Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Guía del informe de creación de perfiles del depurador
Esta sección guía el informe de creación de perfiles del depurador sección por sección. El informe de creación de perfiles se genera en función de las reglas integradas de monitorización y creación de perfiles. El informe muestra gráficos de resultados solo para aquellas reglas que hayan detectado problemas.
importante
En el informe, los gráficos y las recomendaciones se proporcionan con fines informativos y no son definitivos. Es responsabilidad suya realizar su propia evaluación independiente de la información.
Temas
Resumen del trabajo de entrenamiento
Al principio del informe, el depurador proporciona un resumen de su trabajo de entrenamiento. En esta sección, puede ver una descripción general de la duración y las marcas de tiempo en las diferentes fases del entrenamiento.
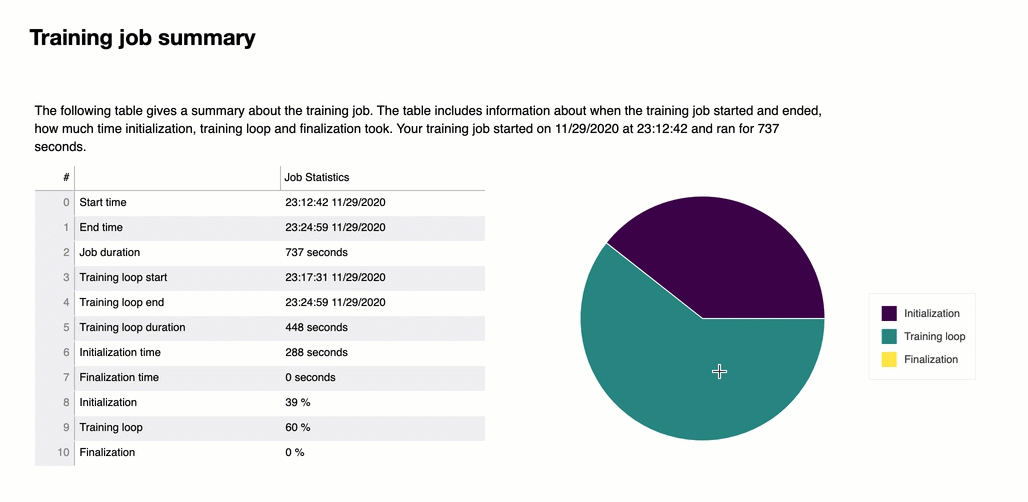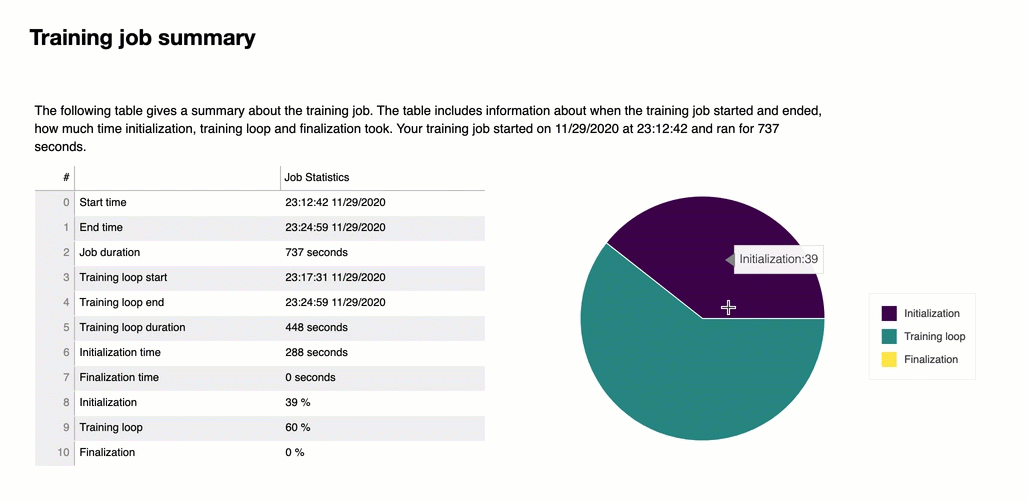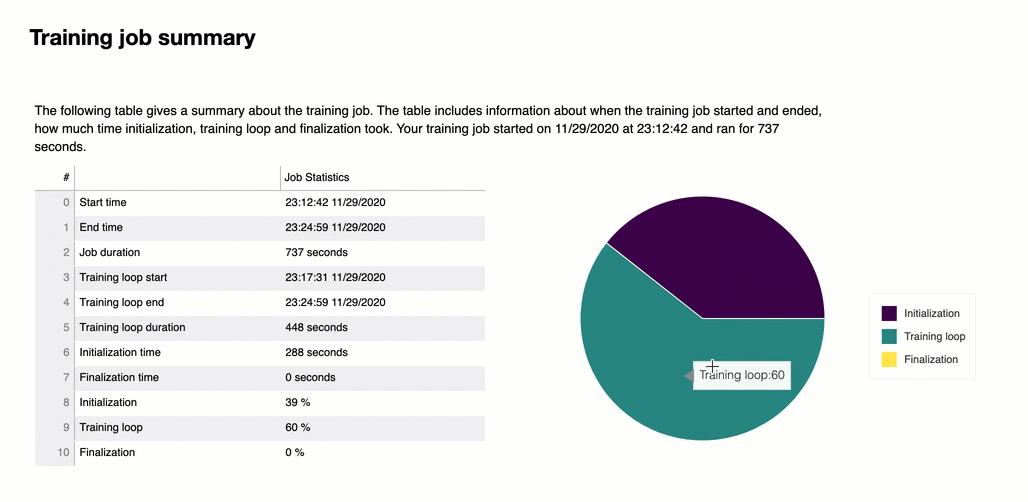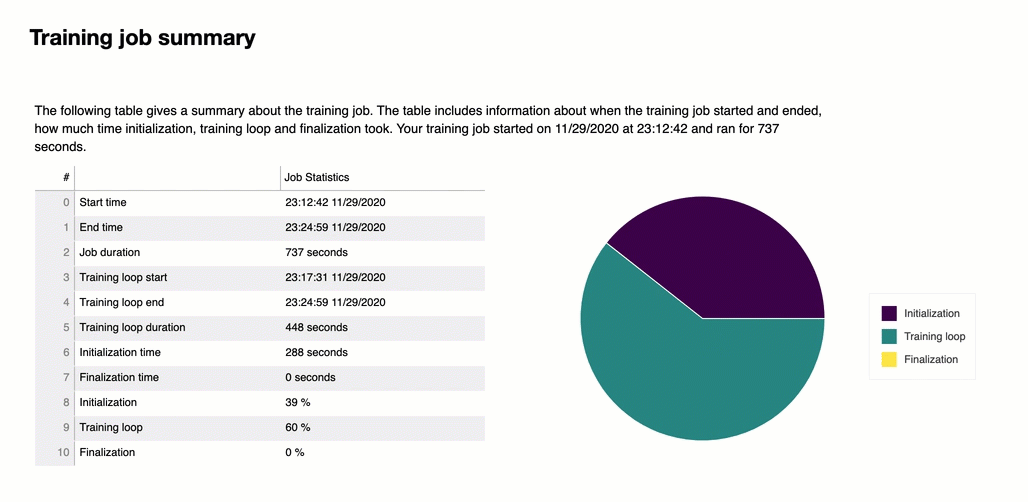
Esta tabla resumen recoge la siguiente información:
-
start_time: hora exacta en la que comenzó el trabajo de entrenamiento.
