Configuración y lanzamiento de un trabajo de ajuste de hiperparámetros
importante
Las políticas de IAM personalizadas que permiten a Amazon SageMaker Studio o Amazon SageMaker Studio Classic crear recursos de Amazon SageMaker también deben conceder permisos para añadir etiquetas a dichos recursos. El permiso para añadir etiquetas a los recursos es necesario porque Studio y Studio Classic etiquetan automáticamente todos los recursos que crean. Si una política de IAM permite a Studio y Studio Classic crear recursos, pero no permite el etiquetado, se pueden producir errores AccessDenied al intentar crear recursos. Para obtener más información, consulte Concesión de permisos para etiquetar recursos de SageMaker.
Las Políticas administradas de AWS para Amazon SageMaker que conceden permisos para crear recursos de SageMaker ya incluyen permisos para añadir etiquetas al crear esos recursos.
Un hiperparámetro es un parámetro de alto nivel que influye en el proceso de aprendizaje durante el entrenamiento del modelo. Para obtener las mejores predicciones del modelo, puede optimizar la configuración de un hiperparámetro o establecer valores de hiperparámetros. El proceso de encontrar una configuración óptima se denomina ajuste de hiperparámetros. Para configurar y lanzar un trabajo de ajuste de hiperparámetros, siga los pasos que se describen a continuación.
Temas
- Especifique la configuración del trabajo de ajuste de hiperparámetros
- Configuración de los trabajos de entrenamiento
- Denominación y lanzamiento del trabajo de ajuste de hiperparámetros
- Monitorización del avance de un trabajo de ajuste de hiperparámetros
- Visualización del estado de los trabajos de entrenamiento
- Visualización del mejor trabajo de entrenamiento
Especifique la configuración del trabajo de ajuste de hiperparámetros
Para especificar la configuración del trabajo de ajuste de hiperparámetros, debe definir un objeto JSON. Transfiera este objeto JSON como valor del parámetro HyperParameterTuningJobConfig a la API CreateHyperParameterTuningJob.
En este objeto JSON, especifique lo siguiente:
En este objeto JSON, debe especificar:
-
HyperParameterTuningJobObjective: la métrica objetiva utilizada para evaluar el rendimiento del trabajo de entrenamiento iniciado por el trabajo de ajuste de hiperparámetros. -
ParameterRanges: el rango de valores que un hiperparámetro ajustable puede utilizar durante la optimización. Para obtener más información, consulte Definición de intervalos de hiperparámetros -
RandomSeed: un valor que se utiliza para inicializar un generador de números pseudoaleatorios. Establecer una semilla aleatoria permitirá que las estrategias de búsqueda de ajuste de hiperparámetros produzcan configuraciones más coherentes para el mismo trabajo de ajuste (opcional). -
ResourceLimits: el número máximo de trabajos de entrenamiento y entrenamiento en paralelo que puede utilizar el trabajo de ajuste de hiperparámetros.
nota
Si utiliza su propio algoritmo para ajustar los hiperparámetros, en lugar de un algoritmo integrado de SageMaker, debe definir las métricas del algoritmo. Para obtener más información, consulte Definición de métricas.
El siguiente ejemplo de código muestra cómo configurar un trabajo de ajuste de hiperparámetros mediante el algoritmo XGBoost integrado. El ejemplo de código muestra cómo definir los rangos para los hiperparámetros eta, alpha, min_child_weight y max_depth. Para obtener más información sobre estos y otros hiperparámetros, consulte Parámetros de XGBoost
En este ejemplo de código, la métrica objetiva para el trabajo de ajuste de hiperparámetros busca la configuración de hiperparámetros que maximiza validation:auc. Los algoritmos integrados de Sagemaker escriben automáticamente la métrica objetiva en CloudWatch Logs. El siguiente ejemplo de código también muestra cómo configurar una RandomSeed.
tuning_job_config = { "ParameterRanges": { "CategoricalParameterRanges": [], "ContinuousParameterRanges": [ { "MaxValue": "1", "MinValue": "0", "Name": "eta" }, { "MaxValue": "2", "MinValue": "0", "Name": "alpha" }, { "MaxValue": "10", "MinValue": "1", "Name": "min_child_weight" } ], "IntegerParameterRanges": [ { "MaxValue": "10", "MinValue": "1", "Name": "max_depth" } ] }, "ResourceLimits": { "MaxNumberOfTrainingJobs": 20, "MaxParallelTrainingJobs": 3 }, "Strategy": "Bayesian", "HyperParameterTuningJobObjective": { "MetricName": "validation:auc", "Type": "Maximize" }, "RandomSeed" : 123 }
Configuración de los trabajos de entrenamiento
El trabajo de ajuste de hiperparámetros iniciará trabajos de entrenamiento para encontrar una configuración óptima de hiperparámetros. Estos trabajos de entrenamiento deben configurarse mediante la API CreateHyperParameterTuningJob de SageMaker.
