Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Métricas y validación
Esta guía muestra las métricas y las técnicas de validación que puede utilizar para medir el rendimiento del modelo de machine learning. Amazon SageMaker Autopilot produce métricas que miden la calidad predictiva de los candidatos a modelos de aprendizaje automático. Las métricas calculadas para los candidatos se especifican mediante una serie de MetricDatumtipos.
Métricas de Piloto automático
La siguiente lista contiene los nombres de las métricas que están disponibles actualmente para medir el rendimiento de los modelos en Piloto automático.
nota
Piloto automático admite las ponderaciones de muestra. Para obtener más información sobre las ponderaciones de muestra y las métricas objetivo disponibles, consulte Métricas ponderadas en Piloto automático.
Estas son las métricas disponibles.
Accuracy-
La relación entre el número de elementos clasificados correctamente y el número total de elementos clasificados (correcta e incorrectamente). Se utiliza tanto para la clasificación binaria como para la clasificación multiclase. La precisión mide el grado de aproximación de los valores de clase pronosticados con respecto a los valores reales. Los valores de las métricas de precisión varían entre cero (0) y uno (1). Un valor de 1 indica una precisión perfecta y un 0 indica una imprecisión perfecta.
AUC-
La métrica del área bajo la curva (AUC) se utiliza para comparar y evaluar la clasificación binaria mediante algoritmos que devuelven probabilidades, como la regresión logística. Para mapear las probabilidades en clasificaciones, estas se comparan con un valor umbral.
La curva relevante es la curva característica de funcionamiento del receptor. La curva traza la tasa de positivos verdaderos (TPR) de las predicciones (o exhaustividad) en comparación con la tasa de falsos positivos (FPR) en función del valor umbral, por encima del cual una predicción se considera positiva. Si se aumenta el umbral, se obtienen menos falsos positivos, pero más falsos negativos.
El AUC es el área bajo la curva característica de funcionamiento de este receptor. Por lo tanto, el AUC proporciona una medida agregada del rendimiento del modelo en todos los umbrales de clasificación posibles. Las puntuaciones del AUC varían entre 0 y 1. Una puntuación de 1 indica una precisión perfecta y una puntuación de la mitad (0,5) indica que la predicción no es mejor que la de un clasificador aleatorio.
BalancedAccuracy-
BalancedAccuracyes una métrica que mide la relación entre las predicciones precisas y todas las predicciones. Esta relación se calcula después de normalizar los positivos verdaderos (TP) y los negativos verdaderos (TN) mediante el número total de valores positivos (P) y negativos (N). Se utiliza tanto en la clasificación binaria como en la multiclase y se define como 0,5 * ((TP/P) + (TN/N)), con valores que van de 0 a 1.BalancedAccuracyproporciona una mejor medida de la precisión cuando el número de positivos o negativos es muy diferente entre sí en un conjunto de datos desequilibrado; por ejemplo, cuando solo el 1 % del correo electrónico es no deseado. F1-
La puntuación
F1es la media armónica de la precisión y la exhaustividad, que se define como F1 = 2 * (precisión * exhaustividad)/(precisión + exhaustividad). Se utiliza para la clasificación binaria en clases denominadas tradicionalmente positivas y negativas. Se dice que las predicciones son verdaderas cuando coinciden con su clase real (correcta) y falsas cuando no coinciden.La precisión es la relación entre las predicciones positivas verdaderas y todas las predicciones positivas, e incluye los falsos positivos de un conjunto de datos. La precisión mide la calidad de la predicción cuando predice la clase positiva.
La exhaustividad (o sensibilidad) es la relación entre las predicciones positivas verdaderas y todas las instancias positivas reales. La exhaustividad mide la precisión con la que un modelo predice los miembros reales de la clase en un conjunto de datos.
Las puntuaciones de F1 varían entre 0 y 1. Una puntuación de 1 indica el mejor rendimiento posible y 0 indica el peor.
F1macro-
La puntuación de
F1macroaplica la puntuación de F1 en los problemas de clasificación multiclase. Para ello, calcula la precisión y la recuperación; luego, calcula la media armónica para calcular la puntuación de F1 de cada clase. Por último,F1macropromedia las puntuaciones individuales para obtener la puntuación deF1macro. Las puntuacionesF1macrovarían entre 0 y 1. Una puntuación de 1 indica el mejor rendimiento posible y 0 indica el peor. InferenceLatency-
La latencia de inferencia es el tiempo aproximado que transcurre entre solicitar una predicción de modelo y recibirla desde un punto de conexión en tiempo real en el que se implementa el modelo. Esta métrica se mide en segundos y solo está disponible en el modo de ensamblaje.
