Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Tutorial del informe de XGBoost formación sobre el depurador
En esta sección se explica el informe de formación sobre el depuradorXGBoost. El informe se agrega automáticamente según la expresión regular del tensor de salida, reconociendo qué tipo de trabajo de entrenamiento se encuentra entre clasificación binaria, clasificación multiclase y regresión.
importante
En el informe, los gráficos y las recomendaciones se proporcionan con fines informativos y no son definitivos. Es responsabilidad suya realizar su propia evaluación independiente de la información.
Temas
- Distribución de las etiquetas verdaderas del conjunto de datos
- Gráfica de pérdidas versus escalones
- Importancia de las características
- Matriz de confusión
- Evaluación de la matriz de confusión
- Tasa de precisión de cada elemento diagonal a lo largo de la iteración
- Curva característica de funcionamiento del receptor
- Distribución de los residuos en el último paso guardado
- Error absoluto de validación por contenedor de etiquetas durante la iteración
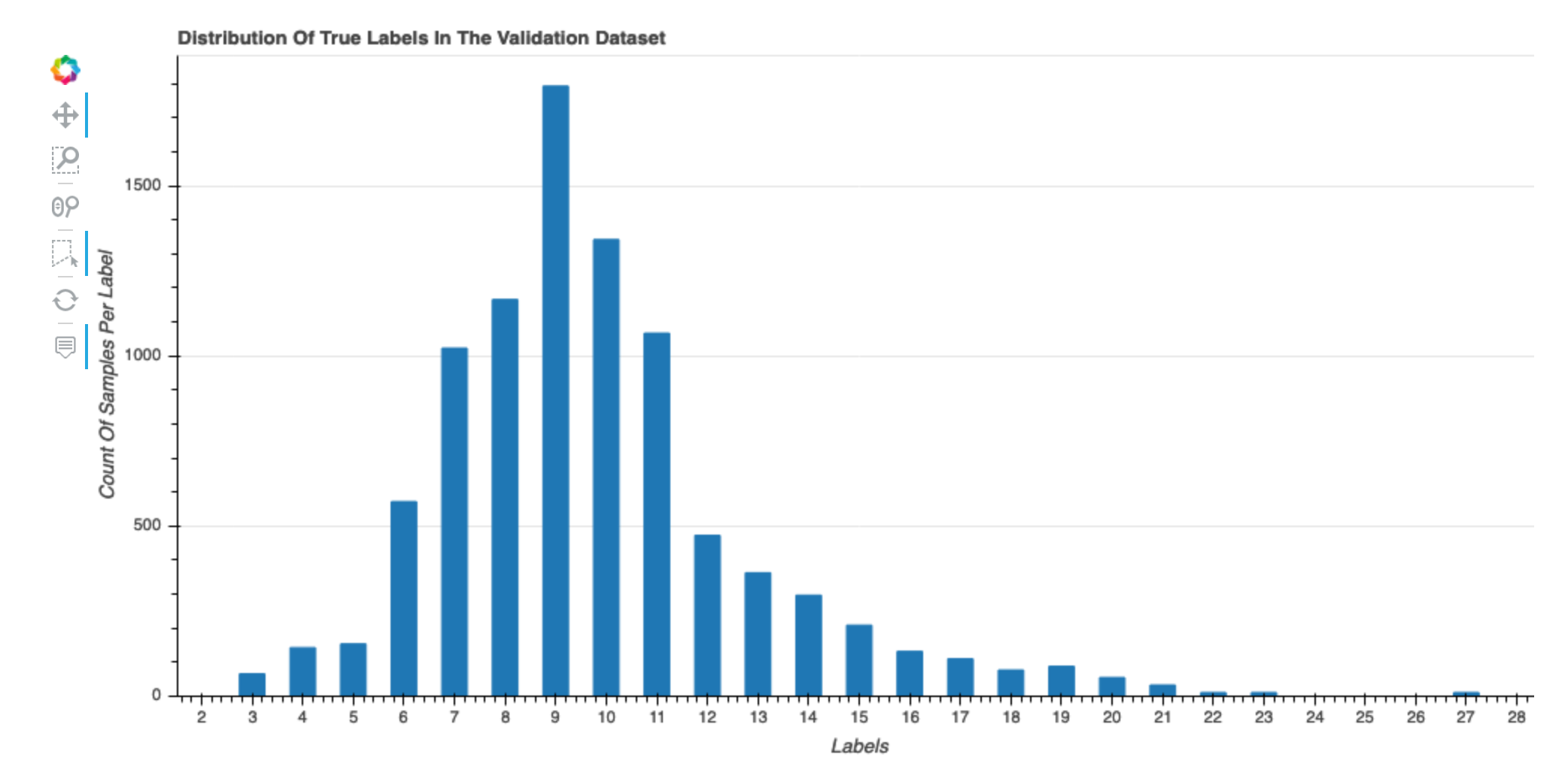
Distribución de las etiquetas verdaderas del conjunto de datos
Este histograma muestra la distribución de las clases etiquetadas (para la clasificación) o los valores (para la regresión) en el conjunto de datos original. La asimetría del conjunto de datos podría provocar imprecisiones. Esta visualización está disponible para los siguientes tipos de modelos: clasificación binaria, multiclasificación y regresión.
