Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Optimice las funciones definidas por el usuario
Las funciones definidas por el usuario (UDFs) y, a PySpark menudo, reducen el rendimiento de RDD.map manera significativa. Esto se debe a la sobrecarga necesaria para representar con precisión tu código Python en la implementación de Scala subyacente de Spark.
El siguiente diagrama muestra la arquitectura de los PySpark trabajos. Cuando lo usas PySpark, el controlador Spark usa la biblioteca Py4j para llamar a los métodos de Java desde Python. Al llamar a Spark SQL o a funciones DataFrame integradas, hay poca diferencia de rendimiento entre Python y Scala porque las funciones se ejecutan en cada ejecutor JVM mediante un plan de ejecución optimizado.
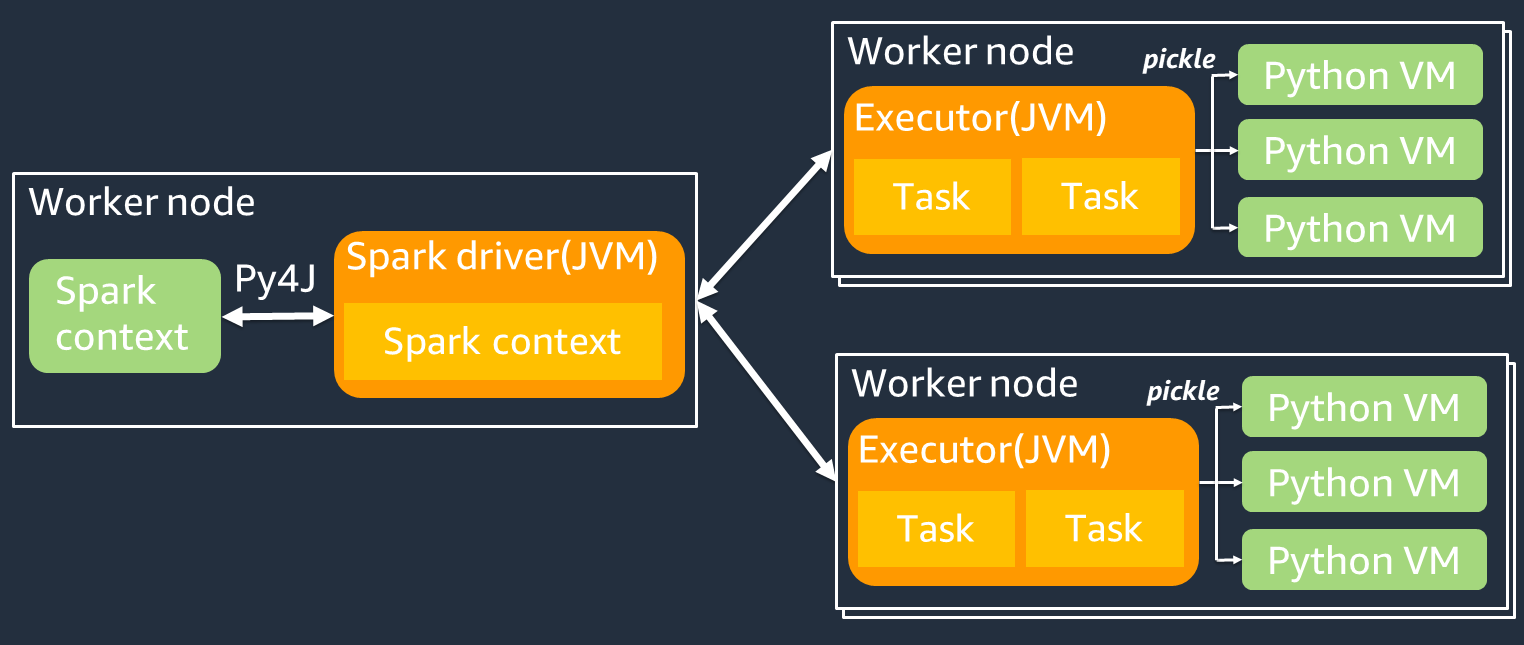
Si usa su propia lógica de Python, como usarmap/ mapPartitions/ udf, la tarea se ejecutará en un entorno de ejecución de Python. La administración de dos entornos genera un costo general. Además, los datos de la memoria deben transformarse para que puedan utilizarlos las funciones integradas del entorno de JVM ejecución. Pickle es un formato de serialización que se utiliza de forma predeterminada para el intercambio entre los tiempos de ejecución y JVM Python. Sin embargo, el coste de esta serialización y deserialización es muy elevado, por lo que UDFs escribir en Java o Scala es más rápido que en Python. UDFs
Para evitar la sobrecarga de serialización y deserialización, tenga en cuenta lo siguiente: PySpark
-
Usa las SQL funciones de Spark integradas: considera reemplazar una función propia UDF o de mapa por una función de Spark SQL o DataFrame funciones integradas. Al ejecutar Spark SQL o funciones DataFrame integradas, hay poca diferencia de rendimiento entre Python y Scala porque las tareas se gestionan en el ejecutor de cada ejecutor. JVM
-
Implemente UDFs en Scala o Java: considere usar uno UDF que esté escrito en Java o Scala, ya que se ejecutan en. JVM
-
Use Apache basado en Arrow UDFs para cargas de trabajo vectorizadas: considere usar el basado en Arrow. UDFs Esta función también se conoce como vectorizada (Pandas). UDF UDF Apache Arrow
es un formato de datos en memoria independiente del lenguaje que se AWS Glue puede utilizar para transferir datos de manera eficiente entre procesos de Python. JVM Actualmente, esto es más beneficioso para los usuarios de Python que trabajan con Pandas o NumPy datos. Arrow es un formato columnar (vectorizado). Su uso no es automático y puede requerir algunos cambios menores en la configuración o el código para aprovechar al máximo y garantizar la compatibilidad. Para obtener más detalles y conocer las limitaciones, consulte Apache Arrow en PySpark
