Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Registre métricas, parámetros y MLflow modelos durante el entrenamiento
Después de conectarse a su servidor de MLflow seguimiento, puede usarlo MLflow SDK para registrar métricas, parámetros y MLflow modelos.
Registra las métricas de entrenamiento
mlflow.log_metricUtilízalo dentro de una MLflow sesión de entrenamiento para hacer un seguimiento de las métricas. Para obtener más información sobre el registro de métricas y su usoMLflow, consultemlflow.log_metric.
with mlflow.start_run(): mlflow.log_metric("foo",1) print(mlflow.search_runs())
Este script debería crear una ejecución experimental e imprimir un resultado similar al siguiente:
run_id experiment_id status artifact_uri ... tags.mlflow.source.name tags.mlflow.user tags.mlflow.source.type tags.mlflow.runName 0 607eb5c558c148dea176d8929bd44869 0 FINISHED s3://dddd/0/607eb5c558c148dea176d8929bd44869/a... ... file.py user-id LOCAL experiment-code-name
Dentro de la MLflow interfaz de usuario, este ejemplo debería tener un aspecto similar al siguiente:
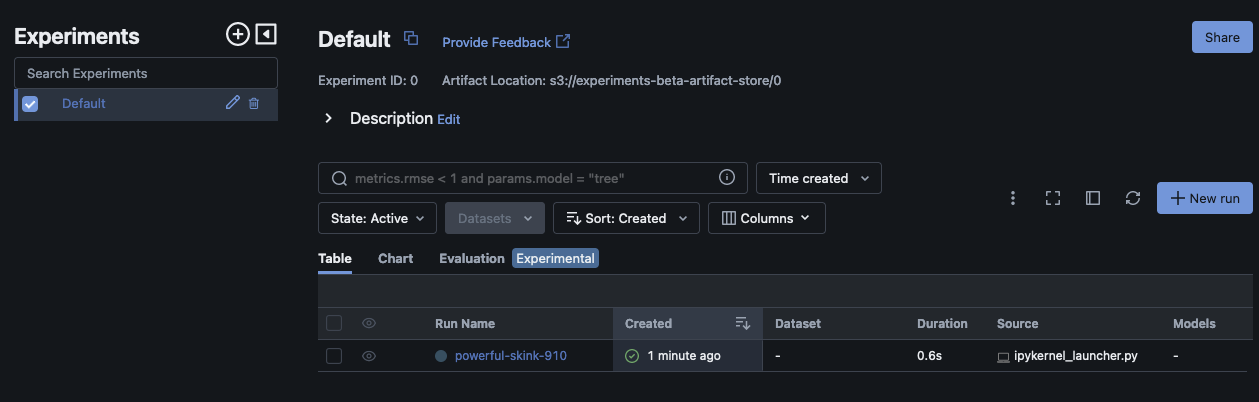
Selecciona Nombre de la ejecución para ver más detalles de la ejecución.
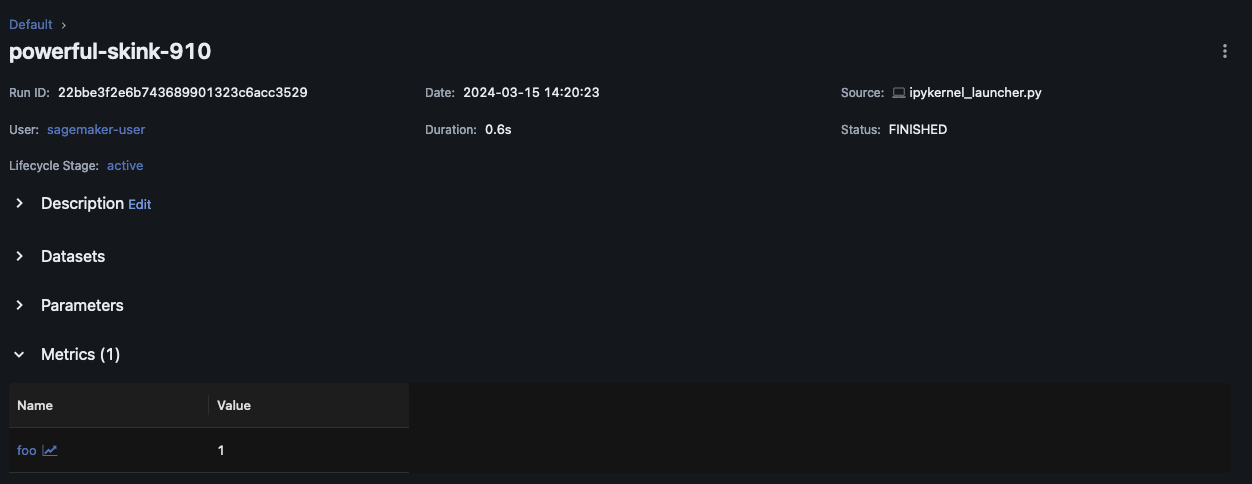
Registra parámetros y modelos
nota
El siguiente ejemplo requiere que su entorno tenga s3:PutObject permisos. Este permiso debe estar asociado al IAM rol que el MLflow SDK usuario asume cuando inicia sesión o se federa en su AWS cuenta. Para obtener más información, consulta los ejemplos de políticas de usuarios y roles.
