Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Procesos de AWS ParallelCluster
Esta sección se aplica únicamente a clústeres de HPC que se implementan con uno de los programadores de trabajos tradicionales compatibles (SGE, Slurm o Torque). Al usarse con estos programadores, AWS ParallelCluster administra el aprovisionamiento del nodo de computación y su eliminación interactuando con el grupo de escalado automático y el programador de trabajos subyacente.
Para clústeres de HPC basados en AWS Batch, AWS ParallelCluster se basa en las capacidades que proporciona por la administración de nodos de computación.
nota
A partir de la versión 2.11.5, AWS ParallelCluster no admite el uso de planificadores SGE o Torque. Puede seguir utilizándolos en las versiones anteriores a la 2.11.4 inclusive, pero no son aptos para recibir actualizaciones futuras ni asistencia para la solución de problemas por parte de los equipos de servicio AWS y soporte AWS.
SGE and Torque integration processes
nota
Esta sección solo se aplica a AWS ParallelCluster las versiones anteriores a la 2.11.4 (inclusive). A partir de la versión 2.11.5, AWS ParallelCluster no admite el uso de Torque planificadores SGE y Amazon SNS y Amazon SQS.
Información general
El ciclo de vida de un clúster comienza después de crearlo el usuario. Normalmente, un clúster se crea a partir de la interfaz de línea de comandos (CLI). Después de crearse, un clúster existe hasta que se elimina. Los demonios de AWS ParallelCluster se ejecutan en los nodos de clúster, principalmente para administrar la elasticidad del clúster HPC. En el siguiente diagrama se muestran un flujo de trabajo de usuario y el ciclo de vida del clúster. En las secciones que aparecen a continuación se describen los demonios de AWS ParallelCluster que se utilizan para administrar el clúster.
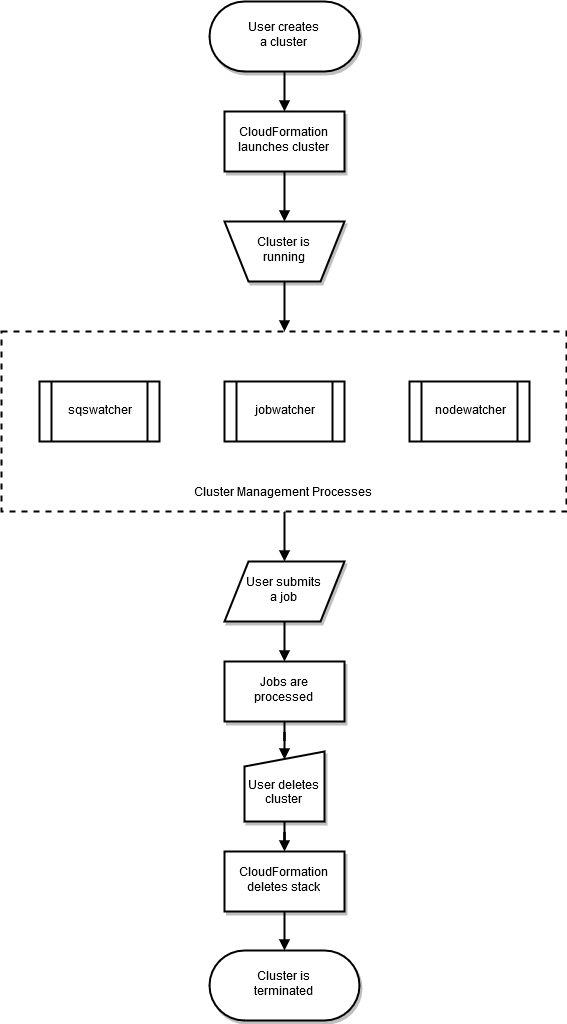
Con SGE y programadores Torque, AWS ParallelCluster use los procesos nodewatcher, jobwatcher y sqswatcher.
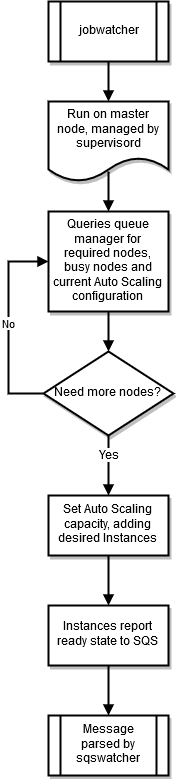
jobwatcher
Cuando se ejecuta un clúster, un proceso propiedad del usuario raíz supervisa el programador configurado (SGE o Torque). Cada minuto evalúa la cola para decidir cuándo escalar verticalmente.
