Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Escalado del entrenamiento
En las siguientes secciones se describen los escenarios en los que es posible que desee ampliar la formación y cómo puede hacerlo utilizando AWS los recursos. Conviene escalar el entrenamiento en una de las siguientes situaciones:
-
Escalar de uno GPU a varios GPUs
-
Escalar de una sola instancia a varias instancias
-
Uso de scripts de entrenamiento personalizados
Escalar de uno GPU a varios GPUs
La cantidad de datos o el tamaño del modelo utilizado en el machine learning pueden crear situaciones en las que el tiempo de entrenamiento de un modelo sea mayor del que se esté dispuesto a esperar. A veces, el entrenamiento no funciona en absoluto porque el modelo o los datos de entrenamiento son demasiado grandes. Una solución es aumentar el número de los GPUs que se utilizan para la formación. En una instancia con variosGPUs, como una p3.16xlarge que tiene ochoGPUs, los datos y el procesamiento se dividen entre los ochoGPUs. Cuando utiliza bibliotecas de entrenamiento distribuido, esto puede provocar una aceleración casi lineal del tiempo que se tarda en entrenar el modelo. Tarda un poco más de 1/8 del tiempo que habría tardado p3.2xlarge con unoGPU.
| Tipo de instancia | GPUs |
|---|---|
| p3.2xlarge | 1 |
| p3.8xlarge | 4 |
| p3.16xlarge | 8 |
| p3dn.24xlarge | 8 |
nota
Los tipos de instancias ml que se utilizan en el SageMaker entrenamiento tienen el mismo número que GPUs los tipos de instancias p3 correspondientes. Por ejemplo, ml.p3.8xlarge tiene el mismo número GPUs que p3.8xlarge -4.
Escalar de una sola instancia a varias instancias
Si desea ampliar aún más su entrenamiento, puede utilizar más instancias. Sin embargo, debe elegir un tipo de instancia más grande antes de añadir más instancias. Revisa la tabla anterior para ver cuántas GPUs hay en cada tipo de instancia p3.
Si ha pasado de utilizar una sola instancia en p3.2xlarge A cuatro GPU GPUs en unap3.8xlarge, pero decide que necesita más potencia de procesamiento, es posible que obtenga un mejor rendimiento e incurra en costes más bajos si elige una p3.16xlarge antes de intentar aumentar el número de instancias. Según las bibliotecas que utilice, cuando mantiene el entrenamiento en una única instancia, el rendimiento es mejor y los costes son inferiores a los de un escenario en el que se utilizan varias instancias.
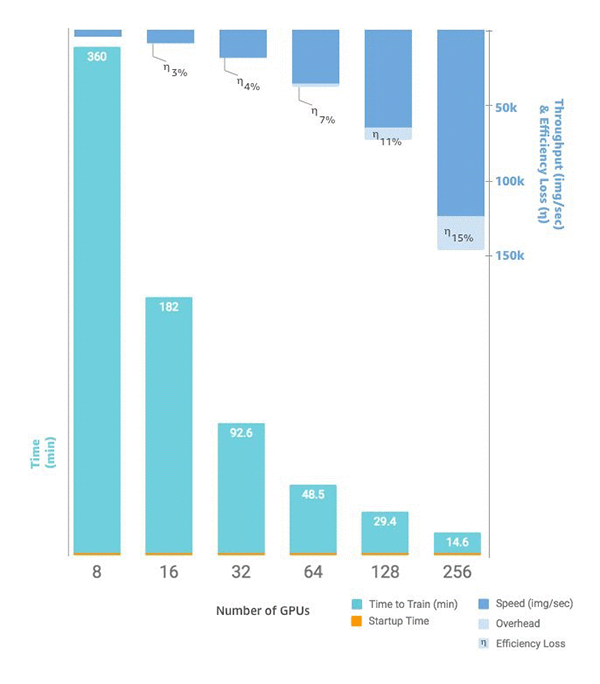
Cuando esté listo para escalar el número de instancias, puede hacerlo con la SDK estimator función SageMaker AI Python configurando suinstance_count. Por ejemplo, puede establecer instance_type = p3.16xlarge y instance_count =
2. En lugar de ocho GPUs en una solap3.16xlarge, tiene 16 GPUs en dos instancias idénticas. En el siguiente gráfico, se muestra el escalado y el rendimiento, empezando por ocho GPUs
Scripts de entrenamiento personalizados
Si bien la SageMaker IA facilita la implementación y el escalado del número de instancias yGPUs, según el marco que se elija, administrar los datos y los resultados puede resultar muy difícil, por lo que a menudo se utilizan bibliotecas de soporte externas. Esta forma tan básica de formación distribuida requiere la modificación del guion de formación para gestionar la distribución de los datos.
SageMaker La IA también es compatible con Horovod y con las implementaciones de formación distribuida nativas de cada uno de los principales marcos de aprendizaje profundo. Si opta por utilizar ejemplos de estos marcos, puede seguir la guía de contenedores de SageMaker AI para Deep Learning Containers y varios cuadernos de ejemplo