Para configurar los trabajos de entrenamiento, defina un objeto JSON y páselo como el valor del parámetro TrainingJobDefinition en CreateHyperParameterTuningJob.
En este objeto JSON, puede especificar lo siguiente:
-
AlgorithmSpecification: la ruta de registro de la imagen de Docker que contiene el algoritmo de entrenamiento y los metadatos relacionados. Para especificar un algoritmo, puede utilizar su propio algoritmo personalizado dentro de un contenedor de Dockero un algoritmo integrado de SageMaker (obligatorio). -
InputDataConfig: la configuración de entrada, incluidosChannelName,ContentTypey origen de datos de entrenamiento y datos de prueba (obligatorio). -
InputDataConfig: la configuración de entrada, incluidosChannelName,ContentTypey origen de datos de entrenamiento y datos de prueba (obligatorio). -
La ubicación de almacenamiento de la salida del algoritmo. Especifique el bucket de S3 en el que desea almacenar la salida de los trabajos de entrenamiento.
-
RoleArn: el nombre de recurso de Amazon (ARN) de un rol de (IAM) AWS Identity and Access Management que SageMaker utiliza para realizar tareas. Las tareas incluyen leer datos de entrada, descargar una imagen de Docker, escribir artefactos del modelo en un bucket de S3, escribir en Registros de Amazon CloudWatch y escribir métricas en Amazon CloudWatch (obligatorio). -
StoppingCondition: el tiempo de ejecución máximo en segundos que puede ejecutar un trabajo de entrenamiento antes de detenerse. Este valor debe ser superior al tiempo necesario para formar al modelo (obligatorio). -
MetricDefinitions: el nombre y la expresión regular que define cualquier métrica que emitan los trabajos de entrenamiento. Defina métricas solo cuando use un algoritmo de entrenamiento personalizado. El ejemplo del código siguiente utiliza un algoritmo integrado, que ya tiene métricas definidas. Para obtener información sobre la definición de métricas (opcional), consulte Definición de métricas. -
TrainingImage: la imagen del contenedor de Dockerque especifica el algoritmo de entrenamiento (opcional). -
StaticHyperParameters: el nombre y valores de hiperparámetros que no están ajustados en el trabajo de ajuste (opcional).
El siguiente ejemplo de código establece valores estáticos para los parámetros eval_metric, num_round, objective, rate_drop y tweedie_variance_power del algoritmo integrado Algoritmo XGBoost con Amazon SageMaker.
Denominación y lanzamiento del trabajo de ajuste de hiperparámetros
Tras configurar el trabajo de ajuste de hiperparámetros, puede lanzarlo llamando a la API CreateHyperParameterTuningJob. En el siguiente código de ejemplo utiliza tuning_job_config y training_job_definition. Se definieron en los dos ejemplos de código anteriores para crear un trabajo de ajuste de hiperparámetros.
