Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Cree un Multi-Model punto final
Puede utilizar la consola de SageMaker IA o la AWS SDK para Python (Boto) para crear un punto final multimodelo. Para crear un punto de conexión respaldado por CPU o GPU a través de la consola, consulte el procedimiento de la consola en las siguientes secciones. Si desea crear un punto final multimodelo con el AWS SDK para Python (Boto), utilice el procedimiento de CPU o GPU de las siguientes secciones. Los flujos de trabajo de la CPU y GPU son similares, pero presentan varias diferencias, como los requisitos del contenedor.
Temas
Creación de un punto de conexión multimodelo (consola)
Puede crear puntos de conexión multimodelo compatibles con la CPU y la GPU a través de la consola. Utilice el siguiente procedimiento para crear un punto final multimodelo a través de la consola de SageMaker IA.
Para crear un punto de conexión multimodelo (consola)
-
Abre la consola Amazon SageMaker AI en https://console.aws.amazon.com/sagemaker/
. -
Elija Modelo y, a continuación, en el grupo Inferencia, elija Crear modelo.
-
En Nombre del modelo, escriba un nombre.
-
Par el rol de IAM, escoja o cree un rol de IAM que tenga asociada la política de IAM
AmazonSageMakerFullAccess. -
En la sección Definición de contenedor, en Proporcionar opciones de imagen de inferencia y artefactos de modelo, elija Utilizar modelos múltiples.
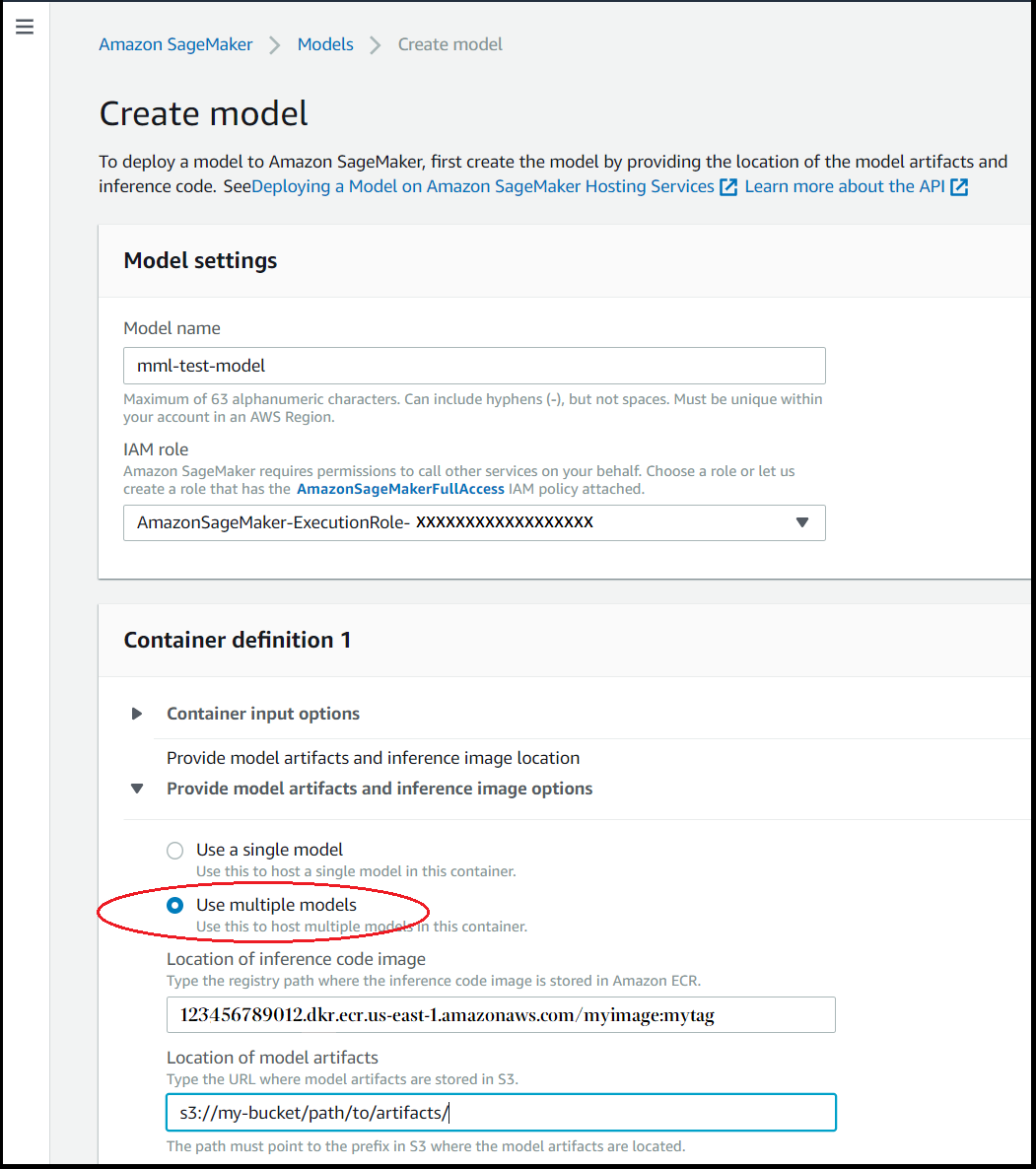
-
Para la Imagen del contenedor de inferencia, introduzca la ruta de Amazon ECR de la imagen de contenedor que desee.
Para los modelos de GPU, debe utilizar un contenedor respaldado por el servidor de inferencia NVIDIA Triton. Para obtener una lista de imágenes de contenedores que funcionan con terminales respaldados por GPU, consulte los contenedores de inferencia NVIDIA Triton (solo compatibles con SM)
. Para obtener más información sobre el servidor de inferencia Triton de NVIDIA, consulte Uso del servidor de inferencia Triton con IA. SageMaker -
Seleccione Crear modelo.
