Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Reduzca la cantidad de datos escaneados
Para empezar, considera cargar solo los datos que necesites. Puedes mejorar el rendimiento simplemente reduciendo la cantidad de datos que se cargan en tu clúster de Spark para cada fuente de datos. Para evaluar si este enfoque es apropiado, usa las siguientes métricas.
Puedes comprobar los bytes leídos de Amazon S3 en CloudWatchlas métricas y obtener más detalles en la interfaz de usuario de Spark, tal y como se describe en la sección de interfaz de usuario de Spark.
CloudWatch métricas
Puede ver el tamaño de lectura aproximado de Amazon S3 en ETLData Movement (bytes). Esta métrica muestra el número de bytes leídos de Amazon S3 por todos los ejecutores desde el informe anterior. Puede utilizarla para supervisar el movimiento de ETL datos desde Amazon S3 y comparar las tasas de lectura con las tasas de ingesta de fuentes de datos externas.
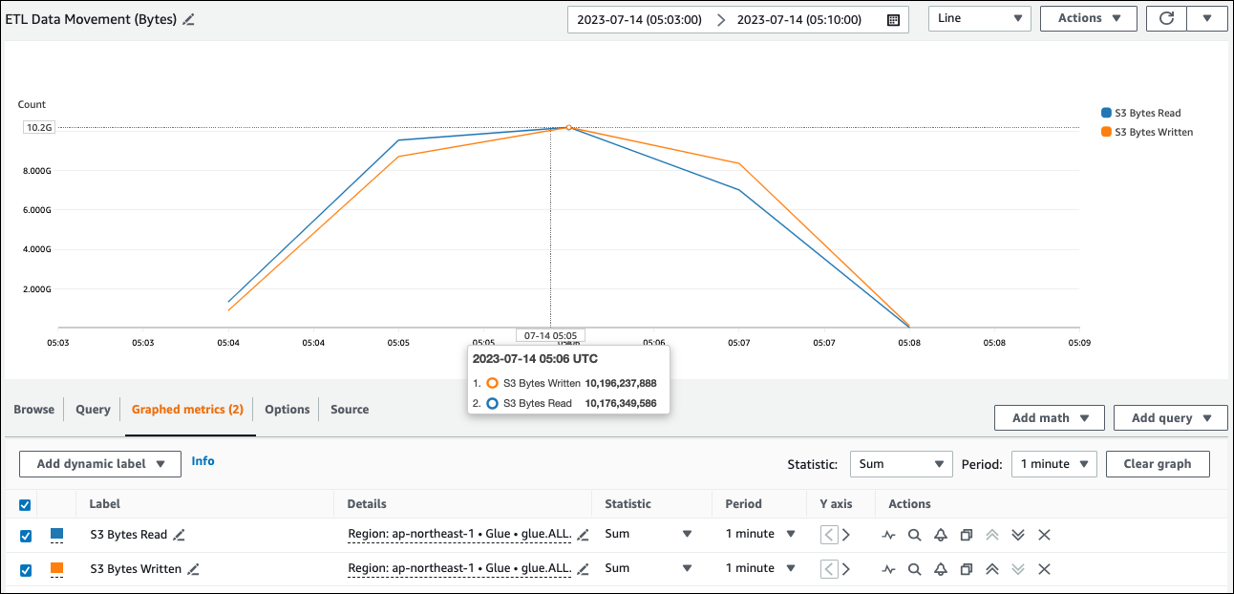
Si observa un punto de datos de lectura de S3 bytes mayor de lo esperado, considere las siguientes soluciones.
Interfaz de usuario de Spark
En la pestaña Stage de la interfaz AWS Glue de usuario de Spark, puedes ver el tamaño de entrada y salida. En el siguiente ejemplo, la etapa 2 lee 47,4 GiB de entrada y 47,7 GiB de salida, mientras que la etapa 5 lee 61,2 MiB de entrada y 56,6 MiB de salida.

Cuando usas la chispa SQL o los DataFrame enfoques en tu AWS Glue trabajo, la pestaña SQL ataFrame /D muestra más estadísticas sobre estas etapas. En este caso, la etapa 2 muestra el número de archivos leídos: 430, el tamaño de los archivos leídos: 47,4 GiB y el número de filas de salida: 160.796.570.