tuning_job_name = "MyTuningJob" smclient.create_hyper_parameter_tuning_job(HyperParameterTuningJobName = tuning_job_name, HyperParameterTuningJobConfig = tuning_job_config, TrainingJobDefinition = training_job_definition)
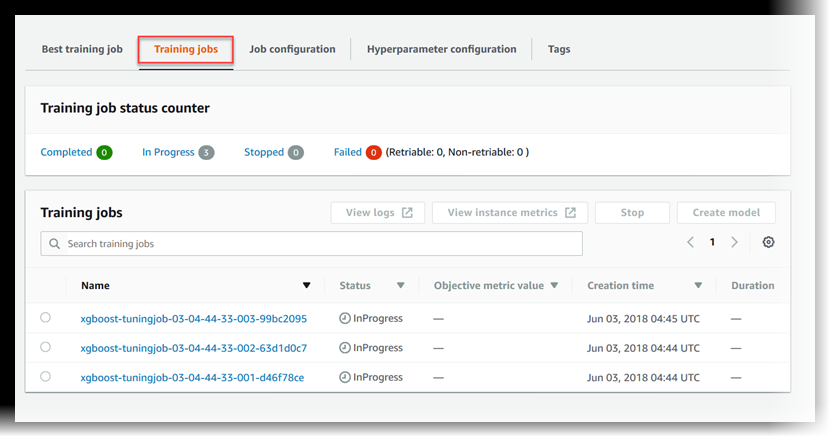
Visualización del estado de los trabajos de entrenamiento
Para ver el estado de los trabajos de entrenamiento que el trabajo de ajuste de hiperparámetros ha lanzado
-
En la lista de trabajos de ajuste de hiperparámetros, elija el trabajo que ha lanzado.
-
Elija Trabajos de entrenamiento.
-
Visualice el estado de cada trabajo de entrenamiento. Para ver más detalles sobre un trabajo, elíjalo en la lista de trabajos de entrenamiento. Para ver un resumen del estado de todos los trabajos de entrenamiento que el trabajo de ajuste de hiperparámetros ha lanzado, consulte Contador de estado del trabajo de entrenamiento.
Un trabajo de entrenamiento puede tener uno de los estados siguientes:
-
Completed: el trabajo de entrenamiento se completó correctamente. -
InProgress: el entrenamiento está en curso. -
Stopped: el trabajo de entrenamiento se detuvo manualmente antes de completarse. -
Failed (Retryable): el trabajo de entrenamiento ha generado un error, pero se puede reintentar. Un trabajo de entrenamiento con errores se puede reintentar solo si los errores se deben a un error de servicio interno. -
Failed (Non-retryable): el trabajo de entrenamiento ha generado un error, pero se puede reintentar. Un trabajo de entrenamiento con errores no se puede volver a intentar cuando se produce un error de cliente.
nota
Los trabajos de ajuste de hiperparámetros se pueden detener y los recursos subyacentes se pueden eliminar, pero los trabajos en sí mismos no se pueden eliminar.
-
Visualización del mejor trabajo de entrenamiento
Un trabajo de ajuste de hiperparámetros utiliza la métrica objetiva que cada trabajo de entrenamiento devuelve para evaluar trabajos de entrenamiento. Mientras el trabajo de ajuste de hiperparámetros está en curso, el mejor trabajo de entrenamiento es el que ha devuelto hasta el momento la mejor métrica objetiva. Una vez que el trabajo de ajuste de hiperparámetros se haya completado, el mejor trabajo de entrenamiento es el que ha devuelto la mejor métrica objetiva.
Para ver el mejor trabajo de entrenamiento, elija Mejor trabajo de entrenamiento.
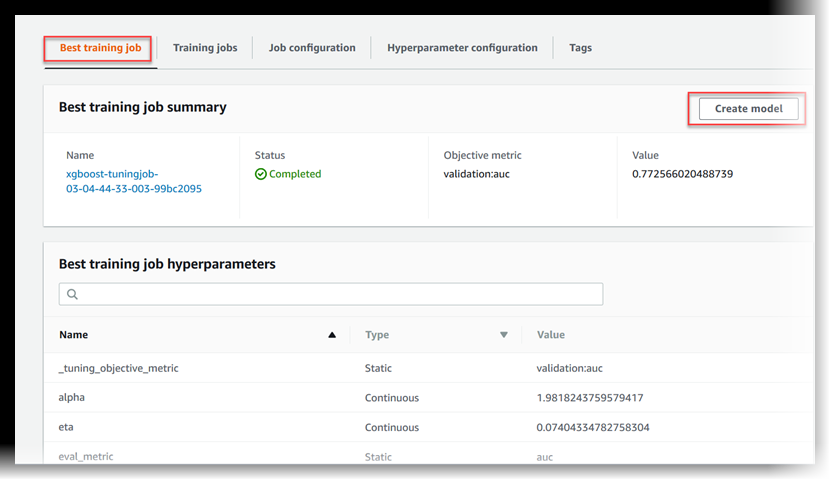
Para implementar el mejor trabajo de entrenamiento como modelo que puede alojar en un punto de conexión de SageMaker, elija Crear modelo.
Paso siguiente
