Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
# Implemente un caso de uso de RAG AWS mediante Terraform y Amazon Bedrock
*Martin Maritsch, Nicolas Jacob Baer, Olivier Brique, Julian Ferdinand Grueber, Alice Morano y Nicola D Orazio, Amazon Web Services*
## Resumen
AWS ofrece varias opciones para crear sus casos de uso de IA generativa habilitados para la [generación aumentada de recuperación (RAG).](https://aws.amazon.com/what-is/retrieval-augmented-generation/) Este patrón le proporciona una solución para una aplicación basada en RAG basada en LangChain y compatible con Amazon Aurora PostgreSQL como almacén vectorial. Puede implementar directamente esta solución con Terraform en su RAG Cuenta de AWS e implementar el siguiente caso de uso sencillo:
1. El usuario carga un archivo de forma manual en un bucket de Amazon Simple Storage Service (Amazon S3), como un archivo de Microsoft Excel o un documento PDF. (Para obtener más información sobre los tipos de archivos compatibles, consulte la documentación de [Unstructured](https://docs.unstructured.io/open-source/core-functionality/partitioning) [Sin estructurar]).
1. El contenido del archivo se extrae y se incrusta en una base de datos de conocimiento basada en Aurora sin servidor compatible con PostgreSQL, que permite la ingesta de documentos casi en tiempo real en el almacén vectorial. Este enfoque permite al modelo de RAG acceder a la información relevante y recuperarla para casos de uso en los que las bajas latencias son importantes.
1. Cuando el usuario utiliza el modelo de generación de texto, mejora la interacción al recuperar y aumentar el contenido relevante de los archivos cargados anteriormente.
El patrón utiliza [Amazon Titan Text Embeddings v2](https://docs.aws.amazon.com/bedrock/latest/userguide/titan-embedding-models.html) como modelo de incrustación y [Anthropic Claude 3 Sonnet](https://aws.amazon.com/bedrock/claude/) como modelo de generación de texto, ambos disponibles en Amazon Bedrock.
## Requisitos previos y limitaciones
**Requisitos previos **
+ Un activo. Cuenta de AWS
+ AWS Command Line Interface (AWS CLI) instalado y configurado con su Cuenta de AWS. Para obtener instrucciones de instalación, consulte [Instalar o actualizar a la última versión de AWS CLI en la](https://docs.aws.amazon.com/cli/latest/userguide/install-cliv2.html) AWS CLI documentación. Para revisar sus AWS credenciales y el acceso a su cuenta, consulte los [ajustes de configuración y del archivo de credenciales](https://docs.aws.amazon.com/cli/latest/userguide/cli-configure-files.html) en la AWS CLI documentación.
+ Acceso al modelo que está habilitado para los modelos de idiomas grandes requeridos (LLMs) en la consola Amazon Bedrock de su Cuenta de AWS. Este patrón requiere lo siguiente: LLMs
+ `amazon.titan-embed-text-v2:0`
+ `anthropic.claude-3-sonnet-20240229-v1:0`
**Limitaciones**
+ Esta arquitectura de ejemplo no incluye una interfaz para responder preguntas mediante programación con la base de datos vectorial. Si su caso de uso requiere una API, considere añadir [Amazon API Gateway](https://docs.aws.amazon.com/apigateway/latest/developerguide) con una AWS Lambda función que ejecute tareas de recuperación y respuesta a preguntas.
+ Este ejemplo de arquitectura no incluye características de supervisión para la infraestructura implementada. Si su caso de uso requiere supervisión, considere la posibilidad de añadir [servicios de supervisión de AWS](https://docs.aws.amazon.com/prescriptive-guidance/latest/implementing-logging-monitoring-cloudwatch/welcome.html).
+ Si carga muchos documentos en poco tiempo al bucket de Amazon S3, es posible que la función de Lambda encuentre límites de tasas. Como solución, puede desacoplar la función de Lambda de una cola de Amazon Simple Queue Service (Amazon SQS) donde pueda controlar la frecuencia de las invocaciones de Lambda.