-
end_time: hora exacta en la que finalizó el trabajo de entrenamiento.
-
job_duration_in_seconds: el tiempo de entrenamiento total desde start_time hasta end_time.
-
training_loop_start: hora exacta en la que comenzó el primer paso de la primera época.
-
training_loop_end: hora exacta en la que finalizó el último paso de la última época.
-
training_loop_duration_in_seconds: tiempo total entre la hora de inicio del ciclo de entrenamiento y la hora de finalización del ciclo de entrenamiento.
-
initialization_in_seconds: tiempo empleado en inicializar el trabajo de entrenamiento. La fase de inicialización cubre el período desde start_time hasta training_loop_start. El tiempo de inicialización se dedica a compilar el guion de entrenamiento, iniciarlo, crear e inicializar el modelo, iniciar las instancias y descargar los datos de entrenamiento. EC2
-
finalization_in_seconds: tiempo empleado en finalizar el trabajo de formación, por ejemplo, terminar el entrenamiento del modelo, actualizar los artefactos del modelo y cerrar las instancias. EC2 La fase de finalización cubre el período desde training_loop_end hasta end_time.
-
inicialización (%): el porcentaje de tiemplo empleado en la inicialización sobre job_duration_in_seconds total.
-
ciclo de porcentaje (%): el porcentaje de tiempo empleado en el ciclo de entrenamiento sobre job_duration_in_seconds en total.
-
finalización (%): el porcentaje de tiempo empleado en la finalización sobre job_duration_in_seconds en total.
Estadísticas de uso del sistema
Esta sección muestra una descripción general de las estadísticas de uso del sistema.
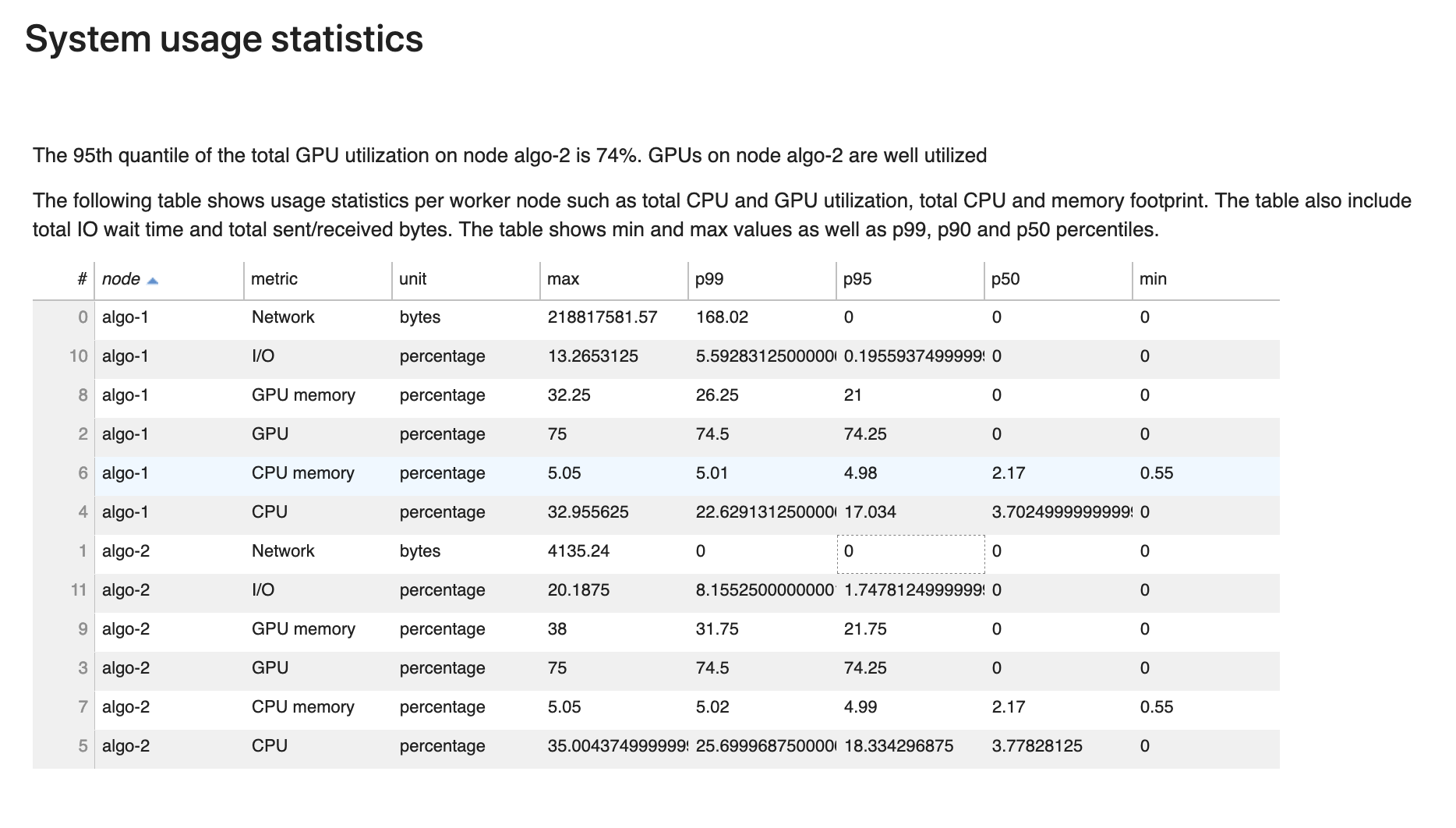
El informe de uso de creación de perfiles del depurador incluye la siguiente información:
-
nodo: muestra el nombre de los nodos. Si se utiliza el entrenamiento distribuido en varios nodos (varias EC2 instancias), los nombres de los nodos tienen el formato de.
algo-n -
métrica: las métricas del sistema recopiladas por el depurador: CPU, GPU, memoria de CPU, memoria de GPU, E/S y métricas de red.
-
unidad: la unidad de la métrica del sistema.
-
max: el valor máximo de cada utilización del sistema.
-
p99: el percentil 99 de cada utilización del sistema.
-
p95: el percentil 95 de cada utilización del sistema.
-
p50: el percentil 50 (mediana) de cada utilización del sistema.
-
min: el valor mínimo de cada métrica del sistema.
Resumen de métricas del marco
En esta sección, los siguientes gráficos circulares muestran el desglose de las operaciones marco en CPUs y GPUs.