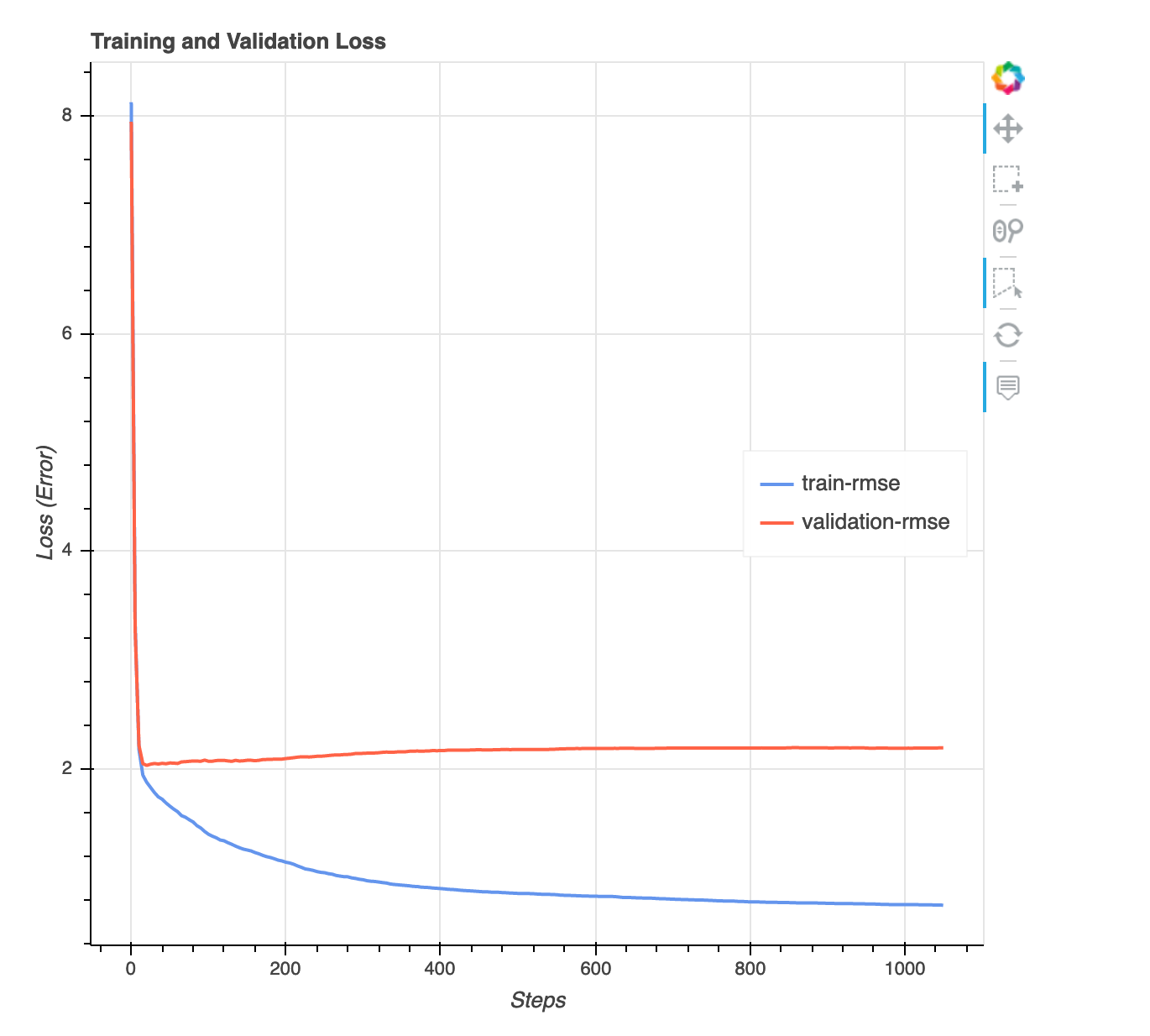
Gráfica de pérdidas versus escalones
Se trata de un gráfico de líneas que muestra la progresión de la pérdida en los datos de entrenamiento y los datos de validación a lo largo de los pasos del entrenamiento. La pérdida es lo que definió en su función objetivo, como el error cuadrático medio. Puede evaluar si el modelo está sobreajustado o insuficientemente ajustado a partir de esta gráfica. Esta sección también proporciona información que puede utilizar para determinar cómo resolver los problemas de sobreajuste y subajuste. Esta visualización está disponible para los siguientes tipos de modelos: clasificación binaria, multiclasificación y regresión.