+ Algunas Servicios de AWS no están disponibles en todos. Regiones de AWS Para obtener información sobre la disponibilidad en regiones, consulte [Servicios de AWS by Region](https://aws.amazon.com/about-aws/global-infrastructure/regional-product-services/). Para ver los puntos de conexión específicos, consulte [Service endpoints and quotas](https://docs.aws.amazon.com/general/latest/gr/aws-service-information.html) y elija el enlace del servicio.
**Versiones de producto**
+ [AWS CLI](https://docs.aws.amazon.com/cli/latest/userguide/getting-started-install.html) versión 2 o posterior
+ La versión 26.0.0 o posterior de [Docker](https://docs.docker.com/get-started/)
+ [Poetry](https://pypi.org/project/poetry/) versión 1.7.1 o posterior
+ [Python](https://www.python.org/downloads/) versión 3.10 o posterior
+ La versión 1.8.4 o posterior de [Terraform](https://developer.hashicorp.com/terraform/install)
## Arquitectura
En el siguiente diagrama se muestran los componentes de la arquitectura y el flujo de trabajo de esta aplicación.
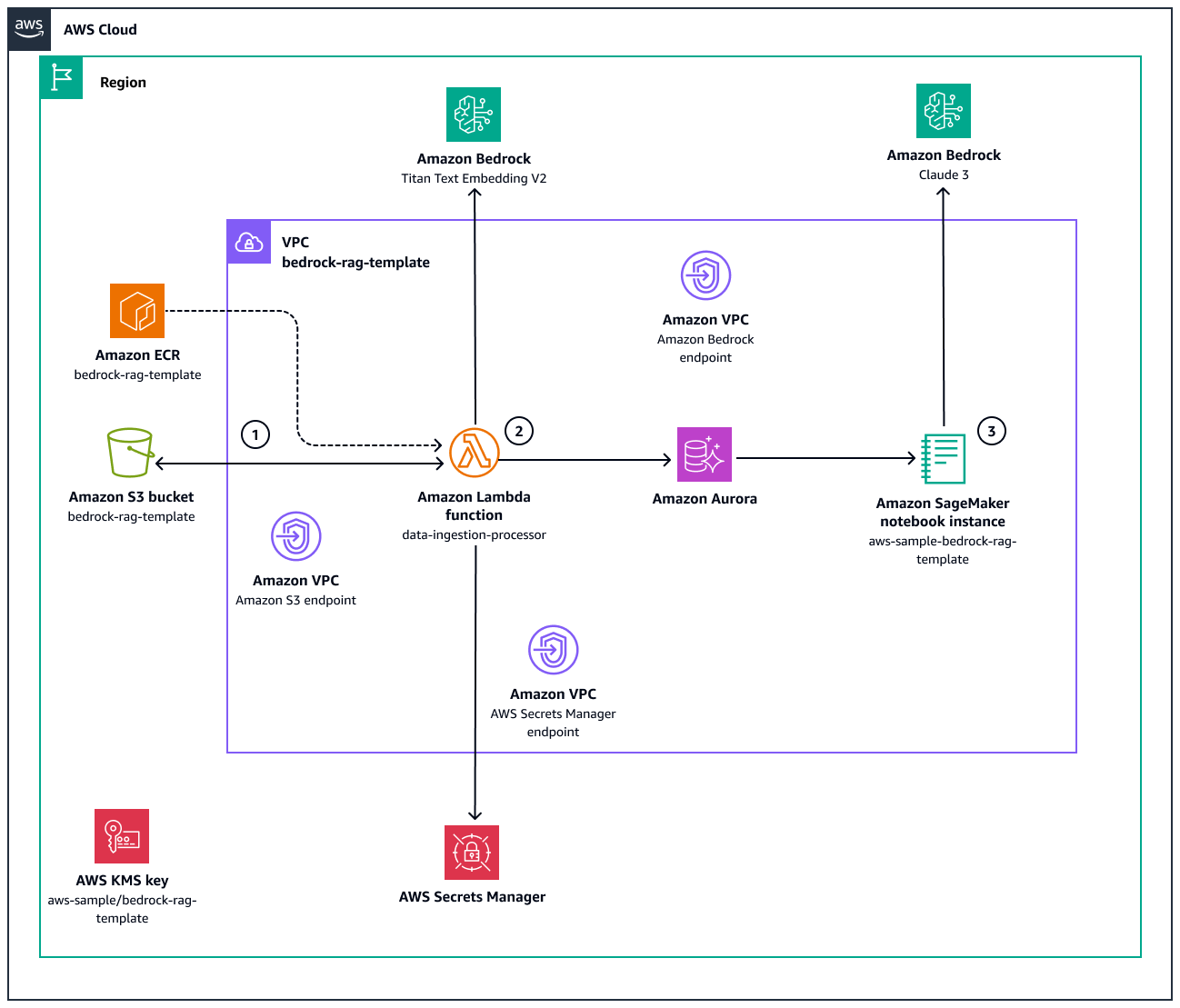
Este diagrama ilustra lo siguiente:
1. Cuando se crea un objeto en el bucket `bedrock-rag-template-` de Amazon S3, una [notificación de Amazon S3](https://docs.aws.amazon.com/AmazonS3/latest/userguide/EventNotifications.html) invoca la función de Lambda `data-ingestion-processor`.
1. La función de Lambda `data-ingestion-processor` se basa en una imagen de Docker almacenada en el repositorio Amazon Elastic Container Registry (Amazon ECR) `bedrock-rag-template`.
[La función usa el [LangChain S3 FileLoader](https://python.langchain.com/v0.1/docs/integrations/document_loaders/aws_s3_file/) para leer el archivo como un documento. LangChain ](https://api.python.langchain.com/en/v0.0.339/schema/langchain.schema.document.Document.html) Luego, divide [LangChain RecursiveCharacterTextSplitter](https://python.langchain.com/v0.1/docs/modules/data_connection/document_transformers/recursive_text_splitter/)cada documento, con una `CHUNK_SIZE` y una `CHUNK_OVERLAP` que dependen del tamaño máximo del token del modelo de incrustación Amazon Titan Text Embedding