Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Etiquetas SSML compatibles
Amazon Polly es compatible con las siguientes etiquetas SSML:
| Acción | Etiqueta SSML | Disponibilidad con voces neuronales | Disponibilidad con voces de formato largo | Disponibilidad con voces generativas |
|---|---|---|---|---|
|
<break> |
Disponibilidad completa |
Disponibilidad completa |
Disponibilidad completa |
|
| <emphasis> |
No disponible |
No disponible |
No disponible |
|
| <lang> |
Disponibilidad completa |
Disponibilidad completa |
Disponibilidad completa |
|
| <mark> |
Disponibilidad completa |
Disponibilidad completa |
Disponibilidad completa |
|
|
<p> |
Disponibilidad completa |
Disponibilidad completa |
Disponibilidad completa |
|
|
<phoneme> |
Disponibilidad completa |
Disponibilidad completa |
No disponible |
|
|
<prosody> |
Disponibilidad parcial |
Disponibilidad parcial |
No disponible |
|
|
<prosody amazon:max-duration> |
No disponible |
No disponible |
No disponible |
|
|
<s> |
Disponibilidad completa |
Disponibilidad completa |
Disponibilidad completa |
|
|
<say-as> |
Disponibilidad parcial |
Disponibilidad parcial |
Disponibilidad parcial |
|
|
<speak> |
Disponibilidad completa |
Disponibilidad completa |
Disponibilidad completa |
|
|
<sub> |
Disponibilidad completa |
Disponibilidad completa |
Disponibilidad completa |
|
|
Mejora de la pronunciación especificando partes del discurso |
<w> |
Disponibilidad completa |
Disponibilidad completa |
Disponibilidad completa |
|
<amazon:auto-breaths> |
No disponible |
No disponible |
No disponible |
|
| <amazon: domain name =" news"> |
Solo en algunas voces neuronales |
No disponible |
No disponible |
|
|
<amazon:effect name="drc"> |
Disponibilidad completa |
Disponibilidad completa |
No disponible |
|
|
<amazon:effect phonation="soft"> |
No disponible |
No disponible |
No disponible |
|
|
<amazon:effect > vocal-tract-length |
No disponible |
No disponible |
No disponible |
|
|
<amazon:effect name="whispered"> |
No disponible |
No disponible |
No disponible |
nota
Si utiliza etiquetas SSML no admitidas en formato largo, neuronal o estándar, aparecerá un error.
Identificación de texto mejorado con SSML
<speak>
Esta etiqueta es compatible con los formatos TTS generativo, largo, neuronal y estándar.
La etiqueta <speak> es el elemento raíz de todo el texto SSML de Amazon Polly. Todo el texto mejorado con SSML debe incluirse entre un par de etiquetas <speak>.
<speak>Mary had a little lamb.</speak>Agregación de una pausa
<break>
Esta etiqueta es compatible con los formatos TTS generativo, largo, neural y estándar.
Para añadir una pausa al texto, utilice la etiqueta <break>. Puede establecer una pausa basada en la intensidad (equivalente a la pausa después de una coma, una frase o un párrafo), o bien puede establecerla en un periodo de tiempo específico en segundos o milisegundos. Si no se especifica un atributo para determinar la duración de la pausa, Amazon Polly utiliza el valor predeterminado <break
strength="medium"/>, que añade una pausa con la duración de una pausa después de una coma.
Valores del atributo strength:
-
none: sin pausa. Usenonepara eliminar una pausa que se produce normalmente, como después de un punto. -
x-weak: tiene la misma fuerza quenone, sin pausa. -
weak: establece una pausa de la misma duración que la pausa después de una coma. -
medium: tiene la misma fuerza queweak. -
strong: establece una pausa de la misma duración que la pausa después de una frase. -
x-strong: establece una pausa de la misma duración que la pausa después de un párrafo.
Valores del atributo time:
-
[number]s10s. -
[number]ms10000ms.
Por ejemplo:
<speak>
Mary had a little lamb <break time="3s"/>Whose fleece was white as snow.
</speak>Si no utiliza un atributo con la etiqueta break, el resultado varia en función del texto:
-
Si no hay ningún otro tipo de puntuación junto a la etiqueta
break, se crea una de tipo<break strength="medium"/>(pausa después de una coma). -
Si la etiqueta está junto a una coma, se actualiza la etiqueta a
<break strength="strong"/>(pausa después de una frase). -
Si la etiqueta está junto a un punto, se actualiza la etiqueta a
<break strength="x-strong"/>(pausa después de un párrafo).
Énfasis de palabras
<emphasis>
Esta etiqueta solo es compatible con el formato TTS estándar.
Para enfatizar palabras, utilice la etiqueta <emphasis>. Enfatizar las palabras cambia el volumen y la velocidad de la voz. Más énfasis significa que Amazon Polly lee el texto más alto y lento. Menos énfasis hace que el texto se lea más bajo y rápido. Para especificar el grado de énfasis, utilice el atributo level.
Valores del atributo level:
-
Strong: aumenta el volumen y ralentiza la velocidad de habla, para que la voz sea más alta y lenta. -
Moderate: aumenta el volumen y ralentiza la velocidad de habla, pero menos questrong.Moderatees el valor predeterminado. -
Reduced: aumenta el volumen e incrementa la velocidad de habla. La voz es más baja y rápida.
nota
La velocidad y el volumen de habla normales para una voz se encuentran entre los niveles moderate y reduced.
Por ejemplo:
<speak> I already told you I <emphasis level="strong">really like</emphasis> that person. </speak>
Especificación de otro idioma para palabras específicas
<lang>
Esta etiqueta es compatible con los formatos TTS generativo, largo, neural y estándar.
Especifique otro idioma para una palabra específica, frase u oración con la etiqueta <lang>. Las palabras y frases extranjeras normalmente se leen mejor cuando se incluyen entre un par de etiquetas <lang>. Para especificar el idioma, utilice el atributo xml:lang. Para ver una lista completa de los idiomas disponibles, consulte Idiomas en Amazon Polly.