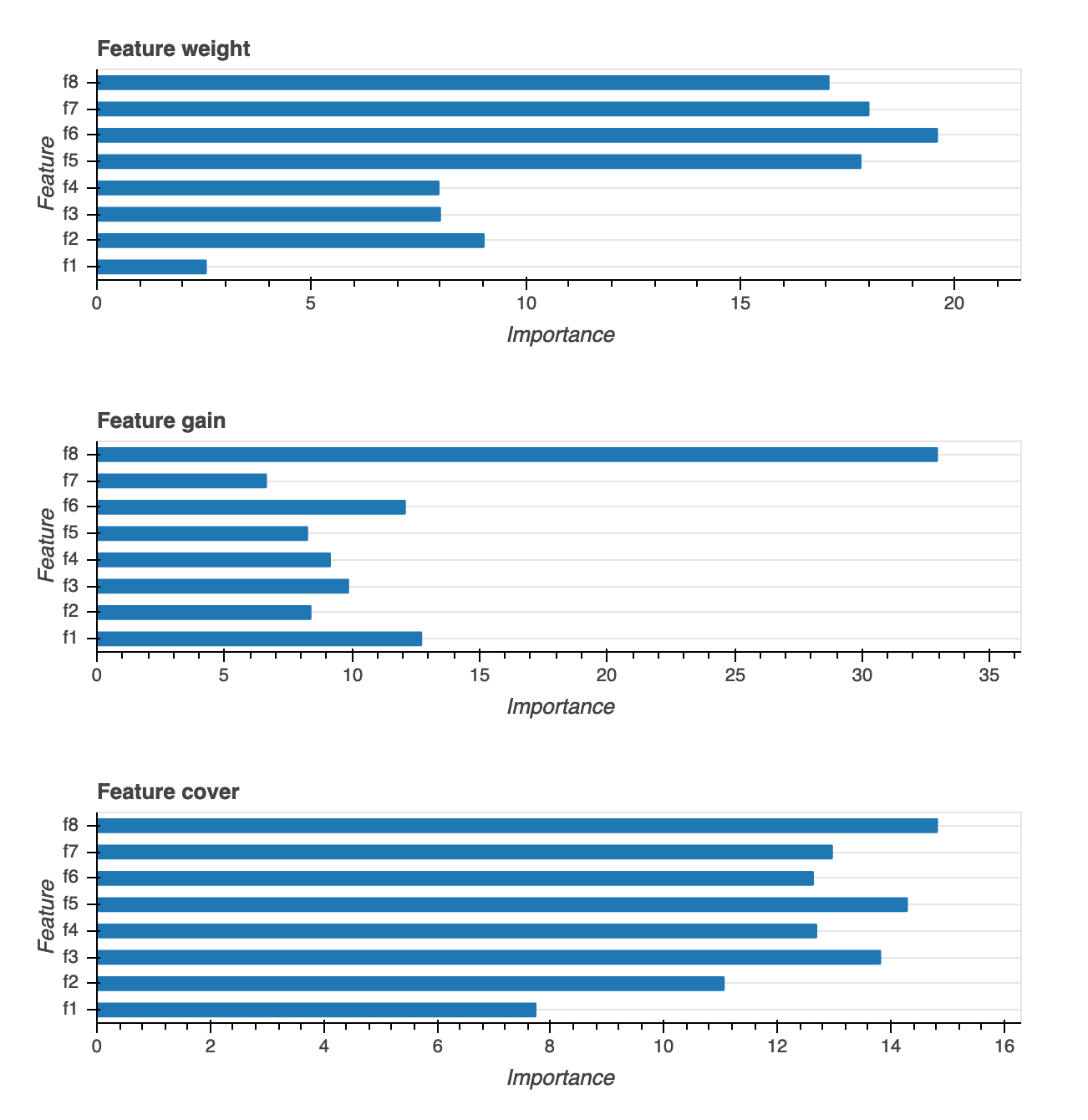
Importancia de las características
Se proporcionan tres tipos diferentes de visualizaciones de la importancia de las características: peso, ganancia y cobertura. Proporcionamos definiciones detalladas para cada uno de los tres en el informe. Las visualizaciones sobre la importancia de las funciones le ayudan a saber qué características de su conjunto de datos de entrenamiento contribuyeron a las predicciones. Las visualizaciones de importancia de las características están disponibles para los siguientes tipos de modelos: clasificación binaria, multiclasificación y regresión.
Matriz de confusión
Esta visualización solo es aplicable a los modelos de clasificación binarios y multiclase. La precisión por sí sola puede no ser suficiente para evaluar el rendimiento de los modelos. Para algunos casos de uso, como la atención médica y la detección de fraudes, también es importante conocer la tasa de falsos positivos y la tasa de falsos negativos. Una matriz de confusión le proporciona las dimensiones adicionales para evaluar el rendimiento de su modelo.

Evaluación de la matriz de confusión
Esta sección le proporciona más información sobre las métricas microscópicas, macroeconómicas y ponderadas de precisión, recuperación y puntuación F1 de su modelo.