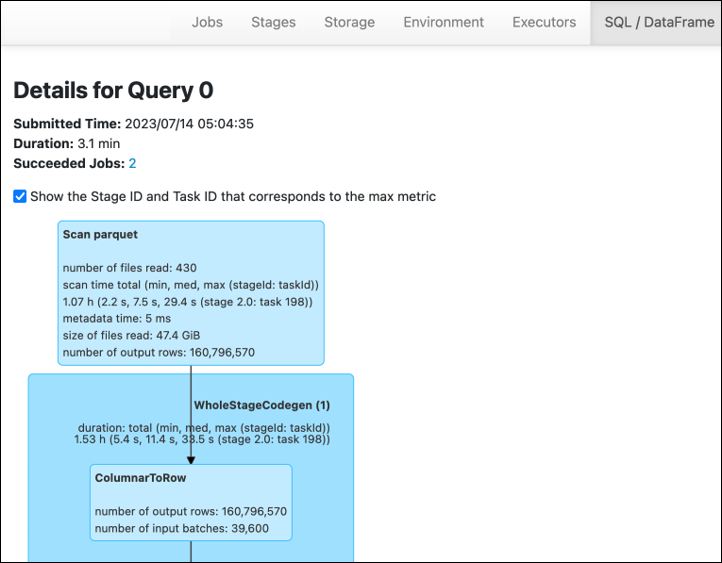
Si observa que hay una diferencia sustancial de tamaño entre los datos que lee y los datos que utiliza, pruebe las siguientes soluciones.
Amazon S3
Para reducir la cantidad de datos que se cargan en su trabajo al leer desde Amazon S3, tenga en cuenta el tamaño, la compresión, el formato y el diseño del archivo (particiones) del conjunto de datos. AWS Glue en el caso ETL de Spark, los trabajos se suelen utilizar para datos sin procesar, pero para un procesamiento distribuido eficiente, es necesario inspeccionar las características del formato de la fuente de datos.
-
Tamaño del archivo: recomendamos mantener el tamaño del archivo de entradas y salidas dentro de un rango moderado (por ejemplo, 128 MB). Los archivos demasiado pequeños y los archivos demasiado grandes pueden causar problemas.
Un gran número de archivos pequeños provoca los siguientes problemas:
-
La elevada carga de E/S de la red en Amazon S3 se debe a la sobrecarga necesaria para realizar solicitudes (por ejemplo
ListGet, oHead) para muchos objetos (en comparación con unos pocos objetos que almacenan la misma cantidad de datos). -
El controlador Spark soporta una gran carga de procesamiento y E/S, lo que generará muchas particiones y tareas y generará un paralelismo excesivo.
Por otro lado, si el tipo de archivo no se puede dividir (por ejemplo, gzip) y los archivos son demasiado grandes, la aplicación Spark debe esperar a que una sola tarea termine de leer todo el archivo.
Para reducir el paralelismo excesivo que se produce al crear una tarea de Apache Spark para cada archivo pequeño, utilice la agrupación de archivos para. DynamicFrames Este enfoque reduce las posibilidades de que se produzca una OOM excepción por parte del controlador Spark. Para configurar la agrupación de archivos, defina los
groupSizeparámetrosgroupFilesy. En el siguiente ejemplo de código, se utiliza AWS Glue DynamicFrame API en un ETL script con estos parámetros.dyf = glueContext.create_dynamic_frame_from_options("s3", {'paths': ["s3://input-s3-path/"], 'recurse':True, 'groupFiles': 'inPartition', 'groupSize': '1048576'}, format="json") -
-
Compresión: si los objetos de S3 ocupan cientos de megabytes, considere comprimirlos. Existen varios formatos de compresión, que se pueden clasificar a grandes rasgos en dos tipos:
-
Los formatos de compresión que no se pueden dividir, como gzip, requieren que un trabajador descomprima todo el archivo.
-
Los formatos de compresión separables, como bzip2 o LZO (indexado), permiten la descompresión parcial de un archivo, que se puede paralelizar.