V2. A continuación, la función de Lambda invoca el modelo de incrustación de Amazon Bedrock para incrustar los fragmentos en representaciones vectoriales numéricas. Por último, estos vectores se almacenan en la base de datos de Aurora PostgreSQL. Para acceder a la base de datos, la función Lambda recupera primero el nombre de usuario y la contraseña de. AWS Secrets Manager
1. En la [instancia de Amazon SageMaker AI notebook](https://docs.aws.amazon.com/sagemaker/latest/dg/nbi.html)`aws-sample-bedrock-rag-template`, el usuario puede escribir un mensaje de pregunta. El código invoca Claude 3 en Amazon Bedrock y añade la información de la base de conocimientos al contexto de la petición. Como resultado, Claude 3 proporciona respuestas utilizando la información de los documentos.
El enfoque de este patrón con respecto a las redes y la seguridad es el siguiente:
+ La función de Lambda `data-ingestion-processor` se encuentra en una subred privada dentro de la nube privada virtual (VPC). La función de Lambda no puede enviar tráfico a la Internet pública debido a su grupo de seguridad. Como resultado, el tráfico a Amazon S3 y Amazon Bedrock se enruta únicamente a través de los puntos de conexión de VPC. Por lo tanto, el tráfico no atraviesa la red pública de Internet, lo que reduce la latencia y añade una capa adicional de seguridad a nivel de red.
+ Todos los recursos y datos se cifran siempre que sea posible mediante la clave AWS Key Management Service (AWS KMS) con el alias`aws-sample/bedrock-rag-template`.
**Automatización y escala**
Este patrón utiliza Terraform para implementar la infraestructura del repositorio de código en una Cuenta de AWS.
## Tools (Herramientas)
**Servicios de AWS**
+ La [edición de Amazon Aurora compatible con PostgreSQL](https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/Aurora.AuroraPostgreSQL.html) es un motor de base de datos relacional compatible con ACID, completamente administrado que le permite configurar, utilizar y escalar implementaciones de PostgreSQL. En este patrón, Aurora compatible con PostgreSQL utiliza el complemento pgvector como base de datos vectorial.