En el siguiente ejemplo, se explica un flujo de trabajo básico de entrenamiento con modelos SKLearn y se muestra cómo realizar un seguimiento de ese modelo en un MLflow experimento. En este ejemplo, se registran los parámetros, las métricas y los artefactos del modelo.
import mlflow from mlflow.models import infer_signature import pandas as pd from sklearn import datasets from sklearn.model_selection import train_test_split from sklearn.linear_model import LogisticRegression from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score # This is the ARN of the MLflow Tracking Server you created mlflow.set_tracking_uri(your-tracking-server-arn) mlflow.set_experiment("some-experiment") # Load the Iris dataset X, y = datasets.load_iris(return_X_y=True) # Split the data into training and test sets X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # Define the model hyperparameters params = {"solver": "lbfgs", "max_iter": 1000, "multi_class": "auto", "random_state": 8888} # Train the model lr = LogisticRegression(**params) lr.fit(X_train, y_train) # Predict on the test set y_pred = lr.predict(X_test) # Calculate accuracy as a target loss metric accuracy = accuracy_score(y_test, y_pred) # Start an MLflow run and log parameters, metrics, and model artifacts with mlflow.start_run(): # Log the hyperparameters mlflow.log_params(params) # Log the loss metric mlflow.log_metric("accuracy",accuracy) # Set a tag that we can use to remind ourselves what this run was for mlflow.set_tag("Training Info","Basic LR model for iris data") # Infer the model signature signature = infer_signature(X_train, lr.predict(X_train)) # Log the model model_info = mlflow.sklearn.log_model( sk_model=lr, artifact_path="iris_model", signature=signature, input_example=X_train, registered_model_name="tracking-quickstart", )
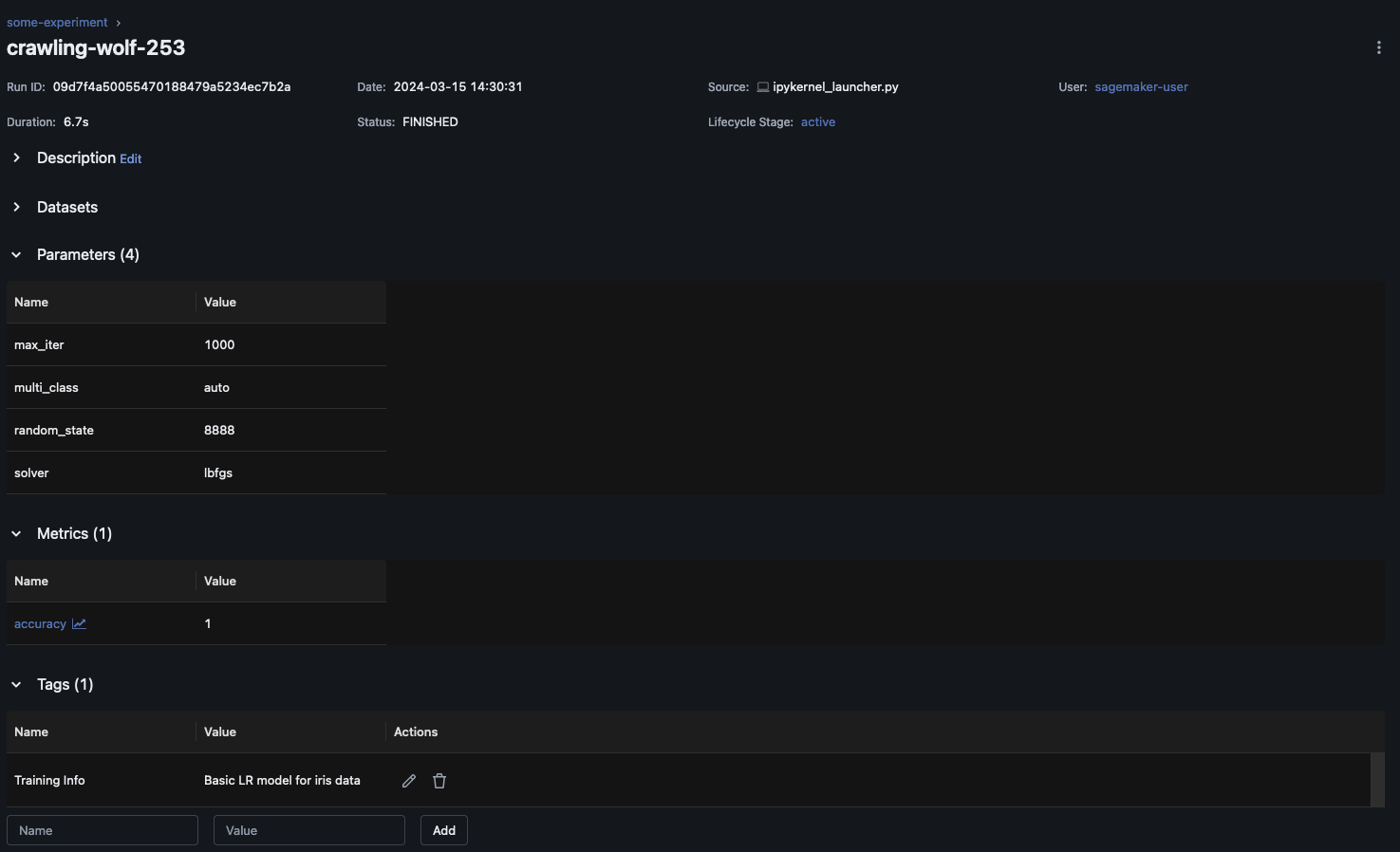
En la MLflow interfaz de usuario, elija el nombre del experimento en el panel de navegación izquierdo para explorar todas las ejecuciones asociadas. Elija el nombre de la ejecución para ver más información sobre cada ejecución. En este ejemplo, la página de ejecución del experimento correspondiente a esta ejecución debería tener un aspecto similar al siguiente.
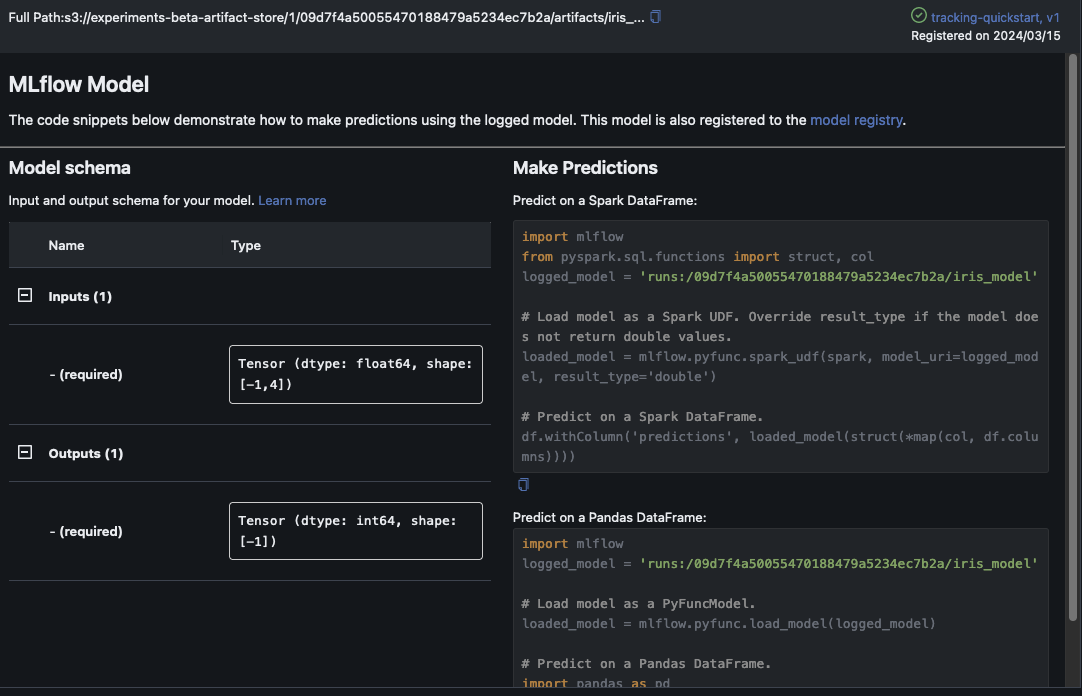
En este ejemplo se registra el modelo de regresión logística. En la MLflow interfaz de usuario, también debería ver los artefactos del modelo registrados.