LogLoss-
La pérdida logarítmica, también conocida como pérdida de entropía cruzada, es una métrica que se utiliza para evaluar la calidad de las salidas probabilísticas, en lugar de las propias salidas. Se utiliza tanto para la clasificación binaria como para la clasificación multiclase en redes neuronales. También es la función de coste de la regresión logística. La pérdida logarítmica es una métrica importante para indicar, con una alta probabilidad, el momento en el que un modelo hace predicciones incorrectas. Los valores están comprendidos entre 0 e infinito. Un valor de 0 representa un modelo que predice perfectamente los datos.
MAE-
El error absoluto medio (MAE) es una medida de la diferencia entre los valores pronosticados y reales cuando se promedian entre todos los valores. El MAE se utiliza habitualmente en el análisis de regresión para comprender el error de predicción del modelo. Si hay regresión lineal, el MAE representa la distancia promedio desde una línea pronosticada hasta el valor real. El MAE se define como la suma de los errores absolutos dividida por el número de observaciones. Los valores van desde 0 hasta el infinito, y los números más pequeños indican un mejor ajuste del modelo a los datos.
MSE-
El error cuadrático medio (MSE) es el promedio de las diferencias cuadráticas entre los valores pronosticados y reales. Se usa para la regresión. Los valores de MSE son siempre positivos. Cuanto mejor prediga los valores reales un modelo, menor será el valor de MSE.
Precision-
La precisión mide el rendimiento de un algoritmo al predecir los verdaderos positivos (TP) de entre todos los positivos que identifica. Se define como Precisión = TP/(TP+FP); los valores van de cero (0) a uno (1) y se utiliza en la clasificación binaria. La precisión es una métrica importante cuando el coste de un falso positivo es elevado. Por ejemplo, el coste de un falso positivo es muy elevado si el sistema de seguridad de un avión se equivoca al decir que es seguro volar. Un falso positivo (FP) refleja una predicción positiva que, en realidad, es negativa en los datos.
PrecisionMacro-
La macro de precisión calcula la precisión de los problemas de clasificación multiclase. Para ello, calcula la precisión de cada clase y promedia las puntuaciones para obtener la precisión de varias clases. Las puntuaciones de
PrecisionMacrovan de cero (0) a uno (1). Las puntuaciones más altas reflejan la capacidad del modelo para predecir positivos verdaderos (TP) a partir de todos los positivos que identifica, promediados en varias clases. R2-
El R 2, también conocido como coeficiente de determinación, se utiliza en la regresión para cuantificar en qué medida un modelo puede explicar la varianza de una variable dependiente. Los valores oscilan entre uno (1) y menos uno (-1). Los números más altos indican una fracción más alta de la variabilidad explicada. Los valores de
R2cercanos a cero (0) indican que el modelo puede explicar muy poco sobre la variable dependiente. Los valores negativos indican que hay un ajuste deficiente y que el rendimiento del modelo es superado por una función constante. En el caso de la regresión lineal, se trata de una línea horizontal. Recall-
La exhaustividad mide el rendimiento de un algoritmo a la hora de predecir correctamente todos los positivos verdaderos (TP) de un conjunto de datos. Un positivo verdadero es una predicción positiva que también es un valor positivo real en los datos. La exhaustividad se define de la siguiente manera: Exhaustividad = TP/(TP+FN), con valores que van de 0 a 1. Las puntuaciones más altas reflejan una mejor capacidad del modelo para predecir los verdaderos positivos (TP) en los datos. Se utiliza en la clasificación binaria.
La exhaustividad es importante en las pruebas de detección de cáncer, ya que se utiliza para encontrar todos los positivos verdaderos. Un falso positivo (FP) refleja una predicción positiva que, en realidad, es negativa en los datos. A menudo no basta con medir solo la exhaustividad, ya que, si se predice cada salida como un verdadero positivo, se obtiene una puntuación de exhaustividad perfecta.
