Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Conceptos del almacén de características
Enumeramos los términos más comunes que se utilizan en Amazon SageMaker Feature Store, seguidos de diagramas de ejemplo para visualizar algunos conceptos:
-
Almacén de características: capa de almacenamiento y administración de datos para características de machine learning (ML). Sirve como único origen de verdad para almacenar, recuperar, eliminar, rastrear, compartir, detectar y controlar el acceso a las características. En el siguiente diagrama de ejemplo, el almacén de características es un almacén para sus grupos de características, que contiene sus datos de ML y proporciona servicios adicionales.
-
Almacenamiento en línea: almacén de baja latencia y alta disponibilidad de un grupo de características que permite la búsqueda de registros en tiempo real. El almacenamiento en línea permite un acceso rápido al registro más reciente a través de la API
GetRecord. -
Almacenamiento sin conexión: almacena datos históricos en su bucket de Amazon S3. El almacenamiento sin conexión se utiliza cuando no se necesitan lecturas de latencia baja (inferior a un segundo). Por ejemplo, el almacenamiento sin conexión se puede utilizar cuando desee almacenar y ofrecer características para la exploración, el entrenamiento de modelos y la inferencia por lotes.
-
Grupo de características: el recurso principal del almacén de características que contiene los datos y metadatos que se utilizan para entrenar o predecir con un modelo de ML. Un grupo de características es una agrupación lógica de características que se utiliza para describir registros. En el siguiente diagrama de ejemplo, un grupo de características contiene sus datos de ML.
-
Característica: una propiedad que se utiliza como una de las entradas para entrenar o predecir con el modelo de ML. En la API del almacén de características, una característica es un atributo de un registro. En el siguiente diagrama de ejemplo, una característica describe una columna en su tabla de datos de ML.
-
Definición de característica: consta de un nombre y uno de los tipos de datos: entero, cadena o fracción. Un grupo de características contiene una lista de definiciones de características. Para obtener más información sobre los tipos de datos del almacén de características, consulte Tipos de datos.
-
Registro: colección de valores de las características de un único identificador de registro. Una combinación de valores de identificador de registro y hora del evento identifica de forma exclusiva un registro dentro de un grupo de características. En el siguiente diagrama de ejemplo, un registro es una fila en su tabla de datos de ML.
-
Nombre del identificador de registro: el nombre del identificador de registro es el nombre de la característica que identifica los registros. Debe hacer referencia a uno de los nombres de una característica definida en las definiciones de características del grupo de características. Cada grupo de características se define con un nombre de identificador de registro.
-
Hora del evento: marca temporal que usted proporciona y que se corresponde al momento en que se produjo el evento de registro. Todos los registros del grupo de características deben tener una hora del evento. El almacenamiento en línea solo contiene el registro correspondiente a la hora del evento más reciente, mientras que el almacenamiento sin conexión contiene todos los registros históricos. Para obtener más información sobre los formatos de la hora del evento, consulte Tipos de datos.
-
Ingestión: adición de nuevos registros a un grupo de características. La ingestión se realiza normalmente a través de la API
PutRecord.
Diagrama general de los conceptos
El siguiente diagrama de ejemplo conceptualiza algunos conceptos del almacén de características:

El almacén de características contiene sus grupos de características y un grupo de características contiene sus datos de ML. En el diagrama de ejemplo, el grupo de características original contiene una tabla de datos que tiene tres características (cada una de las cuales describe una columna) y dos registros (filas).
-
La definición de una característica describe el nombre de la característica y el tipo de datos de los valores de la característica que están asociados a los registros.
-
Un registro contiene los valores de las características, se identifica de forma exclusiva por su identificador de registro y debe incluir la hora del evento.
Diagramas de ingestion
La ingestión es la acción de agregar uno o varios registros a un grupo de características existente. El almacenamiento en línea y sin conexión se actualiza de forma diferente para los diferentes casos de uso de almacenamiento.
