Amazon Redshift dejará de admitir la creación de nuevas UDF de Python a partir del parche 198. Las UDF de Python existentes seguirán funcionando hasta el 30 de junio de 2026. Para obtener más información, consulte la publicación del blog
Uso de la vista SVL_QUERY_SUMMARY
Para analizar la información resumida de una consulta por secuencia con SVL_QUERY_SUMMARY, haga lo siguiente:
-
Ejecute la siguiente consulta para determinar el ID de su consulta:
select query, elapsed, substring from svl_qlog order by query desc limit 5;Examine el texto truncado de la consulta en el campo
substringpara determinar qué valor dequeryrepresenta su consulta. Si ejecutó la consulta más de una vez, utilice el valorqueryde la fila con el valor deelapsedmás bajo. Esa es la fila de la versión compilada. Si ha ejecutado distintas consultas, puede aumentar el valor que utilizó la cláusula LIMIT para asegurarse de que su consulta esté incluida. -
Seleccione las filas de SVL_QUERY_SUMMARY para su consulta. Ordene los resultados por secuencia, segmento y paso:
select * from svl_query_summary where query = MyQueryID order by stm, seg, step;A continuación se muestra un resultado de ejemplo.
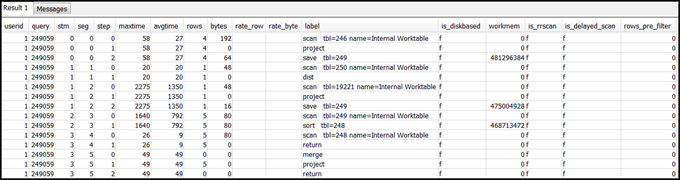
-
Haga corresponder los pasos con las operaciones del plan de consulta utilizando la información en Mapeo entre el plan de consulta y el resumen de la consulta. Tienen que tener, aproximadamente, los mismos valores de filas y de bytes (filas * ancho del plan de consulta). En caso de no coincidir, consulte Faltan estadísticas de tablas o están desactualizadas para conocer las soluciones recomendadas.
-
Controle si el campo
is_diskbasedtiene el valort("true") para algún paso. Hash, aggregate y sort son los operadores que, probablemente, se guarden en el disco si el sistema no tiene suficiente memoria asignada para el procesamiento de consultas.Si
is_diskbasedtiene el valor "true", consulte Memoria insuficiente asignada a la consulta para conocer las soluciones recomendadas. -
Controle los valores del campo
labely vea si hay una secuencia AGG-DIST-AGG en alguna parte de los pasos. Si dicha secuencia está presente, esto indica que hay una agregación de dos pasos, que es costosa. Para reparar esto, cambie la cláusula GROUP BY para utilizar la clave de distribución (la primera clave, si hay varias). -
Revise el valor de
maxtimede cada segmento (es el mismo en todos los pasos del segmento). Identifique el segmento con el valor más alto demaxtimey revise los pasos en este segmento para los siguientes operadores.nota
Un valor elevado de
maxtimeno indica necesariamente un problema con el segmento. Más allá de que el valor sea elevado, es posible que el segmento no haya tardado mucho tiempo en procesarse. Todos los segmentos de una secuencia comienzan a programarse al mismo tiempo. Sin embargo, es posible que algunos segmentos posteriores no se puedan ejecutar hasta obtener datos de los segmentos anteriores. Es posible que este efecto haga parecer que hayan tardado mucho tiempo porque su valor demaxtimeincluye tanto su tiempo de espera como su tiempo de procesamiento.-
BCAST o DIST: en estos casos, el valor elevado de
maxtimepuede resultar de la redistribución de una gran cantidad de filas. Para conocer las soluciones recomendadas, consulte Distribución de datos poco óptima. -
HJOIN (hash join): si el paso en cuestión tiene un valor muy elevado en el campo
rowsen comparación con el valor derowsen el paso final RETURN de la consulta, consulte Combinación hash para conocer las soluciones recomendadas. -
SCAN/SORT: busque una secuencia SCAN, SORT, SCAN, MERGE de pasos justo antes de un paso de combinación. Este patrón indica que los datos desordenados se examinan, ordenan y, luego, fusionan con el área ordenada de la tabla.
Advierta si el valor de rows del paso SCAN tiene un valor muy elevado en comparación con el valor de rows del paso final RETURN de la consulta. Este patrón indica que el motor de ejecución está examinando filas que, luego, se descartan, lo cual es poco eficiente. Para conocer las soluciones recomendadas, consulte Predicado poco restrictivo.
Si el valor de
maxtimedel paso SCAN es elevado, consulte Cláusula WHERE poco óptima para conocer las soluciones recomendadas.Si el valor de
rowsdel paso SORT no es cero, consulte Filas desordenadas o mal ordenadas para conocer las soluciones recomendadas.
-
-
Revise los valores de
rowsy debytesde los pasos 5 a 10 anteriores al paso final RETURN para hacerse una idea de la cantidad de datos que se devuelven al cliente. Este proceso puede ser un arte en sí mismo.Por ejemplo, en el siguiente resumen de consulta de ejemplo, el tercer paso PROJECT proporciona un valor de
rows, pero no un valor debytes. Si analiza los pasos anteriores para buscar uno con el mismo valor derows, encontrará que el paso SCAN proporciona información relacionada con filas y bytes.Lo que sigue es un ejemplo de resultado.
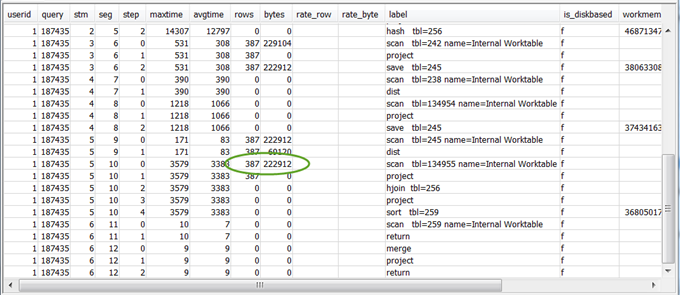
Si devuelve un volumen de datos excepcionalmente grande, consulte Conjunto de resultados muy grande para conocer las soluciones recomendadas.
-
Vea si el valor de
byteses elevado en comparación con el valor derowspara cualquier paso, en relación con los demás pasos. Este patrón puede indicar que está seleccionando demasiadas columnas. Para conocer las soluciones recomendadas, consulte Lista SELECT grande.