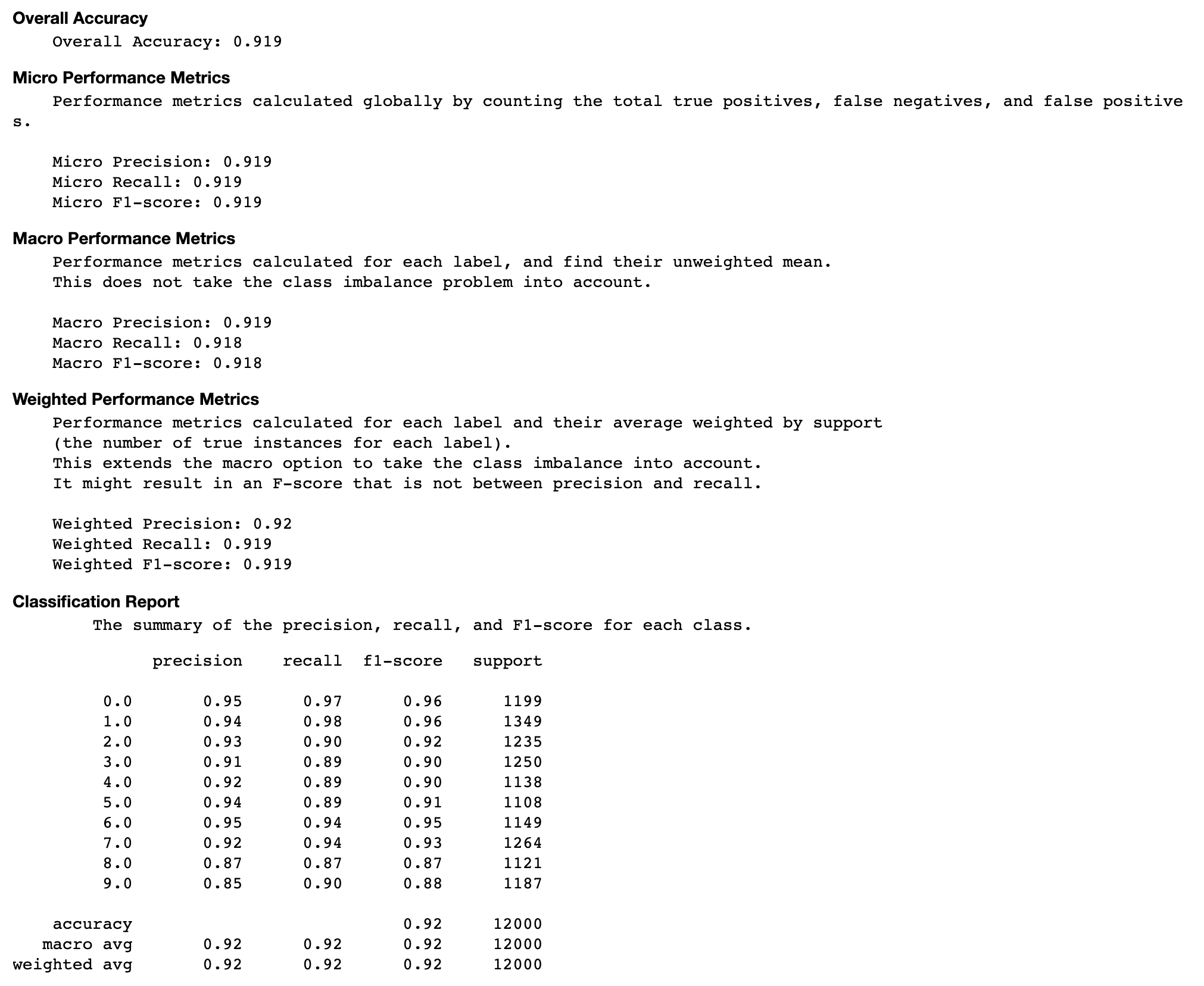
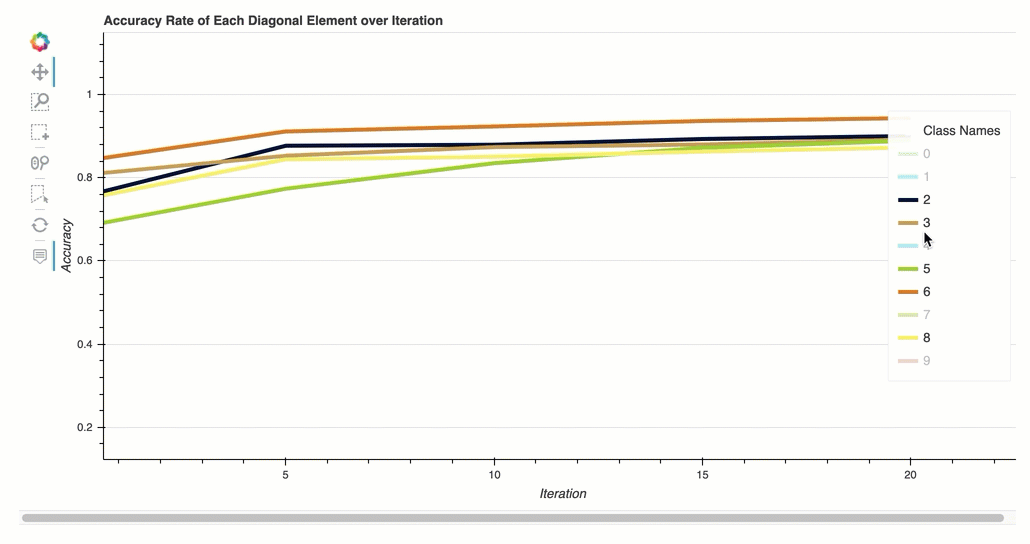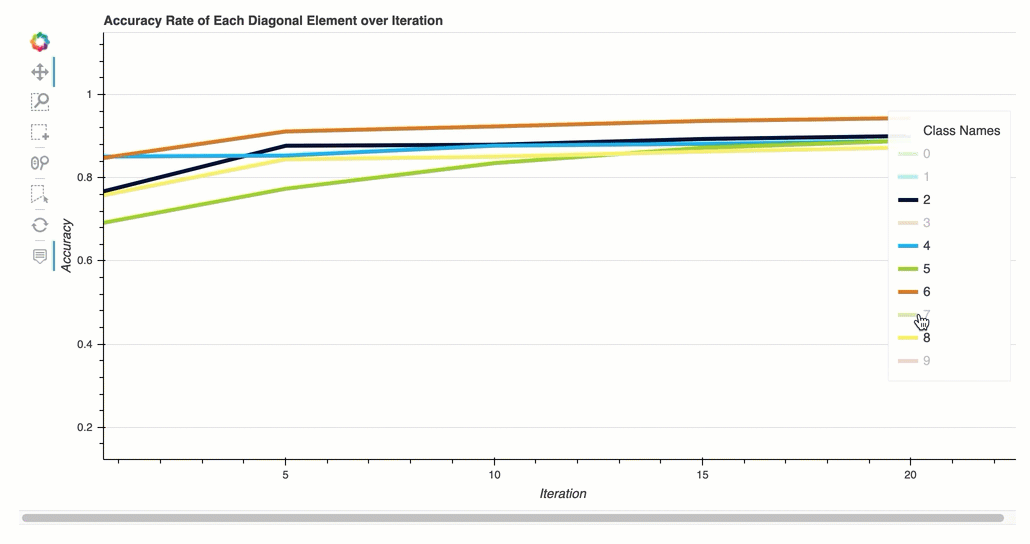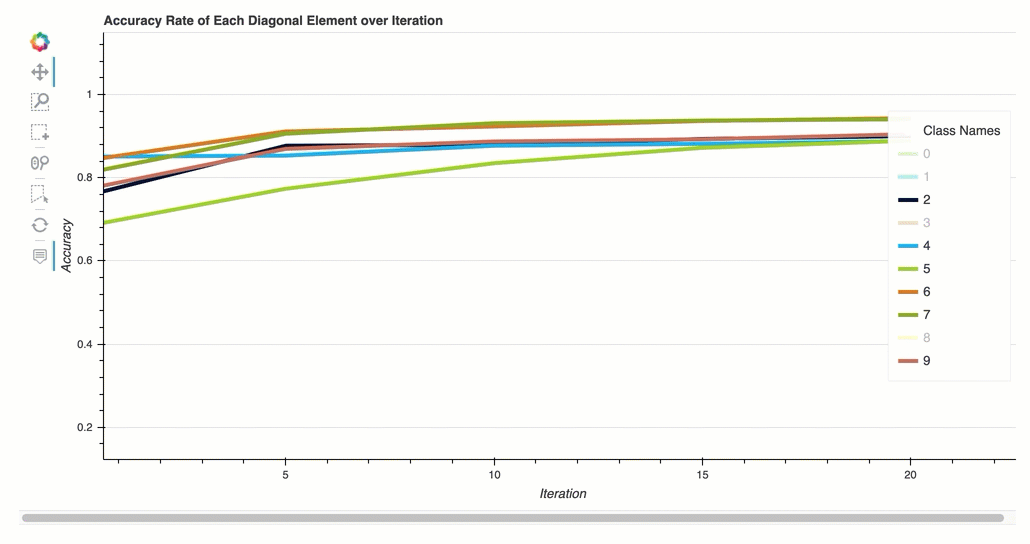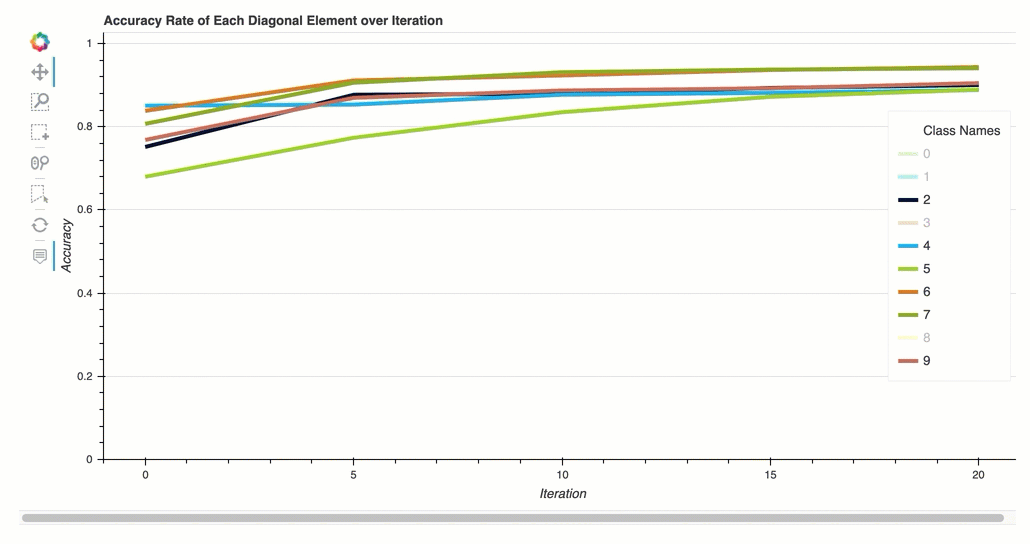
Tasa de precisión de cada elemento diagonal a lo largo de la iteración
Esta visualización solo se aplica a los modelos de clasificación binaria y multiclase. Se trata de un gráfico de líneas que traza los valores diagonales de la matriz de confusión a lo largo de los pasos de entrenamiento de cada clase. Este