Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Un informe de calidad de un modelo de Amazon SageMaker AI (también denominado informe de rendimiento) proporciona información valiosa e información de calidad para el mejor candidato de modelo generado por un trabajo de AutoML. Incluye información sobre los detalles del trabajo, el tipo de problema del modelo, la función objetivo y otros datos relacionados con el tipo de problema. Esta guía muestra cómo ver las métricas de rendimiento del piloto automático de Amazon SageMaker AI de forma gráfica o cómo ver las métricas como datos sin procesar en un archivo JSON.
Por ejemplo, en el caso de los problemas de clasificación, el informe de calidad del modelo incluye lo siguiente:
-
Matriz de confusión
-
El área bajo la curva característica de funcionamiento del receptor (AUC).
-
Información para entender los falsos positivos y los falsos negativos
-
Compensaciones entre positivos verdaderos y falsos positivos
-
Compensación entre precisión y exhaustividad
Piloto automático también proporciona métricas de rendimiento para todos los modelos candidatos. Estas métricas se calculan con todos los datos de entrenamiento y se utilizan para estimar el rendimiento del modelo. El área de trabajo principal incluye estas métricas de forma predeterminada. El tipo de métrica viene determinado por el tipo de problema que se está abordando.
Consulta la documentación de referencia de la SageMaker API de Amazon para ver la lista de métricas disponibles compatibles con Autopilot.
Puede ordenar los modelos candidatos con la métrica correspondiente para ayudarle a seleccionar e implementar el modelo que mejor se adapte a las necesidades de su empresa. Para ver las definiciones de estas métricas, consulte el tema Métricas de piloto automático.
Para ver un informe de rendimiento de un trabajo de Piloto automático, siga estos pasos:
-
Seleccione el icono Inicio (
 ) en el panel de navegación izquierdo para ver el menú de navegación de nivel superior de Amazon SageMaker Studio Classic.
) en el panel de navegación izquierdo para ver el menú de navegación de nivel superior de Amazon SageMaker Studio Classic. -
Seleccione la tarjeta AutoML en el área de trabajo principal. Se abrirá una nueva pestaña Piloto automático.
-
En la sección Nombre, seleccione el trabajo de Piloto automático que contenga los detalles que desee examinar. Se abrirá una nueva pestaña Trabajo de Piloto automático.
-
El panel Trabajos de Piloto automático muestra los valores de las métricas, incluida la métrica objetivo, de cada modelo bajo el Nombre del modelo. El mejor modelo aparece en la parte superior de la lista, bajo el Nombre del modelo, y aparece resaltado en la pestaña Modelos.
-
Para revisar la información sobre el modelo, seleccione el modelo que le interese y Ver detalles del modelo. Se abrirá una nueva pestaña Detalles del modelo.
-
-
Seleccione la pestaña Rendimiento, entre las pestañas Explicabilidad y Artefactos.
-
En la sección superior derecha de la pestaña, selecciona la flecha hacia abajo, en el botón Descargar informes de rendimiento.
-
La flecha hacia abajo ofrece dos opciones para ver las métricas de rendimiento en Piloto automático:
-
Puede descargar un PDF del informe de rendimiento para ver las métricas de forma gráfica.
-
Puede ver las métricas como datos sin procesar y descargarlos como un archivo JSON.
-
-
Para obtener instrucciones sobre cómo crear y ejecutar un trabajo de AutoML en SageMaker Studio Classic, consulte. Creación de trabajos de regresión o clasificación para datos tabulares mediante la API de AutoML
El informe de rendimiento consta de dos secciones. La primera sección contiene detalles sobre el trabajo de Piloto automático generado por el modelo. La segunda sección contiene un informe de calidad del modelo.
Detalles del trabajo en Piloto automático
Esta primera sección del informe proporciona información general sobre el trabajo de Piloto automático que ha generado el modelo. En estos detalles del trabajo, se incluye la siguiente información:
-
Nombre del candidato en Piloto automático
-
Nombre del trabajo en Piloto automático
-
Tipo de problema
-
Métrica objetiva
-
Dirección de optimización
Informe de calidad del modelo
La información sobre la calidad del modelo se genera mediante la información sobre modelos de Piloto automático. El contenido del informe que se genera depende del tipo de problema que se aborde: regresión, clasificación binaria o clasificación multiclase. El informe especifica el número de filas que se incluyeron en el conjunto de datos de evaluación y el momento en que se realizó la evaluación.
Tablas de métricas
La primera parte del informe de calidad del modelo contiene tablas de métricas. Son las adecuadas para el tipo de problema que abordó el modelo.
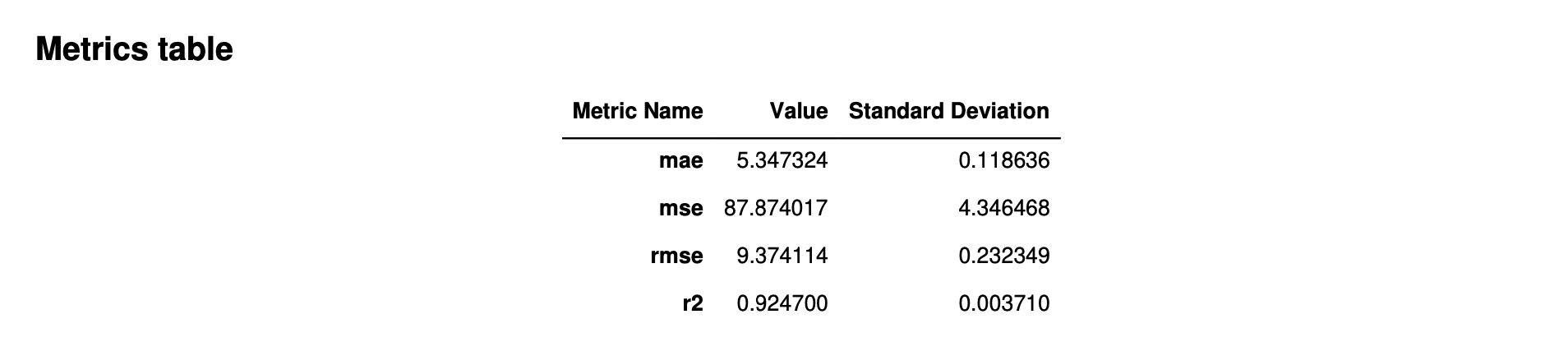
La siguiente imagen es un ejemplo de una tabla de métricas que Piloto automático genera para un problema de regresión. Muestra el nombre, el valor y la desviación estándar de la métrica.