A menos que aplique la etiqueta <lang>, todas las palabras del texto de entrada se leen en el idioma de la voz especificada en voice-id. Si aplica la etiqueta <lang>, las palabras se leen en ese idioma.
Por ejemplo, si el voice-id es Joanna (que habla inglés de Estados Unidos), Amazon Polly lee lo siguiente en la voz de Joanna sin acento francés:
<speak>
Je ne parle pas français.
</speak>Si utiliza la voz de Joanna con la etiqueta <lang>, Amazon Polly lee la frase en la voz de Joanna en francés con acento americano:
<speak>
<lang xml:lang="fr-FR">Je ne parle pas français.</lang>.
</speak>Como Joanna no es una hablante nativa del francés, la pronunciación tendrá como base su idioma nativo, inglés de Estados Unidos. Por ejemplo, aunque una pronunciación francesa perfecta pronunciaría la palabra français con una /R/ vibrante uvular, la voz de Joanna, cuyo idioma nativo es el inglés americano, pronuncia este fonema con el sonido /r/ correspondiente.
Si utiliza el voice-id de Giorgio, que habla italiano, con el siguiente texto, Amazon Polly lee la frase en la voz de Giorgio con pronunciación italiana:
<speak>
Mi piace Bruce Springsteen.
</speak>Si utiliza la misma voz con la siguiente etiqueta <lang>, Amazon Polly pronuncia Bruce Springsteen en inglés con acento italiano:
<speak>
Mi piace <lang xml:lang="en-US">Bruce Springsteen.</lang>
</speak>Esta etiqueta también se puede utilizar como sustituto de la DefaultLangCodeopción opcional al sintetizar voz. Sin embargo, esto requiere dar formato al texto con SSML.
Colocación de una etiqueta personalizada en el texto
<mark>
Esta etiqueta es compatible con los formatos TTS generativo, largo, neuronal y estándar.
Para colocar una etiqueta personalizada dentro del texto, utilice la etiqueta <mark>. Amazon Polly no realiza ninguna acción en la etiqueta, pero devuelve la ubicación de la etiqueta en los metadatos SSML. Esta etiqueta puede ser cualquier cosa que se le ocurra, siempre que mantenga el siguiente formato:
<mark name="tag_name"/>Por ejemplo, suponga que el nombre de la etiqueta es "animal" y el texto de entrada es:
<speak>
Mary had a little <mark name="animal"/>lamb.
</speak>Amazon Polly podría devolver los siguientes metadatos SSML:
{"time":767,"type":"ssml","start":25,"end":46,"value":"animal"}Agregación de una pausa entre párrafos
<p>
Esta etiqueta es compatible con los formatos TTS generativo, largo, neural y estándar.
Para añadir una pausa entre los párrafos del texto, utilice la etiqueta <p>. El uso de esta etiqueta proporciona una pausa que incluyen normalmente los hablantes nativos cuando hay una coma o al final de una frase. Utilice la etiqueta <p> para incluir el párrafo:
<speak>
<p>This is the first paragraph. There should be a pause after this text is spoken.</p>
<p>This is the second paragraph.</p>
</speak>Esto equivale a especificar una pausa con <break strength="x-strong"/>.
Uso de la pronunciación fonética
<phoneme>
Esta etiqueta es compatible con los formatos TTS de formato largo, neuronal y estándar.
Para que Amazon Polly utilice la pronunciación fonética para un determinado texto, utilice la etiqueta <phoneme>.
La etiqueta <phoneme> requiere dos atributos. Indican el alfabeto fonético que utiliza Amazon Polly y los símbolos fonéticos de la pronunciación corregida:
-
alphabet-
ipa: indica que se usará el Sistema Fonético Internacional (IPA, por sus siglas en inglés). -
x-sampa: indica que se usará el Alfabeto Fonético Extendido SAM (X-SAMPA, por sus siglas en inglés).
-
-
ph-
Especifica los símbolos fonéticos para la pronunciación. Para obtener más información, consulte Tablas de fonemas y visemas de los idiomas admitidos.
-
Con la etiqueta <phoneme>, Amazon Polly utiliza la pronunciación especificada por el atributo ph en lugar de la pronunciación estándar asociada de forma predeterminada con el idioma utilizado por la voz seleccionada.
Por ejemplo, la palabra "pecan" puede pronunciarse de dos formas. En el ejemplo siguiente, a la palabra “pecan” se le asigna una pronunciación diferente en cada línea. Amazon Polly pronuncia "pecan" tal y como se especifica en los atributos ph, en lugar de utilizar la pronunciación predeterminada.
Sistema Fonético Internacional (IPA)
<speak> You say, <phoneme alphabet="ipa" ph="pɪˈkɑːn">pecan</phoneme>. I say, <phoneme alphabet="ipa" ph="ˈpi.kæn">pecan</phoneme>. </speak>
Métodos ampliados de evaluación del habla: Alfabeto Fonético Extendido SAM (X-SAMPA)
<speak> You say, <phoneme alphabet='x-sampa' ph='pI"kA:n'>pecan</phoneme>. I say, <phoneme alphabet='x-sampa' ph='"pi.k{n'>pecan</phoneme>. </speak>
Asimismo, el chino mandarín utiliza el pinyin para la pronunciación fonética.
Pinyin
<speak> 你说 <phoneme alphabet="x-amazon-pinyin" ph="bo2">薄</phoneme>。 我说 <phoneme alphabet="x-amazon-pinyin" ph="bao2">薄</phoneme>。 </speak>
En japonés se usa yomigana y la pronunciación kana.
Yomigana
<speak> 名前は<phoneme alphabet="x-amazon-yomigana" ph="ひろかず">浩一</phoneme>です。 名前は<phoneme alphabet="x-amazon-yomigana" ph="ヒロカズ">浩一</phoneme>です。 名前は<phoneme alphabet="x-amazon-yomigana" ph="Hirokazu">浩一</phoneme>です。 </speak>
Pronunciación kana
<speak> 名前は<phoneme alphabet="x-amazon-pron-kana" ph="ヒロ'カズ">浩一</phoneme>です。 </speak>
Control del volumen, velocidad de habla y tono
<prosody>
Los atributos de las etiquetas Prosody son totalmente compatibles con las voces TTS estándar. Las voces neuronales y de formato largo admiten los atributos volume y rate, pero no admiten el atributo pitch.
