Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Optimice las combinaciones
Algunas operaciones, como join() ygroupByKey(), requieren que Spark realice una mezcla aleatoria. La mezcla es el mecanismo de Spark para redistribuir los datos de forma que se agrupen de forma diferente en las particiones. RDD La reorganización puede ayudar a solucionar los cuellos de botella en el rendimiento. Sin embargo, dado que la mezcla suele implicar la copia de datos entre los ejecutores de Spark, la mezcla es una operación compleja y costosa. Por ejemplo, las mezclas generan los siguientes costes:
-
E/S de disco:
-
Genera una gran cantidad de archivos intermedios en el disco.
-
-
E/S de red:
-
Necesita muchas conexiones de red (número de conexiones =
Mapper × Reducer). -
Como los registros se agregan a nuevas RDD particiones que podrían estar alojadas en un ejecutor de Spark diferente, una parte sustancial del conjunto de datos podría moverse entre los ejecutores de Spark a través de la red.
-
-
CPUy carga de memoria:
-
Ordena los valores y fusiona conjuntos de datos. Estas operaciones se planifican en el ejecutor, lo que supone una gran carga para el ejecutor.
-
La reproducción aleatoria es uno de los factores más importantes en la degradación del rendimiento de tu aplicación Spark. Al almacenar los datos intermedios, puede agotar espacio en el disco local del ejecutor, lo que provoca un error en la tarea de Spark.
Puedes evaluar tu rendimiento de shuffle en CloudWatch las métricas y en la interfaz de usuario de Spark.
CloudWatch métricas
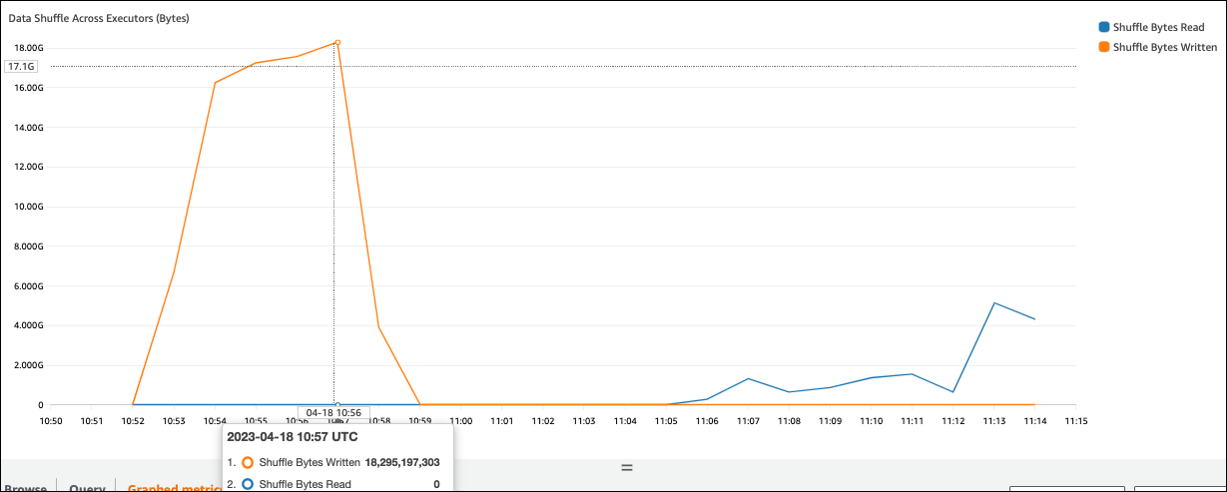
Si el valor de Shuffle Bytes Written es alto en comparación con Shuffle Bytes Read, tu trabajo de Spark podría utilizar operaciones de mezcla aleatoriajoin() groupByKey()
Interfaz de usuario de Spark
En la pestaña Stage de la interfaz de usuario de Spark, puedes comprobar los valores de tamaño de lectura aleatoria y de registros. También puedes verla en la pestaña Ejecutores.
