Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Registros y métricas de canalización de inferencias
La supervisión es importante para mantener la fiabilidad, la disponibilidad y el rendimiento de SageMaker los recursos de Amazon. Para supervisar y solucionar problemas de rendimiento de la canalización de inferencias, utiliza CloudWatch los registros y mensajes de error de Amazon. Para obtener información sobre las herramientas de monitoreo que SageMaker proporciona, consulte. Herramientas para supervisar los AWS recursos aprovisionados mientras se utiliza Amazon SageMaker
Uso de métricas para monitorizar modelos de varios contenedores
Para supervisar los modelos de varios contenedores en Inference Pipelines, utilice Amazon. CloudWatch CloudWatchrecopila datos sin procesar y los procesa para convertirlos en métricas legibles y prácticamente en tiempo real. SageMakerlos trabajos de formación y los puntos finales escriben CloudWatch métricas y registros en el AWS/SageMaker espacio de nombres.
Las siguientes tablas muestran las métricas y dimensiones de los siguientes:
-
Invocaciones de punto de conexión
-
Trabajos de entrenamiento, trabajos de transformación por lotes e instancias de punto de conexión
Una dimensión es un par de nombre-valor que identifica una métrica de forma inequívoca. Puede asignar hasta 10 dimensiones a una métrica. Para obtener más información sobre la supervisión con CloudWatch, consulte. Métricas para monitorizar Amazon SageMaker con Amazon CloudWatch
Métricas de invocación de puntos de conexión
El espacio de nombres AWS/SageMaker incluye las siguientes métricas de respuesta desde llamadas en InvokeEndpoint .
Las métricas se notifican a intervalos de 1 minuto.
| Métrica | Descripción |
|---|---|
Invocation4XXErrors |
El número de Unidades: ninguna Estadísticas válidas: |
Invocation5XXErrors |
El número de Unidades: ninguna Estadísticas válidas: |
Invocations |
Las solicitudes de Para obtener el número total de solicitudes enviadas a un punto de conexión del modelo, utilice la estadística Unidades: ninguna Estadísticas válidas: |
InvocationsPerInstance |
El número de invocaciones de punto final enviadas a un modelo, normalizado Unidades: ninguna Estadísticas válidas: |
ModelLatency |
El tiempo que el modelo o modelos tardan en responder. Esto incluye el tiempo necesario para enviar la solicitud, para obtener la respuesta del contenedor de modelos y para completar la inferencia en el contenedor. ModelLatency es el tiempo total que tardan todos los contenedores en una canalización de inferencia.Unidades: microsegundos Estadísticas válidas: |
OverheadLatency |
El tiempo que se suma al tiempo empleado en responder a una solicitud de un cliente en concepto SageMaker de sobrecarga. Unidades: microsegundos Estadísticas válidas: |
ContainerLatency |
El tiempo que tardó un contenedor de Inference Pipelines en responder visto desde. SageMaker ContainerLatencyincluye el tiempo que se tardó en enviar la solicitud, obtener la respuesta del contenedor del modelo y completar la inferencia en el contenedor.Unidades: microsegundos Estadísticas válidas: |
Dimensiones de las métricas de invocación de puntos de conexión
| Dimensión | Descripción |
|---|---|
EndpointName, VariantName, ContainerName |
Filtra las métricas de invocación de punto de conexión para |
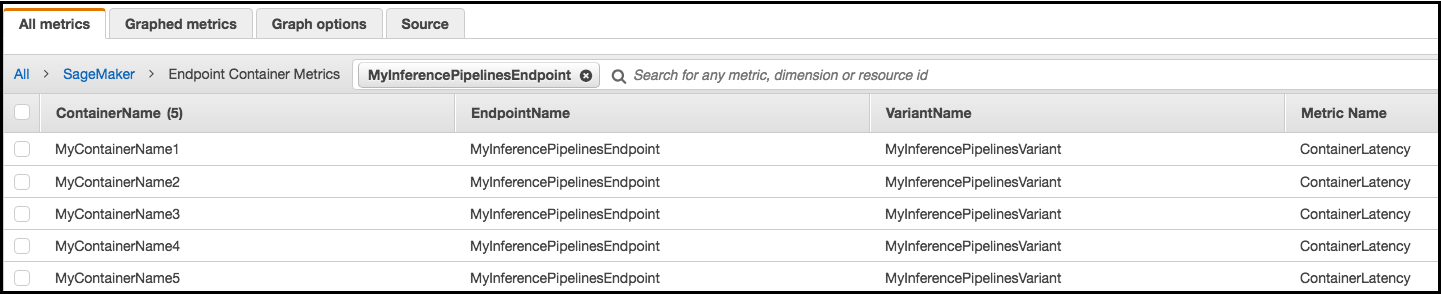
En el caso de un punto final de proceso de inferencia, CloudWatch enumera las métricas de latencia por contenedor de su cuenta como métricas de contenedores de punto final y métricas de variantes de punto final en el SageMakerespacio de nombres, de la siguiente manera. La métrica ContainerLatency solo aparece para canalizaciones de inferencias.
