Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Patrón de aprovisionamiento de eventos
Intención
En las arquitecturas basadas en eventos, el patrón de aprovisionamiento de eventos almacena los eventos que provocan un cambio de estado en un almacén de datos. Esto ayuda a capturar y mantener un historial completo de los cambios de estado y promueve la auditabilidad, la trazabilidad y la capacidad de analizar los estados pasados.
Motivación
Varios microservicios pueden colaborar para gestionar las solicitudes y se comunican a través de eventos. Estos eventos pueden provocar un cambio de estado (datos). El almacenamiento de los objetos de eventos en el orden en que se producen proporciona información valiosa sobre el estado actual de la entidad de datos e información adicional sobre cómo llegó a ese estado.
Aplicabilidad
Utilice el patrón de aprovisionamiento de eventos cuando:
-
Para el seguimiento, se requiere un historial inmutable de los eventos que se producen en una aplicación.
-
Las proyecciones de datos políglotas se requieren a partir de una fuente única de información fiable (SSOT).
-
Point-in se necesita una reconstrucción temporal del estado de la aplicación.
-
Long-term no es necesario almacenar el estado de la aplicación, pero es posible que desee reconstruirlo según sea necesario.
-
Las cargas de trabajo tienen diferentes volúmenes de lectura y escritura. Por ejemplo, tiene cargas de trabajo de escritura intensiva que no requieren procesamiento en tiempo real.
-
La captura de datos de cambios (CDC) es necesaria para analizar el rendimiento de las aplicaciones y otras métricas.
-
Los datos de auditoría son necesarios para todos los eventos que ocurren en un sistema con fines de presentación de informes y cumplimiento.
-
Para obtener escenarios hipotéticos, cambie (inserte, actualice o elimine) los eventos durante el proceso de reproducción para determinar el posible estado final.
Problemas y consideraciones
-
Control de simultaneidad optimista: este patrón almacena todos los eventos que provocan un cambio de estado en el sistema. Varios usuarios o servicios pueden intentar actualizar el mismo dato al mismo tiempo, lo que provoca colisiones de eventos. Estas colisiones se producen cuando se crean y aplican eventos conflictivos al mismo tiempo, lo que da como resultado un estado final de los datos que no se corresponde con la realidad. Para solucionar este problema, puede implementar estrategias para detectar y resolver las colisiones de eventos. Por ejemplo, puede implementar un esquema de control de simultaneidad optimista incluyendo el control de versiones o agregando marcas de tiempo a los eventos para hacer un seguimiento del orden de las actualizaciones.
-
Complejidad: la implementación del aprovisionamiento de eventos requiere un cambio de mentalidad, pasando de las operaciones tradicionales de CRUD a una mentalidad basada en eventos. El proceso de reproducción, que se utiliza para restaurar el sistema a su estado original, puede resultar complejo para garantizar la idempotencia de los datos. El almacenamiento de eventos, las copias de seguridad y las instantáneas también pueden añadir complejidad adicional.
-
Coherencia de eventos: las proyecciones de datos derivadas de los eventos son coherentes finalmente debido a la latencia en la actualización de los datos mediante el patrón de división de responsabilidades por consultas de comandos (CQRS) o vistas materializadas. Cuando los consumidores procesan datos de un almacén de eventos y los editores envían nuevos datos, es posible que la proyección de datos o el objeto de la aplicación no representen el estado actual.
-
Consultas: la recuperación de datos actuales o agregados de los registros de eventos puede ser más compleja y lenta en comparación con las bases de datos tradicionales, especialmente para consultas complejas y tareas de generación de informes. Para mitigar este problema, el aprovisionamiento de eventos se suele implementar con el patrón CQRS.
-
Tamaño y costo del almacén de eventos: el almacén de eventos puede experimentar un crecimiento exponencial debido a la persistencia continua de los eventos, especialmente en sistemas con un alto rendimiento de eventos o periodos de retención prolongados. Por lo tanto, debe archivar periódicamente los datos de los eventos en un almacenamiento rentable para evitar que el almacén de eventos se agrande demasiado.