En la siguiente captura de pantalla, cada ejecutor intercambia aproximadamente 18,6 GB/4020000 registros con el proceso de aleatorización, lo que supone un tamaño total de lectura aleatoria de unos 75 GB (aproximadamente).
La columna Shuffle Spill (Disco) muestra una gran cantidad de datos que se derrama en la memoria del disco, lo que puede provocar un disco lleno o un problema de rendimiento.

Si observas estos síntomas y la etapa tarda demasiado en comparación con tus objetivos de rendimiento, o si no funciona o presenta No space
left on device errores, considera las siguientes soluciones. Out Of Memory
Optimice la unión
La join() operación, que une tablas, es la operación de barajado más utilizada, pero suele suponer un obstáculo en el rendimiento. Como la unión es una operación costosa, le recomendamos no utilizarla a menos que sea esencial para los requisitos de su empresa. Haga las siguientes preguntas para comprobar que está haciendo un uso eficiente de su canalización de datos:
-
¿Está volviendo a calcular una unión que también se realiza en otras tareas que puede reutilizar?
-
¿Va a unirse para resolver las claves ajenas a los valores que no utilizan los consumidores de su producción?
Tras confirmar que las operaciones de unión son esenciales para los requisitos de su empresa, consulte las siguientes opciones para optimizar la unión de forma que se ajuste a sus requisitos.
Presiona hacia abajo antes de unirte
Filtre las filas y columnas innecesarias DataFrame antes de realizar una unión. Esto tiene las siguientes ventajas:
-
Reduce la cantidad de transferencia de datos durante la reproducción aleatoria
-
Reduce la cantidad de procesamiento en el ejecutor Spark
-
Reduce la cantidad de datos escaneados
# Default df_joined = df1.join(df2, ["product_id"]) # Use Pushdown df1_select = df1.select("product_id","product_title","star_rating").filter(col("star_rating")>=4.0) df2_select = df2.select("product_id","category_id") df_joined = df1_select.join(df2_select, ["product_id"])
Utilice DataFrame Join