gráfico muestra cómo progresa la precisión de cada clase a lo largo de los pasos del entrenamiento. Puede identificar las clases con un rendimiento inferior a partir de este gráfico.
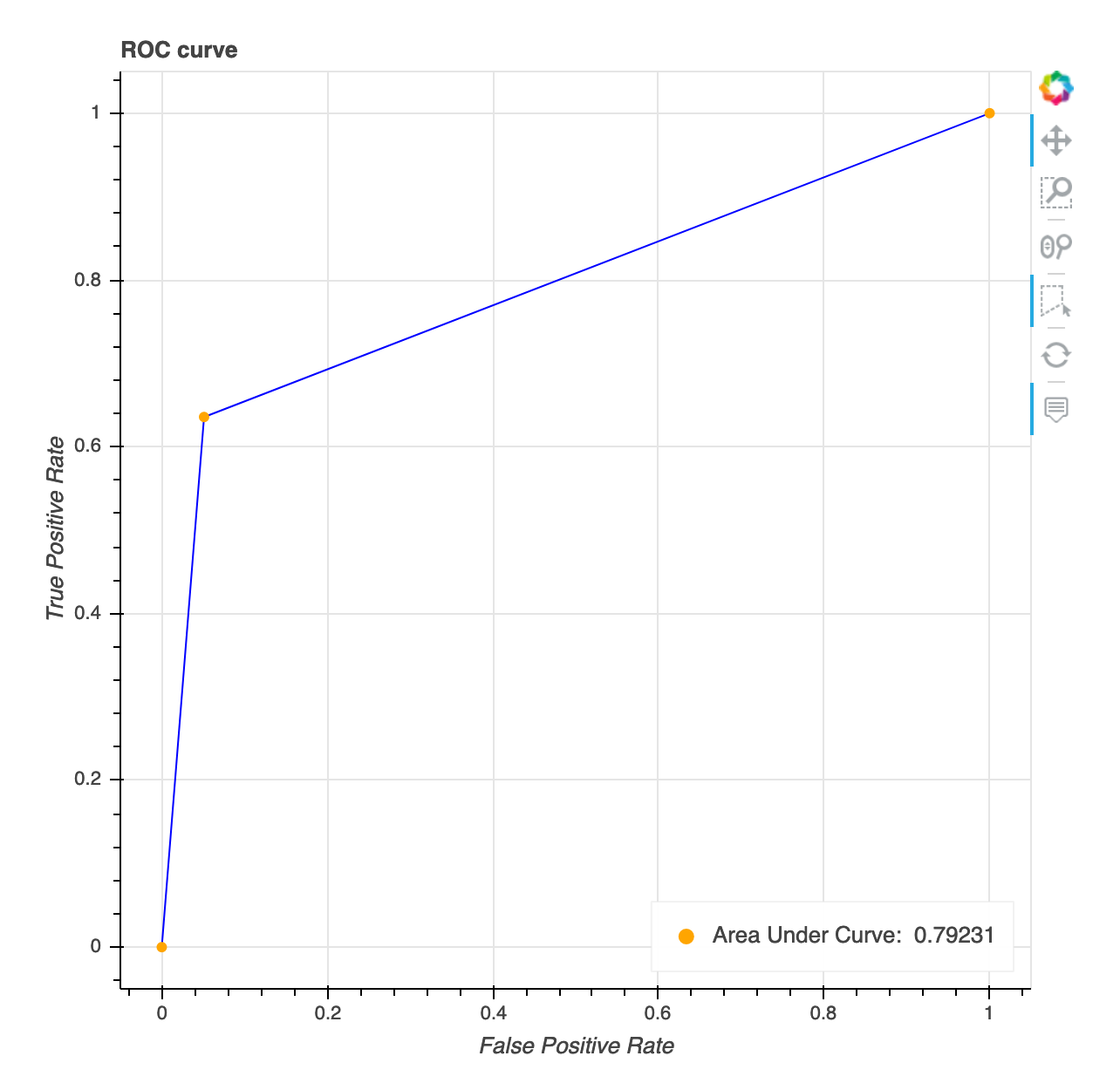
Curva característica de funcionamiento del receptor
Esta visualización solo es aplicable a los modelos de clasificación binaria. La curva de características operativas del receptor se utiliza habitualmente para evaluar el rendimiento del modelo de clasificación binaria. El eje y de la curva es la tasa de positivos verdaderos (TPF) y el eje x es la tasa de falsos positivos (FPR). La gráfica también muestra el valor del área bajo la curva ()AUC. Cuanto más alto sea el AUC valor, más predictivo será el clasificador. También puede usar la ROC curva para comprender la compensación TPR FPR e identificar el umbral de clasificación óptimo para su caso de uso. El umbral de clasificación se puede ajustar para adecuar el comportamiento del modelo y reducir más de uno u otro tipo de error (FP/FN).