Para controlar el volumen, la velocidad o el tono de la voz seleccionada, utilice la etiquetaprosody.
El volumen, la velocidad de habla, y el tono dependen de la voz seleccionada. Además de las diferencias entre las voces de diferentes idiomas, existen diferencias entre las voces que hablan el mismo idioma. Por este motivo, aunque los atributos son similares en todos los idiomas, existen claras variaciones de un idioma a otro y no hay ningún valor absoluto disponible.
La etiqueta prosody tiene tres atributos, cada uno de los cuales tiene varios valores disponibles para establecer el atributo. Todos los atributos utilizan la misma sintaxis:
<prosody attribute="value"></prosody>-
volume-
default: restablece el volumen al nivel predeterminado de la voz actual. -
silent,x-soft,soft,medium,loud,x-loud: establece el volumen en un valor predefinido de la voz actual. -
+ndB,-ndB: cambia el volumen en función del nivel actual. El valor+0dBsignifica que no se producen cambios,+6dBsignifica aproximadamente el doble del volumen actual y-6dBsignifica aproximadamente la mitad del volumen actual.
Por ejemplo, puede establecer el volumen de un pasaje tal y como se indica a continuación:
<speak> Sometimes it can be useful to <prosody volume="loud">increase the volume for a specific speech.</prosody> </speak>También se puede hacer de este modo:
<speak> And sometimes a lower volume <prosody volume="-6dB">is a more effective way of interacting with your audience.</prosody> </speak> -
-
rate-
x-slow,slow,medium,fast,x-fast: establece el tono en un valor predefinido para la voz seleccionada. -
n%: un cambio de porcentaje no negativo en la velocidad de habla. Por ejemplo, un valor de 100% significa que no hay ningún cambio en la velocidad de habla; un valor de 200% significa una velocidad dos veces superior a la velocidad predeterminada y un valor de 50% significa una velocidad de habla a la mitad de la velocidad predeterminada. Este valor tiene un intervalo de 20-200%.
Por ejemplo, puede establecer la velocidad de habla de un pasaje tal y como se indica a continuación:
<speak> For dramatic purposes, you might wish to <prosody rate="slow">slow up the speaking rate of your text.</prosody> </speak>También se puede hacer de este modo:
<speak> Although in some cases, it might help your audience to <prosody rate="85%">slow the speaking rate slightly to aid in comprehension.</prosody> </speak> -
-
pitch-
default: restablece el tono en el valor predeterminado de la voz actual. -
x-low,low,medium,high,x-high: establece el tono en un valor predefinido de la voz actual. -
+n%o-n%: ajusta el tono aplicando un porcentaje relativo. Por ejemplo, un valor de+0%significa que no hay ningún cambio en el tono de base de referencia,+5%da como resultado un tono de base de referencia un poco más alto y-5%da como resultado un tono de base de referencia un poco más bajo.
Por ejemplo, puede establecer el tono de un pasaje tal y como se indica a continuación:
<speak> Do you like sythesized speech <prosody pitch="high">with a pitch that is higher than normal?</prosody> </speak>También se puede hacer de este modo:
<speak> Or do you prefer your speech <prosody pitch="-10%">with a somewhat lower pitch?</prosody> </speak> -
La etiqueta <prosody> debe contener al menos un atributo, pero puede incluir más dentro de la misma etiqueta.
<speak> Each morning when I wake up, <prosody volume="loud" rate="x-slow">I speak quite slowly and deliberately until I have my coffee.</prosody> </speak>
También se puede combinar con etiquetas anidadas, tal y como se indica a continuación:
<speak> <prosody rate="85%">Sometimes combining attributes <prosody pitch="-10%">can change the impression your audience has of a voice</prosody> as well.</prosody> </speak>
Establecimiento de una duración máxima para voz sintetizada
<prosody amazon:max-duration>
Esta etiqueta solo es compatible actualmente con el formato TTS estándar.
Para controlar el tiempo que desea que tarde un fragmento de voz cuando se sintetiza, utilice la etiqueta <prosody> con el atributo amazon:max-duration.
La duración del fragmento de voz sintetizado varía ligeramente, en función de la voz que seleccione. Esto puede dificultar la coincidencia del fragmento de voz sintetizado con elementos visuales u otras actividades que requieran una sincronización precisa. Este problema aumenta en el caso de aplicaciones de traducción, ya que el tiempo que se tarda en decir frases concretas puede variar notablemente en distintos idiomas.
La etiqueta <prosody amazon:max-duration> asigna el fragmento de voz sintetizada a la cantidad de tiempo que desea que tarde (la duración).
Esta etiqueta utiliza la siguiente sintaxis:
<prosody amazon:max-duration="time duration">Con la etiqueta <prosody amazon:max-duration>, puede especificar la duración en segundos o milisegundos:
-
ns -
nms
Por ejemplo, el siguiente texto hablado tiene una duración máxima de 2 segundos:
<speak>
<prosody amazon:max-duration="2s">
Human speech is a powerful way to communicate.
</prosody>
</speak>Texto colocado dentro de la etiqueta, no supera la duración especificada. Si la voz o el idioma elegido normalmente requiere más tiempo que la duración, Amazon Polly acelera el fragmento de voz de modo que se ajuste a la duración especificada.
Si la duración especificada es superior a lo que se tarda en leer el texto en una velocidad normal, Amazon Polly lee el fragmento con normalidad. No ralentiza el fragmento de voz ni añade silencio, por lo que el audio resultante es más corto de lo necesario.
nota
Amazon Polly aumenta la velocidad no más de 5 veces la velocidad normal. Si el texto se lee más rápido que esto, por lo general no tiene sentido. Si un fragmento de voz no puede ajustarse a la duración especificada, incluso aunque la velocidad se acelere al máximo, el audio se acelerará, pero durará más de la duración especificada.