Para Spark (y otros motores de procesamiento distribuido comunes), dividirás el archivo de datos fuente en fragmentos que tu motor pueda procesar en paralelo. Estas unidades suelen denominarse divisiones. Una vez que los datos estén en un formato separable, los AWS Glue lectores optimizados pueden recuperar las divisiones de un objeto S3 al ofrecer la
Rangeopción deGetObjectAPI recuperar solo bloques específicos. Considera el siguiente diagrama para ver cómo funcionaría esto en la práctica.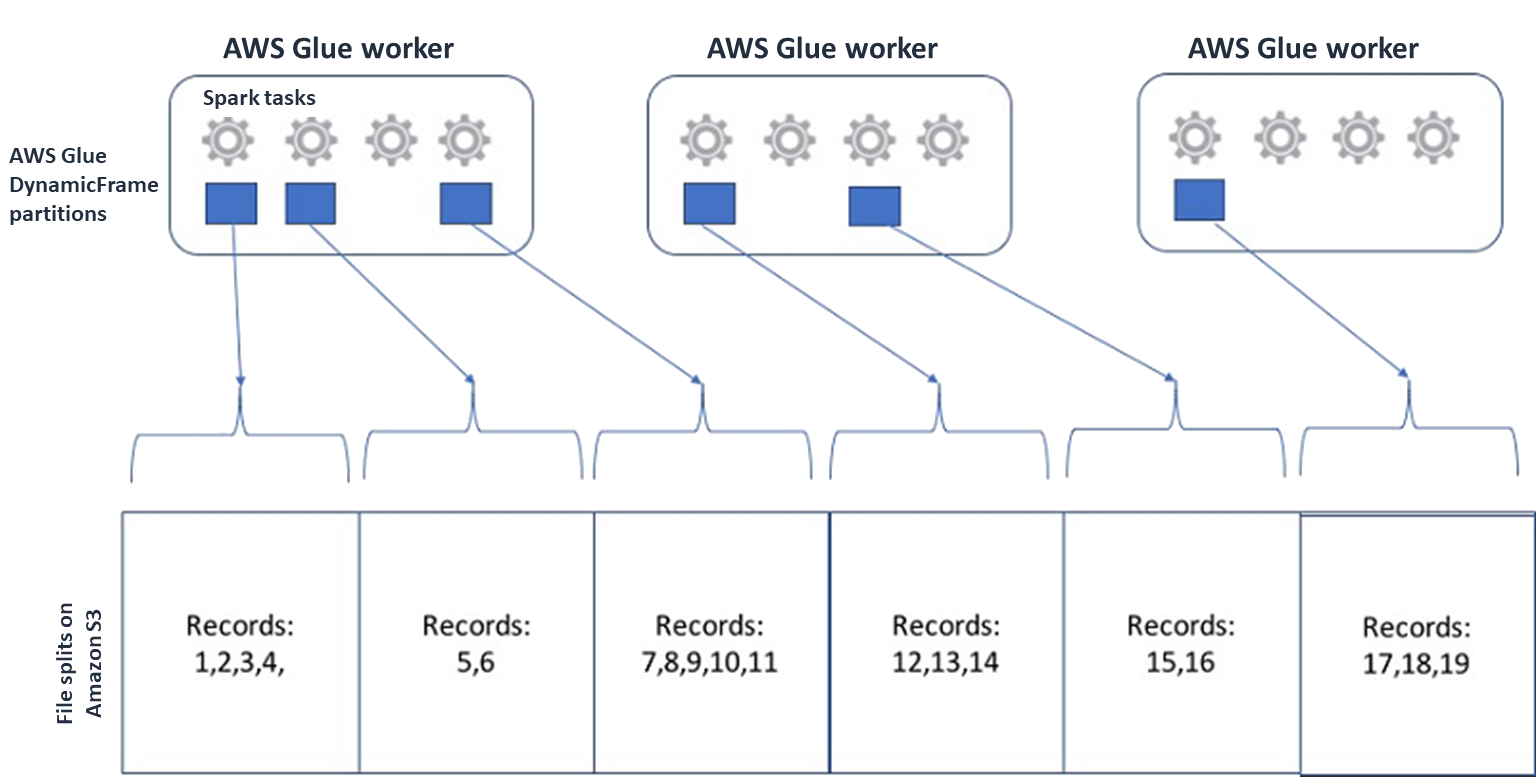
Los datos comprimidos pueden acelerar considerablemente la aplicación, siempre que los archivos tengan un tamaño óptimo o se puedan dividir. Los tamaños de datos más pequeños reducen los datos escaneados desde Amazon S3 y el tráfico de red desde Amazon S3 a su clúster de Spark. Por otro lado, CPU se necesita más para comprimir y descomprimir los datos. La cantidad de cómputo requerida aumenta con la relación de compresión del algoritmo de compresión. Tenga en cuenta esta desventaja a la hora de elegir el formato de compresión separable.
nota
Si bien los archivos gzip generalmente no se pueden dividir, puedes comprimir bloques de parquet individuales con gzip y esos bloques se pueden paralelizar.