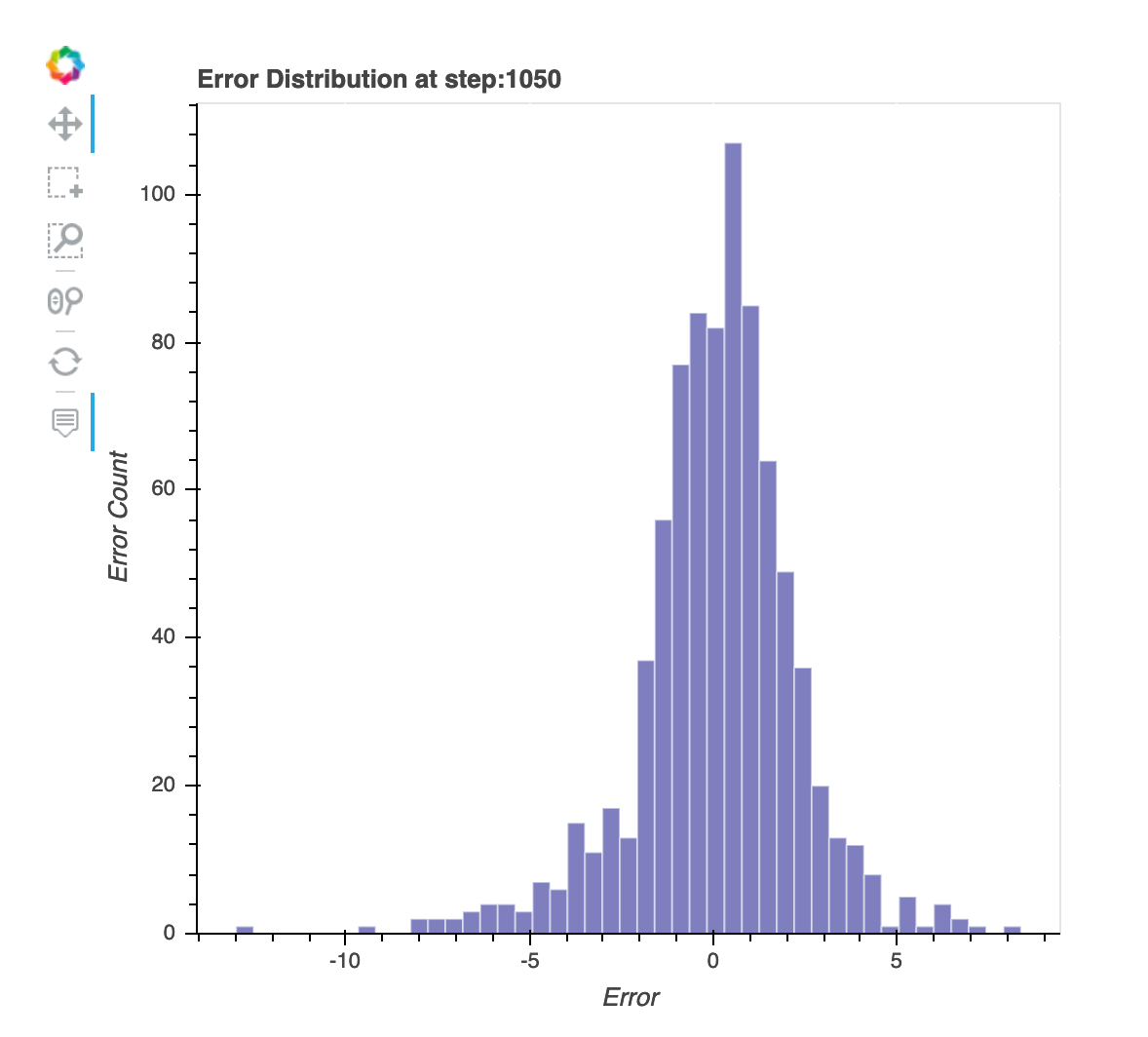
Distribución de los residuos en el último paso guardado
Esta visualización es un gráfico de columnas que muestra las distribuciones residuales del último paso que el depurador capta. En esta visualización, puede comprobar si la distribución residual está cerca de la distribución normal centrada en cero. Si los residuos están sesgados, es posible que sus características no sean suficientes para predecir las etiquetas.