RecallMacro-
La
RecallMacrocalcula la exhaustividad para problemas de clasificación multiclase calculando la exhaustividad para cada clase y promediando las puntuaciones a fin de obtener la exhaustividad de varias clases. Las puntuaciones deRecallMacrovan del 0 al 1. Las puntuaciones más altas reflejan la capacidad del modelo para predecir positivos verdaderos (TP) en un conjunto de datos, mientras que un resultado positivo verdadero refleja una predicción positiva que también es un valor positivo real en los datos. A menudo, no basta con medir solo la exhaustividad, ya que, si se predice cada salida como un verdadero positivo, se obtiene una puntuación de exhaustividad perfecta. RMSE-
La raíz del error cuadrático medio (RMSE) mide la raíz cuadrada de la diferencia cuadrática entre los valores pronosticados y los reales, y se promedia sobre todos los valores. Se utiliza en el análisis de regresión para comprender el error de predicción del modelo. Es una métrica importante para indicar la presencia de valores atípicos y errores de modelo grandes. Los valores van desde cero (0) hasta infinito, y los números más pequeños indican el modelo que se ajusta mejor a los datos. El RMSE depende de la escala y no debe usarse para comparar conjuntos de datos de diferentes tamaños.
Las métricas que se calculan automáticamente para un candidato a modelo vienen determinadas por el tipo de problema que se está abordando.
Consulta la documentación de referencia de la SageMaker API de Amazon para ver la lista de métricas disponibles compatibles con Autopilot.
Métricas ponderadas en Piloto automático
nota
Piloto automático solo admite ponderaciones de muestra en el modo de ensamblaje y para todas las métricas disponibles, con la excepción de Balanced Accuracy y InferenceLatency. BalanceAccuracy viene con su propio esquema de ponderación para conjuntos de datos desequilibrados que no requieren ponderaciones de muestra. InferenceLatency no admite ponderaciones de muestra. Las métricas objetivo Balanced Accuracy y InferenceLatency ignoran las ponderaciones de muestra existentes al entrenar y evaluar un modelo.
Los usuarios pueden añadir una columna de ponderaciones de muestra a sus datos para garantizar que cada observación utilizada para entrenar un modelo de machine learning reciba una ponderación correspondiente a su importancia percibida para el modelo. Esto resulta especialmente útil en escenarios en los que las observaciones del conjunto de datos tienen distintos grados de importancia, o cuando un conjunto de datos contiene un número desproporcionado de muestras de una clase en comparación con otras. La asignación de una ponderación a cada observación en función de su importancia, o mayor importancia, para una clase minoritaria puede mejorar el rendimiento general del modelo o garantizar que este no esté sesgado hacia la clase mayoritaria.
Para obtener información sobre cómo pasar los pesos de las muestras al crear un experimento en la interfaz de usuario de Studio Classic, consulte el paso 7 de Crear un experimento de piloto automático con Studio Classic.
Para obtener información sobre cómo pasar las ponderaciones de muestra mediante programación al crear un experimento de Piloto automático mediante la API, consulte How to add sample weights to an AutoML job en Create an Autopilot experiment programmatically.
Validación cruzada en Piloto automático
La validación cruzada se utiliza para reducir el sobreajuste y el sesgo en la selección del modelo. También se usa para evaluar el rendimiento de un modelo al predecir los valores de un conjunto de datos de validación no observable si el conjunto de datos de validación se extrae de la misma población. Este método es especialmente importante cuando se entrena con conjuntos de datos que tienen un número limitado de instancias de entrenamiento.
Piloto automático utiliza la validación cruzada para crear modelos en la optimización de hiperparámetros (HPO) y en el modo de entrenamiento por ensamblaje. El primer paso del proceso de validación cruzada con Piloto automático consiste en dividir los datos en k particiones.
División en k-particiones
La división en k-particiones es un método que separa un conjunto de datos de entrenamiento de entrada en varios conjuntos de datos de entrenamiento y validación. El conjunto de datos se divide en k submuestras del mismo tamaño, denominadas particiones. Luego, los modelos se entrenan en k-1 particiones y se prueban comparándolos con la partición número k restante, que es el conjunto de datos de validación. El proceso se repite k veces utilizando un conjunto de datos diferente para la validación.