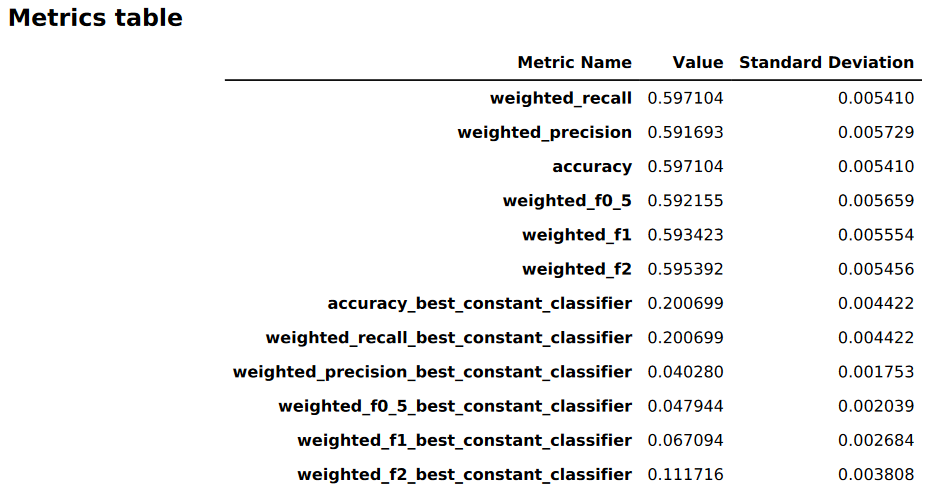
La siguiente imagen es un ejemplo de una tabla de métricas generada por Piloto automático para un problema de clasificación multiclase. Muestra el nombre, el valor y la desviación estándar de la métrica.
Información gráfica sobre el rendimiento del modelo
La segunda parte del informe de calidad del modelo contiene información gráfica para ayudarle a evaluar el rendimiento del modelo. El contenido de esta sección depende del tipo de problema usado en la generación del modelo.
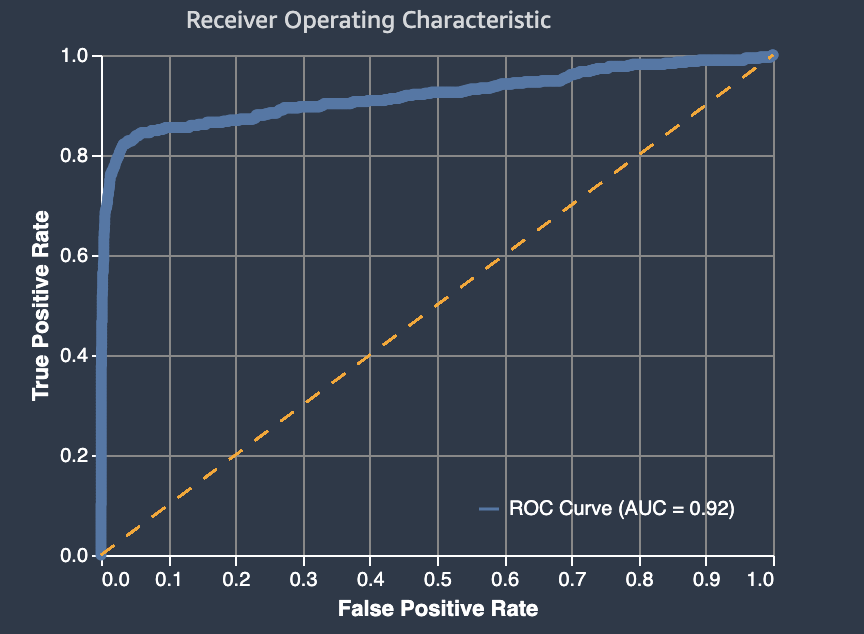
El área bajo la curva característica de funcionamiento del receptor
El área bajo la curva característica de funcionamiento del receptor representa la compensación entre las tasas de positivos verdaderos y falsos positivos. Es una métrica de precisión estándar del sector que se utiliza para los modelos de clasificación binaria. El AUC mide la capacidad del modelo de predecir una mayor puntuación para ejemplos positivos en comparación con ejemplos negativos. El AUC proporciona una medida agregada del rendimiento del modelo en todos los umbrales de clasificación posibles.
La métrica AUC devuelve un valor decimal comprendido entre 0 y 1. Los valores de AUC próximos a 1 indican un modelo de machine learning muy preciso. Los valores cercanos a 0,5 indican un modelo de ML que no es mejor que hacer una suposición al azar. Los valores de AUC cercanos a 0 indican que el modelo ha aprendido los patrones correctos, pero está realizando las predicciones más imprecisas posibles. Los valores cercanos a cero pueden indicar un problema con los datos. Para obtener más información sobre la métrica AUC, vaya al artículo Curva ROC
Lo que sigue es un ejemplo de un gráfico de área bajo la curva característica de funcionamiento del receptor para evaluar las predicciones realizadas mediante un modelo de clasificación binaria. La línea fina discontinua representa el área bajo la curva característica de funcionamiento del receptor que obtendría un modelo que clasifique las no-better-than-random suposiciones, con una puntuación de AUC de 0,5. Las curvas de los modelos de clasificación más precisos se sitúan por encima de esta línea de base aleatoria, en la que la tasa de positivos verdaderos supera a la tasa de falsos positivos. El área situada debajo de la curva característica de funcionamiento del receptor, que representa el rendimiento del modelo de clasificación binaria, es la línea continua más gruesa.
Los componentes del gráfico de tasa de falsos positivos (FPR) y tasa de positivos reales (TPR) se definen de la siguiente manera.
-
Predicciones correctas
-
Positivo real (TP): el valor pronosticado es 1 y el valor real es 1.
-
Negativo real (TN): el valor pronosticado es 0 y el valor real es 0.
-
-
Predicciones erróneas
-
Positivo falso (FP): el valor pronosticado es 1, pero el valor real es 0.
-
Falso negativo (FN): el valor pronosticado es 0, pero el valor real es 1.
-
La tasa de falsos positivos (FPR) mide la fracción de negativos verdaderos (TN) que se predijeron falsamente como positivos (FP), sobre la suma de FP y TN. El rango va de 0 a 1. Un valor bajo indica una mayor exactitud predictiva.
-
FPR = FP/(FP+TN)
La tasa de positivos reales (TPR) mide la fracción de positivos reales que se predijeron correctamente como positivos (TP), sobre la suma de TP y falsos negativos (FN). El rango va de 0 a 1. Un valor mayor indica mejor exactitud predictiva.
-
TPR = TP/(TP+FN)
Matriz de confusión
Una matriz de confusión es una forma de visualizar la precisión de las predicciones realizadas por un modelo para la clasificación binaria y multiclase de diferentes problemas. La matriz de confusión del informe de calidad del modelo contiene lo siguiente.
-
El número y el porcentaje de predicciones correctas e incorrectas para las etiquetas reales
-
El número y el porcentaje de predicciones precisas en la diagonal desde la esquina superior izquierda hasta la esquina inferior derecha
-
El número y el porcentaje de predicciones incorrectas en la diagonal desde la esquina superior derecha hasta la esquina inferior izquierda
Las predicciones incorrectas en una matriz de confusión son los valores de confusión.