-
Escalabilidad del almacén de eventos: el almacén de eventos debe gestionar de manera eficiente grandes volúmenes de operaciones de escritura y lectura. Escalar un almacén de eventos puede resultar difícil, por lo que es importante contar con un almacén de datos que proporcione particiones.
-
Eficiencia y optimización: elija o diseñe un almacén de eventos que gestione las operaciones de escritura y lectura de forma eficiente. El almacén de eventos debe optimizarse para el volumen de eventos y los patrones de consulta esperados para la aplicación. La implementación de mecanismos de indexación y consulta puede acelerar la recuperación de eventos al reconstruir el estado de la aplicación. También puede considerar la posibilidad de utilizar bibliotecas o bases de datos de almacenes de eventos especializadas que ofrezcan características de optimización de consultas.
-
Instantáneas: debe realizar copias de seguridad de los registros de eventos a intervalos regulares con una activación en función del tiempo. Si se reproducen los eventos de la última copia de seguridad correcta de la que se tenga constancia, se recuperará el estado de la aplicación en un momento dado. El objetivo de punto de recuperación (RPO) es el tiempo máximo aceptable desde el último punto de recuperación de datos. El RPO determina qué se considera una pérdida de datos aceptable entre el último punto de recuperación y la interrupción del servicio. La frecuencia de las instantáneas diarias del almacén de datos y eventos debe basarse en el RPO de la aplicación.
-
Sensibilidad temporal: los eventos se almacenan en el orden en que se producen. Por lo tanto, la fiabilidad de la red es un factor importante a tener en cuenta al implementar este patrón. Los problemas de latencia pueden provocar un estado incorrecto del sistema. Utilice las colas “primero en entrar, primero en salir” (FIFO, por sus siglas en inglés) con una entrega como máximo para llevar los eventos al almacén de eventos.
-
Rendimiento de reproducción de eventos: reproducir un número considerable de eventos para reconstruir el estado actual de la aplicación puede llevar mucho tiempo. Se requieren esfuerzos de optimización para mejorar el rendimiento, especialmente cuando se reproducen eventos a partir de datos archivados.
-
Actualizaciones externas del sistema: las aplicaciones que utilizan el patrón de aprovisionamiento de eventos pueden actualizar los almacenes de datos de sistemas externos y capturar estas actualizaciones como objetos de eventos. Durante la reproducción de los eventos, esto podría convertirse en un problema si el sistema externo no espera ninguna actualización. En esos casos, puede utilizar los indicadores de características para controlar las actualizaciones externas del sistema.
-
Consultas al sistema externo: cuando las llamadas al sistema externo son sensibles a la fecha y hora de la llamada, los datos recibidos se pueden almacenar en almacenes de datos internos para utilizarlos durante las reproducciones.
-
Control de versiones de eventos: a medida que la aplicación evoluciona, la estructura de los eventos (esquema) puede cambiar. Es necesario implementar una estrategia de control de versiones para los eventos a fin de garantizar la compatibilidad con versiones anteriores y posteriores. Esto puede implicar la inclusión de un campo de versión en la carga útil del evento y la gestión de las diferentes versiones del evento de forma adecuada durante la reproducción.
Implementación
High-level arquitectura
Comandos y eventos
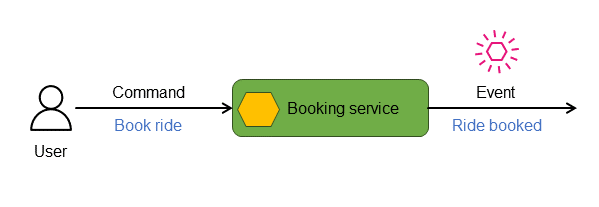
En las aplicaciones de microservicios distribuidas y basadas en eventos, los comandos representan las instrucciones o solicitudes enviadas a un servicio, normalmente con la intención de iniciar un cambio en su estado. El servicio procesa estos comandos y evalúa su validez y aplicabilidad en su estado actual. Si el comando se ejecuta correctamente, el servicio responde emitiendo un evento que indica la acción realizada y la información de estado relevante. Por ejemplo, en el siguiente diagrama, el servicio de reservas responde al comando Reservar viaje emitiendo el evento Viaje reservado.