Puede incluir una sola frase o varias frases dentro de una etiqueta <prosody amazon:max-duration> y puede utilizar varias etiquetas <prosody amazon:max-duration> en su texto.
Por ejemplo:
<speak> <prosody amazon:max-duration="2400ms"> Human speech is a powerful way to communicate. </prosody> <break strength="strong"/> <prosody amazon:max-duration="5100ms"> Even a simple ‘Hello’ can convey a lot of information depending on the pitch, intonation, and tempo. </prosody> <break strength="strong"/> <prosody amazon:max-duration="8900ms"> We naturally understand this information, which is why speech is ideal for creating applications where a screen isn’t practical or possible, or simply isn’t convenient. </prosody> </speak>
El uso de la etiqueta <prosody amazon:max-duration> puede aumentar la latencia cuando Amazon Polly devuelve un fragmento de voz sintetizada. El grado de latencia depende del fragmento y de su longitud. Le recomendamos que utilice texto compuesto por fragmentos de texto relativamente cortos.
Limitaciones
Existen limitaciones, tanto en la forma de utilizar la etiqueta <prosody
amazon:max-duration> y en cómo funciona con otras etiquetas de SSML:
-
El texto dentro de una etiqueta
<prosody amazon:max-duration>no puede tener más de 1500 caracteres. -
No puede anidar etiquetas
<prosody amazon:max-duration>. Si coloca una etiqueta<prosody amazon:max-duration>dentro de otra, Amazon Polly omite la etiqueta interior.Por ejemplo, en el caso siguiente se omite la etiqueta
<prosody amazon:max-duration="5s">:<speak> <prosody amazon:max-duration="16s"> Human speech is a powerful way to communicate. <prosody amazon:max-duration="5s"> Even a simple ‘Hello’ can convey a lot of information depending on the pitch, intonation, and tempo. </prosody> We naturally understand this information, which is why speech is ideal for creating applications where a screen isn’t practical or possible, or simply isn’t convenient. </prosody> </speak> -
No se pueden utilizar las etiquetas
<prosody>con el atributoratedentro de una etiqueta<prosody amazon:max-duration>. Esto se debe a que ambas afectan a la velocidad a la que se dicta el texto.En el ejemplo siguiente, Amazon Polly omite la etiqueta
<prosody rate="2">:<speak> <prosody amazon:max-duration="7500ms"> Human speech is a powerful way to communicate. <prosody rate="2"> Even a simple ‘Hello’ can convey a lot of information depending on the pitch, intonation, and tempo. </prosody> </prosody> </speak>
Pausas y max-duration
Cuando se utiliza la etiqueta max-duration, puede insertar pausas en el texto. Sin embargo, Amazon Polly incluye la longitud de la pausa al calcular la duración máxima del fragmento de voz. Además, Amazon Polly conserva las pausas breves que se producen cuando hay comas y puntos en un fragmento y las incluye en la duración máxima.
Por ejemplo, en el siguiente bloque, la interrupción de 600 milisegundos y la interrupción provocada por comas y puntos se produce en el fragmento de texto de 8 segundos:
<speak> <prosody amazon:max-duration="8s"> Human speech is a powerful way to communicate. <break time="600ms"/> Even a simple ‘Hello’ can convey a lot of information depending on the pitch, intonation, and tempo. </prosody> </speak>
Agregación de una pausa entre frases
<s>
Esta etiqueta es compatible con los formatos TTS generativo, largo, neural y estándar.
Para añadir una pausa entre líneas o frases del texto, utilice la etiqueta <s>. El uso de esta etiqueta tiene el mismo efecto que:
-
Terminar una frase con un punto (.)
-
Especificar una pausa con
<break strength="strong"/>
A diferencia de la etiqueta <break>, la etiqueta <s> incluye la frase. Esto es útil para sintetizar la voz de texto organizado en líneas, en lugar de en frases, como los poemas.
En el siguiente ejemplo, la etiqueta <s> inserta una breve pausa después de la primera y segunda frase. La última frase no tiene ninguna etiqueta <s>, pero también se aplica una breve pausa detrás de ella porque termina con un punto.
<speak> <s>Mary had a little lamb</s> <s>Whose fleece was white as snow</s> And everywhere that Mary went, the lamb was sure to go. </speak>
Control de cómo se leen los tipos especiales de palabras
<say-as>
A excepción de la characters opción, la <say-as> etiqueta es compatible con los formatos TTS generativo, de formato largo, neural y estándar. Tenga en cuenta que si Amazon Polly utiliza una voz neuronal y encuentra la etiqueta <say-as> con la opción characters en tiempo de ejecución, la frase afectada se sintetizará con la voz estándar relacionada. Sin embargo, la frase afectada se seguirá facturando como si utilizara una voz neuronal.
Utilice la etiqueta <say-as> con el atributo interpret-as para indicar a Amazon Polly cómo leer determinados caracteres, palabras y números. De este modo, puede proporcionar información adicional para eliminar cualquier ambigüedad sobre cómo Amazon Polly debe representar el texto.
La etiqueta <say-as> utiliza un atributo, interpret-as, que usa una serie de valores posibles disponibles. Todos ellos utilizan la misma sintaxis:
<say-as interpret-as="value">[text to be interpreted]</say-as>Los valores siguientes están disponibles con interpret-as:
-
charactersospell-out: deletrea cada letra del texto, como en a-b-c.nota
Esta opción no se admite actualmente para voces neuronales. Si utilizas una voz neuronal y Amazon Polly encuentra este código SSML en tiempo de ejecución, la frase afectada se sintetizará con la voz estándar relacionada. Tenga en cuenta, sin embargo, que esta frase se seguirá facturando como si utilizara una voz neuronal.