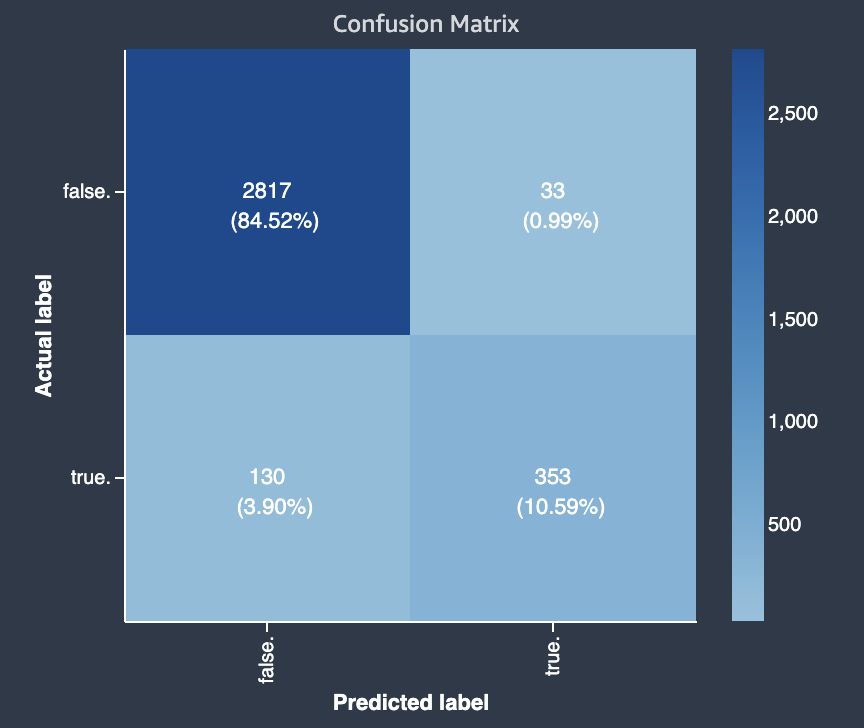
El diagrama siguiente muestra un ejemplo de matriz de confusión para un problema de clasificación binaria. Contiene la siguiente información:
-
El eje vertical está dividido en dos filas que contienen etiquetas reales verdaderas y falsas.
-
El eje horizontal se divide en dos columnas que contienen las etiquetas verdadero y falso que predijo el modelo.
-
La barra de colores asigna un tono más oscuro a un número mayor de muestras para indicar visualmente el número de valores que se clasificaron en cada categoría.
En este ejemplo, el modelo predijo correctamente 2817 valores falsos reales y 353 valores verdaderos reales correctamente. El modelo predijo incorrectamente que 130 valores verdaderos eran falsos y que 33 valores falsos eran verdaderos. La diferencia de tono indica que el conjunto de datos no está equilibrado. El desequilibrio se debe a que hay muchas más etiquetas falsas reales que etiquetas verdaderas.
El diagrama siguiente muestra un ejemplo de matriz de confusión para un problema de clasificación multiclase. La matriz de confusión del informe de calidad del modelo contiene lo siguiente.
-
El eje vertical se divide en tres filas que contienen tres etiquetas reales diferentes.
-
El eje horizontal se divide en tres columnas que contienen las etiquetas que predijo el modelo.
-
La barra de colores asigna un tono más oscuro a un número mayor de muestras para indicar visualmente el número de valores que se clasificaron en cada categoría.
En el siguiente ejemplo, el modelo predijo correctamente 354 valores reales para la etiqueta f, 1094 valores para la etiqueta i y 852 valores para la etiqueta m. La diferencia en el tono indica que el conjunto de datos no está equilibrado, ya que hay muchas más etiquetas para el valor i que para f o m.
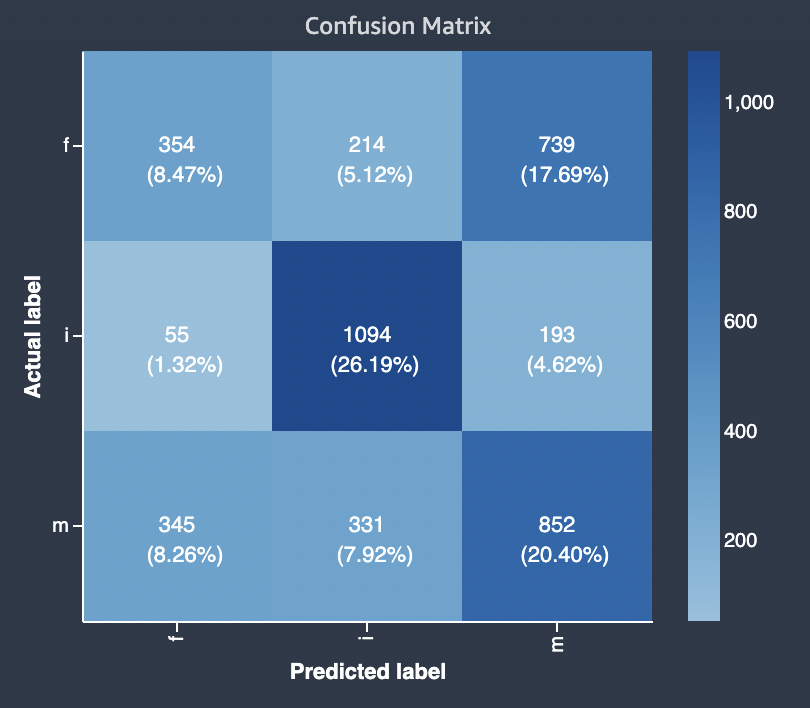
La matriz de confusión del informe de calidad del modelo proporcionado puede incluir un máximo de 15 etiquetas para los tipos de problemas de clasificación multiclase. Si una fila correspondiente a una etiqueta muestra un valor Nan, significa que el conjunto de datos de validación utilizado para comprobar las predicciones del modelo no contiene datos con esa etiqueta.