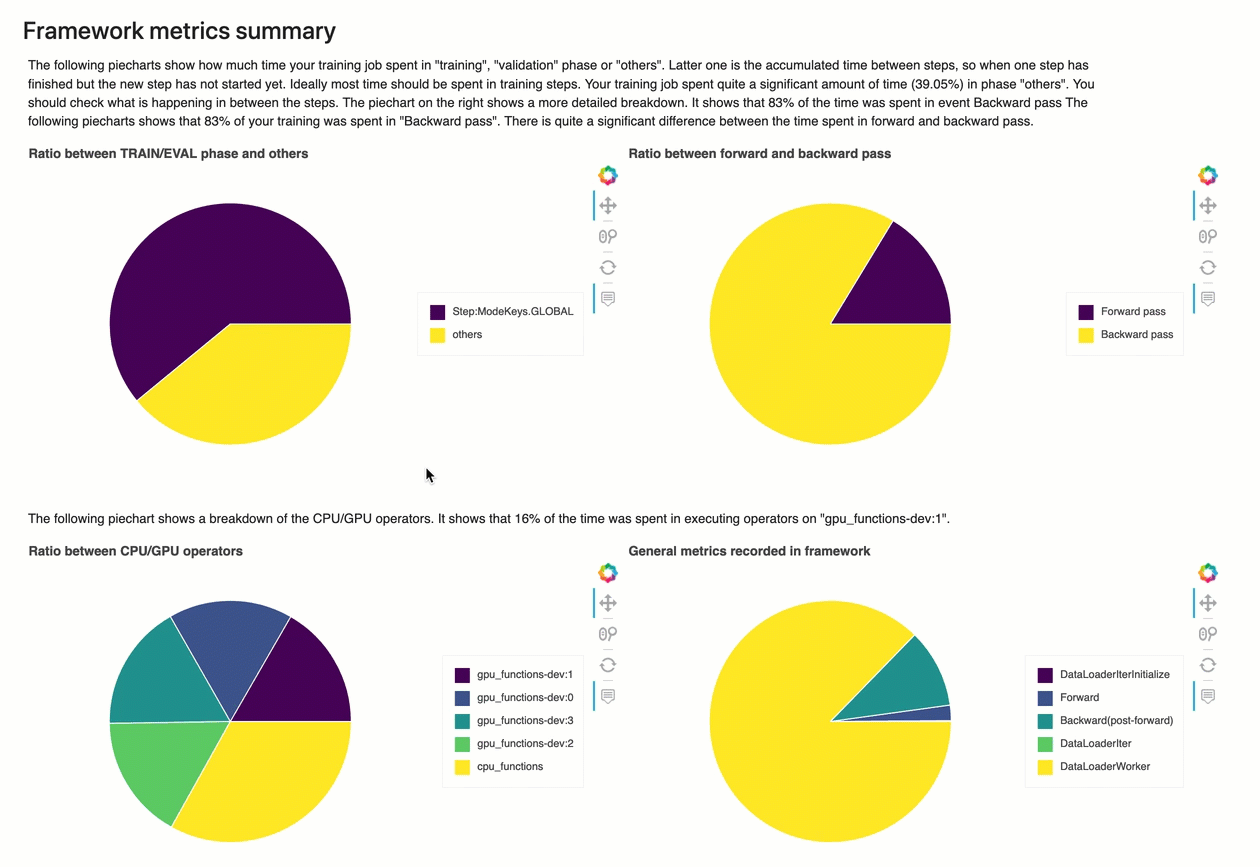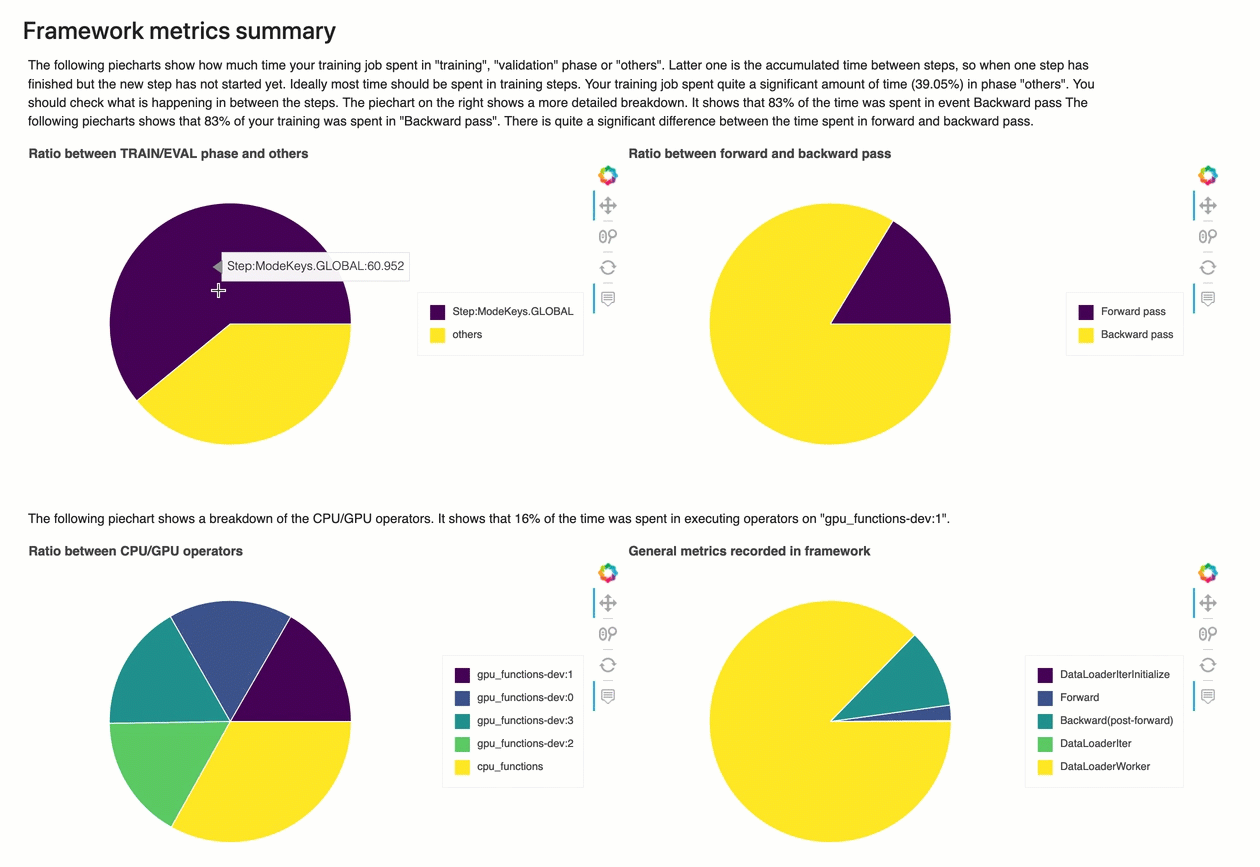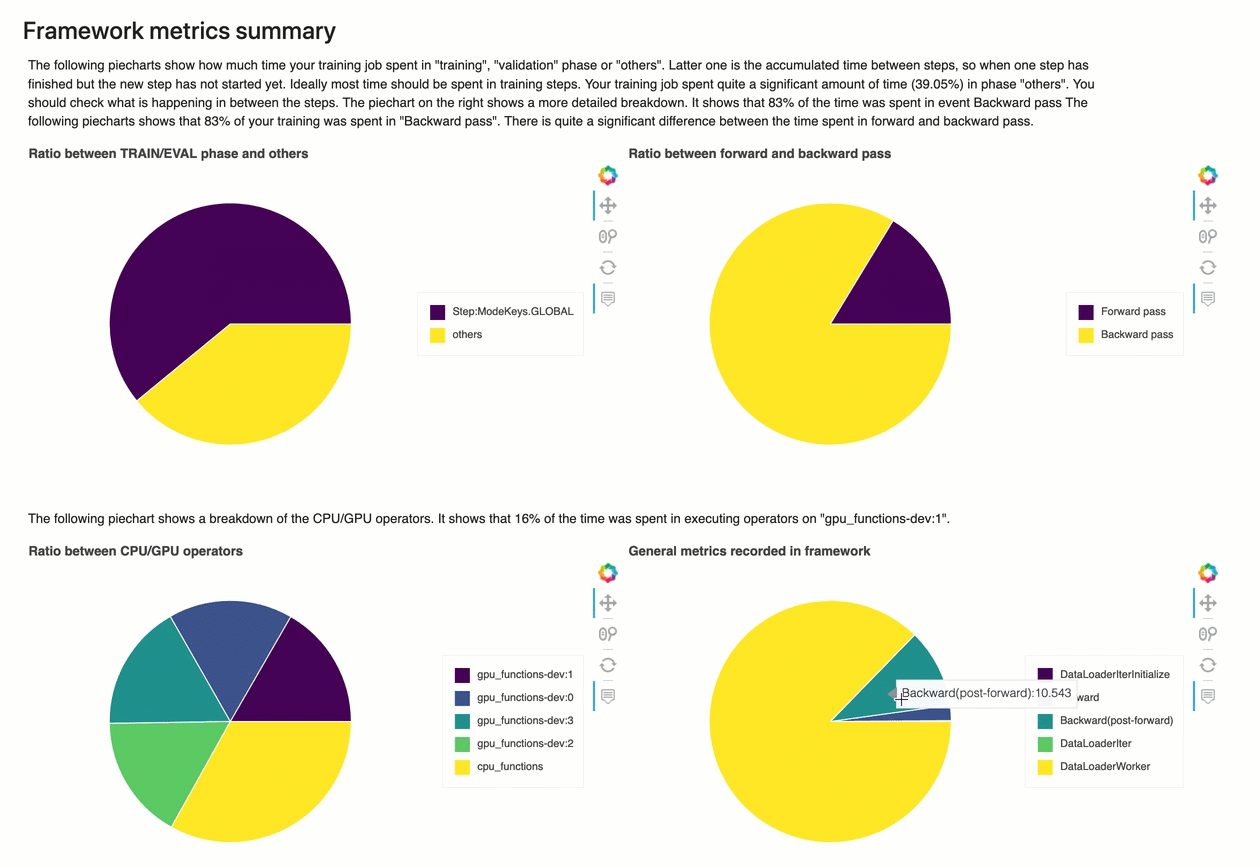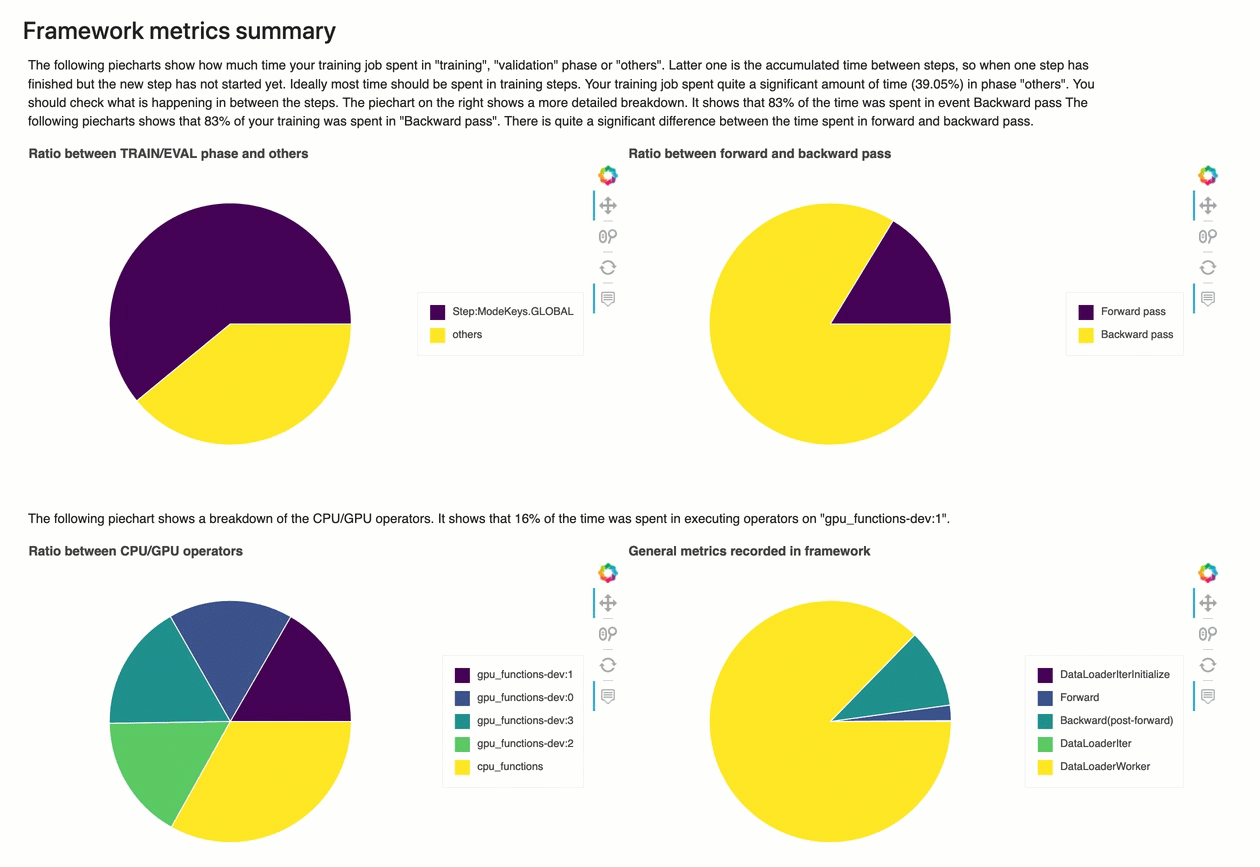
Cada uno de los gráficos circulares analiza las métricas del marco recopiladas en varios aspectos, de la siguiente manera:
-
Relación entre las fases de ENTRENAMIENTO/EVALUACIÓN y otras: muestra la relación entre el tiempo dedicado a las diferentes fases de entrenamiento.
-
Relación entre las pasadas hacia adelante y hacia atrás: muestra la relación entre el tiempo empleado en la pasada hacia adelante y hacia atrás en el ciclo de entrenamiento.
-
Relación entre operadores de CPU/GPU: muestra la relación entre el tiempo dedicado a los operadores que utilizan la CPU o la GPU, como los operadores convolucionales.
-
Métricas generales registradas en el marco: muestra la relación entre el tiempo dedicado a las principales métricas del marco, como la carga de datos y las pasadas hacia adelante y hacia atrás.
Descripción general: operadores de CPU
Esta sección proporciona información detallada sobre los operadores de la CPU. La tabla muestra el porcentaje del tiempo y el tiempo acumulado absoluto dedicados a los operadores de CPU denominados con más frecuencia.