La siguiente imagen muestra la división de k particiones con k = 4 particiones. Cada partición se representa como una fila. Los recuadros de tonos oscuros representan las partes de los datos utilizadas en el entrenamiento. Los recuadros restantes, en tonos claros, indican los conjuntos de datos de validación.

Piloto automático utiliza la validación cruzada de k-particiones tanto en el modo de optimización de hiperparámetros (HPO) como en el de ensamblaje.
Puede implementar modelos de piloto automático creados mediante validación cruzada como lo haría con cualquier otro modelo o piloto automático. SageMaker
Modo HPO
La validación cruzada en k-particiones utiliza el método de división k-particiones para la validación cruzada. En el modo HPO, Piloto automático implementa automáticamente la validación cruzada de k-particiones para conjuntos de datos pequeños con 50 000 instancias de entrenamiento o menos. Realizar una validación cruzada es especialmente importante cuando se entrena con conjuntos de datos pequeños, ya que protege contra el sobreajuste y el sesgo de selección.
El modo HPO utiliza un valor k de 5 en cada uno de los algoritmos candidatos que se utilizan para modelar el conjunto de datos. Varios modelos se entrenan en diferentes divisiones y los modelos se almacenan por separado. Cuando se completa el entrenamiento, las métricas de validación de cada uno de los modelos se promedian para producir una única métrica de estimación. Por último, Piloto automático combina los modelos de la prueba con la mejor métrica de validación en un modelo de ensamblaje. Piloto automático utiliza este modelo de ensamblaje para hacer predicciones.
La métrica de validación de los modelos entrenados por Piloto automático se presenta como métrica objetivo en la tabla de clasificación de modelos. Piloto automático utiliza la métrica de validación predeterminada para cada tipo de problema que gestiona, a menos que especifique lo contrario. Para ver una lista de todas las métricas que Piloto automático utiliza, consulte Métricas de Piloto automático.
Por ejemplo, el conjunto de datos Boston Housing
La validación cruzada puede aumentar los tiempos de entrenamiento en un promedio del 20 %. Los tiempos de entrenamiento también pueden aumentar significativamente en el caso de conjuntos de datos complejos.
nota
En el modo HPO, puedes ver las métricas de entrenamiento y validación de cada pliegue de tus registros. /aws/sagemaker/TrainingJobs CloudWatch Para obtener más información sobre CloudWatch los registros, consulteRegistra los grupos y las transmisiones que Amazon SageMaker envía a Amazon CloudWatch Logs.
Modo de ensamblaje
nota
Piloto automático admite las ponderaciones de muestra en el modo de ensamblaje. Para obtener la lista de métricas compatibles con las ponderaciones de muestra, consulte Métricas de Piloto automático.
En el modo de ensamblaje, la validación cruzada se realiza independientemente del tamaño del conjunto de datos. Los clientes pueden proporcionar su propio conjunto de datos de validación y una tasa de división de datos personalizada o dejar que Piloto automático divida el conjunto de datos automáticamente con una tasa de división 80-20 %. A continuación, los datos de entrenamiento se dividen en k dos para realizar una validación cruzada, donde el motor k determina el AutoGluon valor de. Un conjunto consta de varios modelos de machine learning, cada uno de los cuales se denomina modelo base. Un único modelo base se basa en (k-1) pliegues y hace out-of-fold predicciones en el pliegue restante. Este proceso se repite para todos los k pliegues y las predicciones out-of-fold (OOF) se concatenan para formar un único conjunto de predicciones. Todos los modelos base del conjunto siguen este mismo proceso de generación de predicciones OOF.
La siguiente imagen muestra la división de k particiones, con k = 4 particiones. Cada partición se representa como una fila. Los recuadros de tonos oscuros representan las partes de los datos utilizadas en el entrenamiento. Los recuadros restantes, en tonos claros, indican los conjuntos de datos de validación.
En la parte superior de la imagen, en cada partición, el primer modelo base hace predicciones sobre el conjunto de datos de validación después de entrenar a los conjuntos de datos de entrenamiento. En cada partición posterior, los conjuntos de datos cambian de rol. Un conjunto de datos que antes se utilizaba para el entrenamiento ahora se utiliza para la validación y viceversa. Al final de los k pliegues, todas las predicciones se concatenan para formar un único conjunto de predicciones denominado predicción (OOF). out-of-fold Este proceso se repite para todos los modelos base n.