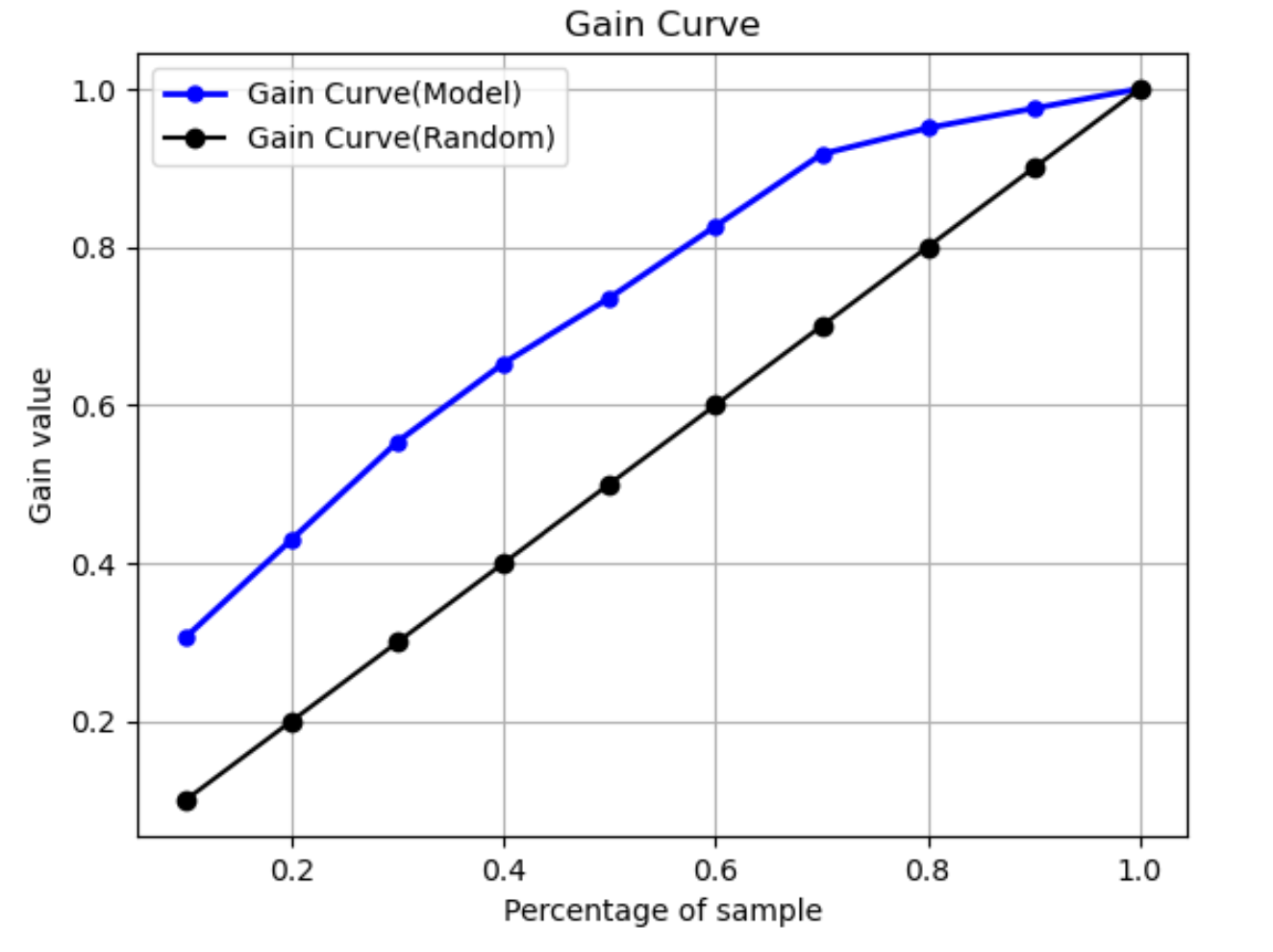
Curva de ganancia
En la clasificación binaria, una curva de ganancia predice el beneficio acumulado de usar un porcentaje del conjunto de datos para encontrar una etiqueta positiva. El valor de ganancia se calcula durante el entrenamiento dividiendo el número acumulado de observaciones positivas entre el número total de observaciones positivas de los datos, en cada decil. Si el modelo de clasificación creado durante el entrenamiento es representativo de los datos no observados, puede usar la curva de ganancia para predecir el porcentaje de datos en el que debe concentrarse para obtener un porcentaje de etiquetas positivas. Cuanto mayor sea el porcentaje del conjunto de datos utilizado, mayor será el porcentaje de etiquetas positivas encontradas.
En el siguiente gráfico de ejemplo, la curva de ganancia es la línea con pendiente variable. La línea recta es el porcentaje de etiquetas positivas que se encuentran al seleccionar un porcentaje de datos del conjunto de datos de forma aleatoria. Al segmentar el 20 % del conjunto de datos, lo normal sería encontrar más del 40 % de las etiquetas positivas. Por ejemplo, podría usar una curva de ganancia para determinar en qué concentrarse en una campaña de marketing. Con nuestro ejemplo de curva de ganancia, si el 83 % de las personas de un vecindario compraran galletas, le enviaría un anuncio a aproximadamente el 60 % del vecindario.
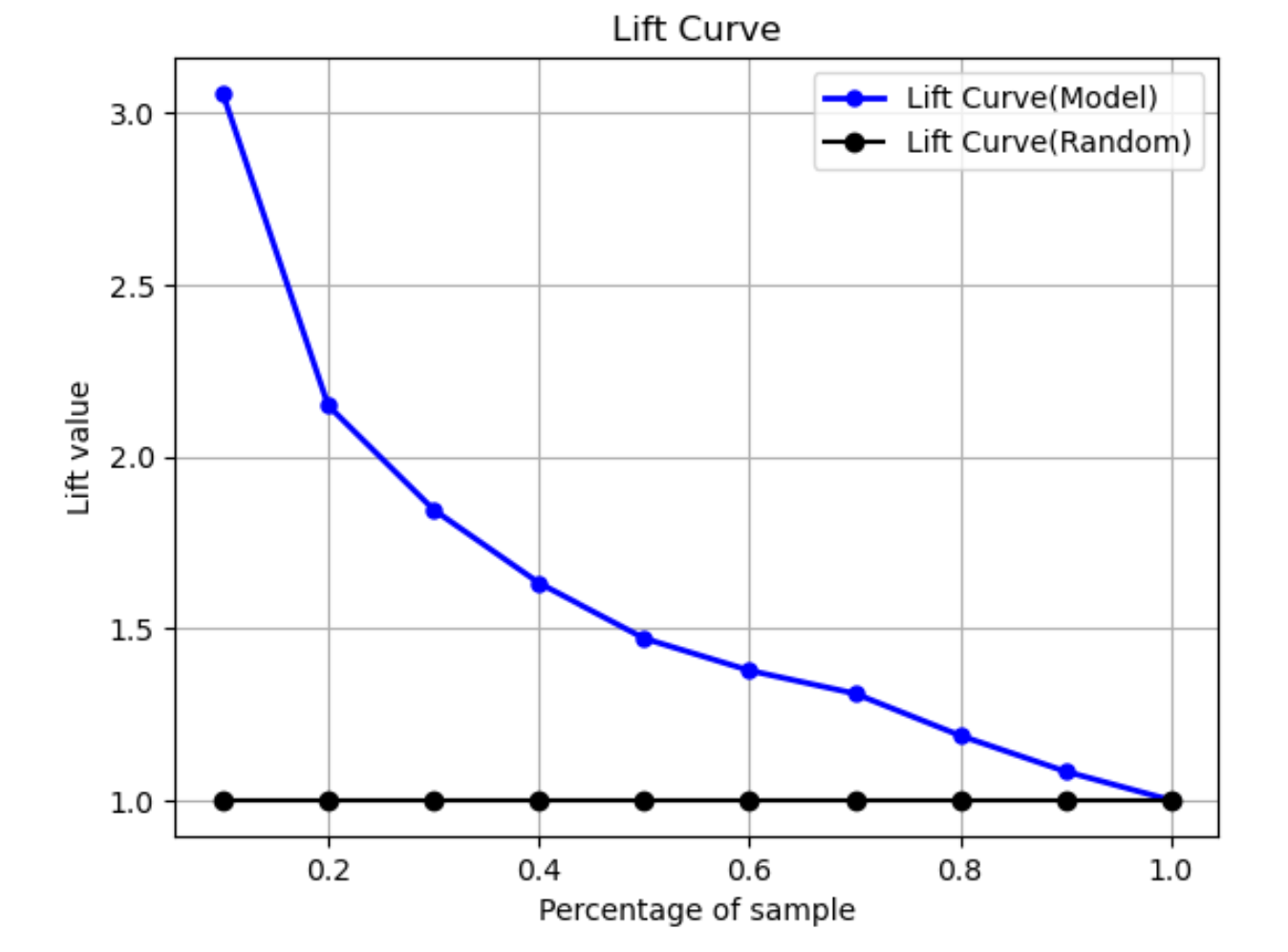
Curva de elevación
En la clasificación binaria, la curva de elevación ilustra la elevación que supone utilizar un modelo entrenado para predecir la probabilidad de encontrar una etiqueta positiva en comparación con una suposición aleatoria. El valor de elevación se calcula durante el entrenamiento utilizando la relación entre el porcentaje de ganancia y la proporción de etiquetas positivas en cada decil. Si el modelo creado durante el entrenamiento es representativo de los datos no observados, use la curva de elevación para predecir la ventaja de usar el modelo en lugar de hacer predicciones aleatorias.