Almacenes de eventos
Los eventos se registran en un repositorio o almacén de datos inmutable, solo de anexos y ordenado cronológicamente, conocido como almacén de eventos. Cada cambio de estado se trata como un objeto de evento individual. Un objeto de entidad o un almacén de datos con un estado inicial conocido, su estado actual y cualquier vista en un momento dado se pueden reconstruir reproduciendo los eventos en el orden en que se produjeron.
El almacén de eventos actúa como un registro histórico de todas las acciones y cambios de estado, y sirve como una valiosa fuente única de información fiable. Puede utilizar el almacén de eventos para obtener el estado final y actualizado del sistema pasando los eventos por un procesador de reproducción, que los aplica para producir una representación precisa del estado más reciente del sistema. También puede utilizar el almacén de eventos para generar una perspectiva en un momento dado del estado mediante la reproducción de los eventos a través de un procesador de reproducción. En el patrón de aprovisionamiento de eventos, es posible que el estado actual no esté completamente representado por el objeto de evento más reciente. Puede obtener el estado actual de tres maneras:
-
Mediante la agregación de eventos relacionados. Los objetos de eventos relacionados se combinan para generar el estado actual para la consulta. Este enfoque se suele utilizar junto con el patrón CQRS, ya que los eventos se combinan y se escriben en el almacén de datos de solo lectura.
-
Mediante el uso de vistas materializadas. Puede utilizar el aprovisionamiento de eventos con el patrón de vista materializada para calcular o resumir los datos del evento y obtener el estado actual de los datos relacionados.
-
Mediante la reproducción de eventos. Los objetos de eventos se pueden reproducir para llevar a cabo acciones que generen el estado actual.
El siguiente diagrama muestra el evento Ride booked almacenado en un almacén de eventos.

El almacén de eventos publica los eventos que almacena, y los eventos se pueden filtrar y enrutar al procesador correspondiente para realizar acciones posteriores. Por ejemplo, los eventos se pueden enrutar a un procesador de vistas que resuma el estado y muestre una vista materializada. Los eventos se transforman al formato de datos del almacén de datos de destino. Esta arquitectura se puede ampliar para derivar diferentes tipos de almacenes de datos, lo que conduce a una persistencia políglota de los datos.
En el diagrama siguiente, se describen los eventos de una aplicación de reserva de viajes. Todos los eventos que se producen en la aplicación se almacenan en el almacén de eventos. A continuación, los eventos almacenados se filtran y se envían a diferentes consumidores.