-
-
Formato de archivo: utilice un formato de columnas. Apache Parquet
y Apache ORC son formatos de datos en columnas populares. Comprima y ORC almacene los datos de manera eficiente mediante la compresión basada en columnas, codificando y comprimiendo cada columna en función de su tipo de datos. Para obtener más información sobre las codificaciones de Parquet, consulte Definiciones de codificación de Parquet . Los archivos de parquet también se pueden dividir. Los formatos en columnas agrupan los valores por columnas y los almacenan juntos en bloques. Al usar formatos en columnas, puede omitir los bloques de datos que corresponden a columnas que no planea usar. Las aplicaciones de Spark solo pueden recuperar las columnas que necesitas. Por lo general, unas relaciones de compresión mejores o la omisión de bloques de datos implican leer menos bytes de Amazon S3, lo que se traduce en un mejor rendimiento. Ambos formatos también admiten los siguientes enfoques de compresión descendente para reducir la E/S:
-
Empuje por proyección: la compresión por proyección es una técnica para recuperar solo las columnas especificadas en la aplicación. Las columnas se especifican en la aplicación Spark, como se muestra en los siguientes ejemplos:
-
DataFrame ejemplo:
df.select("star_rating") -
SQLEjemplo de Spark:
spark.sql("select start_rating from <table>")
-
-
Depresión de predicados: la compresión de predicados es una técnica para procesar cláusulas de forma eficiente.
WHEREGROUP BYAmbos formatos tienen bloques de datos que representan valores de columnas. Cada bloque contiene las estadísticas del bloque, como los valores máximo y mínimo. Spark puede usar estas estadísticas para determinar si el bloque debe leerse u omitirse en función del valor del filtro utilizado en la aplicación. Para utilizar esta función, añade más filtros en las condiciones, como se muestra en los siguientes ejemplos:-
DataFrame ejemplo:
df.select("star_rating").filter("star_rating < 2") -
SQLEjemplo de Spark:
spark.sql("select * from <table> where star_rating < 2")
-
-
-
Diseño de archivos: al almacenar los datos de S3 en objetos situados en diferentes rutas en función de cómo se vayan a utilizar los datos, podrá recuperar los datos relevantes de forma eficiente. Para obtener más información, consulte Organizar objetos mediante prefijos en la documentación de Amazon S3. AWS Glue admite almacenar claves y valores en prefijos de Amazon S3 en este formato
key=value, dividiendo los datos según la ruta de Amazon S3. Al particionar sus datos, puede restringir la cantidad de datos escaneados por cada aplicación de análisis posterior, lo que mejora el rendimiento y reduce los costos. Para obtener más información, consulte Administrar particiones para su ETL salida. AWS GlueLa partición divide la tabla en diferentes partes y mantiene los datos relacionados en archivos agrupados en función de los valores de las columnas, como el año, el mes y el día, como se muestra en el siguiente ejemplo.
# Partitioning by /YYYY/MM/DD s3://<YourBucket>/year=2023/month=03/day=31/0000.gz s3://<YourBucket>/year=2023/month=03/day=01/0000.gz s3://<YourBucket>/year=2023/month=03/day=02/0000.gz s3://<YourBucket>/year=2023/month=03/day=03/0000.gz ...Puede definir particiones para su conjunto de datos modelándolo con una tabla en. AWS Glue Data Catalog A continuación, puede restringir la cantidad de datos escaneados mediante la reducción de particiones de la siguiente manera:
-
Para AWS Glue DynamicFrame, configure
push_down_predicate(ocatalogPartitionPredicate).dyf = Glue_context.create_dynamic_frame.from_catalog( database=src_database_name, table_name=src_table_name, push_down_predicate = "year='2023' and month ='03'", ) -
En el caso de Spark DataFrame, establece una ruta fija para podar las particiones.
df = spark.read.format("json").load("s3://<YourBucket>/year=2023/month=03/*/*.gz") -
En el caso de SparkSQL, puedes configurar la cláusula where para eliminar las particiones del catálogo de datos.
df = spark.sql("SELECT * FROM <Table> WHERE year= '2023' and month = '03'") -
Para particionar por fecha cuando escribas tus datos AWS Glue, introduce DynamicFrame o partitionBy()
DataFrame con la información de fecha de tus columnas de la siguiente manera. partitionKeys -
DynamicFrame
glue_context.write_dynamic_frame_from_options( frame= dyf, connection_type='s3',format='parquet' connection_options= { 'partitionKeys': ["year", "month", "day"], 'path': 's3://<YourBucket>/<Prefix>/' } ) -
DataFrame
df.write.mode('append')\ .partitionBy('year','month','day')\ .parquet('s3://<YourBucket>/<Prefix>/')
Esto puede mejorar el rendimiento de los consumidores de los datos de salida.