-
cardinalonumber: interpreta el valor numérico como un número cardinal; por ejemplo, 1.234. -
ordinal: interpreta el texto numérico como un número ordinal; por ejemplo, 1.234º. -
digits: deletrea cada dígito por separado; por ejemplo, 1-2-3-4. -
fraction: interpreta el texto numérico como una fracción. Esto es aplicable a las fracciones comunes, como 3/20, y a las fracciones mixtas, como 2 ½. Para obtener más información, consulte las secciones siguientes. -
unit: interpreta un texto numérico como una medida. El valor debe ser un número o una fracción seguido de una unidad (sin espacio entre ellos) como en1/2inch, o solo de una unidad, como en1meter. -
date: interpreta el texto como una fecha. El formato de la fecha debe especificarse con el atributo format. Para obtener más información, consulte las secciones siguientes. -
time: interpreta el texto numérico como una cantidad de tiempo en minutos y segundos; por ejemplo,1'21". -
address: interpreta el texto como parte de una dirección postal. -
expletive: emite un pitido en lugar del contenido incluido en la etiqueta. -
telephone: interpreta el texto numérico como un número de teléfono de 7 o 10 dígitos, como en2025551212. También puede utilizar este valor para las extensiones telefónicas, como en2025551212x345. Para obtener más información, consulte las secciones siguientes.nota
En la actualidad, la opción
telephoneno está disponible para todos los idiomas. Sin embargo, están disponibles para las siguientes variantes de inglés hablado: (en-AU, en-GB, en-IN, en-US y en-GB-WLS); las siguientes variantes de español hablado (es-ES, es-MX y es-US); las siguientes variantes de francés hablado: (fr-FR y fr-CA), y las siguientes variantes de portugués hablado: (pt-BR y pt-PT), así como para el alemán (de-DE), el italiano (it-IT), el japonés (ja-JP) y el ruso (ru-RU). También debe tenerse en cuenta que, en algunos casos, idiomas como el árabe (arb) tratan automáticamente el conjunto de números como un número de teléfono y, por lo tanto, no implementan realmente la etiqueta SSML.telephone
Fracciones
Amazon Polly interpreta los valores dentro de la etiqueta say-as que tengan el atributo interpret-as="fraction" como fracciones comunes. A continuación se presenta la sintaxis de las fracciones:
-
Fracción
Sintaxis:
número cardinal/número cardinal(por ejemplo, 2/9).Por ejemplo:
<say-as interpret-as="fraction">2/9</say-as>se pronuncia "dos novenos." -
Número mixto no negativo
Sintaxis:
número cardinal+número cardinal/número cardinal(por ejemplo, 3+1/2).Por ejemplo,
<say-as interpret-as="fraction">3+1/2</say-as>se pronuncia "tres y medio".nota
Debe haber un signo
+entre "3" y "1/2". Amazon Polly no admite un número mixto sin el signo+, como, por ejemplo, "3 1/2".
Fechas
Cuando interpret-as se establece en date, también se deberá indicar el formato de la fecha.
Utiliza la siguiente sintaxis:
<say-as interpret-as="date" format="format">[date]</say-as>
Por ejemplo:
<speak> I was born on <say-as interpret-as="date" format="mdy">12-31-1900</say-as>. </speak>
Los siguientes formatos pueden utilizarse con el atributo date.
-
mdy: M. onth-day-year -
dmy: ay-month-year D. -
ymd: ear-month-day Y. -
md: mes-día. -
dm: día-mes. -
ym: año-mes. -
my: mes-año. -
d: Día. -
m: Month. -
y: Year. -
yyyymmdd: ear-month-day Y. Si utiliza este formato, puede hacer que Amazon Polly omita partes de la fecha mediante signos de interrogación.Por ejemplo, Amazon Polly reproduce lo siguiente como "22 de septiembre":
<say-as interpret-as="date">????0922</say-as>Formatno es necesario.
Teléfono
Amazon Polly intenta interpretar correctamente el texto proporcionado a partir de su formato aun cuando no aparece la etiqueta <say-as>. Por ejemplo, si el texto incluye "202-555-1212", Amazon Polly lo interpreta como un número de teléfono de 10 cifras y lee cada cifra individualmente, aplicando una breve pausa en cada guion. En este caso, no es necesario usar <say-as interpret-as="telephone">. Sin embargo, si proporciona el texto “2025551212” y quiere que Amazon Polly lo lea como un número de teléfono, debería especificar <say-as
interpret-as="telephone">.
La lógica para interpretar cada elemento depende del idioma. Por ejemplo, en inglés de EE. UU. y en inglés de Reino Unido, los números de teléfono no se expresan igual (en inglés de Reino Unido, se agrupan las secuencias del mismo número; por ejemplo, "doble cinco" o "triple cuatro"). Para ver la diferencia, puede probar el siguiente ejemplo con una voz de Estados Unidos y otra de Reino Unido:
<speak> Richard's number is <say-as interpret-as="telephone">2122241555</say-as> </speak>
Pronunciación de acrónimos y abreviaturas
<sub>
Esta etiqueta es compatible con los formatos TTS generativo, largo, neuronal y estándar.
Utilice la etiqueta <sub> con el atributo alias para sustituir una sola palabra (o pronunciación) del texto seleccionado como un acrónimo o una abreviatura.
Se utiliza esta sintaxis:
<sub alias="new word">abbreviation</sub>En el siguiente ejemplo, el nombre "Mercury" (Mercurio) se sustituye por el símbolo químico del elemento para que el contenido de audio sea más claro.
<speak> My favorite chemical element is <sub alias="Mercury">Hg</sub>, because it looks so shiny. </speak>
Mejora de la pronunciación especificando partes del discurso
<w>
Esta etiqueta es compatible con los formatos TTS generativo, largo, neural y estándar.
Puede utilizar la etiqueta <w> para personalizar la pronunciación de las palabras especificando su categoría gramatical o su significado alternativo. Esto se realiza mediante el atributo role.
Esta etiqueta utiliza la siguiente sintaxis:
<w role="attribute">text</w>Los siguientes valores pueden utilizarse con el atributo role:
Para especificar la categoría gramatical:
-
amazon:VB: interpreta la palabra como un verbo (presente simple). -
amazon:VBD: interpreta la palabra como un verbo en tiempo pasado. -
amazon:DT: interpreta la palabra como determinante. -
amazon:IN: interpreta la palabra como una preposición. -
amazon:JJ: interpreta la palabra como un adjetivo. -
amazon:NN: interpreta la palabra como un sustantivo.