Intenta usar un Spark de alto niveldyf.toDF(). Como se explica en la sección Temas clave de Apache Spark, estas operaciones de unión aprovechan internamente la optimización de consultas realizada por el optimizador de Catalyst.
Mezcla y difunde combinaciones de hash y sugerencias
Spark admite dos tipos de unión: shuffle join y broadcast hash join. Una unión hash de difusión no requiere una combinación aleatoria y puede requerir menos procesamiento que una combinación aleatoria. Sin embargo, solo se aplica al unir una mesa pequeña a una mesa grande. Al unirte a una tabla que quepa en la memoria de un solo ejecutor de Spark, considera usar una combinación hash broadcast.
El siguiente diagrama muestra la estructura de alto nivel y los pasos de una combinación hash de difusión y una combinación aleatoria.
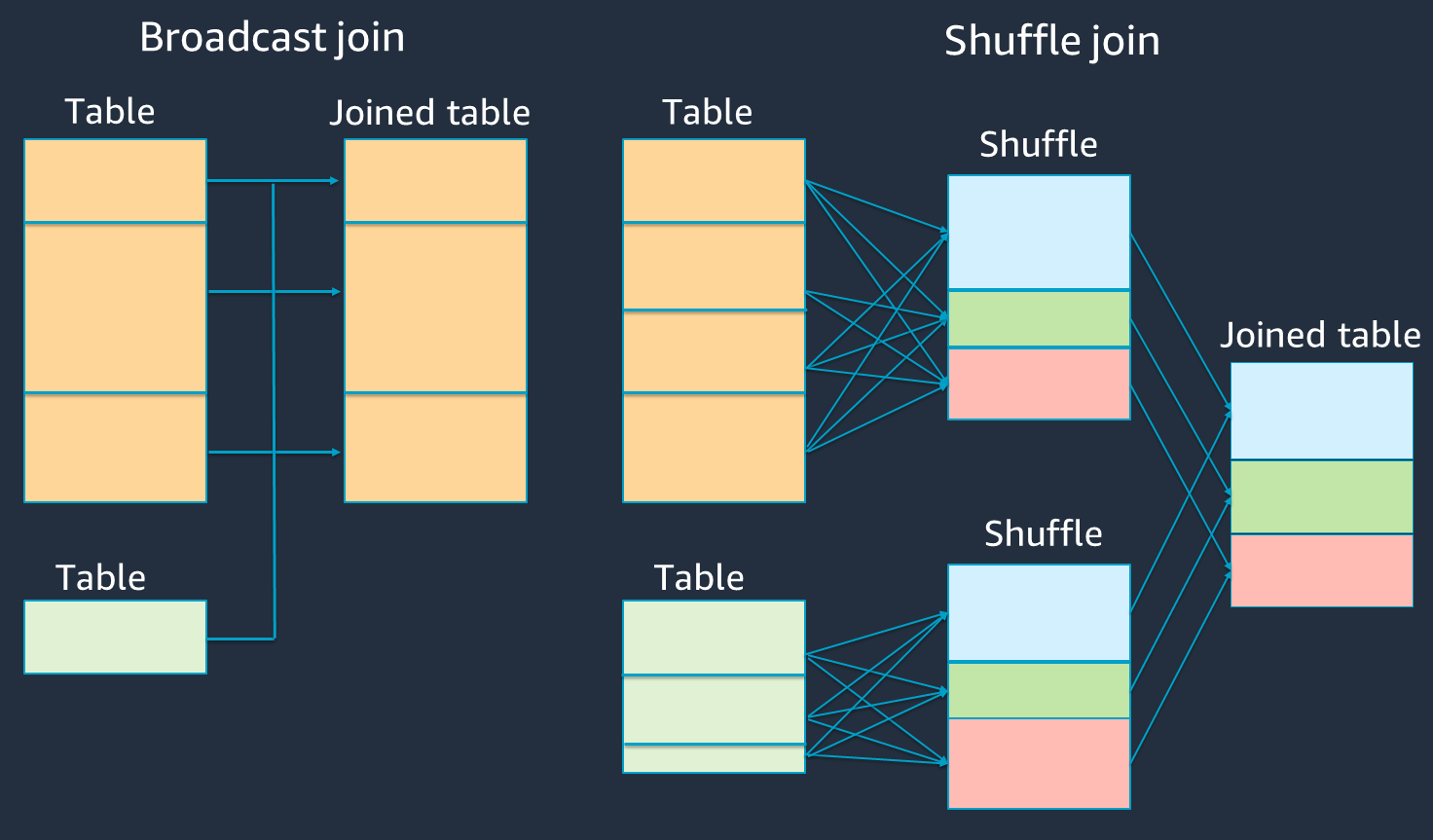
Los detalles de cada combinación son los siguientes:
-
Combinación aleatoria:
-
La combinación de hash aleatorio une dos tablas sin ordenar y distribuye la unión entre las dos tablas. Es adecuada para uniones de tablas pequeñas que se pueden almacenar en la memoria del ejecutor de Spark.
-
La combinación ordenar-combinar distribuye las dos tablas que se van a unir por clave y las ordena antes de unirlas. Es adecuada para unir tablas grandes.
-
-
Combinación de hash de transmisión:
-
Una combinación de hash de transmisión empuja la tabla RDD o más pequeña a cada uno de los nodos de trabajo. Luego, combina el lado del mapa con cada partición de la tabla o más grandeRDD.
Es adecuado para las uniones cuando una de tus RDDs tablas cabe en la memoria o se puede hacer que quepa en la memoria. Siempre que sea posible, es recomendable hacer una combinación hash de transmisión, ya que no es necesario mezclarla. Puedes usar una sugerencia para unirte a una transmisión desde Spark de la siguiente manera.
# DataFrame from pySpark.sql.functions import broadcast df_joined= df_big.join(broadcast(df_small), right_df[key] == left_df[key], how='inner') -- SparkSQL SELECT /*+ BROADCAST(t1) / FROM t1 INNER JOIN t2 ON t1.key = t2.key;Para obtener más información sobre las sugerencias para unirse, consulta las sugerencias para unirse
.