-
Implemente el punto de conexión multimodelo como lo haría con un punto de conexión de modelo único. Para obtener instrucciones, consulte Implemente el modelo en los servicios de alojamiento de SageMaker IA.
Cree un punto final multimodelo mediante CPU con el AWS SDK para Python (Boto3)
Utilice la siguiente sección para crear un punto de conexión multimodelo respaldado por instancias de CPU. Puede crear un punto final multimodelo mediante la SageMaker IA create_modelcreate_endpointcreate_endpoint_configMode, MultiModel. También debe transferir el campo ModelDataUrl que especifica el prefijo en Amazon S3 donde se encuentran los artefactos del modelo, en lugar de la ruta a un solo artefacto del modelo, como haría cuando se implementa un solo modelo.
Para ver un ejemplo de portátil que utiliza la SageMaker IA para implementar varios modelos de XGBoost en un terminal, consulte el cuaderno de muestra XGBoost de Multi-Model Endpoint
En el siguiente procedimiento se describen los pasos clave utilizados en esa muestra para crear un punto de conexión multimodelo.
Para implementar el modelo (AWS SDK para Python (Boto 3)
-
Obtenga un contenedor con una imagen que permita implementar puntos de conexión multimodelo. Para obtener una lista de los algoritmos integrados y contenedores de marcos que admiten puntos de conexión multimodelo, consulte Algoritmos, marcos e instancias compatibles con puntos de conexión multimodelo. Para este ejemplo, utilizamos el algoritmo integrado K-Nearest Algoritmo de vecinos (k-NN). Llamamos a la función de utilidad SageMaker Python SDK
image_uris.retrieve()para obtener la dirección de la imagen del algoritmo integrado de K-Nearest Neighbors.import sagemaker region = sagemaker_session.boto_region_name image = sagemaker.image_uris.retrieve("knn",region=region) container = { 'Image': image, 'ModelDataUrl': 's3://<BUCKET_NAME>/<PATH_TO_ARTIFACTS>', 'Mode': 'MultiModel' } -
Obtenga un cliente de AWS SDK para Python (Boto3) SageMaker IA y cree el modelo que usa este contenedor.