Por ejemplo, dependiendo de la categoría gramatical, la pronunciación en inglés de Estados Unidos de la palabra "read" varia en función de la etiqueta:
<speak> The word <say-as interpret-as="characters">read</say-as> may be interpreted as either the present simple form <w role="amazon:VB">read</w>, or the past participle form <w role="amazon:VBD">read</w>. </speak>
Para especificar un significado específico:
-
amazon:DEFAULT: usa el sentido predeterminado de la palabra. -
amazon:SENSE_1: cuando es aplicable, utiliza un sentido de la palabra que no es el predeterminado. Por ejemplo, el nombre "bass" se pronuncia de forma diferente en función de su significado. El significado predeterminado es la parte más baja de la escala musical. El significado alternativo es una especie de pez de agua dulce, también denominado "bass", pero que se pronuncia de forma diferente. Si se utiliza<w role="amazon:SENSE_1">bass</w>, se aplica la pronunciación no predeterminada (es decir, pez de agua dulce) en el texto del audio.
Esta diferencia en la pronunciación y el significado se puede oír si se sintetiza lo siguiente:
<speak> Depending on your meaning, the word <say-as interpret-as="characters">bass</say-as> may be interpreted as either a musical element: bass, or as its alternative meaning, a freshwater fish <w role="amazon:SENSE_1">bass</w>. </speak>
nota
Algunos idiomas pueden tener otra selección de categorías gramaticales.
Adición de sonido de respiración
<amazon:breath> y <amazon:auto-breaths>
Esta etiqueta solo es compatible con el formato TTS estándar.
La voz con sonido natural incluye tanto palabras habladas correctamente como sonidos de respiración. Al añadir sonidos de respiración a la voz sintetizada, puede hacer que suene más natural. Las etiquetas <amazon:breath> y <amazon:auto-breaths> proporcionan respiraciones. Dispone de las opciones siguientes:
-
Modo manual: puede establecer la ubicación, la duración y el volumen de un sonido de respiración en el texto
-
Modo automático: Amazon Polly inserta automáticamente sonidos de respiración en la salida de voz
-
Modo mixto: tanto usted como Amazon Polly añaden sonidos de respiración
Modo manual
En el modo manual, debe colocar la etiqueta <amazon:breath/> en el texto de entrada donde desee ubicar una respiración. Puede personalizar la duración y el volumen de las respiraciones con los atributos duration y volume, respectivamente:
-
duration: controla la duración de la respiración. Los valores válidos son:default,x-short,short,medium,long,x-long. El valor predeterminado esmedium. -
volume: controla el volumen de la respiración. Los valores válidos son:default,x-soft,soft,medium,loud,x-loud. El valor predeterminado esmedium.
nota
La duración y el volumen exactos de cada valor de atributo dependen de la voz utilizada de Amazon Polly.
Para establecer un sonido de respiración con los valores predeterminados, utilice <amazon:breath/> sin atributos.
Por ejemplo, para utilizar atributos con el objeto de definir la duración y el volumen de una respiración a la mitad, configure los atributos de la siguiente forma:
<speak> Sometimes you want to insert only <amazon:breath duration="medium" volume="x-loud"/>a single breath. </speak>
Para utilizar los valores predeterminados, se usa la etiqueta:
<speak> Sometimes you need <amazon:breath/>to insert one or more average breaths <amazon:breath/> so that the text sounds correct. </speak>
Puede añadir sonidos de respiración individuales en un pasaje, tal y como se indica a continuación:
<speak> <amazon:breath duration="long" volume="x-loud"/> <prosody rate="120%"> <prosody volume="loud"> Wow! <amazon:breath duration="long" volume="loud"/> </prosody> That was quite fast. <amazon:breath duration="medium" volume="x-loud"/> I almost beat my personal best time on this track. </prosody> </speak>
Modo automático
En el modo automático, se utiliza la etiqueta <amazon:auto-breaths> para indicar a Amazon Polly que cree automáticamente ruidos de respiración en los intervalos apropiados. Puede establecer la frecuencia de los intervalos, su volumen y su duración. Coloque la etiqueta </amazon:auto-breaths> al principio del texto al que desee aplicar respiración automática y cierre la etiqueta al final.
nota
A diferencia de la etiqueta de modo manual, <amazon:breath/>, la etiqueta <amazon:auto-breaths> necesita una etiqueta de cierre (</amazon:auto-breaths>).
Puede utilizar los siguientes atributos opcionales con la etiqueta <amazon:auto-breaths>:
-
volume: controla el volumen de la respiración. Los valores válidos son:default,x-soft,soft,medium,loud,x-loud. El valor predeterminado esmedium. -
frequency: controla la frecuencia con la que se producen los sonidos de respiración en el texto. Los valores válidos son:default,x-low,low,medium,high,x-high. El valor predeterminado esmedium. -
duration: controla la duración de la respiración. Los valores válidos son:default,x-short,short,medium,long,x-long. El valor predeterminado esmedium.
De forma predeterminada, la frecuencia de sonidos de respiración depende del texto de entrada. Sin embargo, sonidos de respiración se suelen producir después de comas y puntos.
En los siguientes ejemplos se muestra cómo usar la etiqueta <amazon:auto-breaths>. Para decidir qué opciones se utilizarán en su contenido, copie los ejemplos correspondientes en la consola de Amazon Polly y escuche las diferencias.
-
Uso del modo automático sin parámetros opcionales.
