Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Ejemplos de código: SDK para Python
Esta sección proporciona un ejemplo de código para crear e invocar un punto final que utilice la explicabilidad en línea de SageMaker Clarify. En estos ejemplos de código se utiliza AWS SDKpara Python.
Datos tabulares
En el siguiente ejemplo se utilizan datos tabulares y un SageMaker modelo llamadomodel_name. En este ejemplo, el contenedor del modelo acepta datos en CSV formato y cada registro tiene cuatro características numéricas. En esta configuración mínima, únicamente con fines de demostración, los datos de SHAP referencia se establecen en cero. Consulte para SHAPLíneas de base para la explicabilidad obtener información sobre cómo elegir valores más adecuados paraShapBaseline.
Configure el punto de conexión de la siguiente manera:
endpoint_config_name = 'tabular_explainer_endpoint_config' response = sagemaker_client.create_endpoint_config( EndpointConfigName=endpoint_config_name, ProductionVariants=[{ 'VariantName': 'AllTraffic', 'ModelName': model_name, 'InitialInstanceCount': 1, 'InstanceType': 'ml.m5.xlarge', }], ExplainerConfig={ 'ClarifyExplainerConfig': { 'ShapConfig': { 'ShapBaselineConfig': { 'ShapBaseline': '0,0,0,0', }, }, }, }, )
Utilice la configuración de punto de conexión para crear un punto de conexión, de la siguiente manera:
endpoint_name = 'tabular_explainer_endpoint' response = sagemaker_client.create_endpoint( EndpointName=endpoint_name, EndpointConfigName=endpoint_config_name, )
Utilice el DescribeEndpoint API para inspeccionar el progreso de la creación de un punto final, de la siguiente manera:
response = sagemaker_client.describe_endpoint( EndpointName=endpoint_name, ) response['EndpointStatus']
Cuando el estado del punto final sea "InService«, invoque el punto final con un registro de prueba, de la siguiente manera:
response = sagemaker_runtime_client.invoke_endpoint( EndpointName=endpoint_name, ContentType='text/csv', Accept='text/csv', Body='1,2,3,4', )
nota
En el ejemplo de código anterior, en el caso de los puntos de conexión multimodelo, introduzca un parámetro TargetModel adicional en la solicitud para especificar a qué modelo debe dirigirse en el punto de conexión.
Suponga que la respuesta tiene un código de estado 200 (sin errores) y cargue el cuerpo de la respuesta de la siguiente manera:
import codecs import json json.load(codecs.getreader('utf-8')(response['Body']))
La acción predeterminada para el punto de conexión es explicar el registro. A continuación, se muestra un ejemplo de salida en el JSON objeto devuelto.
{ "version": "1.0", "predictions": { "content_type": "text/csv; charset=utf-8", "data": "0.0006380207487381" }, "explanations": { "kernel_shap": [ [ { "attributions": [ { "attribution": [-0.00433456] } ] }, { "attributions": [ { "attribution": [-0.005369821] } ] }, { "attributions": [ { "attribution": [0.007917749] } ] }, { "attributions": [ { "attribution": [-0.00261214] } ] } ] ] } }
Utilice el parámetro EnableExplanations para habilitar las explicaciones bajo demanda, de la siguiente manera:
response = sagemaker_runtime_client.invoke_endpoint( EndpointName=endpoint_name, ContentType='text/csv', Accept='text/csv', Body='1,2,3,4', EnableExplanations='[0]>`0.8`', )
nota
En el ejemplo de código anterior, en el caso de los puntos de conexión multimodelo, introduzca un parámetro TargetModel adicional en la solicitud para especificar a qué modelo debe dirigirse en el punto de conexión.
En este ejemplo, el valor de predicción es inferior al valor umbral de 0.8, por lo que no se explica el registro:
{ "version": "1.0", "predictions": { "content_type": "text/csv; charset=utf-8", "data": "0.6380207487381995" }, "explanations": {} }
Utilice herramientas de visualización para ayudar a interpretar las explicaciones devueltas. La siguiente imagen muestra cómo se pueden utilizar los SHAP gráficos para comprender cómo contribuye cada entidad a la predicción. El valor base del diagrama, también denominado valor esperado, es la media de las predicciones del conjunto de datos de entrenamiento. Las características que empujan el valor esperado hacia arriba aparecen en rojo y las características que empujan el valor esperado hacia abajo aparecen en azul. Consulte el diseño de fuerza SHAP aditiva
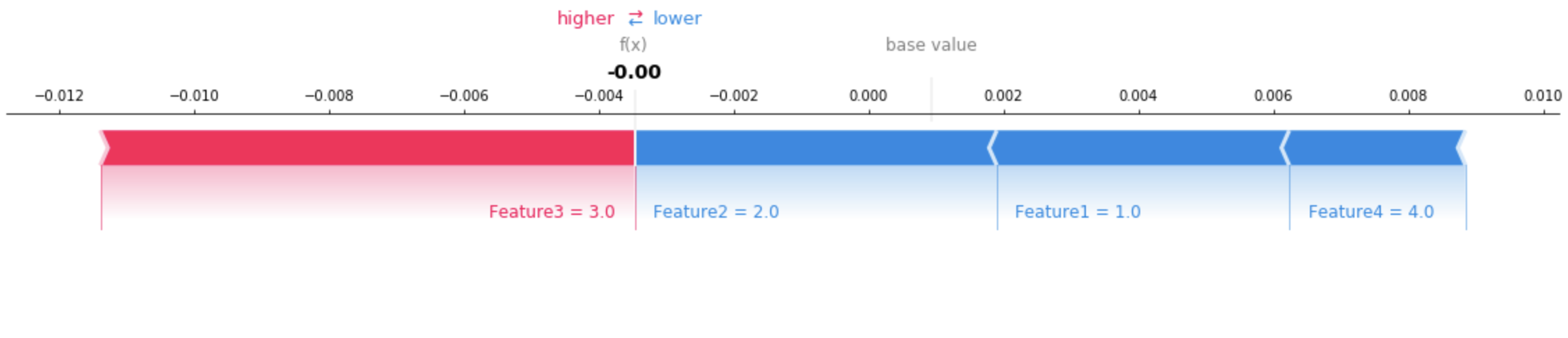
Consulte el cuaderno de ejemplos completo para datos tabulares
Datos de texto
En esta sección se proporciona un ejemplo de código para crear e invocar un punto de conexión de explicabilidad en línea para datos de texto. El ejemplo de código se usa SDK para Python.