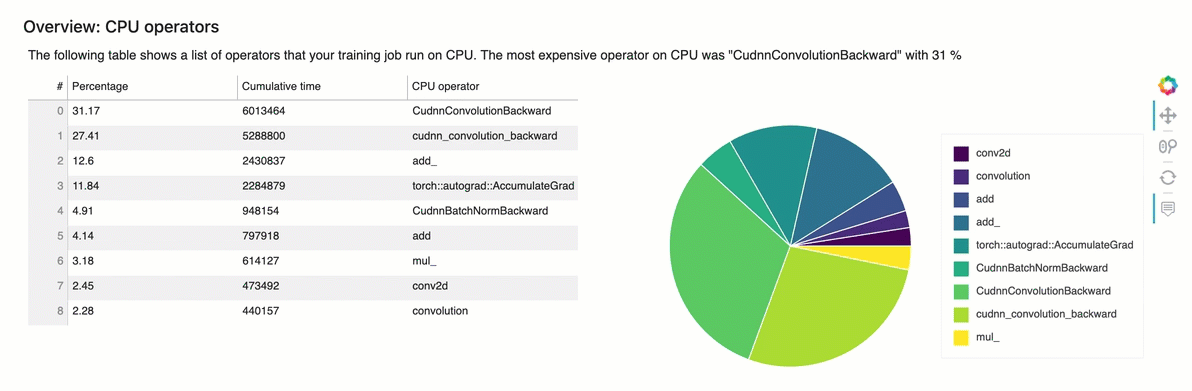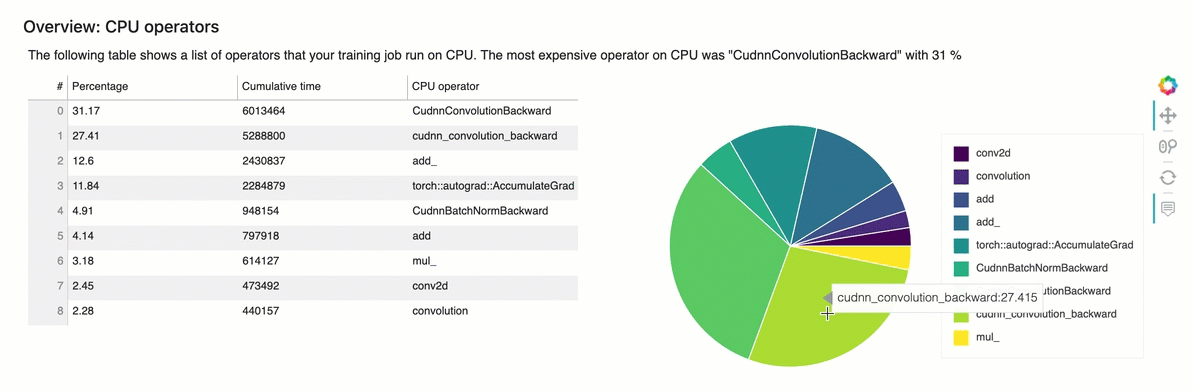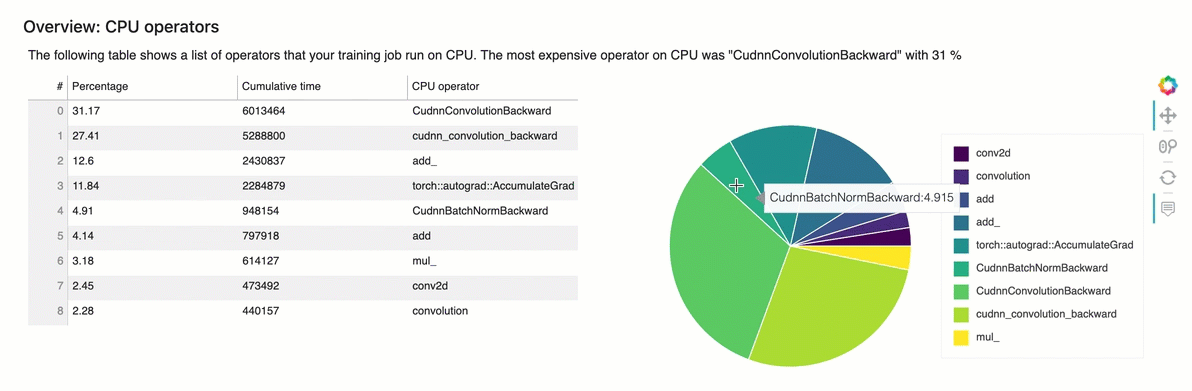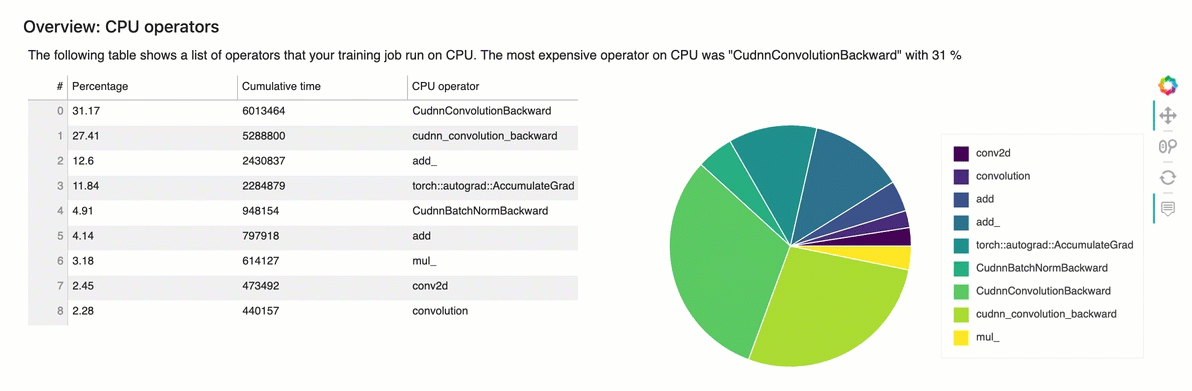
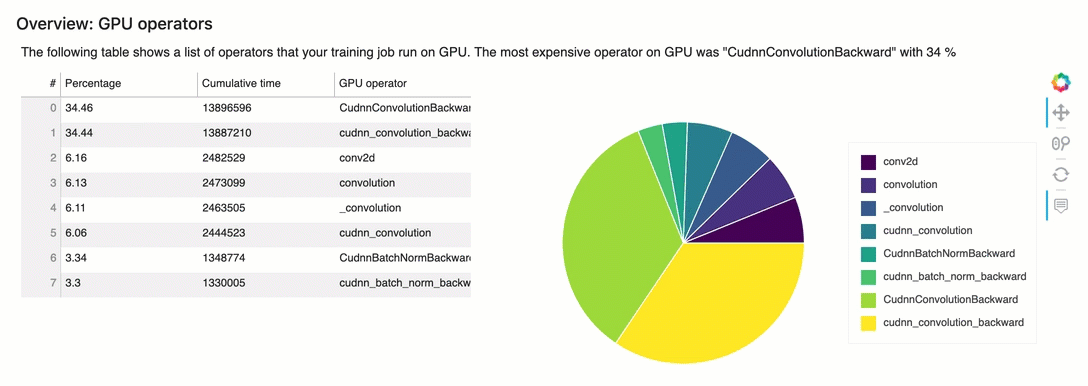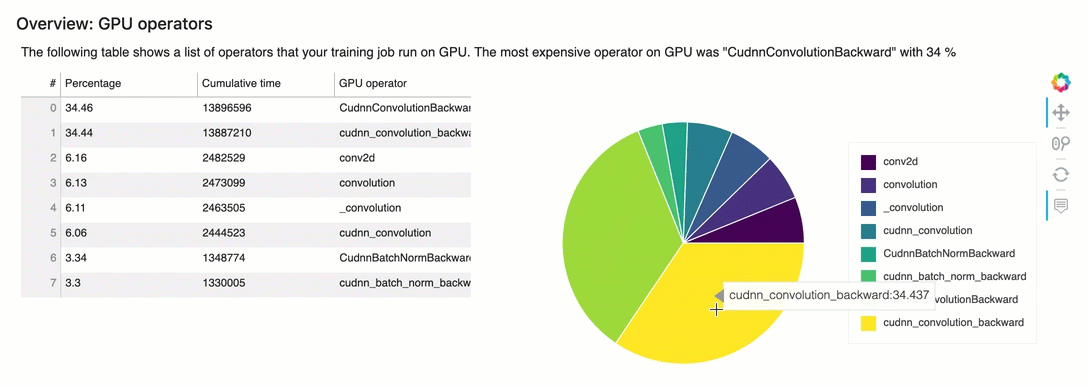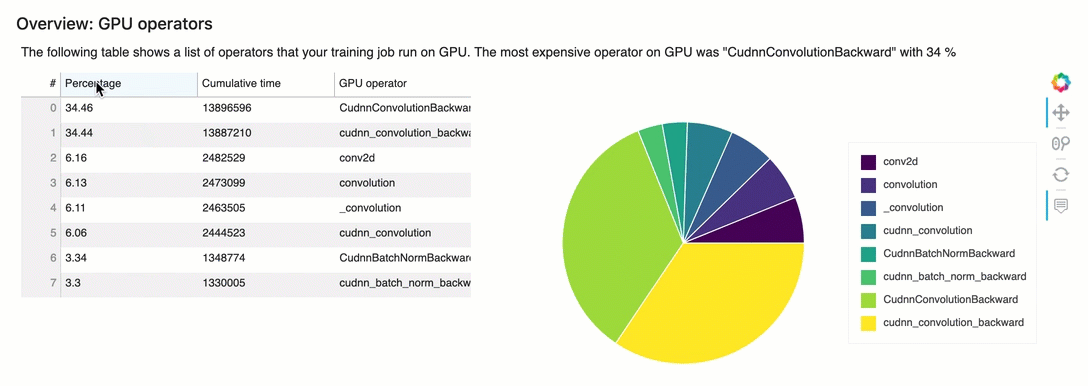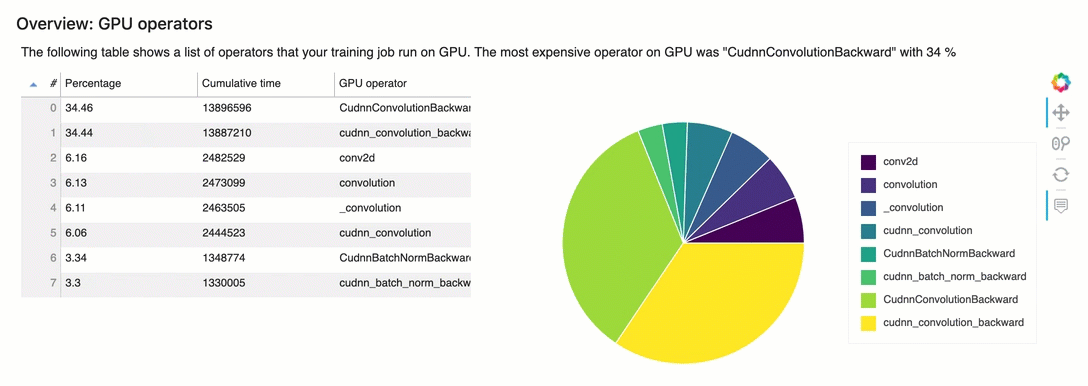
Descripción general: operadores de GPU