<speak> <amazon:auto-breaths>Amazon Polly is a service that turns text into lifelike speech, allowing you to create applications that talk and build entirely new categories of speech- enabled products. Amazon Polly is a text-to-speech service that uses advanced deep learning technologies to synthesize speech that sounds like a human voice. With dozens of lifelike voices across a variety of languages, you can select the ideal voice and build speech- enabled applications that work in many different countries.</amazon:auto-breaths> </speak> -
Uso del modo automático con control de volumen. Los parámetros no especificados (
durationyfrequency) se establecen en los valores predeterminados (medium).<speak> <amazon:auto-breaths volume="x-soft">Amazon Polly is a service that turns text into lifelike speech, allowing you to create applications that talk and build entirely new categories of speech-enabled products. Amazon Polly is a text-to-speech service, that uses advanced deep learning technologies to synthesize speech that sounds like a human voice. With dozens of lifelike voices across a variety of languages, you can select the ideal voice and build speech- enabled applications that work in many different countries.</amazon:auto-breaths> </speak> -
Uso del modo automático con control de frecuencia. Los parámetros no especificados (
durationyvolume) se establecen en los valores predeterminados (medium).<speak> <amazon:auto-breaths frequency="x-low">Amazon Polly is a service that turns text into lifelike speech, allowing you to create applications that talk and build entirely new categories of speech-enabled products. Amazon Polly is a text-to-speech service, that uses advanced deep learning technologies to synthesize speech that sounds like a human voice. With dozens of lifelike voices across a variety of languages, you can select the ideal voice and build speech- enabled applications that work in many different countries.</amazon:auto-breaths> </speak> -
Uso del modo automático con varios parámetros. Para el parámetro sin especificar
Duration, Amazon Polly utiliza el valor predeterminado (medium).<speak> <amazon:auto-breaths volume="x-loud" frequency="x-low">Amazon Polly is a service that turns text into lifelike speech, allowing you to create applications that talk and build entirely new categories of speech-enabled products. Amazon Polly is a text-to-speech service, that uses advanced deep learning technologies to synthesize speech that sounds like a human voice. With dozens of lifelike voices across a variety of languages, you can select the ideal voice and build speech-enabled applications that work in many different countries.</amazon:auto-breaths> </speak>
Estilo de habla Newscaster
<amazon: domain name =" news">
El estilo presentador solo está disponible para las voces de Matthew o Joanna, que solo están disponibles en inglés de Estados Unidos (en-US), y Lupe, en español estadounidense (es-US). Solo se admite cuando se usa el formato Neural.
Para utilizar el estilo Newscaster, utilice etiquetas SSML y la siguiente sintaxis:
<amazon:domain name="news">text</amazon:domain>
Por ejemplo, puede utilizar el estilo presentador con la voz de Matthew de la siguiente manera:
<speak> <amazon:domain name="news"> From the Tuesday, April 16th, 1912 edition of The Guardian newspaper: The maiden voyage of the White Star liner Titanic, the largest ship ever launched, has ended in disaster. The Titanic started her trip from Southampton for New York on Wednesday. Late on Sunday night she struck an iceberg off the Grand Banks of Newfoundland. By wireless telegraphy she sent out signals of distress, and several liners were near enough to catch and respond to the call. </amazon:domain> </speak>
Adición de compresión de rango dinámico
<amazon:effect name="drc">
Esta etiqueta es compatible con los formatos TTS de formato largo, neuronal y estándar.
En función del texto, el idioma y la voz utilizados en un archivo de audio, los sonidos varían desde suaves a altos. Con frecuencia, los sonidos ambientales, como el sonido de un vehículo en movimiento, pueden enmascarar los sonidos más suaves, lo que impide oír con claridad la pista de audio. Para mejorar el volumen de determinados sonidos en el archivo de audio, utilice la etiqueta de compresión de rango dinámico (drc).
La etiqueta drc establece un umbral de "volumen" de rango medio para el audio y aumenta el volumen (la ganancia) de los sonidos alrededor de dicho umbral. El mayor aumento de ganancia se aplica cerca del umbral, y dicho aumento se va reduciendo al alejarse del umbral.
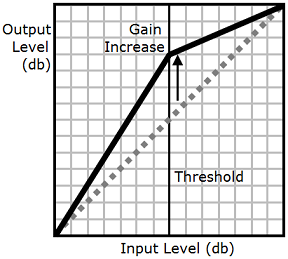
Esto facilita la audición de los sonidos de rango medio en un entorno ruidoso, lo que permite que todo el archivo de audio se oiga con más claridad.
La etiqueta drc es un parámetro booleano (está presente o no lo está). Utiliza la sintaxis: <amazon:effect name="drc"> y se cierra con </amazon:effect>.
Puede utilizar la etiqueta drc con cualquier voz o idioma compatible con Amazon Polly. Puede aplicarla a una sección entera de la grabación o solo a unas pocas palabras. Por ejemplo:
<speak> Some audio is difficult to hear in a moving vehicle, but <amazon:effect name="drc"> this audio is less difficult to hear in a moving vehicle.</amazon:effect> </speak>
nota
Si utiliza "drc" en la sintaxis , esta distingue entre mayúsculas y minúsculas.amazon:effect
Uso de drc con la etiqueta prosody
volume
Como muestra el siguiente gráfico, la etiqueta prosody
volume aumenta de manera uniforme el volumen de un archivo de audio desde el nivel original (línea discontinua) a un nivel ajustado (línea continua). Para aumentar aún más el volumen de determinadas partes del archivo, utilice la etiqueta drc con la etiqueta prosody
volume. La combinación de etiquetas no afecta a la configuración de la etiqueta prosody volume.
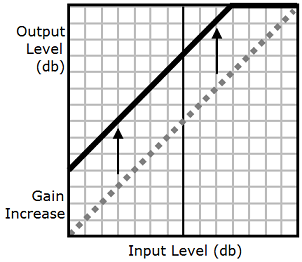
Cuando se utilizan las etiquetas drc y prosody
volume juntas, Amazon Polly aplica primero la etiqueta drc, aumentando los sonidos de rango medio (los que están cerca del umbral). A continuación, aplica la etiqueta prosody volume y aumenta el volumen de toda la pista de audio de manera uniforme.