+ [Amazon Bedrock](https://docs.aws.amazon.com/bedrock/latest/userguide/what-is-bedrock.html) es un servicio totalmente gestionado que pone a su disposición modelos básicos de alto rendimiento (FMs) de las principales empresas emergentes de IA y Amazon a través de una API unificada.
+ [AWS Command Line Interface (AWS CLI)](https://docs.aws.amazon.com/cli/latest/userguide/cli-chap-welcome.html) es una herramienta de código abierto que le ayuda a interactuar Servicios de AWS mediante comandos en su consola de línea de comandos.
+ [Amazon Elastic Container Registry (Amazon ECR)](https://docs.aws.amazon.com/AmazonECR/latest/userguide/what-is-ecr.html) es un servicio de registro de imágenes de contenedor administrado que es seguro, escalable y fiable. En este patrón, Amazon ECR aloja la imagen de Docker para la función de Lambda `data-ingestion-processor`.
+ [AWS Identity and Access Management (IAM)](https://docs.aws.amazon.com/IAM/latest/UserGuide/introduction.html) le ayuda a administrar de forma segura el acceso a sus AWS recursos al controlar quién está autenticado y autorizado a usarlos.
+ [AWS Key Management Service (AWS KMS)](https://docs.aws.amazon.com/kms/latest/developerguide/overview.html) lo ayuda a crear y controlar claves criptográficas que ayudan a proteger los datos.
+ [AWS Lambda](https://docs.aws.amazon.com/lambda/latest/dg/welcome.html) es un servicio de computación que ayuda a ejecutar código sin necesidad de aprovisionar ni administrar servidores. Ejecuta el código solo cuando es necesario y amplía la capacidad de manera automática, por lo que solo pagará por el tiempo de procesamiento que utilice. En este patrón, Lambda ingiere datos en el almacén vectorial.
+ [Amazon SageMaker AI](https://docs.aws.amazon.com/sagemaker/?id=docs_gateway) es un servicio de aprendizaje automático (ML) gestionado que le ayuda a crear y entrenar modelos de aprendizaje automático para luego implementarlos en un entorno hospedado listo para la producción.
+ [AWS Secrets Manager](https://docs.aws.amazon.com/secretsmanager/latest/userguide/intro.html) lo ayuda a reemplazar las credenciales codificadas en su código, incluidas contraseñas, con una llamada a la API de Secrets Manager para recuperar el secreto mediante programación.
+ [Amazon Simple Storage Service (Amazon S3)](https://docs.aws.amazon.com/AmazonS3/latest/userguide/Welcome.html) es un servicio de almacenamiento de objetos basado en la nube que lo ayuda a almacenar, proteger y recuperar cualquier cantidad de datos.
+ [Amazon Virtual Private Cloud (Amazon VPC)](https://docs.aws.amazon.com/vpc/latest/userguide/what-is-amazon-vpc.html) le ayuda a lanzar AWS recursos en una red virtual que haya definido. Esa red virtual es similar a la red tradicional que utiliza en su propio centro de datos, con los beneficios de usar la infraestructura escalable de AWS. La VPC incluye subredes y tablas de enrutamiento para controlar el flujo de tráfico.
**Otras herramientas**
+ [Docker](https://docs.docker.com/manuals/) es un conjunto de productos de plataforma como servicio (PaaS) que utiliza la virtualización a nivel del sistema operativo para entregar software en contenedores.
+ [HashiCorp Terraform](https://www.terraform.io/docs) es una herramienta de infraestructura como código (IaC) que facilita usar el código para aprovisionar y administrar los recursos y la infraestructura en la nube.
+ [Poetry](https://pypi.org/project/poetry/) es una herramienta de empaquetado y administración de dependencias de Python.
+ [Python](https://www.python.org/) es un lenguaje de programación informático de uso general.