Esta sección proporciona información detallada sobre los operadores de GPU. La tabla muestra el porcentaje del tiempo y el tiempo acumulado absoluto dedicado a los operadores de GPU denominados con más frecuencia.
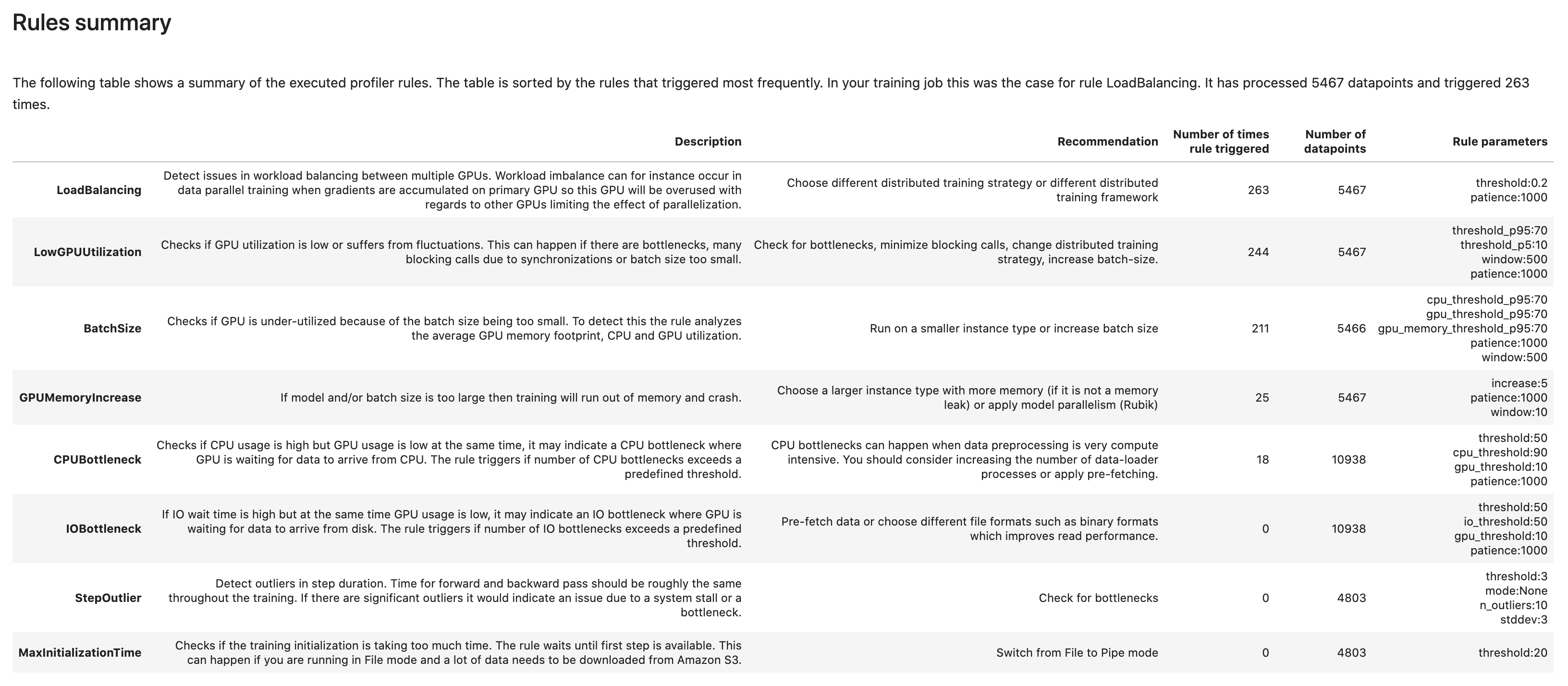
Resumen de reglas
En esta sección, el depurador agrega todos los resultados de la evaluación de las reglas, los análisis, las descripciones de las reglas y las sugerencias.