Para cada punto de conexión y cada contenedor, las métricas de latencia muestran los nombres del contenedor, punto de conexión, variante y métrica.
Métricas de instancias de punto de conexión, trabajo de transformación por lotes y trabajo de entrenamiento
Los espacios de nombres /aws/sagemaker/TrainingJobs, /aws/sagemaker/TransformJobs y /aws/sagemaker/Endpoints incluyen las siguientes métricas para los trabajos de entrenamiento y las instancias de punto de conexión.
Las métricas se notifican a intervalos de 1 minuto.
| Métrica | Descripción |
|---|---|
CPUUtilization |
El porcentaje de CPU unidades que utilizan los contenedores que se ejecutan en una instancia. El valor oscila entre el 0% y el 100% y se multiplica por el número deCPUs. Por ejemplo, si hay cuatroCPUs, Para los trabajos de entrenamiento, Para los trabajos de transformación por lotes, En el caso de los modelos con varios contenedores, En el caso de las variantes de punto final, Unidades: porcentaje |
MemoryUtilization |
El porcentaje de memoria que utilizan los contenedores que se ejecutan en una instancia. Este valor oscila entre 0 % y 100 %. Para trabajos de entrenamiento, Para trabajos de transformación por lotes, MemoryUtilization es la suma de memoria utilizada por todos los contenedores que se ejecutan en la instancia.Para variantes de punto de conexión, Unidades: porcentaje |
GPUUtilization |
El porcentaje de GPU unidades que utilizan los contenedores que se ejecutan en una instancia. Para los trabajos de entrenamiento, Para los trabajos de transformación por lotes, En el caso de los modelos con varios contenedores, En el caso de las variantes de punto final, Unidades: porcentaje |
GPUMemoryUtilization |
El porcentaje de GPU memoria que utilizan los contenedores que se ejecutan en una instancia. GPUMemoryUtilizationoscila entre el 0% y el 100% y se multiplica por el número deGPUs. Por ejemplo, si hay cuatroGPUs, Para los trabajos de entrenamiento, En el caso de los trabajos de transformación por lotes, En el caso de los modelos con varios contenedores, En el caso de las variantes de punto final, Unidades: porcentaje |
DiskUtilization |
El porcentaje de espacio en disco que utilizan los contenedores que se ejecutan en una instancia. DiskUtilization oscila entre el 0% y el 100%. Esta métrica no es compatible con los trabajos de transformación por lotes. Para trabajos de entrenamiento, Para variantes de punto de conexión, Unidades: porcentaje |
Dimensiones de métricas de instancias de punto de conexión, trabajo de transformación por lotes y trabajo de entrenamiento
| Dimensión | Descripción |
|---|---|
Host |
Para trabajos de entrenamiento, Para trabajos de transformación por lotes, Para los puntos de conexión, |
Para ayudarte a depurar tus trabajos de formación, los puntos finales y las configuraciones del ciclo de vida de las instancias de notebook, SageMaker también envía todo lo que un contenedor de algoritmos, un contenedor de modelos o una configuración del ciclo de vida de una instancia de cuaderno envíe a stdout stderr Amazon CloudWatch Logs. Puede utilizar esta información para depuración y para analizar el progreso.
Uso de registros para monitorizar una canalización de inferencia
La siguiente tabla muestra los grupos de registros y las secuencias de registros SageMaker. Envía a Amazon CloudWatch
Un flujo de registro es una secuencia de eventos de registro que comparten la misma fuente. Cada fuente independiente de registros CloudWatch constituye un flujo de registro independiente. Un grupo de registro es un grupo de flujos de registro que comparten la misma configuración de retención, monitorización y control de acceso.
Registros
| Nombre del grupo de registro | Nombre del flujo de registro |
|---|---|
/aws/sagemaker/TrainingJobs |
|
/aws/sagemaker/Endpoints/[EndpointName] |
|
|
|
|
|
|
|
/aws/sagemaker/NotebookInstances |
|
/aws/sagemaker/TransformJobs |
|
|
|
|
|
|
nota
SageMakercrea el grupo de /aws/sagemaker/NotebookInstances registros al crear una instancia de notebook con una configuración de ciclo de vida. Para obtener más información, consulte Personalización de una instancia de SageMaker bloc de notas mediante un LCC script.
Para obtener más información sobre el SageMaker registro, consulteRegistra los grupos y las transmisiones que Amazon SageMaker envía a Amazon CloudWatch Logs.