En el siguiente gráfico de ejemplo, la curva de elevación es la línea con pendiente variable. La línea recta es la curva de elevación asociada a la selección aleatoria del porcentaje correspondiente del conjunto de datos. Al seleccionar aleatoriamente el 40 % del conjunto de datos con las etiquetas de clasificación de su modelo, lo normal sería encontrar aproximadamente 1,7 veces el número de etiquetas positivas que habría encontrado al seleccionar aleatoriamente el 40 % de los datos no observados.
Curva de precisión/exhaustividad
La curva de precisión/exhaustividad representa la compensación entre precisión y exhaustividad en problemas de clasificación binaria.
La precisión mide la fracción de positivos reales que se predicen como positivos (TP) de entre todas las predicciones positivas (TP y falsos positivos). El rango va de 0 a 1. Un valor mayor indica mejor exactitud predictiva.
-
Precisión = TP/(TP+FP)
La exhaustividad mide la fracción de positivos reales (TP) que se predicen como positivos de entre todas las predicciones positivas reales (TP y falsos negativos). También se conoce como sensibilidad o tasa positiva verdadera. El rango va de 0 a 1. Un valor mayor indica una mejor detección de los valores positivos de la muestra.
-
Exhaustividad = TP/(TP+FN)
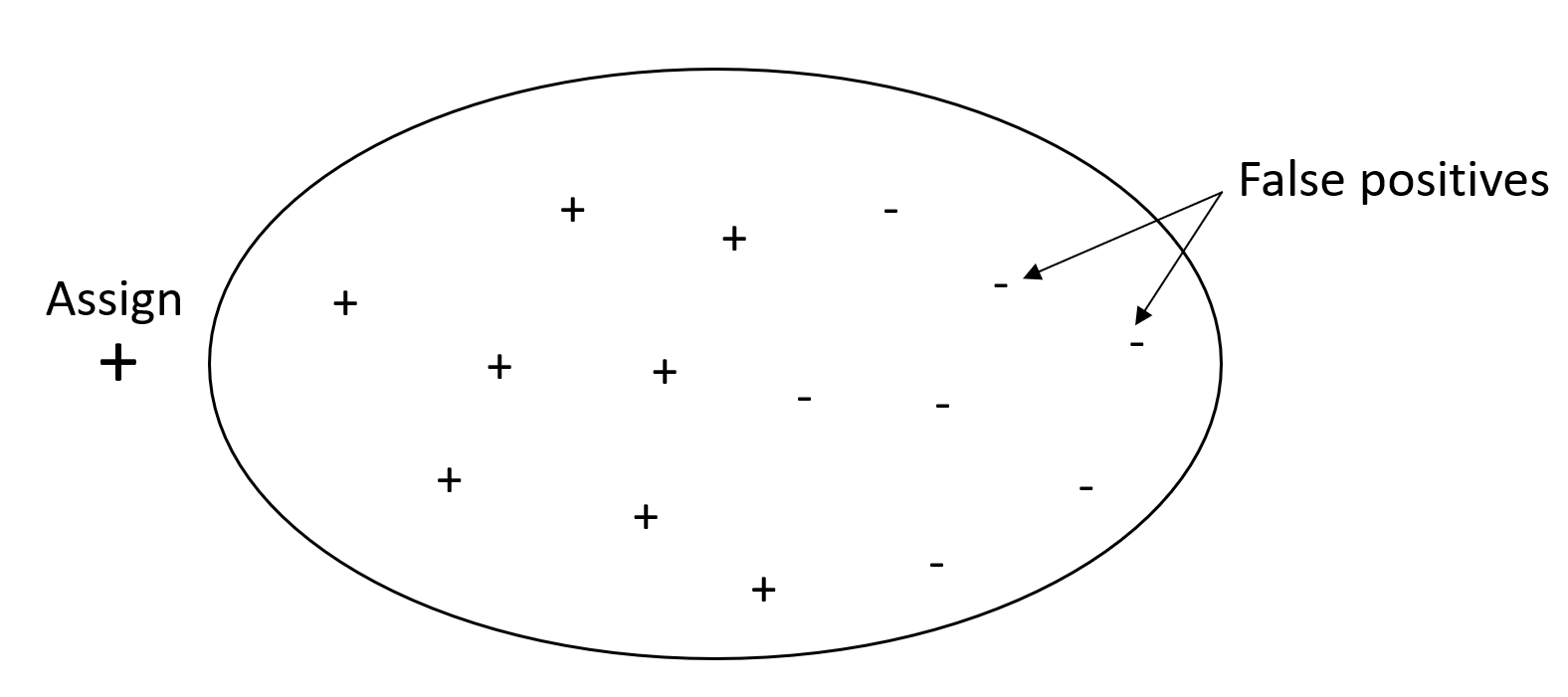
El objetivo de un problema de clasificación es etiquetar correctamente tantos elementos como sea posible. Un sistema con un nivel alto de exhaustividad, pero con un nivel bajo de precisión, arroja un alto porcentaje de falsos positivos.
El siguiente gráfico muestra un filtro de spam que marca todos los correos electrónicos como spam. Tiene un alto nivel de exhaustividad, pero una precisión baja, ya que la exhaustividad no mide los falsos positivos.
Otórguele más importancia a la exhaustividad que a la precisión si el problema que está abordando tiene una penalización baja por declarar falsos positivos, pero una penalización alta por omitir positivos verdaderos. Por ejemplo, la detección de una colisión inminente en un vehículo autónomo.