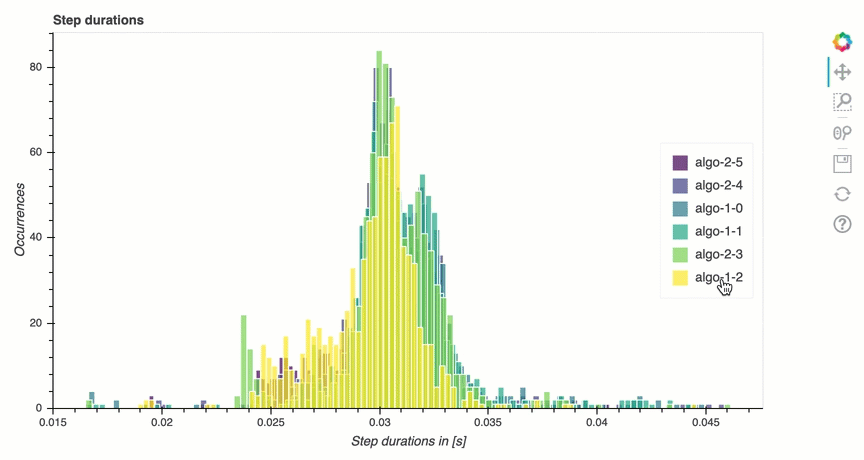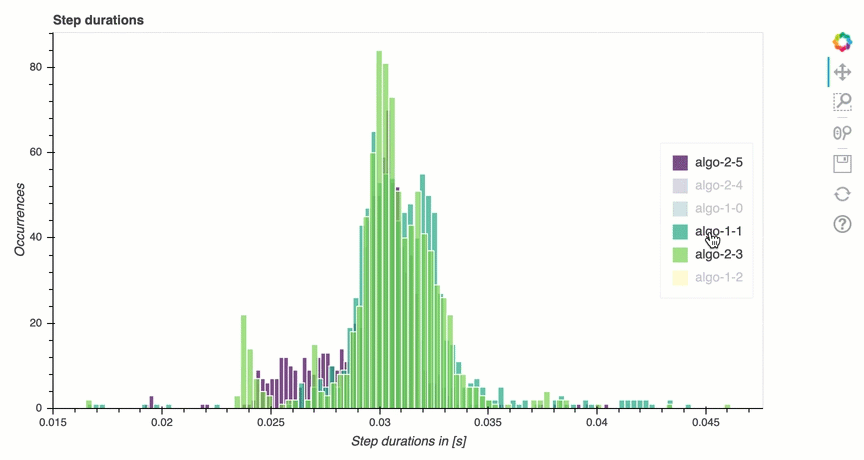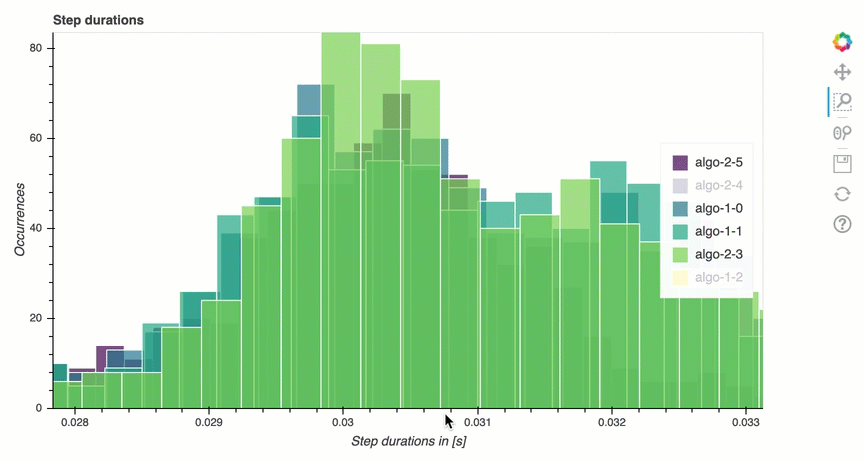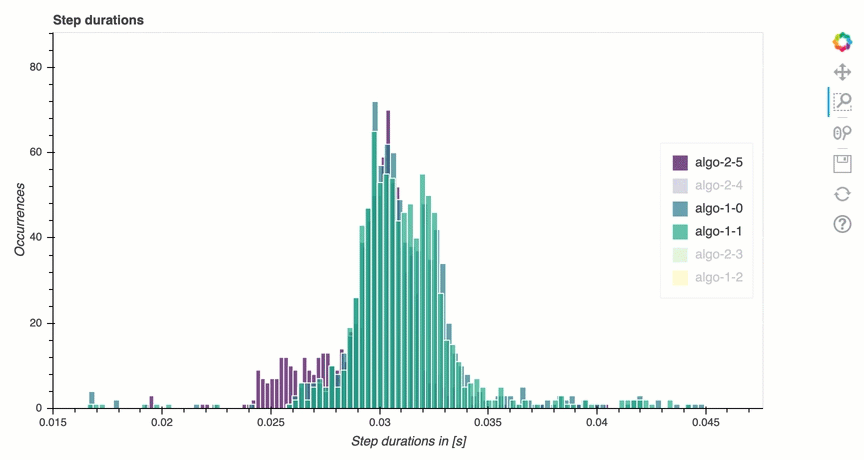
Análisis del ciclo de entrenamiento: duración de los pasos
En esta sección, encontrará estadísticas detalladas de la duración de los pasos en cada núcleo de la GPU de cada nodo. El depurador evalúa los valores medios, máximos, p99, p95, p50 y mínimos de las duraciones de los pasos y evalúa los valores atípicos de los pasos. El siguiente histograma muestra las duraciones de los pasos capturadas en los diferentes nodos de trabajo y. GPUs Para activar o desactivar el histograma de cada trabajador, seleccione las leyendas de la parte derecha. Puede comprobar si hay alguna GPU en particular que esté provocando valores atípicos en la duración de los pasos.
Análisis de utilización de la GPU
En esta sección se muestran las estadísticas detalladas sobre el uso del núcleo de la GPU según la regla LowGPUUtilization . También se resumen las estadísticas de uso de la GPU (media, p95 y p5) para determinar si el trabajo de formación está infrautilizado. GPUs
BatchSize
Esta sección muestra las estadísticas detalladas del uso total de la CPU, las utilizaciones individuales de la GPU y el consumo de memoria de la GPU. La BatchSize regla determina si es necesario cambiar el tamaño del lote para utilizar mejor el. GPUs Puede comprobar si el tamaño del lote es demasiado pequeño, lo que provoca una infrautilización o si es demasiado grande, lo que provoca problemas de sobreutilización y falta de memoria. En el gráfico, los recuadros muestran los rangos de percentiles p25 y p75 (rellenados de morado oscuro y amarillo brillante, respectivamente) desde la mediana (p50), y las barras de error muestran el percentil 5 para el límite inferior y el percentil 95 para el límite superior.

Cuellos de botella de la CPU
En esta sección, puede analizar en detalle los cuellos de botella de la CPU que la CPUBottleneck regla detectó en su trabajo de formación. La regla comprueba si el uso de la CPU es superior a cpu_threshold (90 % de forma predeterminada) y también si el uso de la GPU es inferior a gpu_threshold (10 % de forma predeterminada).