import boto3 sagemaker_client = boto3.client('sagemaker') response = sagemaker_client.create_model( ModelName ='<MODEL_NAME>', ExecutionRoleArn = role, Containers = [container]) -
(Opcional) Si usa una canalización de inferencia en serie, obtenga los contenedores adicionales que se incluirán en la canalización e inclúyalos en el argumento
ContainersdeCreateModel:preprocessor_container = { 'Image': '<ACCOUNT_ID>.dkr.ecr.<REGION_NAME>.amazonaws.com/<PREPROCESSOR_IMAGE>:<TAG>' } multi_model_container = { 'Image': '<ACCOUNT_ID>.dkr.ecr.<REGION_NAME>.amazonaws.com/<IMAGE>:<TAG>', 'ModelDataUrl': 's3://<BUCKET_NAME>/<PATH_TO_ARTIFACTS>', 'Mode': 'MultiModel' } response = sagemaker_client.create_model( ModelName ='<MODEL_NAME>', ExecutionRoleArn = role, Containers = [preprocessor_container, multi_model_container] )nota
Solo puede utilizar un punto de conexión habilitado para varios modelos en una canalización de inferencia en serie.
-
(Opcional) Si su caso de uso no aprovecha almacenamiento en caché del modelo, defina el valor del campo
ModelCacheSettingdel parámetroMultiModelConfigenDisablede inclúyalo en el argumentoContainerde la llamada acreate_model. El valor predeterminado del campoModelCacheSettingesEnabled.container = { 'Image': image, 'ModelDataUrl': 's3://<BUCKET_NAME>/<PATH_TO_ARTIFACTS>', 'Mode': 'MultiModel' 'MultiModelConfig': { // Default value is 'Enabled' 'ModelCacheSetting': 'Disabled' } } response = sagemaker_client.create_model( ModelName ='<MODEL_NAME>', ExecutionRoleArn = role, Containers = [container] ) -
Configure el punto de conexión multimodelo para el modelo. Recomendamos configurar los puntos de conexión con al menos dos instancias. Esto permite a la SageMaker IA proporcionar a los modelos un conjunto de predicciones de alta disponibilidad en varias zonas de disponibilidad.
response = sagemaker_client.create_endpoint_config( EndpointConfigName ='<ENDPOINT_CONFIG_NAME>', ProductionVariants=[ { 'InstanceType': 'ml.m4.xlarge', 'InitialInstanceCount': 2, 'InitialVariantWeight': 1, 'ModelName':'<MODEL_NAME>', 'VariantName': 'AllTraffic' } ] )nota
Solo puede utilizar un punto de conexión habilitado para varios modelos en una canalización de inferencia en serie.
-
Creación del punto de conexión multimodelo utilizando los parámetros
EndpointNameyEndpointConfigName.response = sagemaker_client.create_endpoint( EndpointName ='<ENDPOINT_NAME>', EndpointConfigName ='<ENDPOINT_CONFIG_NAME>')
Cree un punto final multimodelo mediante GPU con AWS SDK para Python (Boto3)
Utilice la siguiente sección para crear un punto de conexión multimodelo respaldado por GPU. Se crea un punto de conexión multimodelo mediante la SageMaker IA create_modelcreate_endpointcreate_endpoint_configMode, MultiModel. También debe transferir el campo ModelDataUrl que especifica el prefijo en Amazon S3 donde se encuentran los artefactos del modelo, en lugar de la ruta a un solo artefacto del modelo, como haría cuando se implementa un solo modelo. En el caso de puntos de conexión multimodelo respaldados por GPU, también debe utilizar un contenedor con el servidor de inferencia NVIDIA Triton que esté optimizado para ejecutarse en instancias de GPU. Para obtener una lista de imágenes de contenedores que funcionan con terminales respaldados por GPU, consulte los contenedores de inferencia NVIDIA Triton (solo compatibles con SM)
Para ver un ejemplo de cuaderno que muestra cómo crear un punto final multimodelo respaldado por GPU, consulte Ejecutar varios modelos de aprendizaje profundo en GPU con puntos de enlace Amazon SageMaker AI Multi-model (MME
En el siguiente procedimiento se describen los pasos clave para crear un punto de conexión multimodelo.