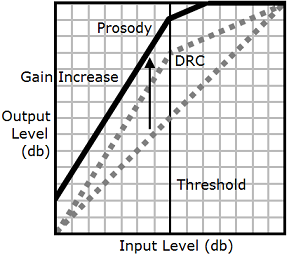
Para utilizar las etiquetas juntas, anide una dentro de la otra. Por ejemplo:
<speak> <prosody volume="loud">This text needs to be understandable and loud. <amazon:effect name="drc"> This text also needs to be more understandable in a moving car.</amazon:effect></prosody> </speak>
En este texto, la etiqueta prosody volume establece el nivel de volumen de todo el pasaje en "loud" (alto). La etiqueta drc mejora el volumen de los valores de rango medio de la segunda frase.
nota
Cuando utilice las etiquetas drc y prosody
volume juntas, emplee las prácticas estándar de XML para el anidado de etiquetas.
Habla de forma suave
<amazon:effect phonation="soft">
Esta etiqueta solo es compatible actualmente con el formato TTS estándar.
<amazon:effect phonation="soft">Para especificar que el texto introducido debe pronunciarse por softer-than-normal voz, utilice la etiqueta.
Se utiliza esta sintaxis:
<amazon:effect phonation="soft">text</amazon:effect>Por ejemplo, puede utilizar esta etiqueta con la voz de Matthew tal y como se indica a continuación:
<speak> This is Matthew speaking in my normal voice. <amazon:effect phonation="soft">This is Matthew speaking in my softer voice.</amazon:effect> </speak>
Control del timbre
<amazon:effect > vocal-tract-length
Esta etiqueta solo es compatible actualmente con el formato TTS estándar.
El timbre es la calidad tonal de una voz que permite diferenciar entre voces distintas, aunque todas tengan el mismo tono y volumen. Una de las características fisiológicas más importantes que contribuye al timbre de voz es la longitud del tracto vocal. El tracto vocal es una cavidad de aire que se extiende desde la parte superior de las cuerdas vocales hasta el borde de los labios.
Para controlar el timbre del fragmento hablado en Amazon Polly, utilice la etiqueta vocal-tract-length. Esta etiqueta tiene el efecto de modificar la longitud del tracto vocal del altavoz, lo que hace que este suene como si hubiese cambiado de tamaño. Al aumentar el valor de vocal-tract-length, el altavoz suena como si fuera físicamente más grande. Al reducirlo, el altavoz suena como si fuera más pequeño. Puede utilizar esta etiqueta con todas las voces del catálogo de conversión de texto a voz de Amazon Polly.
Para cambiar el timbre, utilice los siguientes valores:
-
+n%o-n%: ajusta la longitud del tracto vocal aplicando un cambio de porcentaje relativo a la voz actual. Por ejemplo, +4% o -2%. Los valores válidos están comprendidos entre +100% y -50%. Los valores que están fuera de este intervalo se recortan. Por ejemplo, +111% suena como +100% y -60% suena como -50%. -
n%: cambia la longitud del tracto vocal en un porcentaje absoluto de la longitud del tracto de la voz actual. Por ejemplo, 110% o 75%. Un valor absoluto del 110% equivale a un valor relativo de +10%. Un valor absoluto del 100% equivale al valor predeterminado para la voz actual.
El siguiente ejemplo muestra cómo modificar la longitud del tracto vocal para cambiar el timbre:
<speak> This is my original voice, without any modifications. <amazon:effect vocal-tract-length="+15%"> Now, imagine that I am much bigger. </amazon:effect> <amazon:effect vocal-tract-length="-15%"> Or, perhaps you prefer my voice when I'm very small. </amazon:effect> You can also control the timbre of my voice by making minor adjustments. <amazon:effect vocal-tract-length="+10%"> For example, by making me sound just a little bigger. </amazon:effect><amazon:effect vocal-tract-length="-10%"> Or, making me sound only somewhat smaller. </amazon:effect> </speak>
Combinación de varias etiquetas
Puede combinar la etiqueta vocal-tract-length con cualquier otra etiqueta SSML compatible con Amazon Polly. Dado que el timbre (longitud del tracto vocal) y el tono están íntimamente relacionados, es probable que obtenga resultados óptimos si utiliza las etiquetas vocal-tract-length y <prosody
pitch>. Para crear la voz más realista, le recomendamos utilizar diferentes porcentajes de cambio para ambas etiquetas. Experimente con varias combinaciones para obtener los resultados que desea.
El siguiente ejemplo muestra cómo combinar etiquetas.
<speak> The pitch and timbre of a person's voice are connected in human speech. <amazon:effect vocal-tract-length="-15%"> If you are going to reduce the vocal tract length, </amazon:effect><amazon:effect vocal-tract-length="-15%"> <prosody pitch="+20%"> you might consider increasing the pitch, too. </prosody></amazon:effect> <amazon:effect vocal-tract-length="+15%"> If you choose to lengthen the vocal tract, </amazon:effect> <amazon:effect vocal-tract-length="+15%"> <prosody pitch="-10%"> you might also want to lower the pitch. </prosody></amazon:effect> </speak>
Susurros
<amazon:effect name="whispered">
Esta etiqueta solo es compatible actualmente con el formato TTS estándar.
Esta etiqueta indica que la entrada de texto debe leerse en susurros y no con voz normal. Puede utilizarse con todas las voces del catálogo de conversión de texto a voz de Amazon Polly.
Utiliza la siguiente sintaxis:
<amazon:effect name="whispered">text</amazon:effect>Por ejemplo:
<speak> <amazon:effect name="whispered">If you make any noise, </amazon:effect> she said, <amazon:effect name="whispered">they will hear us.</amazon:effect> </speak>
En este caso, la parte del discurso que dice el personaje se leerá en susurros, mientras que la frase "she said" se leerá de forma normal con la voz de Amazon Polly elegida.
Puede mejorar el efecto de "susurro" ralentizando el ritmo prosódico hasta en un 10%, en función del efecto deseado.
Por ejemplo:
<speak> When any voice is made to whisper, <amazon:effect name="whispered"> <prosody rate="-10%">the sound is slower and quieter than normal speech </prosody></amazon:effect> </speak>
Cuando se generan las comillas para una voz susurrada, la secuencia de audio debe incluir también la voz susurrada para garantizar que las comillas coinciden con la secuencia de audio.