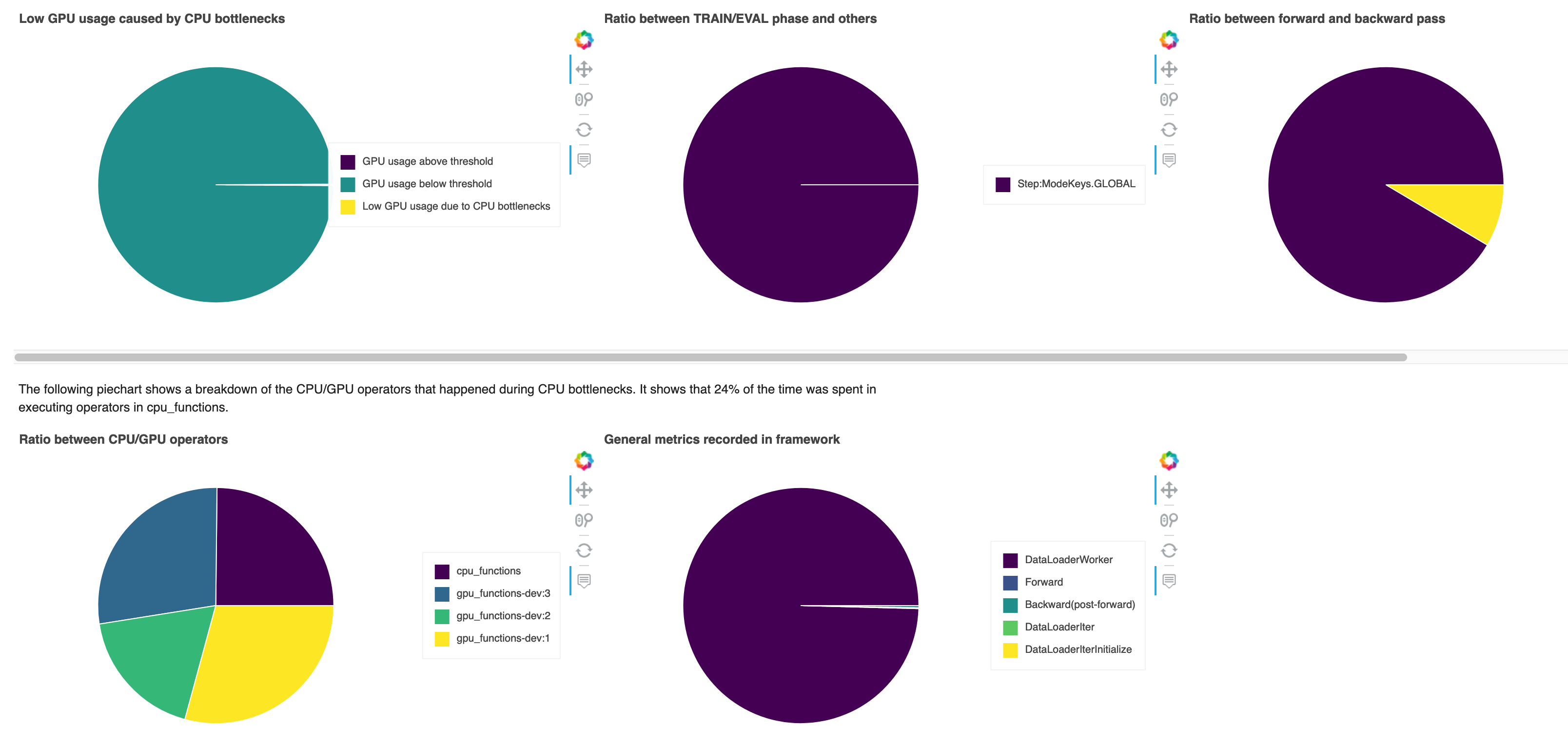
Los gráficos circulares muestran la siguiente información:
-
Poco uso de la GPU causado por cuellos de botella de la CPU: muestra la relación de puntos de datos entre los que tienen una utilización de la GPU por encima y por debajo del umbral y los que coinciden con los criterios de cuello de botella de la CPU.
-
Relación entre las fases de ENTRENAMIENTO/EVALUACIÓN y otras: muestra la relación entre el tiempo dedicado a las diferentes fases de entrenamiento.
-
Relación entre las pasadas hacia adelante y hacia atrás: muestra la relación entre el tiempo empleado en la pasada hacia adelante y hacia atrás en el ciclo de entrenamiento.
-
Relación entre los operadores de CPU/GPU: muestra la relación entre el tiempo empleado en y GPUs por los operadores de CPUs Python, como los procesos de carga de datos y los operadores de paso hacia adelante y hacia atrás.
-
Métricas generales registradas en el marco: muestra las principales métricas del marco y la relación entre el tiempo dedicado a las métricas.
Cuellos de botella de E/S
En esta sección, encontrará un resumen de los cuellos de botella de E/S. La regla evalúa el tiempo de espera de E/S y las tasas de utilización de la GPU, y monitoriza si el tiempo dedicado a las solicitudes de E/S supera un porcentaje umbral del tiempo total de entrenamiento. Podría indicar cuellos de botella de E/S en los que se espera que los datos lleguen del almacenamiento GPUs .
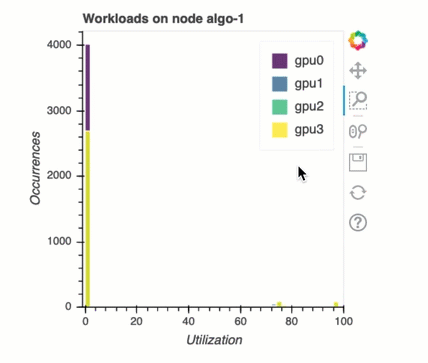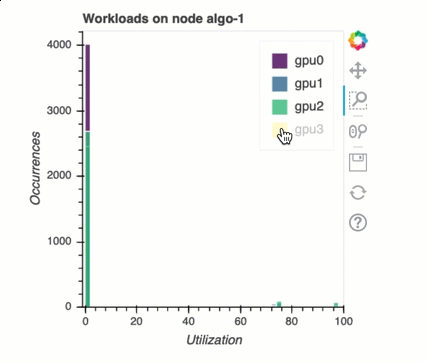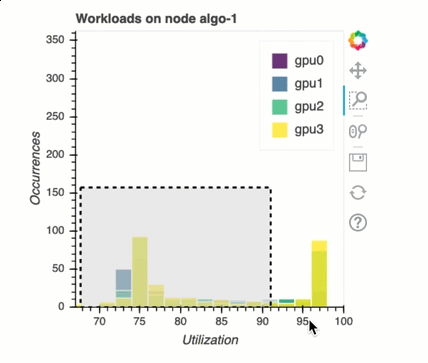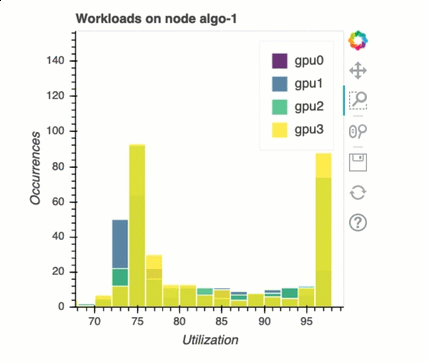
Equilibrio de carga en el entrenamiento con varias GPU
En esta sección, puede identificar los problemas de equilibrio de la carga de trabajo en todos los ámbitos. GPUs
Análisis de memoria de GPU
En esta sección, puedes analizar la utilización de la memoria de la GPU recopilada por la regla de GPUMemory aumento. En el gráfico, los recuadros muestran los rangos de percentiles p25 y p75 (rellenados de morado oscuro y amarillo brillante, respectivamente) desde la mediana (p50), y las barras de error muestran el percentil 5 para el límite inferior y el percentil 95 para el límite superior.