**Repositorio de código**
El código de este patrón está disponible en el repositorio GitHub [terraform-rag-template-using-amazon-bedrock](https://github.com/aws-samples/terraform-rag-template-using-amazon-bedrock).
## Prácticas recomendadas
+ Aunque este ejemplo de código se puede implementar en cualquier Región de AWS lugar, le recomendamos que utilice US East (North Virginia) `us-east-1` o US West (North California). `us-west-1` Esta recomendación se basa en la disponibilidad de modelos de incrustación y fundacionales en Amazon Bedrock en el momento de la publicación de este patrón. Para obtener una up-to-date lista del soporte del modelo base de Amazon Bedrock Regiones de AWS, consulte [Soporte de modelos Región de AWS en la](https://docs.aws.amazon.com/bedrock/latest/userguide/models-regions.html) documentación de Amazon Bedrock. Para obtener información sobre cómo implementar este ejemplo de código en otras regiones, consulte la [información adicional](#deploy-rag-use-case-on-aws-additional).
+ Este patrón solo proporciona una proof-of-concept demostración (PoC) o piloto. Si desea llevar el código a producción, asegúrese de seguir las siguientes prácticas recomendadas:
+ Habilite el registro de acceso al servidor de Amazon S3.
+ Configure la [supervisión y las alertas](https://docs.aws.amazon.com/lambda/latest/dg/lambda-monitoring.html) para la función de Lambda.
+ Si su caso de uso requiere una API, considere añadir Amazon API Gateway con una función de Lambda que ejecute tareas de recuperación y respuesta a preguntas.
+ Siga el principio de privilegio mínimo y conceda los permisos mínimos necesarios para llevar a cabo una tarea. Para obtener más información, consulte [Otorgar privilegio mínimo](https://docs.aws.amazon.com/IAM/latest/UserGuide/access_policies.html#grant-least-priv) y [Prácticas recomendadas de seguridad](https://docs.aws.amazon.com/IAM/latest/UserGuide/IAMBestPracticesAndUseCases.html) en la documentación de IAM.
## Epics
### Implemente la solución en un Cuenta de AWS
| Tarea | Descripción | Habilidades requeridas |
| --- | --- | --- |
| Clonar el repositorio. | Para clonar el GitHub repositorio proporcionado con este patrón, utilice el siguiente comando:git clone https://github.com/aws-samples/terraform-rag-template-using-amazon-bedrock
| AWS DevOps |
| Configure las variables. | Para configurar los parámetros de este patrón, haga lo siguiente:[See the AWS documentation website for more details](http://docs.aws.amazon.com/es_es/prescriptive-guidance/latest/patterns/deploy-rag-use-case-on-aws.html) | AWS DevOps |
| Implemente la solución. | Para implementar la solución, haga lo siguiente:[See the AWS documentation website for more details](http://docs.aws.amazon.com/es_es/prescriptive-guidance/latest/patterns/deploy-rag-use-case-on-aws.html)
La implementación de la infraestructura aprovisiona una instancia de SageMaker IA dentro de la VPC y con los permisos para acceder a la base de datos PostgreSQL de Aurora. | AWS DevOps |
### Pruebe la solución
| Tarea | Descripción | Habilidades requeridas |
| --- | --- | --- |
| Ejecute la demostración. | Una vez que la implementación anterior de la infraestructura se haya realizado correctamente, siga estos pasos para ejecutar la demostración en cuaderno de Jupyter:[See the AWS documentation website for more details](http://docs.aws.amazon.com/es_es/prescriptive-guidance/latest/patterns/deploy-rag-use-case-on-aws.html)
El cuaderno de Jupyter le guía a través del siguiente proceso:[See the AWS documentation website for more details](http://docs.aws.amazon.com/es_es/prescriptive-guidance/latest/patterns/deploy-rag-use-case-on-aws.html) | AWS general |
### Limpieza de la infraestructura
| Tarea | Descripción | Habilidades requeridas |
| --- | --- | --- |