Si no tiene acceso para modificar la canalización que crea el conjunto de datos de entrada, la partición no es una opción. En su lugar, puedes excluir las rutas S3 innecesarias mediante patrones globales. Establece exclusiones al leer. DynamicFrame Por ejemplo, el siguiente código excluye los días de los meses 01 a 09 del año 2023.
dyf = glueContext.create_dynamic_frame.from_catalog( database=db, table_name=table, additional_options = { "exclusions":"[\"**year=2023/month=0[1-9]/**\"]" }, transformation_ctx='dyf' )También puede establecer exclusiones en las propiedades de la tabla del catálogo de datos:
-
Clave:
exclusions -
Valor:
["**year=2023/month=0[1-9]/**"]
-
-
-
Demasiadas particiones de Amazon S3: evite particionar los datos de Amazon S3 en columnas que contengan una amplia gama de valores, como una columna de ID con miles de valores. Esto puede aumentar considerablemente el número de particiones del bucket, ya que el número de particiones posibles es el producto de todos los campos por los que ha realizado la partición. Demasiadas particiones pueden provocar lo siguiente:
-
Aumento de la latencia para recuperar los metadatos de las particiones del catálogo de datos
-
Mayor número de archivos pequeños, lo que requiere más API solicitudes de Amazon S3 (
ListGet, yHead)
Por ejemplo, si estableces un tipo de fecha en
partitionByopartitionKeys, la partición a nivel de fechayyyy/mm/ddes adecuada para muchos casos de uso. Sin embargo,yyyy/mm/dd/<ID>podría generar tantas particiones que afectaría negativamente al rendimiento en su conjunto.Por otro lado, algunos casos de uso, como las aplicaciones de procesamiento en tiempo real, requieren muchas particiones, por ejemplo
yyyy/mm/dd/hh. Si su caso de uso requiere particiones importantes, considere la posibilidad de utilizar índices de AWS Glue particiones para reducir la latencia a la hora de recuperar los metadatos de las particiones del catálogo de datos. -
Bases de datos y JDBC
Para reducir el escaneo de datos al recuperar información de una base de datos, puede especificar un where predicado (o cláusula) en una SQL consulta. Las bases de datos que no proporcionan una SQL interfaz proporcionarán su propio mecanismo de consulta o filtrado.
Cuando utilice conexiones de conectividad de bases de datos Java (JDBC), proporcione una consulta de selección con la where cláusula para los siguientes parámetros:
-
Para DynamicFrame, utilice la sampleQueryopción. Cuando
create_dynamic_frame.from_cataloglo utilice, configure eladditional_optionsargumento de la siguiente manera.query = "SELECT * FROM <TableName> where id = 'XX' AND" datasource0 = glueContext.create_dynamic_frame.from_catalog( database = db, table_name = table, additional_options={ "sampleQuery": query, "hashexpression": key, "hashpartitions": 10, "enablePartitioningForSampleQuery": True }, transformation_ctx = "datasource0" )Cuando
using create_dynamic_frame.from_options, configure elconnection_optionsargumento de la siguiente manera.query = "SELECT * FROM <TableName> where id = 'XX' AND" datasource0 = glueContext.create_dynamic_frame.from_options( connection_type = connection, connection_options={ "url": url, "user": user, "password": password, "dbtable": table, "sampleQuery": query, "hashexpression": key, "hashpartitions": 10, "enablePartitioningForSampleQuery": True } ) -
Para DataFrame, utilice la opción de consulta
. query = "SELECT * FROM <TableName> where id = 'XX'" jdbcDF = spark.read \ .format('jdbc') \ .option('url', url) \ .option('user', user) \ .option('password', pwd) \ .option('query', query) \ .load() -
En el caso de Amazon Redshift, utilice la AWS Glue versión 4.0 o una versión posterior para aprovechar la compatibilidad con pulsaciones descendentes del conector Amazon Redshift Spark.
dyf = glueContext.create_dynamic_frame.from_catalog( database = "redshift-dc-database-name", table_name = "redshift-table-name", redshift_tmp_dir = args["temp-s3-dir"], additional_options = {"aws_iam_role": "arn:aws:iam::role-account-id:role/rs-role-name"} ) -
Para otras bases de datos, consulte la documentación de esa base de datos.
AWS Glue opciones
-
Para evitar un análisis completo de todas las ejecuciones continuas de tareas y procesar solo los datos que no estaban presentes durante la última ejecución de la tarea, habilite los marcadores de tareas.
-
Para limitar la cantidad de datos de entrada que se van a procesar, habilite la ejecución limitada con marcadores de trabajos. Esto ayuda a reducir la cantidad de datos escaneados para cada ejecución de trabajo.
