Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Introducción a la biblioteca de paralelismo de datos distribuidos de SageMaker IA
La biblioteca de paralelismo de datos distribuidos de SageMaker IA (SMDDP) es una biblioteca de comunicación colectiva que mejora el rendimiento informático del entrenamiento en paralelo de datos distribuidos. La biblioteca de SMDDP aborda la sobrecarga de comunicaciones de las principales operaciones de comunicación colectiva ofreciendo lo siguiente.
-
La biblioteca ofrece ofertas optimizadas para.
AllReduceAWSAllReducees una operación clave que se utiliza para sincronizar los gradientes entre las GPU al final de cada iteración de entrenamiento durante el entrenamiento con datos distribuidos. -
La biblioteca ofrece ofertas optimizadas para.
AllGatherAWSAllGatheres otra operación clave utilizada en el entrenamiento paralelo de datos fragmentados, que es una técnica de paralelismo de datos eficiente en memoria que ofrecen bibliotecas populares, como la biblioteca de paralelismo de modelos de SageMaker IA (SMP), DeepSpeed Zero Redundancy Optimizer (ZeRO) y Fully Sharded Data Parallelism (FSDP). PyTorch -
La biblioteca realiza una comunicación optimizada de nodo a nodo mediante el pleno uso de la infraestructura de AWS red y la topología de instancias de Amazon EC2.
La biblioteca de SMDDP puede aumentar la velocidad de entrenamiento ofreciendo una mejora del rendimiento a medida que escala el clúster de entrenamiento, con una eficiencia de escalado casi lineal.
nota
Las bibliotecas de formación distribuidas por SageMaker IA están disponibles a través de los contenedores de aprendizaje AWS profundo PyTorch y Hugging Face de SageMaker la plataforma de formación. Para usar las bibliotecas, debe usar el SDK de SageMaker Python o las SageMaker API a través de SDK for Python (Boto3) o. AWS Command Line Interface En toda la documentación, las instrucciones y los ejemplos se centran en cómo utilizar las bibliotecas de formación distribuidas con el SDK de SageMaker Python.
Operaciones de comunicación colectiva de SMDDP optimizadas para AWS recursos de cómputo e infraestructura de red
La biblioteca SMDDP proporciona implementaciones AllReduce y operaciones AllGather colectivas optimizadas para los recursos AWS informáticos y la infraestructura de red.
Operación colectiva AllReduce de SMDDP
La biblioteca de SMDDP consigue una superposición óptima de la operación AllReduce con la transferencia hacia atrás, lo que mejora significativamente el uso de la GPU. Consigue una eficiencia de escalado casi lineal y una velocidad de entrenamiento más rápida optimizando las operaciones del kernel entre CPU y GPU. La biblioteca ejecuta AllReduce en paralelo mientras la GPU calcula gradientes sin quitar ciclos de GPU adicionales, lo que permite que la biblioteca consiga un entrenamiento más rápido.
-
Aprovecha las CPU: la biblioteca utiliza CPU para gradientes
AllReduce, descargando esta tarea de las GPU. -
Uso mejorado de la GPU: las GPU del clúster se centran en los gradientes informáticos, mejorando su utilización durante toda el entrenamiento.