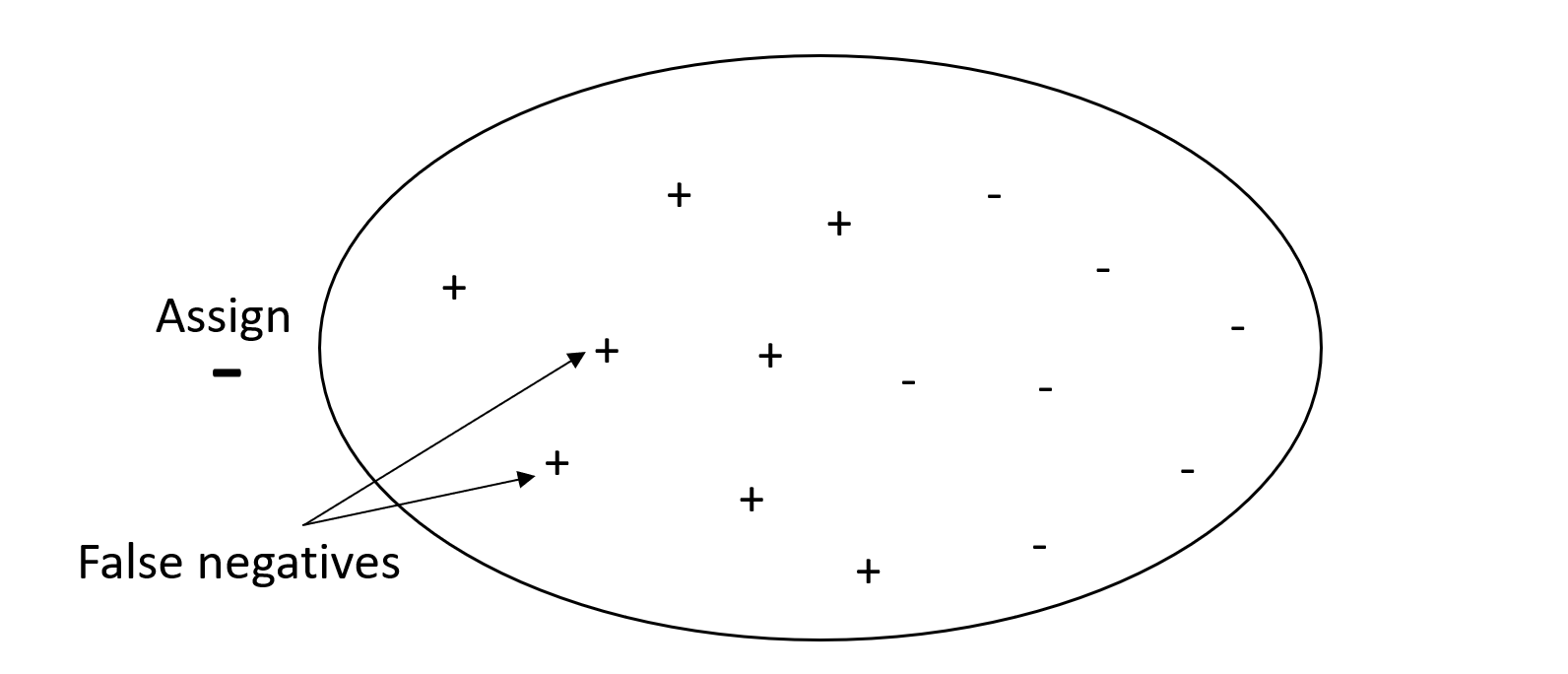
Por otro lado, un sistema con un nivel alto de precisión, pero con un nivel bajo de exhaustividad, arroja un alto porcentaje de falsos negativos. Un filtro de spam que marca todos los correos electrónicos como deseables (no spam) tiene una alta precisión, pero un nivel bajo de exhaustividad, ya que la precisión no mide los falsos negativos.
Otórguele más importancia a la precisión que a la exhaustividad si el problema que está abordando tiene una penalización baja por declarar falsos negativos, pero una penalización alta por omitir negativos verdaderos. Por ejemplo, marcar un filtro sospechoso para una auditoría fiscal.
En el siguiente gráfico se muestra un filtro de spam con un nivel alto de precisión, pero un nivel bajo de exhaustividad, ya que la precisión no mide los falsos negativos.
Un modelo que hace predicciones con un nivel alto de precisión y exhaustividad genera una gran cantidad de resultados correctamente etiquetados. Para obtener más información, consulte el artículo Precisión y exhaustividad
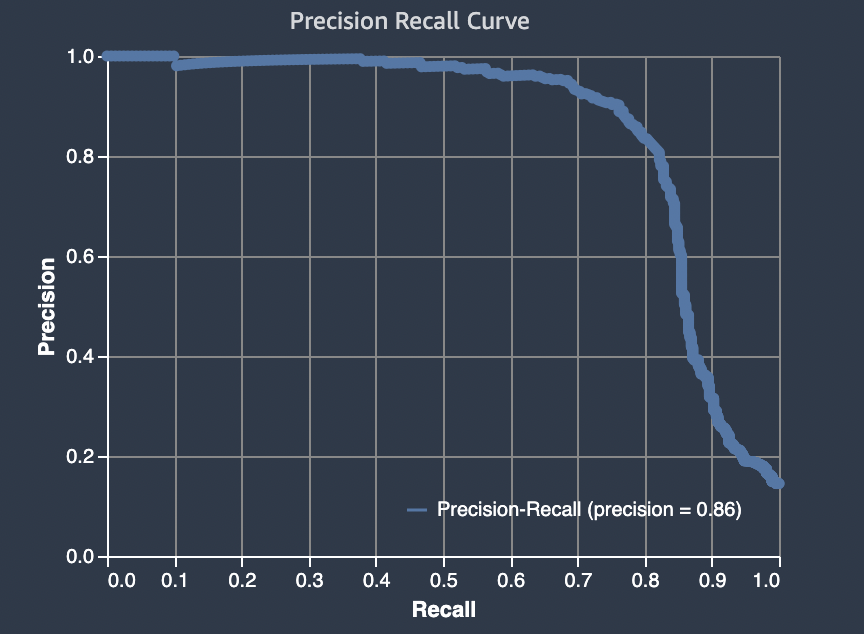
Área bajo la curva de precisión/exhaustividad (AUPRC)
Para problemas de clasificación binaria, Amazon SageMaker Autopilot incluye un gráfico del área bajo la curva de recuperación de precisión (AUPRC). La métrica AUPRC proporciona una medida agregada del rendimiento del modelo en todos los umbrales de clasificación posibles, y utiliza tanto la precisión como la exhaustividad. La AUPRC no tiene en cuenta el número de negativos verdaderos. Por lo tanto, puede resultar útil evaluar el rendimiento del modelo en los casos en que haya una gran cantidad de negativos verdaderos en los datos. Por ejemplo, para modelar un gen que contiene una mutación poco frecuente.
El siguiente gráfico es un ejemplo de un gráfico AUPRC. La precisión, en su nivel más alto, es 1 y la exhaustividad es 0. En la esquina inferior derecha del gráfico, la exhaustividad está en su valor más alto (1) y la precisión es 0. Entre estos dos puntos, la curva AUPRC ilustra la compensación entre precisión y exhaustividad en diferentes umbrales.