Para implementar el modelo (AWS SDK para Python (Boto 3)
-
Defina la imagen del contenedor. Para crear un punto final multimodelo compatible con la GPU para ResNet los modelos, defina el contenedor para usar la imagen del servidor NVIDIA Triton. Este contenedor admite puntos de conexión multimodelo y está optimizado para ejecutarse en instancias de GPU. Llamamos a la función de utilidad SageMaker AI Python SDK
image_uris.retrieve()para obtener la dirección de la imagen. Por ejemplo:import sagemaker region = sagemaker_session.boto_region_name // Find the sagemaker-tritonserver image at // https://github.com/aws/amazon-sagemaker-examples/blob/main/sagemaker-triton/resnet50/triton_resnet50.ipynb // Find available tags at https://github.com/aws/deep-learning-containers/blob/master/available_images.md#nvidia-triton-inference-containers-sm-support-only image = "<ACCOUNT_ID>.dkr.ecr.<REGION_NAME>.amazonaws.com/sagemaker-tritonserver:<TAG>".format( account_id=account_id_map[region], region=region ) container = { 'Image': image, 'ModelDataUrl': 's3://<BUCKET_NAME>/<PATH_TO_ARTIFACTS>', 'Mode': 'MultiModel', "Environment": {"SAGEMAKER_TRITON_DEFAULT_MODEL_NAME": "resnet"}, } -
Obtenga un cliente de AWS SDK para Python (Boto3) SageMaker IA y cree el modelo que utiliza este contenedor.
import boto3 sagemaker_client = boto3.client('sagemaker') response = sagemaker_client.create_model( ModelName ='<MODEL_NAME>', ExecutionRoleArn = role, Containers = [container]) -
(Opcional) Si usa una canalización de inferencia en serie, obtenga los contenedores adicionales que se incluirán en la canalización e inclúyalos en el argumento
ContainersdeCreateModel:preprocessor_container = { 'Image': '<ACCOUNT_ID>.dkr.ecr.<REGION_NAME>.amazonaws.com/<PREPROCESSOR_IMAGE>:<TAG>' } multi_model_container = { 'Image': '<ACCOUNT_ID>.dkr.ecr.<REGION_NAME>.amazonaws.com/<IMAGE>:<TAG>', 'ModelDataUrl': 's3://<BUCKET_NAME>/<PATH_TO_ARTIFACTS>', 'Mode': 'MultiModel' } response = sagemaker_client.create_model( ModelName ='<MODEL_NAME>', ExecutionRoleArn = role, Containers = [preprocessor_container, multi_model_container] )nota
Solo puede utilizar un punto de conexión habilitado para varios modelos en una canalización de inferencia en serie.
-
(Opcional) Si su caso de uso no aprovecha almacenamiento en caché del modelo, defina el valor del campo
ModelCacheSettingdel parámetroMultiModelConfigenDisablede inclúyalo en el argumentoContainerde la llamada acreate_model. El valor predeterminado del campoModelCacheSettingesEnabled.container = { 'Image': image, 'ModelDataUrl': 's3://<BUCKET_NAME>/<PATH_TO_ARTIFACTS>', 'Mode': 'MultiModel' 'MultiModelConfig': { // Default value is 'Enabled' 'ModelCacheSetting': 'Disabled' } } response = sagemaker_client.create_model( ModelName ='<MODEL_NAME>', ExecutionRoleArn = role, Containers = [container] ) -
Configure el punto de conexión multimodelo con instancias respaldadas por GPU para el modelo. Recomendamos configurar los puntos de conexión con más de una instancia para permitir una alta disponibilidad y un mayor número de visitas a la memoria caché.
response = sagemaker_client.create_endpoint_config( EndpointConfigName ='<ENDPOINT_CONFIG_NAME>', ProductionVariants=[ { 'InstanceType': 'ml.g4dn.4xlarge', 'InitialInstanceCount': 2, 'InitialVariantWeight': 1, 'ModelName':'<MODEL_NAME>', 'VariantName': 'AllTraffic' } ] ) -
Creación del punto de conexión multimodelo utilizando los parámetros
EndpointNameyEndpointConfigName.response = sagemaker_client.create_endpoint( EndpointName ='<ENDPOINT_NAME>', EndpointConfigName ='<ENDPOINT_CONFIG_NAME>')