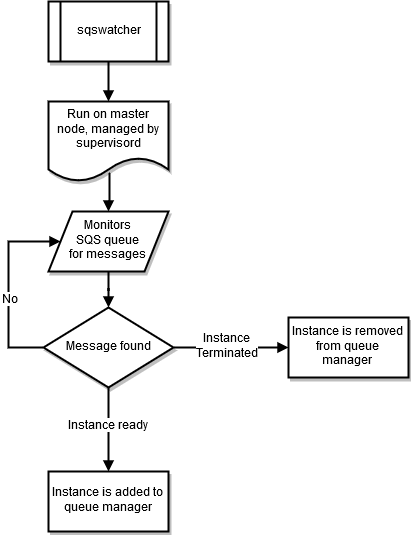
sqswatcher
El proceso monitoriza los mensajes de sqswatcher que el escalado automático envía para notificarle los cambios de estado en el clúster. Cuando una instancia está online, envía un mensaje "instancia lista" a Amazon SQS. sqs_watcher recoge este mensaje y se ejecuta en el nodo principal. Estos mensajes se utilizan para notificar al administrador de la cola que hay instancias nuevas online o que se han terminado instancias, de modo que se puedan añadir o eliminar de la cola.
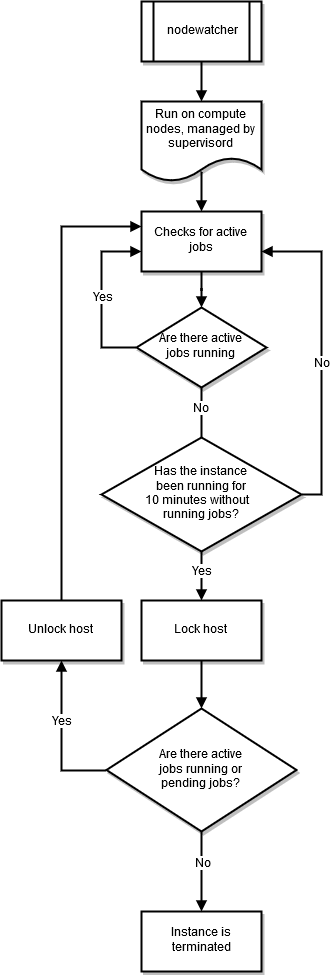
nodewatcher
El proceso nodewatcher se ejecuta en cada nodo de la flota de computación. Transcurrido el periodo scaledown_idletime, tal como define el usuario, la instancia se termina.
Slurm integration processes
Con programadores Slurm, AWS ParallelCluster usa los procesos clustermgtd y computemgt.
clustermgtd
Los clústeres que se ejecutan en modo heterogéneo (indicado mediante la especificación de un valor queue_settings) tienen un proceso daemon de administración de clústeres (clustermgtd) que se ejecuta en el nodo principal. Estas tareas las realiza el daemon de administración de clústeres.
-
Limpieza de particiones inactivas
-
Administración de la capacidad estática: asegúrese de que la capacidad estática esté siempre activa y en buen estado
-
Programador de sincronización con Amazon EC2.
-
Limpieza de instancias huérfanas
-
Restaure el estado del nodo del programador en la terminación de Amazon EC2 que se produce fuera del flujo de trabajo suspendido
-
Administración de instancias de Amazon EC2 en mal estado (no se cumplen las comprobaciones de estado de Amazon EC2)
-
Administración de eventos de mantenimiento programados
-
La administración de los nodos del programador no funciona correctamente (comprobaciones de estado fallidas)
computemgtd
Los clústeres que se ejecutan en modo heterogéneo (indicado mediante la especificación de un valor queue_settings) tienen procesos daemon (computemgtd) de administración de cómputo que se ejecutan en cada uno de los nodos de cómputo. Cada cinco (5) minutos, el daemon de administración de cómputo confirma que se puede acceder al nodo principal y que está en buen estado. Si transcurren cinco (5) minutos durante los cuales no se pueda acceder al nodo principal o éste no esté en buen estado, el nodo de procesamiento se cierra.