| Limpie la infraestructura. | Para eliminar todos los recursos que creó cuando ya no sean necesarios, utilice el siguiente comando:terraform destroy -var-file=commons.tfvars
| AWS DevOps |
## Recursos relacionados
**AWS resources**
+ [Creación de funciones de Lambda con Python](https://docs.aws.amazon.com/lambda/latest/dg/lambda-python.html)
+ [Parámetros de inferencia para modelos básicos](https://docs.aws.amazon.com/bedrock/latest/userguide/model-parameters.html)
+ [Acceso a los modelos fundacionales de Amazon Bedrock](https://docs.aws.amazon.com/bedrock/latest/userguide/model-access.html)
+ [El papel de las bases de datos vectoriales en las aplicaciones de IA generativa](https://aws.amazon.com/blogs/database/the-role-of-vector-datastores-in-generative-ai-applications/) (blog de bases AWS de datos)
+ [Uso de Amazon Aurora PostgreSQL](https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/Aurora.AuroraPostgreSQL.html)
**Otros recursos**
+ [Documentación de pgvector](https://github.com/pgvector/pgvector)
## Información adicional
**Implementación de una base de datos vectorial**
Este patrón utiliza Aurora compatible con PostgreSQL para implementar una base de datos vectorial para RAG. Como alternativa a Aurora PostgreSQL AWS , ofrece otras capacidades y servicios para RAG, como Amazon Bedrock Knowledge Bases y Amazon Service. OpenSearch Puede elegir la solución que mejor se adapte a sus requisitos específicos:
+ [Amazon OpenSearch Service](https://docs.aws.amazon.com/opensearch-service/latest/developerguide/what-is.html) proporciona motores de búsqueda y análisis distribuidos que puede utilizar para almacenar y consultar grandes volúmenes de datos.
+ [Las bases de conocimiento de Amazon Bedrock](https://docs.aws.amazon.com/bedrock/latest/userguide/knowledge-base.html) están diseñadas para crear e implementar bases de conocimiento como una abstracción adicional para simplificar el proceso de ingesta y recuperación de RAG. Las bases de conocimiento de Amazon Bedrock funcionan tanto con Aurora PostgreSQL como con Amazon Service. OpenSearch
**¿Implementar en otros Regiones de AWS**
Como se describe en [Arquitectura](#deploy-rag-use-case-on-aws-architecture), le recomendamos que utilice la región Este de EE. UU. (Norte de Virginia):`us-east-1` u Oeste de EE. UU. (Norte de California):`us-west-1` para implementar este ejemplo de código. Sin embargo, hay dos formas posibles de implementar este ejemplo de código en regiones distintas de `us-east-1` y `us-west-1`. Puede configurar la región de implementación en el archivo `commons.tfvars`. Para el acceso al modelo fundacional entre regiones, tenga en cuenta las opciones siguientes:
+ **Atravesar la Internet pública**: si el tráfico puede atravesar la Internet pública, añada puertas de enlace de Internet a la VPC. A continuación, ajuste el grupo de seguridad asignado a la función Lambda `data-ingestion-processor` y a la instancia de SageMaker AI notebook para permitir el tráfico saliente a la Internet pública.
+ **No atravesar la Internet pública**: para implementar este ejemplo en cualquier otra región que no sea `us-east-1` ni `us-west-1`, haga lo siguiente:
1. En la región `us-east-1` o `us-west-1`, cree una VPC adicional que incluya un punto de conexión de VPC para `bedrock-runtime`.
1. Cree una conexión de emparejamiento mediante el [emparejamiento de VPC](https://docs.aws.amazon.com/vpc/latest/peering/what-is-vpc-peering.html) o una [puerta de enlace de tránsito](https://docs.aws.amazon.com/vpc/latest/tgw/tgw-peering.html) a la VPC de la aplicación.
1. Al configurar el cliente `bedrock-runtime` de boto3 en cualquier función de Lambda fuera de `us-east-1` o `us-west-1`, pase el nombre de DNS privado del punto de conexión de VPC para `bedrock-runtime` en `us-east-1` o us-west-1 como `endpoint_url` al cliente de boto3.