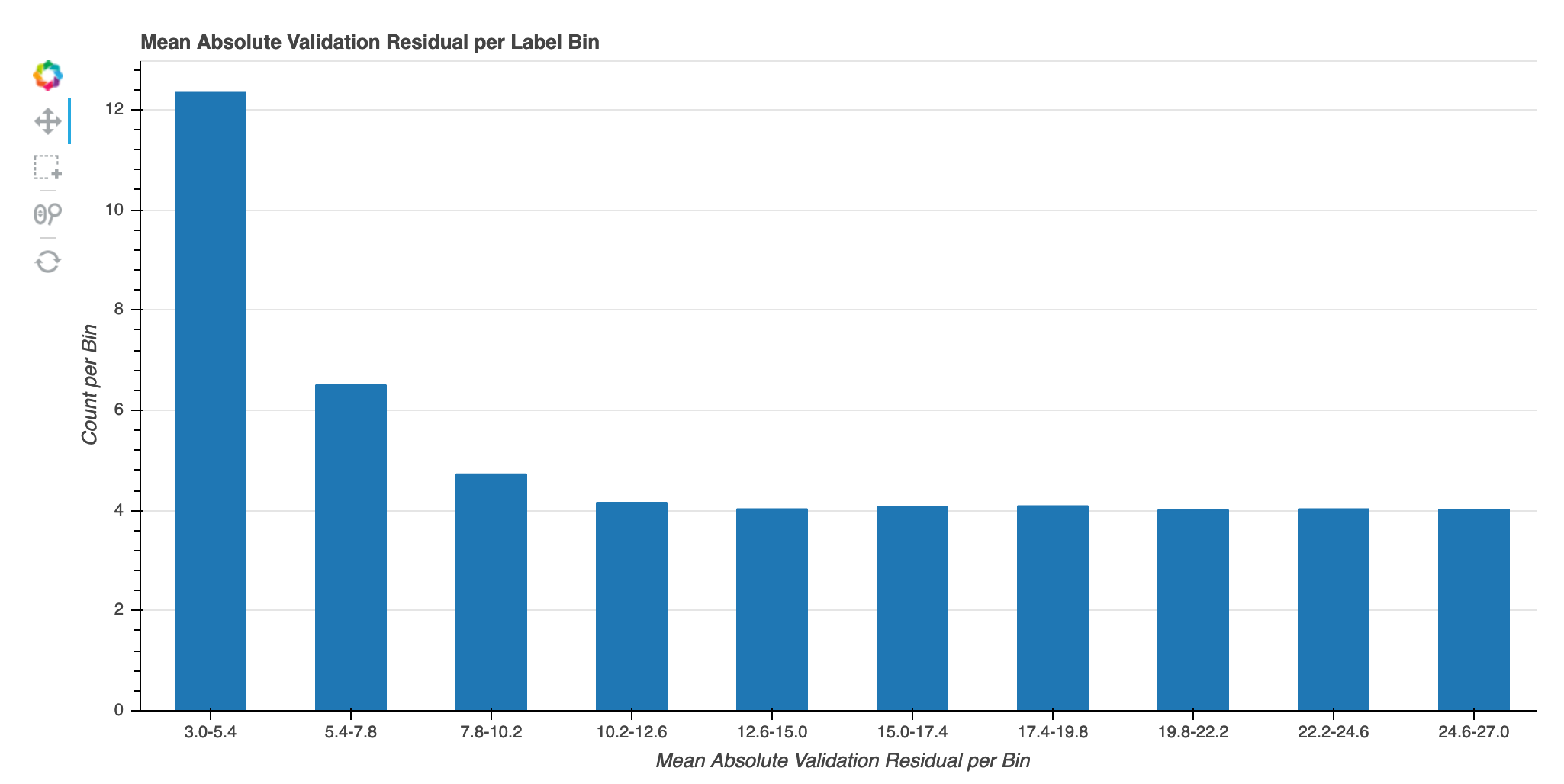
Error absoluto de validación por contenedor de etiquetas durante la iteración
Esta visualización solo se aplica a los modelos de regresión. Los valores objetivo reales se dividen en 10 intervalos. Esta visualización muestra cómo progresan los errores de validación en cada intervalo a lo largo de los pasos de entrenamiento en gráficos de líneas. El error de validación absoluto es el valor absoluto de la diferencia entre la predicción y lo real durante la validación. Puede identificar los intervalos de bajo rendimiento a partir de esta visualización.