-
En la AWS Glue versión 3.0 y versiones posteriores, puede aprovechar las uniones hash emitidas automáticamente activando la ejecución adaptativa de consultas
En la AWS Glue versión 3.0, se puede activar la ejecución adaptativa de consultas mediante la configuración. spark.sql.adaptive.enabled=true La ejecución adaptativa de consultas está habilitada de forma predeterminada en AWS Glue 4.0.
Puedes configurar parámetros adicionales relacionados con las combinaciones aleatorias y las uniones hash emitidas:
-
spark.sql.adaptive.localShuffleReader.enabled -
spark.sql.adaptive.autoBroadcastJoinThreshold
Para obtener más información sobre los parámetros relacionados, consulte Convertir una unión de clasificación y fusión en una unión
En la AWS Glue versión 3.0 o versiones posteriores, puedes usar otras sugerencias de unión para mezclar y así ajustar tu comportamiento.
-- Join Hints for shuffle sort merge join SELECT /*+ SHUFFLE_MERGE(t1) / FROM t1 INNER JOIN t2 ON t1.key = t2.key; SELECT /*+ MERGEJOIN(t2) / FROM t1 INNER JOIN t2 ON t1.key = t2.key; SELECT /*+ MERGE(t1) / FROM t1 INNER JOIN t2 ON t1.key = t2.key; -- Join Hints for shuffle hash join SELECT /*+ SHUFFLE_HASH(t1) / FROM t1 INNER JOIN t2 ON t1.key = t2.key; -- Join Hints for shuffle-and-replicate nested loop join SELECT /*+ SHUFFLE_REPLICATE_NL(t1) / FROM t1 INNER JOIN t2 ON t1.key = t2.key;
Usa el agrupamiento
La combinación ordenar-fusionar requiere dos fases: barajar y ordenar y, a continuación, fusionar. Estas dos fases pueden sobrecargar el ejecutor de Spark OOM y provocar problemas de rendimiento cuando algunos ejecutores se fusionan y otros se clasifican simultáneamente. En esos casos, podría ser posible realizar una unión eficiente mediante agrupamiento.
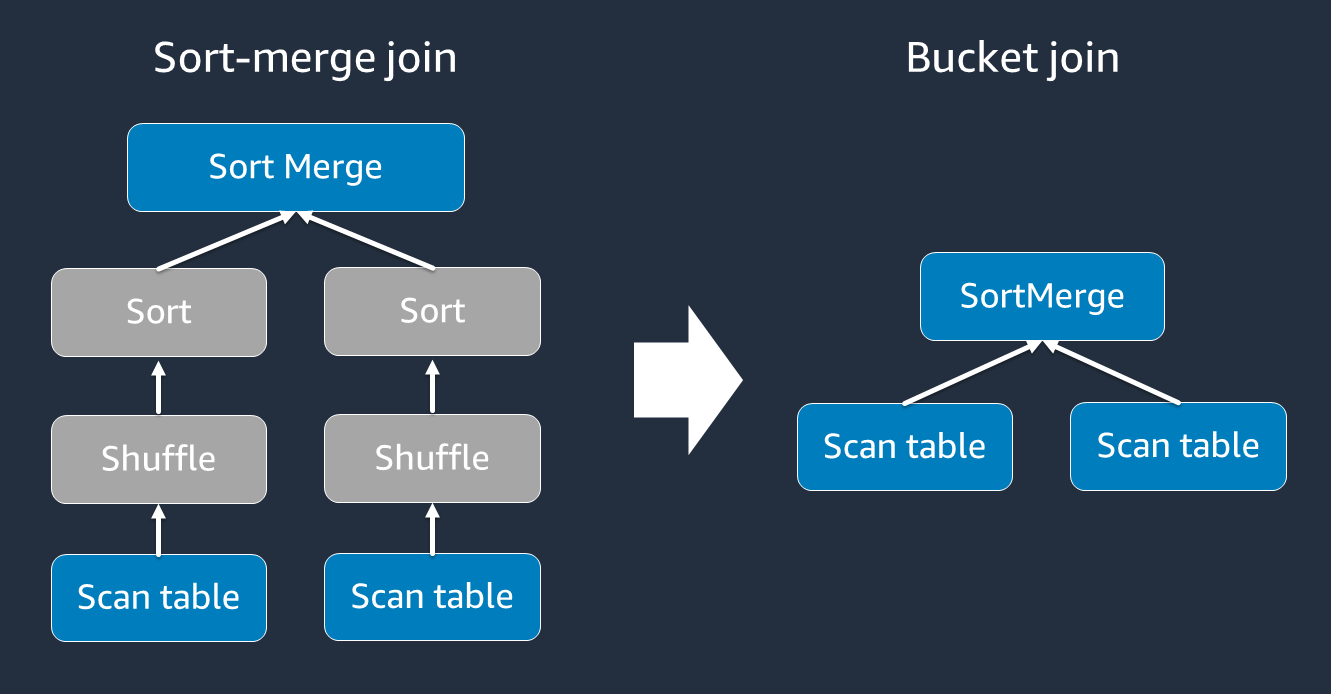
Las tablas agrupadas son útiles para lo siguiente:
-
Los datos se unían con frecuencia a través de la misma clave, como
account_id -
Cargar tablas acumulativas diarias, como las tablas base y delta, que podrían agruparse en una columna común