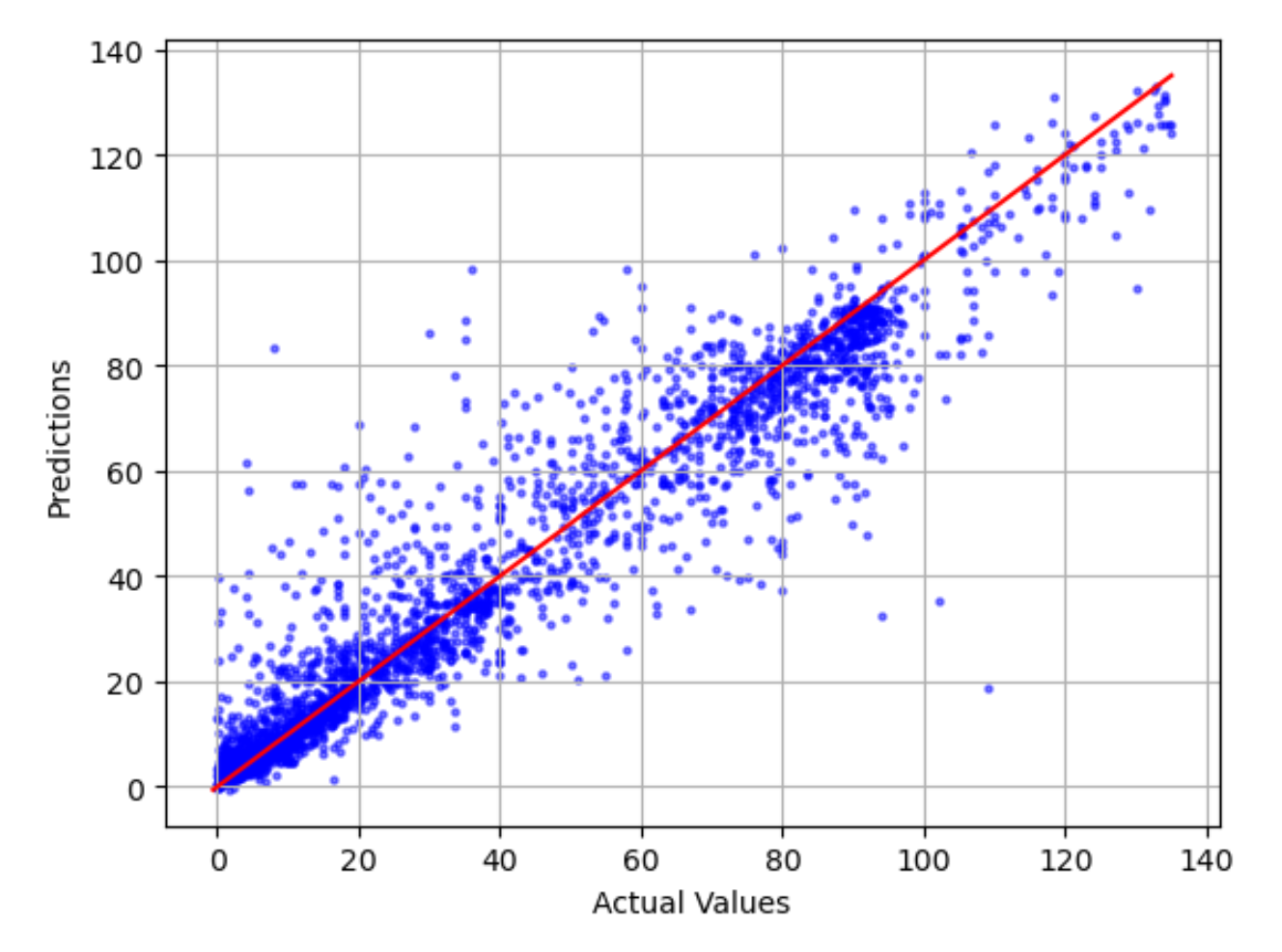
Comparación entre la gráfica real y la prevista
La comparación entre la gráfica real y la prevista muestra la diferencia entre los valores reales y previstos del modelo. En el siguiente gráfico de ejemplo, la línea continua representa la mejor opción. Si el modelo tuviera una precisión del 100 %, cada punto previsto sería igual a su punto real correspondiente y estaría situado en esta línea de la mejor opción. La distancia desde la línea de mejor opción es una indicación visual del error del modelo. Cuanto mayor sea la distancia desde la línea de mejor opción, mayor será el error del modelo.
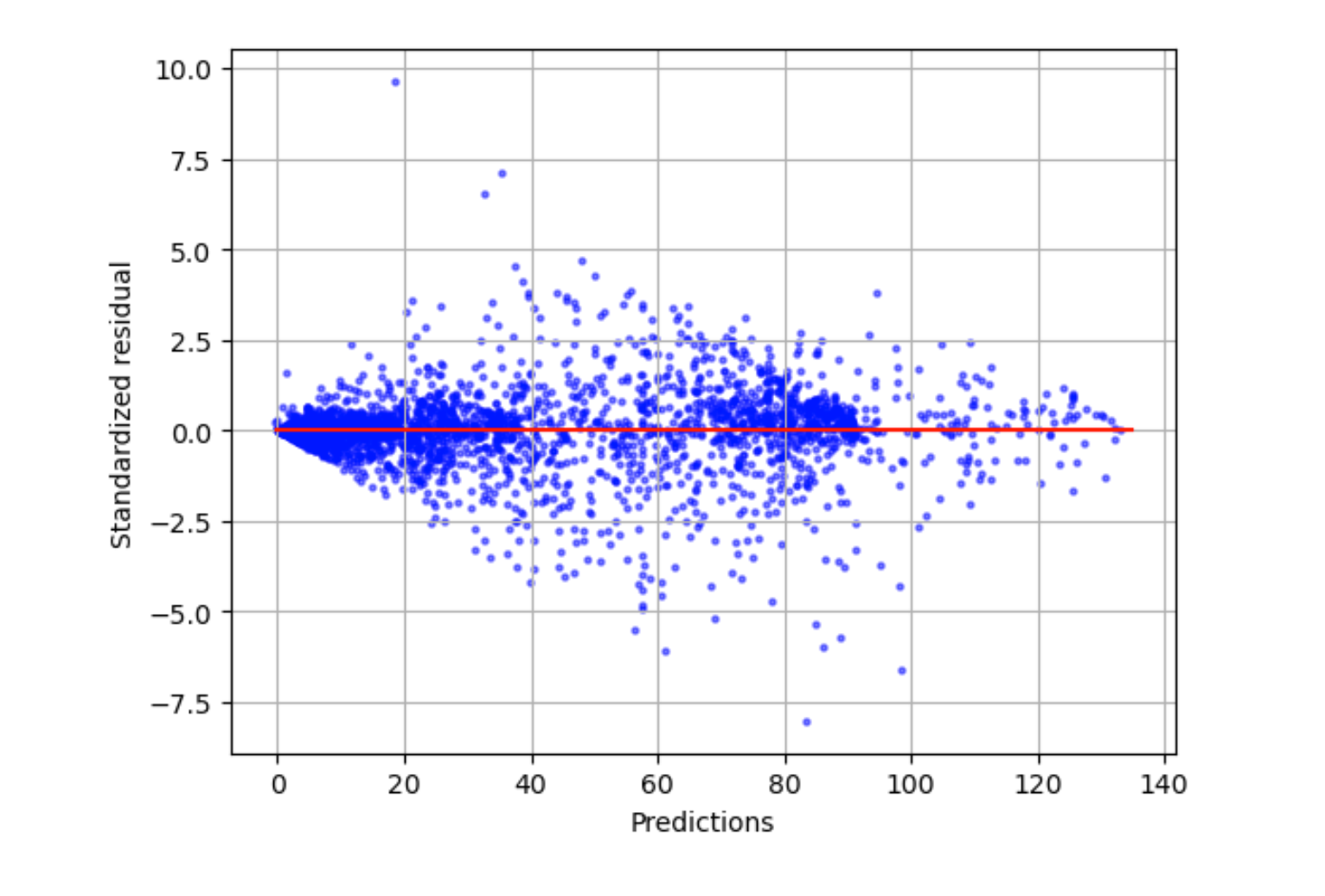
Gráfica residual estandarizada
Una gráfica residual estandarizada incorpora los siguientes términos estadísticos:
residual-
Un residual (sin procesar) muestra la diferencia entre los valores reales y los pronosticados por el modelo. Cuanto mayor sea la diferencia, mayor será el valor residual.
