden incluir probabilidades de las clases detectadas, información de ubicación y otros datos. En el siguiente ejemplo, se muestra cómo realizar inferencias en una imagen a partir de una transmisión de vídeo y enviar la salida del modelo a una función de procesamiento.
ejemplo application.py
def process_media(self, stream): """Runs inference on a frame of video.""" image_data = preprocess(stream.image,self.MODEL_DIM) logger.debug('Image data: {}'.format(image_data)) # Run inference inference_start = time.time()inference_results = self.call({"data":image_data}, self.MODEL_NODE)# Log metrics inference_time = (time.time() - inference_start) * 1000 if inference_time > self.inference_time_max: self.inference_time_max = inference_time self.inference_time_ms += inference_time # Process results (classification)self.process_results(inference_results, stream)
El siguiente ejemplo muestra una función que procesa los resultados del modelo de clasificación básico. El modelo de muestra devuelve una matriz de probabilidades, que es el primer y único valor de la matriz de resultados.
ejemplo application.py
def process_results(self, inference_results, stream): """Processes output tensors from a computer vision model and annotates a video frame.""" if inference_results is None: logger.warning("Inference results are None.") return max_results = 5 logger.debug('Inference results: {}'.format(inference_results)) class_tuple = inference_results[0] enum_vals = [(i, val) for i, val in enumerate(class_tuple[0])] sorted_vals = sorted(enum_vals, key=lambda tup: tup[1]) top_k = sorted_vals[::-1][:max_results] indexes = [tup[0] for tup in top_k] for j in range(max_results): label = 'Class [%s], with probability %.3f.'% (self.classes[indexes[j]], class_tuple[0][indexes[j]]) stream.add_label(label, 0.1, 0.1 + 0.1*j)
El código de la aplicación busca los valores con las probabilidades más altas y los asigna a las etiquetas de un archivo de recursos que se carga durante la inicialización.
Creación de un modelo personalizado
Puede usar los modelos que haya creado PyTorch, en Apache MXNet y TensorFlow en las aplicaciones de AWS Panorama. Como alternativa a la creación y el entrenamiento de modelos en SageMaker IA, puedes usar un modelo entrenado o crear y entrenar tu propio modelo con un marco compatible y exportarlo a un entorno local o a Amazon EC2.
nota
Para obtener más información sobre las versiones de los marcos y los formatos de archivo compatibles con SageMaker AI Neo, consulte los marcos compatibles en la Guía para desarrolladores de Amazon SageMaker AI.
El repositorio de esta guía proporciona un ejemplo de aplicación que muestra este flujo de trabajo para un modelo de Keras en TensorFlow SavedModel formato. Utiliza TensorFlow 2 y se puede ejecutar localmente en un entorno virtual o en un contenedor Docker. La aplicación de muestra también incluye plantillas y scripts para crear el modelo en una EC2 instancia de Amazon.
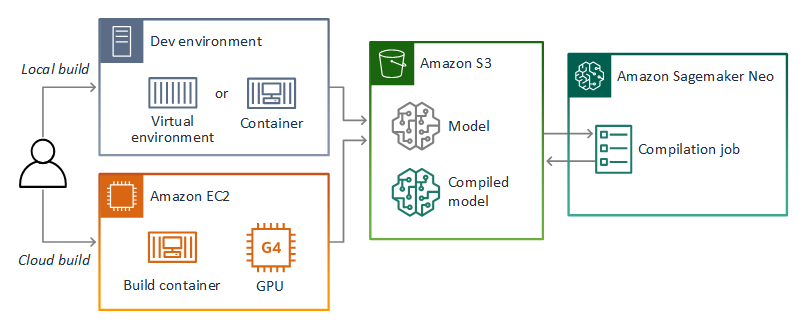
AWS Panorama usa SageMaker AI Neo para compilar modelos para usarlos en el dispositivo AWS Panorama. Para cada marco, utilice el formato compatible con SageMaker AI Neo y empaquete el modelo en un .tar.gz archivo.
Para obtener más información, consulte Compilar e implementar modelos con Neo en la Guía para desarrolladores de Amazon SageMaker AI.
Empaquetar un modelo
Un paquete de modelos consta de un descriptor, una configuración de paquete y un archivo de modelos. Al igual que en un paquete de imágenes de aplicaciones, la configuración del paquete indica al servicio AWS Panorama dónde se almacenan el modelo y el descriptor en Amazon S3.
ejemplo packages/123456789012-SQUEEZENET_PYTORCH-1.0/descriptor.json
{ "mlModelDescriptor": { "envelopeVersion": "2021-01-01", "framework": "PYTORCH", "frameworkVersion": "1.8", "precisionMode": "FP16", "inputs": [ { "name": "data", "shape": [ 1, 3, 224, 224 ] } ] } }
nota
Especifique únicamente la versión principal y secundaria de la versión del framework. Para obtener una lista de las versiones compatibles PyTorch MXNet, de Apache y de las TensorFlow versiones, consulte Marcos compatibles.
Para importar un modelo, utilice el comando import-raw-model CLI de la aplicación AWS Panorama. Si realiza algún cambio en el modelo o en su descriptor, debe volver a ejecutar este comando para actualizar los activos de la aplicación. Para obtener más información, consulte Cambiar el modelo de visión artificial.
Para ver el esquema JSON del archivo descriptor, consulte assetDescriptor.schema.json.
Modelos de formación
Cuando entrene un modelo, use imágenes del entorno de destino o de un entorno de prueba que se parezca mucho al entorno de destino. Tenga en cuenta los siguientes factores que pueden afectar al rendimiento del modelo:
-
Iluminación: la cantidad de luz que refleja un sujeto determina la cantidad de detalles que el modelo debe analizar. Es posible que un modelo entrenado con imágenes de sujetos bien iluminados no funcione bien en un entorno con poca luz o retroiluminado.
-
Resolución: el tamaño de entrada de un modelo suele fijarse en una resolución de entre 224 y 512 píxeles de ancho en una relación de aspecto cuadrada. Antes de pasar un fotograma de vídeo al modelo, puede reducirlo o recortarlo para que se ajuste al tamaño requerido.
-
Distorsión de la imagen: la distancia focal y la forma de la lente de la cámara pueden provocar que las imágenes se distorsionen alejándose del centro del encuadre. La posición de la cámara también determina qué características del sujeto son visibles. Por ejemplo, una cámara de techo con una lente gran angular mostrará la parte superior del sujeto cuando esté en el centro del encuadre y una vista sesgada del costado del sujeto a medida que se aleja del centro.
Para solucionar estos problemas, puede preprocesar las imágenes antes de enviarlas al modelo y entrenar al modelo sobre una variedad más amplia de imágenes que reflejen las variaciones de los entornos del mundo real. Si un modelo necesita funcionar en situaciones de iluminación y con una variedad de cámaras, necesitará más datos para el entrenamiento. Además de recopilar más imágenes, puede obtener más datos de entrenamiento creando variaciones de las imágenes existentes que estén sesgadas o tengan una iluminación diferente.