Puede crear una tabla agrupada mediante el siguiente código.
df.write.bucketBy(50, "account_id").sortBy("age").saveAsTable("bucketed_table")
Reparticione DataFrames las claves de unión antes de la unión
Para reparticionar los dos elementos DataFrames de las claves de combinación antes de la unión, utilice las siguientes instrucciones.
df1_repartitioned = df1.repartition(N,"join_key") df2_repartitioned = df2.repartition(N,"join_key") df_joined = df1_repartitioned.join(df2_repartitioned,"product_id")
Esto dividirá dos (aún separados) de RDDs la clave de unión antes de iniciar la unión. Si las dos RDDs están particionadas en la misma clave y con el mismo código de partición, es muy probable que los RDD registros que planea unir estén ubicados en el mismo elemento de trabajo antes de volver a barajarlos para unirlos. Esto podría mejorar el rendimiento al reducir la actividad de la red y el sesgo de datos durante la unión.
Supere el sesgo de datos
La asimetría de los datos es una de las causas más comunes de un cuello de botella en los trabajos de Spark. Se produce cuando los datos no se distribuyen uniformemente entre las particiones. RDD Esto hace que las tareas de esa partición tarden mucho más que en otras, lo que retrasa el tiempo total de procesamiento de la aplicación.
Para identificar el sesgo de los datos, evalúa las siguientes métricas en la interfaz de usuario de Spark:
-
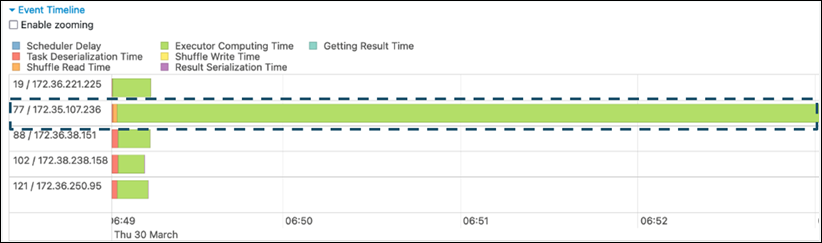
En la pestaña Escenario de la interfaz de usuario de Spark, examina la página de cronología del evento. Puedes ver una distribución desigual de las tareas en la siguiente captura de pantalla. Las tareas que se distribuyen de forma desigual o que tardan demasiado en ejecutarse pueden indicar un sesgo en los datos.
-
Otra página importante es Summary Metrics, que muestra las estadísticas de las tareas de Spark. La siguiente captura de pantalla muestra las métricas con los percentiles de duración, tiempo de GC, pérdida (memoria), pérdida (disco), etc.