Ejemplo de ingestión en el almacenamiento en línea
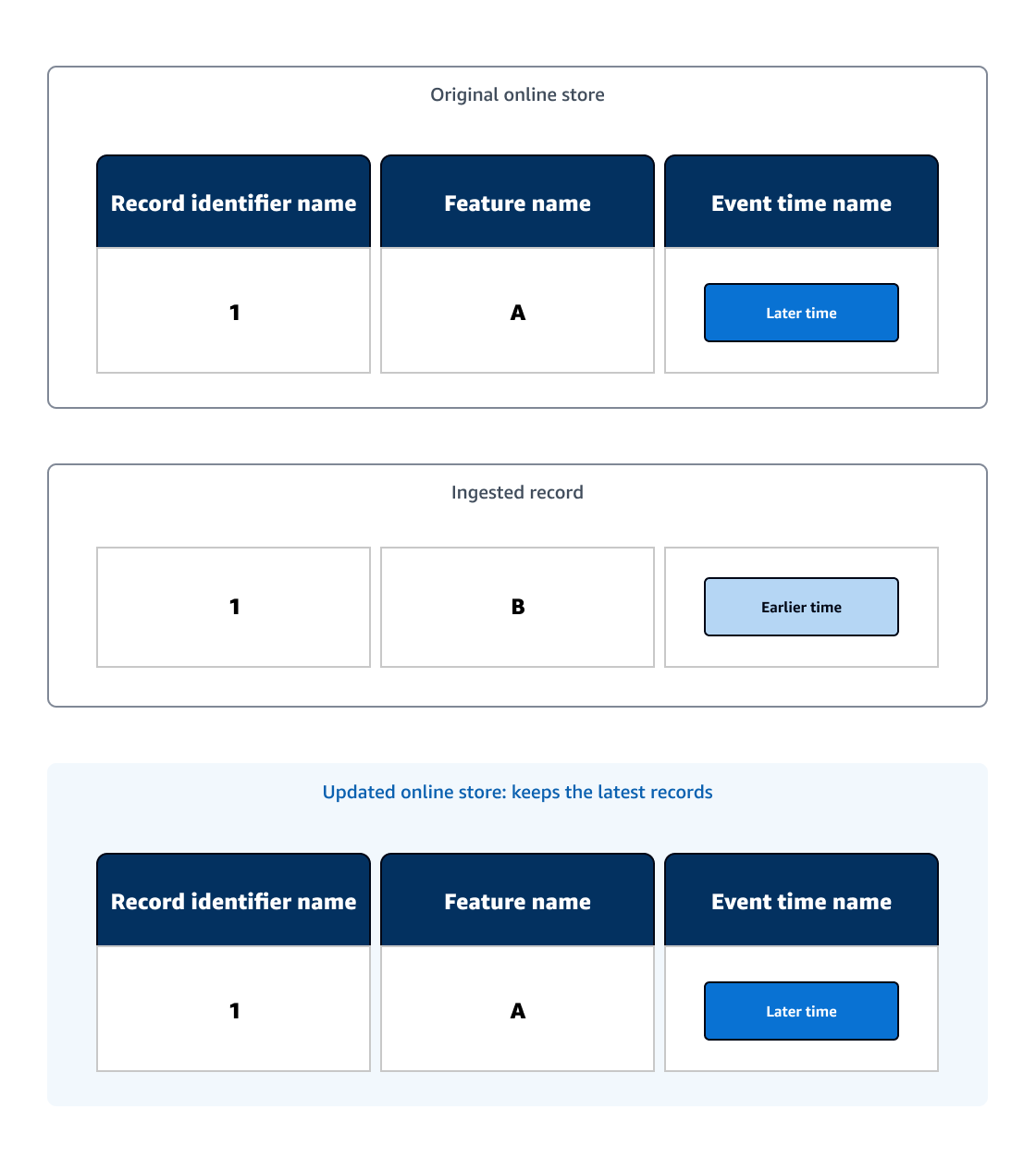
La tienda en línea actúa como una búsqueda de registros en tiempo real y solo conserva la mayoría up-to-date de los registros. Una vez que se ha ingerido un registro nuevo en un almacenamiento en línea existente, el almacenamiento en línea actualizado solo conservará el registro con la hora de evento más reciente.
En el siguiente diagrama de ejemplo, el almacenamiento en línea original contiene una tabla de datos de ML con un solo registro. Se ingiere un registro con el mismo nombre de ID de registro que el registro original, y el registro ingerido tiene una hora de evento anterior a la del registro original. Como el almacenamiento en línea actualizado solo guarda el registro con la última hora del evento, el almacenamiento en línea actualizado contiene el registro original.