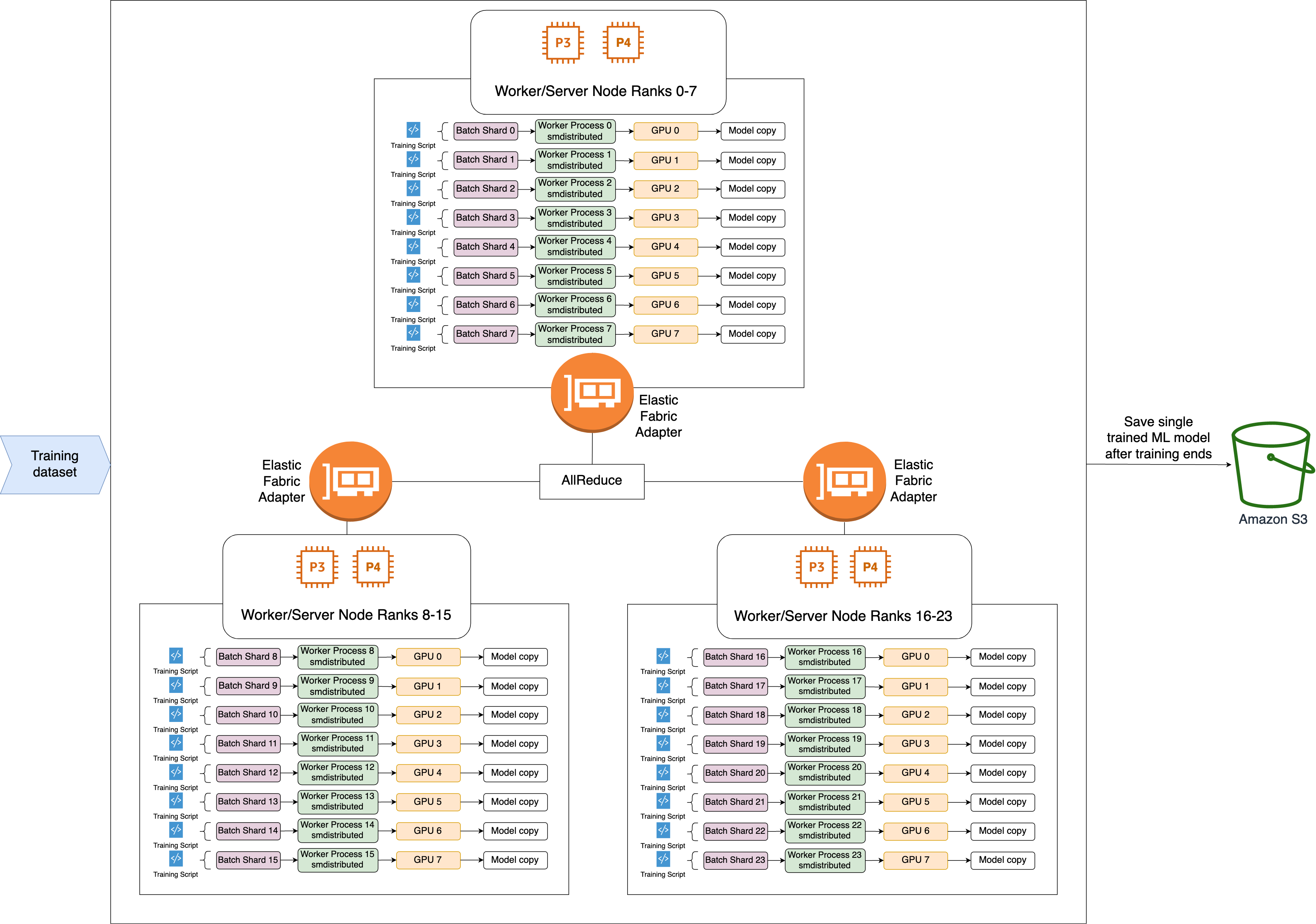
Este es el flujo de trabajo de alto nivel de la operación AllReduce de SMDDP.
-
La biblioteca asigna rangos a las GPU (trabajadores).
-
En cada iteración, la biblioteca divide cada lote global entre el número total de trabajadores (tamaño mundial) y asigna pequeños lotes (fragmentos por lotes) a los trabajadores.
-
El tamaño del lote global es
(number of nodes in a cluster) * (number of GPUs per node) * (per batch shard). -
Un fragmento por lotes (lote pequeño) es un subconjunto de conjuntos de datos asignado a cada GPU (trabajador) por iteración.
-
-
La biblioteca lanza un script de entrenamiento para cada trabajador.
-
La biblioteca administra copias de los pesos y degradados del modelo de los trabajadores al final de cada iteración.