standard deviation-
La desviación estándar es una medida de cómo varían los valores con respecto a un valor promedio. Una desviación estándar alta indica que muchos valores son muy diferentes a su valor promedio. Una desviación estándar baja indica que muchos valores son similares a su valor promedio.
standardized residual-
Un valor residual estandarizado divide los residuales sin procesar por su desviación estándar. Los residuales estandarizados tienen unidades de desviación estándar y son útiles para identificar valores atípicos en los datos, independientemente de la diferencia de escala de los residuales sin procesar. Si un residual estandarizado es mucho más pequeño o más grande que los demás residuales estandarizados, esto indica que el modelo no se ajusta bien a estas observaciones.
La gráfica de residuales estandarizada mide la intensidad de la diferencia entre los valores observados y esperados. El valor previsto real se muestra en el eje x. Un punto con un valor superior a un valor absoluto de 3 suele considerarse un valor atípico.
El siguiente gráfico de ejemplo muestra que una gran cantidad de residuales estandarizados se agrupan alrededor de 0 en el eje horizontal. Los valores cercanos a cero indican que el modelo se ajusta bien a estos puntos. El modelo no predice bien los puntos hacia la parte superior e inferior de la gráfica.
Histograma residual
Un histograma residual estandarizado incorpora los siguientes términos estadísticos:
residual-
Un residual (sin procesar) muestra la diferencia entre los valores reales y los pronosticados por el modelo. Cuanto mayor sea la diferencia, mayor será el valor residual.
standard deviation-
La desviación estándar es una medida de cuánto varían los valores con respecto a un valor promedio. Una desviación estándar alta indica que muchos valores son muy diferentes a su valor promedio. Una desviación estándar baja indica que muchos valores son similares a su valor promedio.
standardized residual-
Un valor residual estandarizado divide los residuales sin procesar por su desviación estándar. Los residuales estandarizados tienen unidades de desviación estándar. Son útiles para identificar valores atípicos en los datos, independientemente de la diferencia de escala de los residuales sin procesar. Si un residual estandarizado es mucho más pequeño o más grande que los demás residuales estandarizados, el modelo no se ajusta bien a estas observaciones.
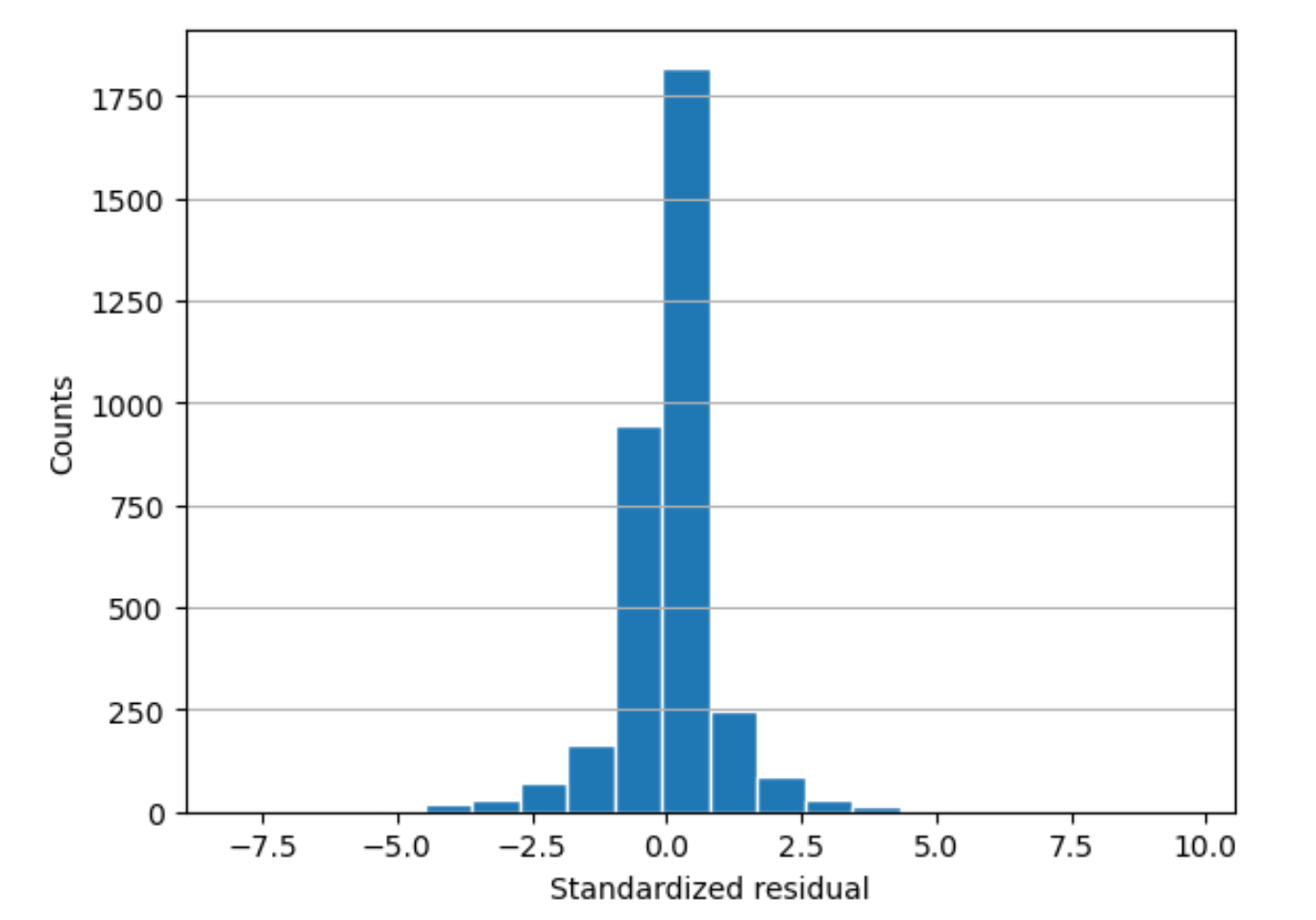
histogram-
Un histograma es un gráfico que muestra la frecuencia con la que ocurre un valor.
El histograma residual muestra la distribución de los valores residuales estandarizados. Un histograma distribuido en forma de campana y centrado en el cero indica que el modelo no subestima ni sobreestima sistemáticamente un rango determinado de valores objetivo.
En el siguiente gráfico, los valores residuales estandarizados indican que el modelo se ajusta bien a los datos. Si el gráfico mostrara valores muy alejados del valor central, eso indicaría que esos valores no se ajustan bien al modelo.