En el siguiente ejemplo, se utilizan datos de texto y un SageMaker modelo llamadomodel_name. En este ejemplo, el contenedor del modelo acepta datos en CSV formato y cada registro es una cadena única.
endpoint_config_name = 'text_explainer_endpoint_config' response = sagemaker_client.create_endpoint_config( EndpointConfigName=endpoint_config_name, ProductionVariants=[{ 'VariantName': 'AllTraffic', 'ModelName': model_name, 'InitialInstanceCount': 1, 'InstanceType': 'ml.m5.xlarge', }], ExplainerConfig={ 'ClarifyExplainerConfig': { 'InferenceConfig': { 'FeatureTypes': ['text'], 'MaxRecordCount': 100, }, 'ShapConfig': { 'ShapBaselineConfig': { 'ShapBaseline': '"<MASK>"', }, 'TextConfig': { 'Granularity': 'token', 'Language': 'en', }, 'NumberOfSamples': 100, }, }, }, )
-
ShapBaseline: un token especial reservado para el procesamiento del lenguaje natural (NLP). -
FeatureTypes: identifica la característica como texto. Si no se proporciona este parámetro, el explicador intentará inferir el tipo de característica. -
TextConfig: especifica la unidad de granularidad y el idioma para el análisis de las características del texto. En este ejemplo, el idioma es el inglés y la granularidadtokensignifica una palabra en texto inglés. -
NumberOfSamples: un límite para establecer los límites superiores del tamaño del conjunto de datos sintéticos. -
MaxRecordCount: el número máximo de registros de una solicitud que puede gestionar el contenedor de modelos. Este parámetro se establece para estabilizar el rendimiento.
Utilice la configuración de punto de conexión para crear un punto de conexión, de la siguiente manera:
endpoint_name = 'text_explainer_endpoint' response = sagemaker_client.create_endpoint( EndpointName=endpoint_name, EndpointConfigName=endpoint_config_name, )
Cuando el estado del punto de conexión pase a ser InService, invoque el punto de conexión. En el siguiente ejemplo de código, se utiliza un registro de prueba de la siguiente manera:
response = sagemaker_runtime_client.invoke_endpoint( EndpointName=endpoint_name, ContentType='text/csv', Accept='text/csv', Body='"This is a good product"', )
Si la solicitud se completa correctamente, el cuerpo de la respuesta devolverá un JSON objeto válido similar al siguiente:
{ "version": "1.0", "predictions": { "content_type": "text/csv", "data": "0.9766594\n" }, "explanations": { "kernel_shap": [ [ { "attributions": [ { "attribution": [ -0.007270948666666712 ], "description": { "partial_text": "This", "start_idx": 0 } }, { "attribution": [ -0.018199033666666628 ], "description": { "partial_text": "is", "start_idx": 5 } }, { "attribution": [ 0.01970993241666666 ], "description": { "partial_text": "a", "start_idx": 8 } }, { "attribution": [ 0.1253469515833334 ], "description": { "partial_text": "good", "start_idx": 10 } }, { "attribution": [ 0.03291143366666657 ], "description": { "partial_text": "product", "start_idx": 15 } } ], "feature_type": "text" } ] ] } }
Utilice herramientas de visualización para ayudar a interpretar las atribuciones de texto devueltas. La siguiente imagen muestra cómo se puede utilizar la utilidad de visualización de captum para comprender cómo contribuye cada palabra a la predicción. Cuanto mayor sea la saturación del color, mayor será la importancia que se le dé a la palabra. En este ejemplo, un color rojo brillante muy saturado indica una fuerte contribución negativa. Un color verde muy saturado indica una fuerte contribución positiva. El color blanco indica que la palabra tiene una contribución neutra. Consulte la biblioteca de captum

Consulte el cuaderno de ejemplos completo para texto