-
La biblioteca sincroniza los pesos y degradados del modelo entre los trabajadores para agregar un solo modelo entrenado.
El siguiente diagrama de arquitectura muestra un ejemplo de cómo la biblioteca configura el paralelismo de datos para un clúster de 3 nodos.
Operación colectiva AllGather de SMDDP
AllGather es una operación colectiva en la que cada trabajador comienza con un búfer de entrada y, a continuación, concatena o reúne los búferes de entrada de todos los demás trabajadores en un búfer de salida.
nota
La operación AllGather colectiva SMDDP está disponible en AWS Deep Learning Containers (DLC) para PyTorch la versión 2.0.1 smdistributed-dataparallel>=2.0.1 y versiones posteriores.
AllGather se utiliza mucho en técnicas de entrenamiento distribuido, como el paralelismo de datos particionados, en el que cada trabajador individual tiene una fracción de un modelo o una capa particionada. Los trabajadores llaman a AllGather antes de las transferencias hacia delante y hacia atrás para reconstruir las capas particionadas. Las transferencias hacia adelante y hacia atrás continúan hacia delante una vez recopilados todos los parámetros. Durante la transferencia hacia atrás, cada trabajador también llama a ReduceScatter para recolectar (reducir) los gradientes y dividirlos (dispersarlos) en particiones de gradiente para actualizar la capa particionada correspondiente. Para obtener más información sobre el papel de estas operaciones colectivas en el paralelismo de datos fragmentados, consulte las implementaciones de la biblioteca SMP sobre el paralelismo de datos fragmentados, ZeRO, en la documentación, y el blog sobre el paralelismo de datos fragmentado completo. DeepSpeed PyTorch
Como las operaciones colectivas se invocan en todas las iteraciones, AllGather son las que más contribuyen a la sobrecarga de comunicación de la GPU. Un cálculo más rápido de estas operaciones colectivas se traduce directamente en un tiempo de entrenamiento más corto sin efectos secundarios sobre la convergencia. Para lograrlo, la biblioteca de SMDDP ofrece AllGather optimizado para instancias P4d
AllGather de SMDDP utiliza las siguientes técnicas para mejorar el rendimiento de computación en las instancias P4d.
-
Transfiere datos entre instancias (entre nodos) a través de la red Elastic Fabric Adapter (EFA)
con topología de malla. EFA es la solución de red AWS de baja latencia y alto rendimiento. Una topología en malla para la comunicación de red entre nodos se adapta mejor a las características de la EFA y de la infraestructura de red. AWS En comparación con la topología en anillo o árbol de NCCL, que implica varios saltos de paquetes, SMDDP evita la acumulación de latencia con varios saltos, ya que solo necesita un salto. SMDDP implementa un algoritmo de control de velocidad de red que equilibra la carga de trabajo de cada nivel de comunicación en una topología de malla y consigue un mayor rendimiento de la red global. -
Adopta una biblioteca de copias en memoria de GPU de baja latencia basada en tecnología NVIDIA GPUDirect RDMA (GDRCopy)
para coordinar el tráfico de red local de NVLink y EFA. GDRCopy, una biblioteca de copias de memoria de GPU de baja latencia que ofrece NVIDIA, proporciona comunicación de baja latencia entre procesos de CPU y kernels CUDA de GPU. Con esta tecnología, la biblioteca de SMDDP puede canalizar el movimiento de datos entre nodos y dentro de ellos. -
Reduce el uso de multiprocesadores de streaming de GPU para aumentar la potencia de cómputo necesaria para ejecutar kernels de modelo. Las instancias P4d y P4de están equipadas con GPU NVIDIA A100, cada una de las cuales tiene 108 multiprocesadores de streaming. Mientras que el NCCL utiliza hasta 24 multiprocesadores de streaming para ejecutar operaciones colectivas, SMDDP utiliza menos de 9 multiprocesadores de streaming. Los kernels de cómputo de modelos recogen los multiprocesadores de streaming guardados para agilizar la computación.