Cuando las tareas estén distribuidas uniformemente, verás números similares en todos los percentiles. Cuando los datos estén sesgados, verá valores muy sesgados en cada percentil. En el ejemplo, la duración de la tarea es inferior a 13 segundos en el percentil mínimo, el percentil 25, la mediana y el percentil 75. Si bien la tarea Max procesó 100 veces más datos que el percentil 75, su duración de 6,4 minutos es aproximadamente 30 veces mayor. Esto significa que al menos una tarea (o hasta un 25 por ciento de las tareas) llevó mucho más tiempo que el resto de las tareas.
Si ves que los datos están sesgados, prueba lo siguiente:
-
Si usa AWS Glue 3.0, habilite la ejecución adaptativa de consultas mediante la configuración
spark.sql.adaptive.enabled=true. La ejecución adaptativa de consultas está habilitada de forma predeterminada en la AWS Glue versión 4.0.También puede utilizar la ejecución de consultas adaptativa para el sesgo de datos introducido por las uniones configurando los siguientes parámetros relacionados:
-
spark.sql.adaptive.skewJoin.skewedPartitionFactor -
spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes -
spark.sql.adaptive.advisoryPartitionSizeInBytes=128m (128 mebibytes or larger should be good) -
spark.sql.adaptive.coalescePartitions.enabled=true (when you want to coalesce partitions)
Para obtener más información, consulte la documentación de Apache Spark
. -
-
Utilice claves con un amplio rango de valores para las claves de unión. En una combinación aleatoria, las particiones se determinan para cada valor hash de una clave. Si la cardinalidad de una clave de unión es demasiado baja, es más probable que la función hash distribuya mal los datos entre las particiones. Por lo tanto, si su aplicación y su lógica empresarial lo admiten, considere la posibilidad de utilizar una clave de cardinalidad más alta o una clave compuesta.
# Use Single Primary Key df_joined = df1_select.join(df2_select, ["primary_key"]) # Use Composite Key df_joined = df1_select.join(df2_select, ["primary_key","secondary_key"])
Utilice la memoria caché
Cuando utilices el método repetitivo DataFrames, evita tener que df.persist() hacer cálculos o barajarlos de forma adicional utilizando df.cache() o almacenando en caché los resultados del cálculo en la memoria de cada ejecutor de Spark y en el disco. Spark también admite la persistencia RDDs en el disco o la replicación en varios nodos (nivel de almacenamiento).
Por ejemplo, puedes conservarlos DataFrames añadiendo. df.persist() Cuando la memoria caché ya no sea necesaria, puede utilizarla unpersist para descartar los datos almacenados en la memoria caché.
df = spark.read.parquet("s3://<Bucket>/parquet/product_category=Books/") df_high_rate = df.filter(col("star_rating")>=4.0) df_high_rate.persist() df_joined1 = df_high_rate.join(<Table1>, ["key"]) df_joined2 = df_high_rate.join(<Table2>, ["key"]) df_joined3 = df_high_rate.join(<Table3>, ["key"]) ... df_high_rate.unpersist()
Elimina las acciones innecesarias de Spark
Evita ejecutar acciones innecesarias como countshow, ocollect. Como se explica en la sección Temas clave de Apache Spark, Spark es perezoso. Cada transformación se RDD puede volver a calcular cada vez que ejecutes una acción en ella. Cuando utilizas muchas acciones de Spark, se recurre a varios accesos a fuentes, se realizan cálculos de tareas y se ejecuta aleatoriamente cada acción.
Si no necesitas ninguna collect() otra acción en tu entorno comercial, considera eliminarlas.
nota
Evita usar Spark collect() en entornos comerciales en la medida de lo posible. La collect() acción devuelve todos los resultados de un cálculo realizado en el ejecutor de Spark al controlador de Spark, lo que podría provocar que el controlador de Spark devuelva un OOM error. Para evitar OOM errores, Spark lo establece de forma spark.driver.maxResultSize = 1GB predeterminada, lo que limita el tamaño máximo de los datos devueltos al controlador de Spark a 1 GB.