Ejemplo de ingestión en el almacenamiento sin conexión
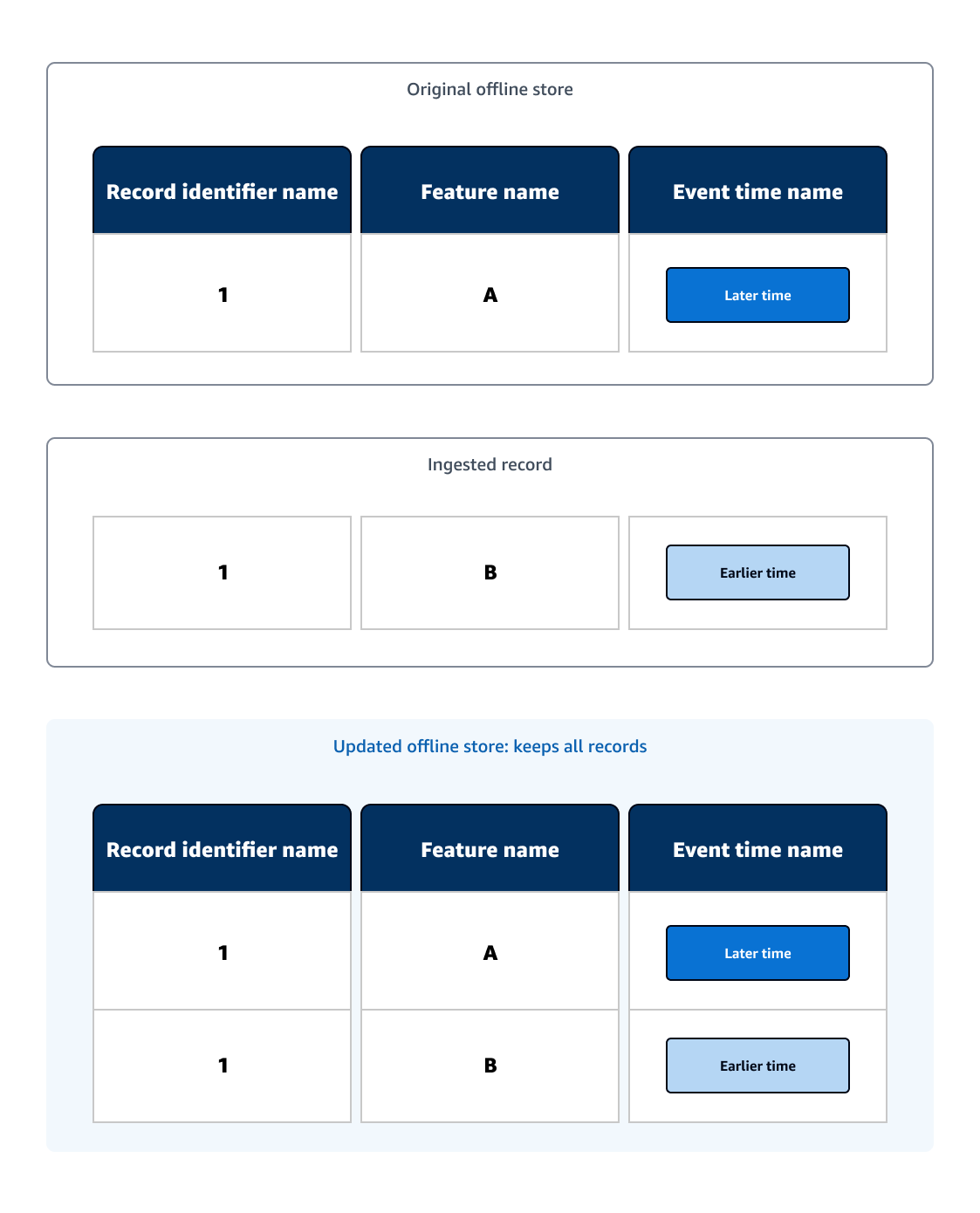
El almacenamiento sin conexión actúa como una consulta histórica de registros y guarda todos los registros. Después de ingerir un registro nuevo en un almacenamiento sin conexión existente, el almacenamiento sin conexión actualizado conservará el nuevo registro.
En el siguiente diagrama de ejemplo, el almacenamiento sin conexión original contiene una tabla de datos de ML con un solo registro. Se ingiere un registro con el mismo nombre de ID de registro que el registro original, y el registro ingerido tiene una hora de evento anterior a la del registro original. Como el almacenamiento sin conexión actualizado conserva todos los registros, este contiene ambos registros.