. El siguiente ejemplo compara un incremental básico UDF en Python estándar, como vectorizado UDF y en Spark. SQL
Python estándar UDF
El tiempo de ejemplo es 3,20 (segundos).
Código de ejemplo
# DataSet df = spark.range(10000000).selectExpr("id AS a","id AS b") # UDF Example def plus(a,b): return a+b spark.udf.register("plus",plus) df.selectExpr("count(plus(a,b))").collect()
Plan de ejecución
== Physical Plan == AdaptiveSparkPlan isFinalPlan=false +- HashAggregate(keys=[], functions=[count(pythonUDF0#124)]) +- Exchange SinglePartition, ENSURE_REQUIREMENTS, [id=#580] +- HashAggregate(keys=[], functions=[partial_count(pythonUDF0#124)]) +- Project [pythonUDF0#124] +- BatchEvalPython [plus(a#116L, b#117L)], [pythonUDF0#124] +- Project [id#114L AS a#116L, id#114L AS b#117L] +- Range (0, 10000000, step=1, splits=16)
Vectorizado UDF
El tiempo de ejemplo es 0.59 (seg).
El vectorizado UDF es 5 veces más rápido que el ejemplo anterior. UDF Al comprobarloPhysical Plan, puede ver ArrowEvalPython que Apache Arrow vectoriza esta aplicación. Para habilitar VectorizedUDF, debe spark.sql.execution.arrow.pyspark.enabled = true especificarlo en su código.
Código de ejemplo
# Vectorized UDF from pyspark.sql.types import LongType from pyspark.sql.functions import count, pandas_udf # Enable Apache Arrow Support spark.conf.set("spark.sql.execution.arrow.pyspark.enabled", "true") # DataSet df = spark.range(10000000).selectExpr("id AS a","id AS b") # Annotate pandas_udf to use Vectorized UDF @pandas_udf(LongType()) def pandas_plus(a,b): return a+b spark.udf.register("pandas_plus",pandas_plus) df.selectExpr("count(pandas_plus(a,b))").collect()
Plan de ejecución
== Physical Plan == AdaptiveSparkPlan isFinalPlan=false +- HashAggregate(keys=[], functions=[count(pythonUDF0#1082L)], output=[count(pandas_plus(a, b))#1080L]) +- Exchange SinglePartition, ENSURE_REQUIREMENTS, [id=#5985] +- HashAggregate(keys=[], functions=[partial_count(pythonUDF0#1082L)], output=[count#1084L]) +- Project [pythonUDF0#1082L] +- ArrowEvalPython [pandas_plus(a#1074L, b#1075L)], [pythonUDF0#1082L], 200 +- Project [id#1072L AS a#1074L, id#1072L AS b#1075L] +- Range (0, 10000000, step=1, splits=16)
Spark SQL
El tiempo de ejemplo es 0.087 (seg).
Spark SQL es mucho más rápido que VectorizedUDF, porque las tareas se ejecutan en cada ejecutor sin JVM un tiempo de ejecución de Python. Si puedes sustituir la tuya UDF por una función integrada, te recomendamos que lo hagas.
Código de ejemplo
df.createOrReplaceTempView("test") spark.sql("select count(a+b) from test").collect()
Uso de pandas para macrodatos
Si ya estás familiarizado con los pandas