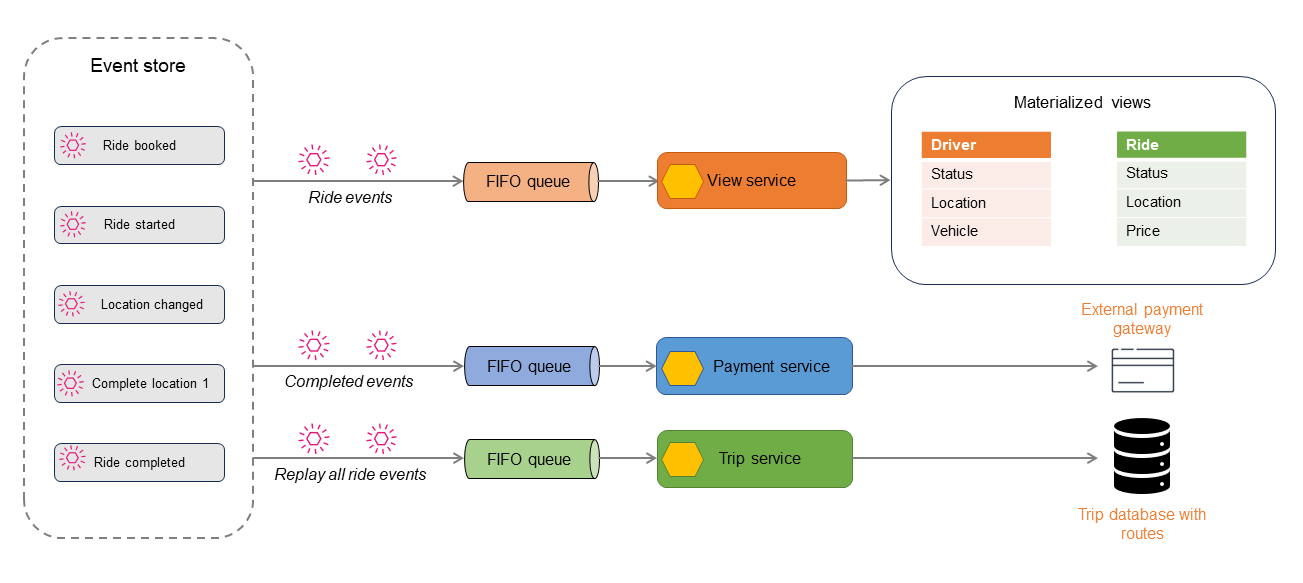
Los eventos de los viajes se pueden utilizar para generar almacenes de datos de solo lectura mediante el CQRS o el patrón de vista materializada. Para obtener el estado actual del viaje, del conductor o de la reserva, consulte los almacenes de lectura. Algunos eventos, como Location changed o Ride completed, se publican para otro consumidor para el procesamiento de pagos. Cuando se completa el viaje, todos los eventos del viaje se reproducen para crear un historial del viaje con fines de auditoría o elaboración de informes.
El patrón de aprovisionamiento de eventos se utiliza con frecuencia en aplicaciones que requieren una recuperación en un momento dado y también cuando los datos deben proyectarse en diferentes formatos utilizando una fuente única de información fiable. Ambas operaciones requieren un proceso de reproducción para ejecutar los eventos y obtener el estado final requerido. Es posible que el procesador de reproducción también requiera un punto de partida conocido, idealmente no desde el inicio de la aplicación, ya que no sería un proceso eficiente. Le recomendamos que tome instantáneas periódicas del estado del sistema y aplique un número menor de eventos para obtener un estado actualizado.
Implementación mediante los servicios de AWS
En la siguiente arquitectura, Amazon Kinesis Data Streams se utiliza como almacén de eventos. Este servicio captura y administra los cambios en las aplicaciones como eventos y ofrece una solución de flujo de datos en tiempo real y de alto rendimiento. Para implementar el patrón de abastecimiento de eventos en AWS, también puede utilizar servicios como Amazon EventBridge y Amazon Managed Streaming for Apache Kafka Kafka (Amazon MSK) en función de las necesidades de su aplicación.
Para mejorar la durabilidad y habilitar la auditoría, puede archivar los eventos capturados por Kinesis Data Streams en Amazon Simple Storage Service (Amazon S3). Este enfoque de almacenamiento doble ayuda a retener los datos de eventos históricos de forma segura para futuros análisis y fines de cumplimiento.