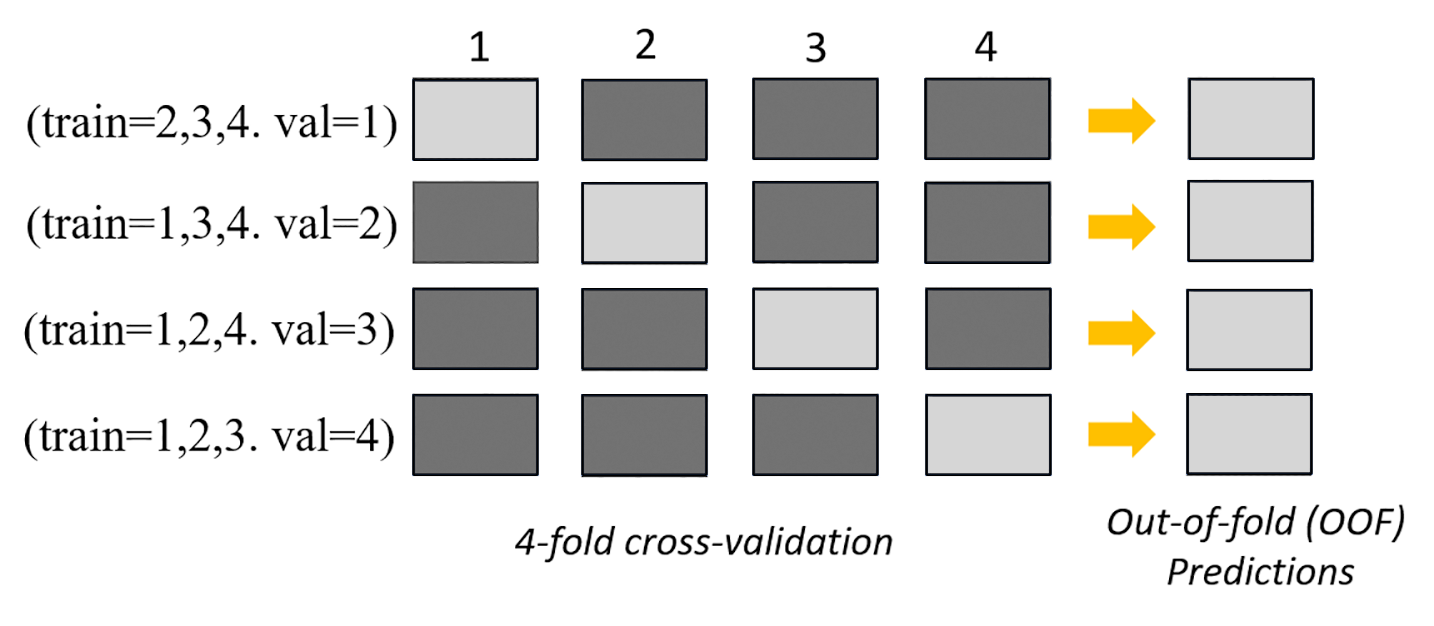
Luego, las predicciones OOF para cada modelo base se utilizan como características para entrenar un modelo de apilamiento. El modelo de apilamiento aprende las ponderaciones de importancia de cada modelo base. Estas ponderaciones se utilizan para combinar las predicciones OOF a fin de formar la predicción final. El rendimiento del conjunto de datos de validación determina qué modelo base o de apilamiento es el mejor, y este modelo se devuelve como modelo final.
En el modo de ensamblaje, puede proporcionar su propio conjunto de datos de validación o dejar que Piloto automático divida el conjunto de datos de entrada automáticamente (80 % entrenamiento y 20 % validación). A continuación, los datos de entrenamiento se dividen en k particiones para la validación cruzada, y generan una predicción OOF y un modelo base para cada partición.
Estas predicciones OOF se utilizan como características para entrenar un modelo de apilamiento, que aprende a la vez las ponderaciones de cada modelo base. Estas ponderaciones se utilizan para combinar las predicciones OOF a fin de formar la predicción final. Los conjuntos de datos de validación de cada partición se utilizan para ajustar los hiperparámetros de todos los modelos base y del modelo de apilamiento. El rendimiento del conjunto de datos de validación determina qué modelo base o de apilamiento es el mejor, y este modelo se devuelve como modelo final.