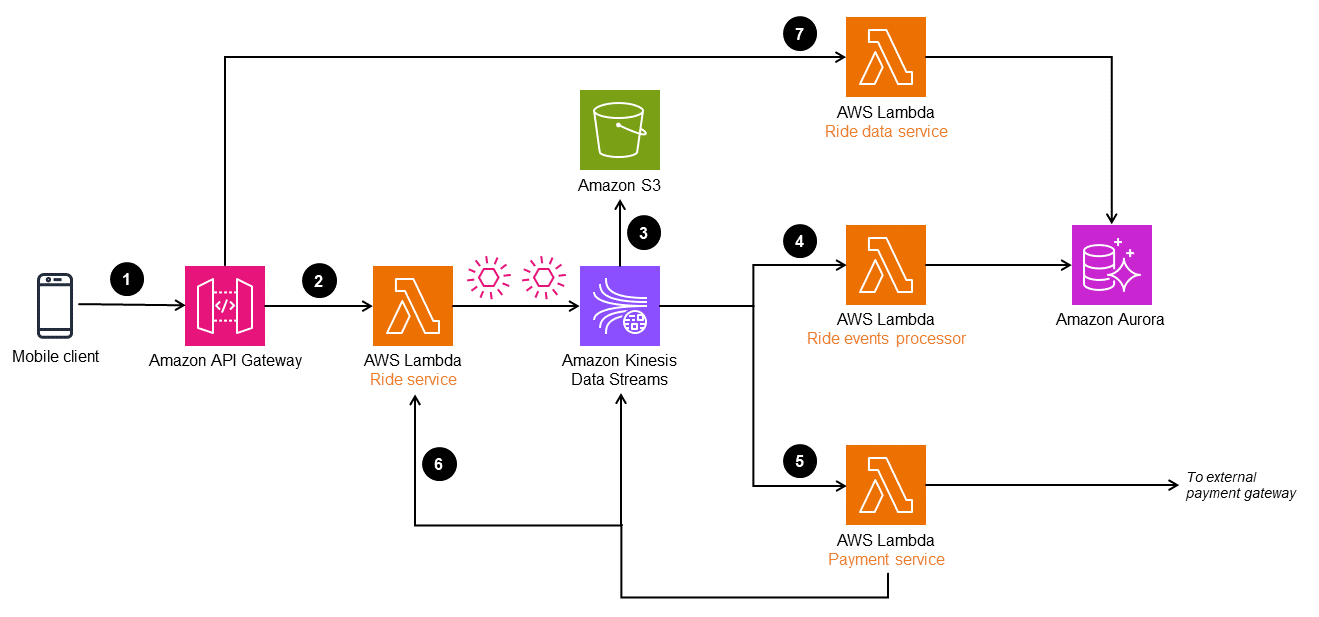
El flujo de trabajo consta de los siguientes pasos:
-
La solicitud de reserva de un viaje se realiza a través de un cliente móvil a un punto de conexión de Amazon API Gateway.
-
El microservicio de viajes (función de Lambda
Ride service) recibe la solicitud, transforma los objetos y los publica en Kinesis Data Streams. -
Los datos de eventos de Kinesis Data Streams se almacenan en Amazon S3 con fines de cumplimiento e historial de auditoría.
-
La función de Lambda
Ride event processortransforma y procesa los eventos y los almacena en una base de datos de Amazon Aurora para proporcionar una vista materializada de los datos del viaje. -
Los eventos de viajes completados se filtran y se envían para su procesamiento a una puerta de enlace de pago externa. Cuando se haya completado el pago, se enviará otro evento a Kinesis Data Streams para actualizar la base de datos del viaje.
-
Cuando se completa el viaje, los eventos del viaje se reproducen en la función de Lambda
Ride servicepara crear las rutas y el historial del viaje. -
La información sobre los viajes se puede leer a través del
Ride data service, que se lee en la base de datos de Aurora.
API Gateway también puede enviar el objeto de evento directamente a Kinesis Data Streams sin la función de Lambda Ride service. Sin embargo, en un sistema complejo, como un servicio de transporte privado, es posible que sea necesario procesar y enriquecer el objeto del evento antes de incorporarlo al flujo de datos. Por este motivo, la arquitectura tiene un Ride service que procesa el evento antes de enviarlo a Kinesis Data Streams.
Referencias de blogs
